Une histoire de trois API Apache Spark : RDDs, DataFrames et Datasets
Quand les utiliser et pourquoi
par Jules Damji
Parmi toutes les joies des développeurs, rien n'est plus attrayant qu'un ensemble d'API qui rendent les développeurs productifs, faciles à utiliser, intuitives et expressives. L'un des attraits d'Apache Spark pour les développeurs a été ses API faciles à utiliser, pour opérer sur de grands ensembles de données, dans différentes langues : Scala, Java, Python et R.
Dans ce blog, j'explore trois ensembles d'API — RDD, DataFrames et Datasets — disponibles dans Apache Spark 2.2 et au-delà ; pourquoi et quand utiliser chaque ensemble ; j'en décris les avantages en termes de performances et d'optimisation ; et j'énumère les scénarios où utiliser des DataFrames et des Datasets plutôt que des RDD. Principalement, je me concentrerai sur les DataFrames et les Datasets, car dans Apache Spark 2.0, ces deux API sont unifiées.
Notre principale motivation derrière cette unification est notre quête pour simplifier Spark en limitant le nombre de concepts que vous devez apprendre et en offrant des moyens de traiter les données structurées. Et grâce à la structure, Spark peut offrir une abstraction de plus haut niveau et des API comme des constructions de langage spécifiques à un domaine.
Resilient Distributed Dataset (RDD)
RDD était l'API principale orientée utilisateur dans Spark depuis sa création. Au cœur, un RDD est une collection distribuée immuable d'éléments de vos données, partitionnée sur les nœuds de votre cluster qui peuvent être opérés en parallèle avec une API de bas niveau offrant des transformations et des actions.
Quand utiliser les RDD ?
Considérez ces scénarios ou cas d'utilisation courants pour utiliser les RDD lorsque :
- vous souhaitez des transformations et des actions de bas niveau et un contrôle sur votre jeu de données ;
- vos données ne sont pas structurées, comme des flux multimédias ou des flux de texte ;
- vous souhaitez manipuler vos données avec des constructions de programmation fonctionnelle plutôt que des expressions spécifiques à un domaine ;
- vous ne vous souciez pas d'imposer un schéma, comme un format en colonnes, lors du traitement ou de l'accès aux attributs de données par nom ou par colonne ; et
- vous pouvez renoncer à certains avantages d'optimisation et de performance disponibles avec les DataFrames et les Datasets pour les données structurées et semi-structurées.
Qu'advient-il des RDD dans Apache Spark 2.0 ?
Vous pourriez demander : Les RDD sont-ils relégués au rang de citoyens de seconde zone ? Sont-ils dépréciés ?
La réponse est un retentissant NON !
De plus, comme vous le noterez ci-dessous, vous pouvez passer de manière transparente entre DataFrame ou Dataset et RDD à volonté — par de simples appels de méthode d'API — et les DataFrames et Datasets sont construits sur les RDD.
DataFrames
Comme un RDD, un DataFrame est une collection distribuée immuable de données. Contrairement à un RDD, les données sont organisées en colonnes nommées, comme une table dans une base de données relationnelle. Conçu pour faciliter encore plus le traitement des grands ensembles de données, DataFrame permet aux développeurs d'imposer une structure à une collection distribuée de données, permettant une abstraction de plus haut niveau ; il fournit une API de langage spécifique à un domaine pour manipuler vos données distribuées ; et rend Spark accessible à un public plus large, au-delà des ingénieurs de données spécialisés.
Dans notre aperçu du webinaire Apache Spark 2.0 et dans le blog suivant, nous avons mentionné qu'en Spark 2.0, les API DataFrame fusionneront avec les API Datasets, unifiant les capacités de traitement de données entre les bibliothèques. Grâce à cette unification, les développeurs ont maintenant moins de concepts à apprendre ou à retenir, et travaillent avec une API unique de haut niveau et type-safe appelée Dataset.
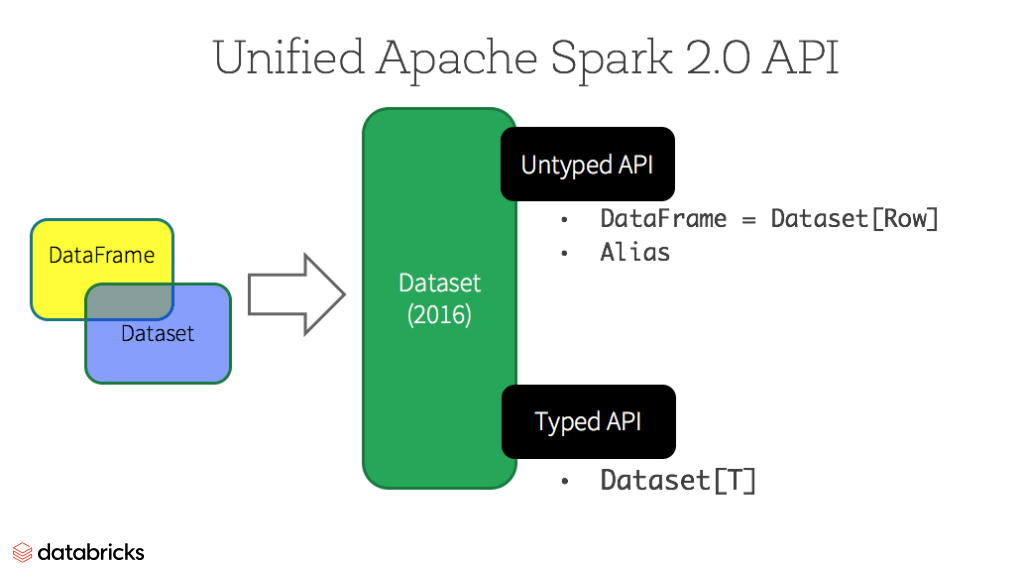
Datasets
À partir de Spark 2.0, Dataset adopte deux caractéristiques d'API distinctes : une API fortement typée et une API non typée, comme le montre le tableau ci-dessous. Conceptuellement, considérez DataFrame comme un alias pour une collection d'objets génériques Dataset[Row], où un Row est un objet JVM générique non typé. Dataset, en revanche, est une collection d'objets JVM fortement typés, dictés par une classe de cas que vous définissez en Scala ou une classe en Java.
API typées et non typées
| Langage | Abstraction principale |
|---|---|
| Scala | Dataset[T] & DataFrame (alias pour Dataset[Row]) |
| Java | Dataset[T] |
| Python* | DataFrame |
| R* | DataFrame |
Remarque : Comme Python et R n'ont pas de sécurité de type à la compilation, nous n'avons que des API non typées, à savoir les DataFrames.
Avantages des API Dataset
En tant que développeur Spark, vous bénéficiez des API unifiées DataFrame et Dataset dans Spark 2.0 de plusieurs manières.
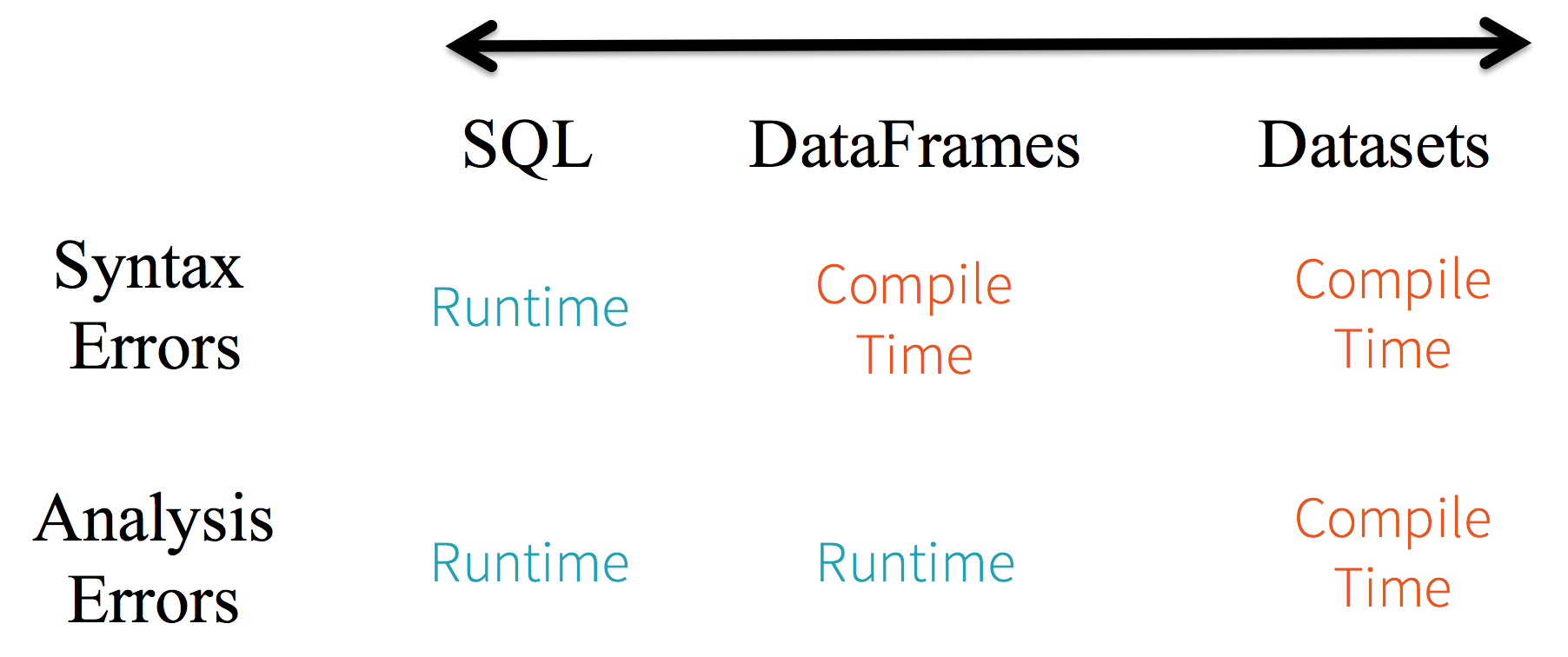
1. Typage statique et sécurité de type à l'exécution
Considérez le typage statique et la sécurité à l'exécution comme un spectre, SQL étant le moins restrictif et Dataset le plus restrictif. Par exemple, dans vos requêtes de chaîne Spark SQL, vous ne connaîtrez une erreur de syntaxe qu'à l'exécution (runtime) (ce qui peut être coûteux), tandis qu'avec les DataFrames et les Datasets, vous pouvez détecter les erreurs à la compilation (ce qui permet d'économiser du temps de développement et des coûts). C'est-à-dire, si vous appelez une fonction dans DataFrame qui ne fait pas partie de l'API, le compilateur la détectera. Cependant, il ne détectera pas un nom de colonne inexistant avant l'exécution.
À l'extrémité du spectre se trouve Dataset, le plus restrictif. Comme les API Dataset sont toutes exprimées sous forme de fonctions lambda et d'objets typés JVM, toute inadéquation de paramètres typés sera détectée à la compilation. De plus, votre erreur d'analyse peut également être détectée à la compilation, lors de l'utilisation de Datasets, économisant ainsi du temps de développement et des coûts.
Tout cela se traduit par un spectre de sécurité de type le long de la syntaxe et des erreurs d'analyse dans votre code Spark, avec Datasets comme étant le plus restrictif mais le plus productif pour un développeur.
2. Abstraction de haut niveau et vue personnalisée sur les données structurées et semi-structurées
Les DataFrames, en tant que collection de Datasets[Row], offrent une vue personnalisée et structurée de vos données semi-structurées. Par exemple, supposons que vous ayez un énorme ensemble de données d'événements d'appareils IoT, exprimé en JSON. Comme le JSON est un format semi-structuré, il se prête bien à l'utilisation de Dataset comme une collection de Dataset[DeviceIoTData] fortement typés et spécifiques.
Vous pourriez exprimer chaque entrée JSON comme DeviceIoTData, un objet personnalisé, avec une classe de cas Scala.
Ensuite, nous pouvons lire les données à partir d'un fichier JSON.
Trois choses se produisent ici en coulisses dans le code ci-dessus :
- Spark lit le JSON, déduit le schéma et crée une collection de DataFrames.
- À ce stade, Spark convertit vos données en DataFrame = Dataset[Row], une collection d'objets Row génériques, car il ne connaît pas le type exact.
- Maintenant, Spark convertit le Dataset[Row] -> Dataset[DeviceIoTData] objet Scala JVM spécifique au type, tel que dicté par la classe DeviceIoTData.
La plupart d'entre nous qui travaillons avec des données structurées sont habitués à visualiser et à traiter les données de manière tabulaire ou à accéder à des attributs spécifiques au sein d'un objet. Avec Dataset comme collection d'objets typés Dataset[ElementType], vous bénéficiez de manière transparente de la sécurité à la compilation et d'une vue personnalisée pour les objets JVM fortement typés. Et votre Dataset[T] fortement typé résultant du code ci-dessus peut être facilement affiché ou traité avec des méthodes de haut niveau.
3. Facilité d'utilisation des API avec structure
Bien que la structure puisse limiter le contrôle sur ce que votre programme Spark peut faire avec les données, elle introduit des sémantiques riches et un ensemble facile d'opérations spécifiques au domaine qui peuvent être exprimées sous forme de constructions de haut niveau. La plupart des calculs, cependant, peuvent être réalisés avec les API de haut niveau de Dataset. Par exemple, il est beaucoup plus simple d'effectuer des opérations agg, select, sum, avg, map, filter, ou groupBy en accédant à un objet de type Dataset DeviceIoTData plutôt qu'aux champs de données des lignes RDD.
Exprimer votre calcul dans une API spécifique au domaine est beaucoup plus simple et plus facile qu'avec des expressions de type algèbre relationnelle (dans les RDD). Par exemple, le code ci-dessous va filter() et map() pour créer un autre Dataset immuable.
4. Performance et Optimisation
En plus de tous les avantages ci-dessus, vous ne pouvez pas négliger les gains d'efficacité spatiale et de performance lors de l'utilisation des API DataFrame et Dataset pour deux raisons.
Premièrement, comme les API DataFrame et Dataset sont construites sur le moteur Spark SQL, elles utilisent Catalyst pour générer un plan de requête logique et physique optimisé. Que ce soit via les API DataFrame/Dataset R, Java, Scala ou Python, toutes les requêtes de type relationnel subissent le même optimiseur de code, offrant ainsi une efficacité spatiale et de vitesse. Alors que l'API de type Dataset[T] est optimisée pour les tâches d'ingénierie de données, le Dataset[Row] non typé (un alias de DataFrame) est encore plus rapide et convient à l'analyse interactive.

Deuxièmement, puisque Spark en tant que compilateur comprend votre objet JVM de type Dataset, il le mappe à la représentation mémoire interne de Tungsten à l'aide des Encodeurs. En conséquence, les encodeurs Tungsten peuvent sérialiser/désérialiser efficacement les objets JVM ainsi que générer un bytecode compact qui peut s'exécuter à des vitesses supérieures.
Quand utiliser DataFrames ou Datasets ?
- Si vous souhaitez des sémantiques riches, des abstractions de haut niveau et des API spécifiques au domaine, utilisez DataFrame ou Dataset.
- Si votre traitement exige des expressions de haut niveau, des filtres, des maps, des agrégations, des moyennes, des sommes, des requêtes SQL, un accès par colonnes et l'utilisation de fonctions lambda sur des données semi-structurées, utilisez DataFrame ou Dataset.
- Si vous souhaitez un degré plus élevé de sécurité de type à la compilation, des objets JVM typés, profiter de l'optimisation Catalyst et bénéficier de la génération de code efficace de Tungsten, utilisez Dataset.
- Si vous souhaitez une unification et une simplification des API entre les bibliothèques Spark, utilisez DataFrame ou Dataset.
- Si vous êtes un utilisateur R, utilisez DataFrames.
- Si vous êtes un utilisateur Python, utilisez DataFrames et revenez aux RDD si vous avez besoin de plus de contrôle.
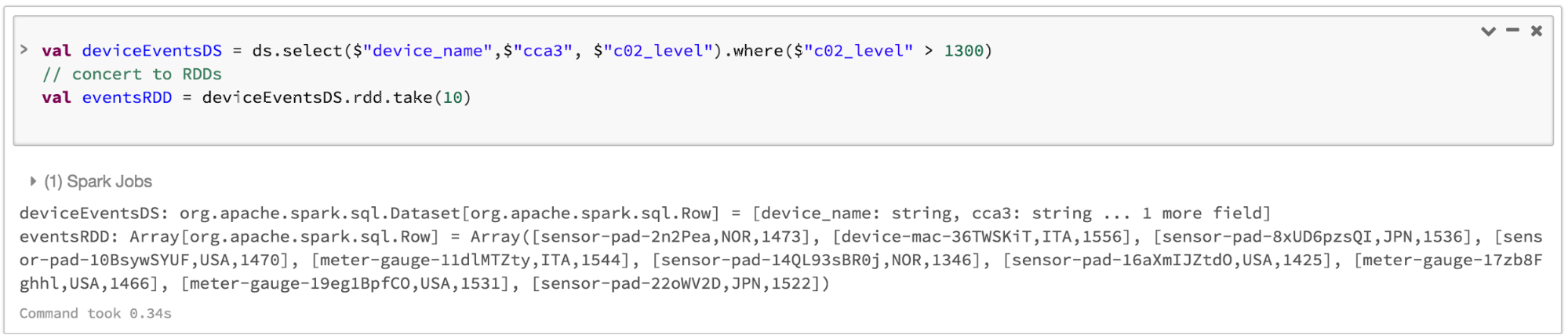
Notez que vous pouvez toujours interopérer ou convertir de manière transparente un DataFrame et/ou un Dataset en RDD, par un simple appel de méthode .rdd. Par exemple,
Mise en commun
En résumé, le choix entre RDD et DataFrame/Dataset semble évident. Alors que le premier vous offre des fonctionnalités et un contrôle de bas niveau, le second permet une vue et une structure personnalisées, offre des opérations de haut niveau et spécifiques au domaine, économise de l'espace et s'exécute à des vitesses supérieures.
Alors que nous examinions les leçons apprises des premières versions de Spark — comment simplifier Spark pour les développeurs, comment l'optimiser et le rendre performant — nous avons décidé d'élever les API RDD de bas niveau vers une abstraction de haut niveau comme DataFrame et Dataset et de construire cette abstraction de données unifiée à travers les bibliothèques sur l'optimiseur Catalyst et Tungsten.
Choisissez celle qui répond à vos besoins et à votre cas d'utilisation — DataFrames/Dataset ou API RDD — mais je ne serais pas surpris si vous rejoigniez la majorité des développeurs qui travaillent avec des données structurées et semi-structurées.
Et ensuite ?
Vous pouvez essayer Apache Spark 2.2 sur Databricks.
Vous pouvez également regarder la présentation de Spark Summit sur A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets
Si vous ne vous êtes pas encore inscrit, essayez Databricks dès maintenant.
Dans les semaines à venir, nous publierons une série d'articles sur Structured Streaming. Restez à l'écoute.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.