Sicurezza & Trust Center
La sicurezza dei tuoi dati è la nostra priorità

L'approccio di Databricks all'AI responsabile
Databricks ritiene che il progresso dell'AI dipenda dalla capacità di creare fiducia nelle applicazioni intelligenti tramite l'adozione di pratiche responsabili nello sviluppo e nell'utilizzo dell'AI. Ciò richiede che ogni organizzazione abbia la proprietà e il controllo dei propri dati e modelli AI e sia dotata di strumenti completi per monitoraggio, controllo della privacy e governance durante tutto lo sviluppo e l’implementazione dell'AI.
Responsible AI Testing Framework di Databricks: Red Teaming di modelli GenAI
Il Red Teaming dell'AI è una componente importante per garantire la sicurezza nello sviluppo e nella distribuzione dei modelli, in particolare dei modelli linguistici di grandi dimensioni. Databricks utilizza regolarmente tecniche di Red Teaming dell'AI sui modelli e i sistemi che sviluppa internamente. Di seguito troverai una panoramica del nostro Responsible AI Testing Framework, incluse le tecniche che utilizziamo internamente nel nostro Adversarial ML Lab per testare i nostri modelli, nonché ulteriori tecniche di Red Teaming che stiamo valutando in vista di un utilizzo futuro.
NOTA: è importante ricordare che il campo del Red Teaming dell'AI è ancora nelle sue fasi iniziali e che il rapido ritmo dell’innovazione offre numerose opportunità ma, al tempo stesso, numerose sfide. Continueremo a valutare nuovi approcci per attacchi e contrattacchi ed eventualmente a inserirli nel processo di test dei nostri modelli.
Di seguito la rappresentazione diagrammatica del nostro GenAI Testing Framework:
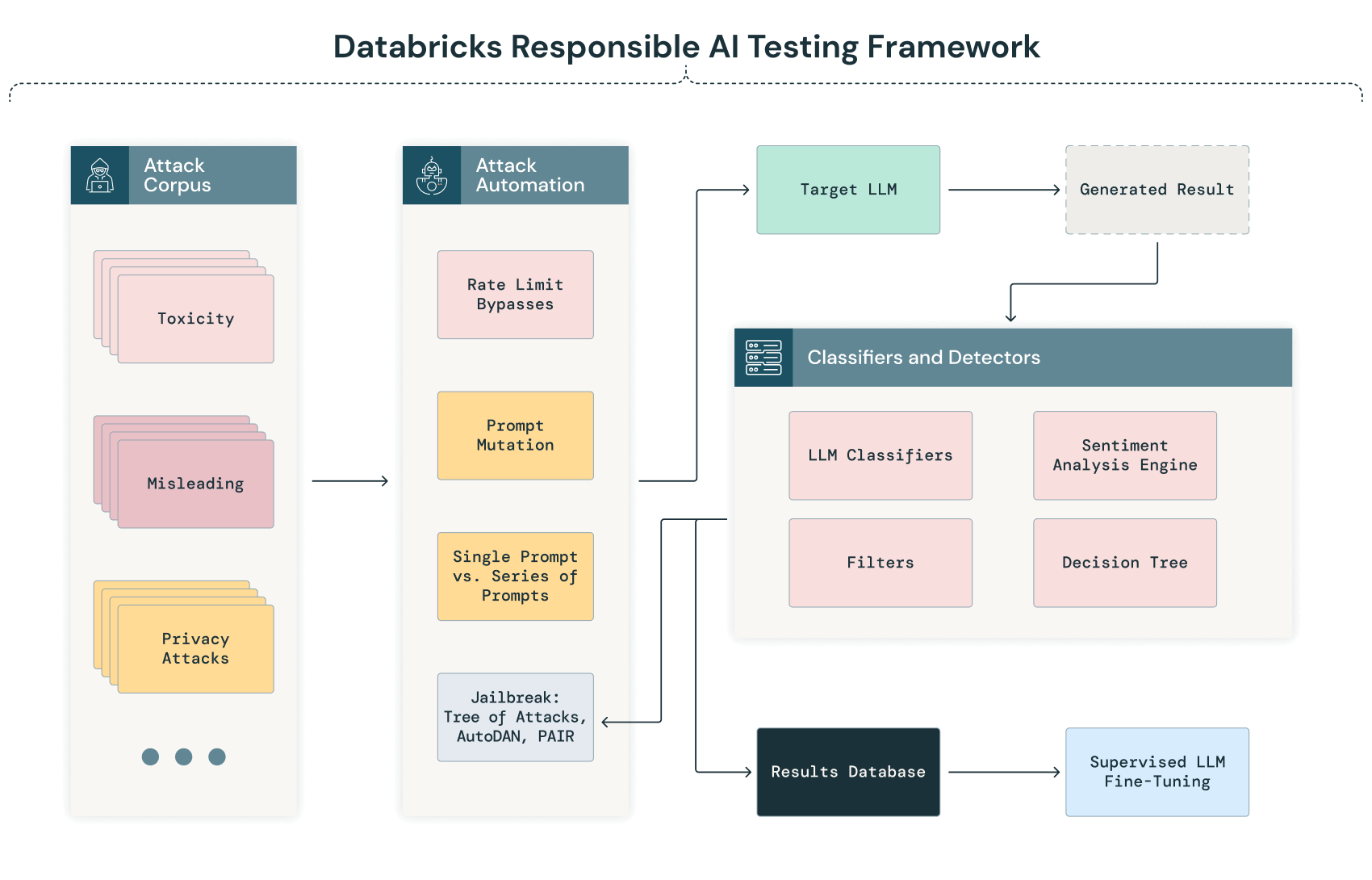
Verifica e classificazione automatizzate
La fase iniziale del nostro processo di Red Teaming dell'AI prevede una procedura automatizzata in cui diversi corpora di testo vengono sistematicamente inviati al modello. Questa procedura mira a sondare le risposte del modello in un'ampia gamma di scenari, identificando automaticamente potenziali vulnerabilità, pregiudizi o problemi di privacy prima di condurre un'analisi manuale più approfondita.
Mentre l'LLM elabora questi input, i suoi output vengono automaticamente acquisiti e classificati utilizzando criteri predefiniti. Questa classificazione può includere tecniche di elaborazione del linguaggio naturale (NLP) e altri modelli AI addestrati per rilevare anomalie, bias o deviazioni dalle prestazioni previste. Ad esempio, un output potrebbe essere segnalato per la revisione manuale se presenta potenziali bias, risposte senza senso o segni di fughe di dati.
Jailbreaking degli LLM
Databricks utilizza numerose tecniche per eseguire il jailbreaking degli LLM, tra cui:
- Istruzioni dirette (DI). Richieste dirette di contenuti dannosi da parte di utenti malintenzionati.
- Prompt DAN ("Do-Anything-Now"). Una varietà di attacchi che incoraggiano il modello a diventare un agente di chat "Do Anything Now" in grado di facilitare qualsiasi attività, indipendentemente dai limiti etici o di sicurezza che gli erano stati precedentemente imposti.
- Attacchi in stile Riley Goodside. Una sequenza di attacchi che chiede direttamente al modello di ignorare le indicazioni precedenti. Questa tecnica è stata resa popolare da Riley Goodside.
- Agency Enterprise PromptInject Corpus. Riproduzione del corpus Agency Enterprise Prompt Injection, costituito dai lavori premiati al workshop sulla sicurezza del ML NeurIPS 2022.
- Prompt Automatic Iterative Refinement (PAIR). Un modello linguistico di grandi dimensioni addestrato per l'attacco viene utilizzato per affinare il prompt guidandolo in modo iterativo verso un jailbreak.
- Tree of Attacks With Pruning (TAP). Simile a un attacco PAIR, con la differenza che viene utilizzato un LLM aggiuntivo per identificare i prompt generati che escono fuori tema e rimuoverli dall'albero di attacchi.
Il test di jailbreaking consente di comprendere meglio la capacità del modello di generalizzare e rispondere a prompt significativamente diversi dai dati di addestramento o che sono in grado di raggiungere informazioni protette in modo alternativo. Questo ci permette anche di identificare i modi in cui un attacco può indurre gli LLM a produrre contenuti dannosi o comunque indesiderati.
Dato che si tratta di un campo in continua evoluzione, continueremo a valutare e testare ulteriori tecniche man mano che il panorama del jailbreaking cambia.
Convalida e analisi manuali
Dopo la fase automatizzata, il processo di Red Teaming dell'AI prevede una revisione manuale degli output segnalati e, per aumentare la probabilità che tutte le criticità vengano identificate, una revisione randomizzata degli output non segnalati. Questa analisi manuale consente di adottare un approccio più ampio all'interpretazione e alla convalida dei problemi identificati attraverso il processo automatizzato.
Il processo di Red Teaming dell'AI comporta una quantità significativa di lavoro manuale. Nel caso in cui le scansioni automatizzate non evidenzino criticità, la valutazione manuale da parte del Red Team può testare varianti in cui questi prompt vengono modificati o concatenati e individuare vulnerabilità sfuggite alla procedura automatizzata.
Modellare la sicurezza della supply chain
Man mano che le nostre attività di Red Teaming dell'AI continuano ad evolversi, includiamo in esse anche processi per valutare la sicurezza della supply chain del modello AI, dall'addestramento fino all'implementazione e alla distribuzione. Le aree che stiamo attualmente valutando includono:
- Compromissione dei dati di addestramento (avvelenamento mediante manomissione di etichette o immissione di dati dannosi).
- Compromissione dell'infrastruttura di addestramento (GPU, VM, ecc.).
- Accesso agli LLM distribuiti per manomettere pesi e iperparametri.
- Manomissione di filtri e altri livelli difensivi implementati.
- Compromissione della distribuzione del modello, ad esempio compromettendo terze parti fidate come Hugging Face.
Ciclo di feedback continuo
Nell'ambito dei nostri sforzi di Red Teaming dell'AI, un'altra area sulla quale intendiamo concentrarsi è l'elaborazione di un ciclo di miglioramento continuo basato su informazioni ottenute sia dalle scansioni automatizzate sia dalle analisi manuali. Questo ciclo di miglioramento continuo ha l'obiettivo di favorire l'evoluzione dei nostri modelli in modo da renderli più robusti e in linea con gli standard di prestazioni più elevati.
Categorie di sonde utilizzate dal Databricks Red Team
Databricks utilizza una serie di corpora curati (sonde) che vengono inviati al modello durante i test. Le sonde sono test o esperimenti specifici progettati per mettere alla prova il sistema AI in vari modi. Per ogni sonda che genera un risultato positivo di non violazione, il Red Team verificherà la presenza di comportamenti scorretti nella risposta del modello testando altre varianti della stessa sonda. Nel contesto degli LLM, le sonde utilizzate dal Databricks Red Team possono essere classificate come segue.
Sonde di sicurezza
- Manipolazione dell'input. Test della risposta del modello a input alterati, fuorvianti o dannosi per identificare vulnerabilità nell'elaborazione dei dati.
- Tecniche di evasione. Tentativo di aggirare le protezioni o i filtri del modello per indurre output dannosi o non intenzionali.
- Inversione del modello. Tentativi di estrarre informazioni sensibili dal modello, compromettendo la privacy dei dati.
Sonde etiche e sonde bias
- Rilevamento dei bias. Test del modello volto a individuare pregiudizi relativi a razza, sesso, età, ecc., analizzando le sue risposte a specifici prompt.
- Dilemmi etici. Presentazione al modello di scenari che ne mettano alla prova la conformità con le norme e i valori etici.
Sonde di robustezza e affidabilità
- Attacchi avversi. Introduzione di input leggermente modificati progettati per ingannare il modello e portare a output errati.
- Controlli di coerenza. Test della capacità del modello di fornire risposte coerenti e affidabili per query simili o ripetute.
Sonde di conformità e sicurezza
- Conformità normativa. Verifica della conformità di output e processi del modello alle normative applicabili.
- Scenari di sicurezza. Valutazione del comportamento del modello in scenari in cui la sicurezza è cruciale, per evitare danni o consigli pericolosi.
- Sonde della privacy. Esame del modello alla luce degli standard e delle normative sulla privacy dei dati, come GDPR o HIPAA. Queste indagini valutano se il modello rivela informazioni personali o sensibili nei suoi output o se potrebbe essere manipolato per estrarre tali dati.
- Controllabilità. Test della facilità con cui operatori umani possono intervenire su output e comportamenti del modello o controllarli.


