Conçu pour le stockage de données ouvert et intelligent
Choisissez votre emplacement de stockage et votre format, et conservez la propriété et la portab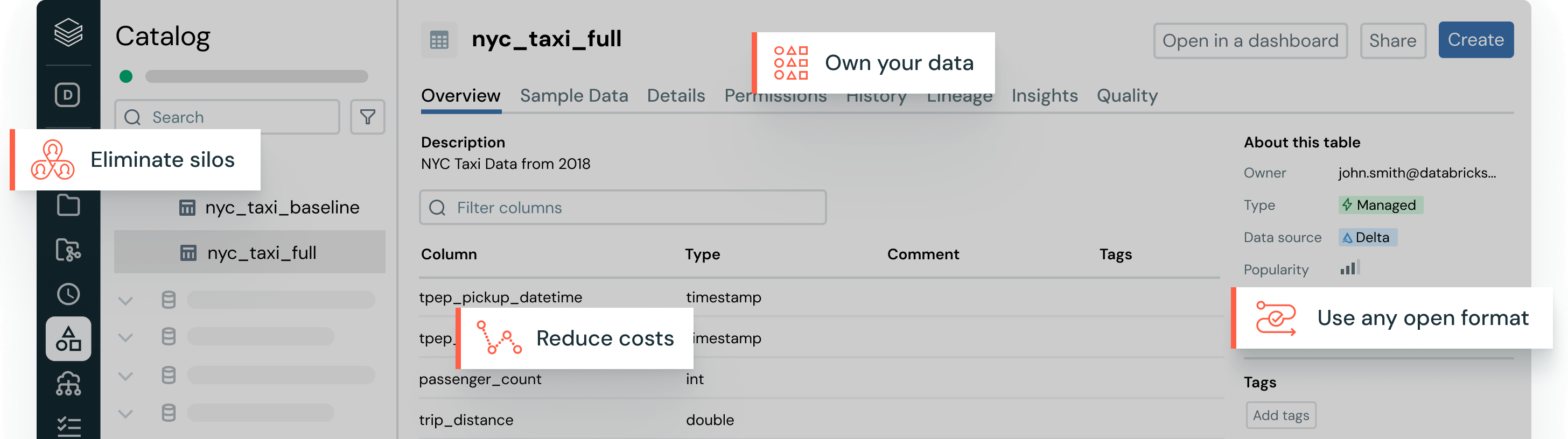
LES MEILLEURES ÉQUIPES RÉUSSISSENT AVEC LA DATA INTELLIGENCE
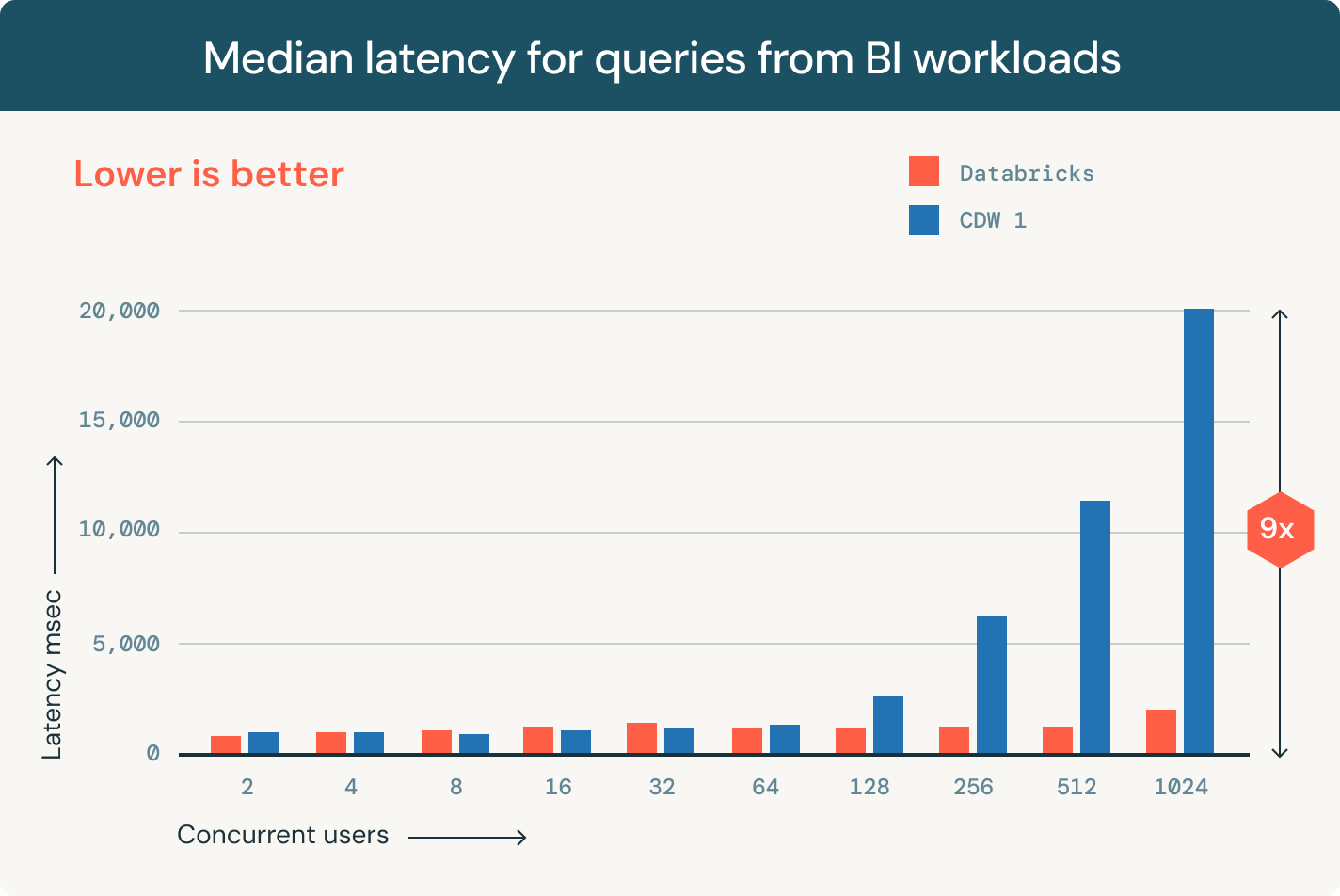
Stockage Lakehouse qui est flexible et rapide
Éliminez les maux de tête liés à la gestion des données avec des formats de table ouverts, une gouvernance centralisée et des optimisations de données automatiques.Formats compatibles
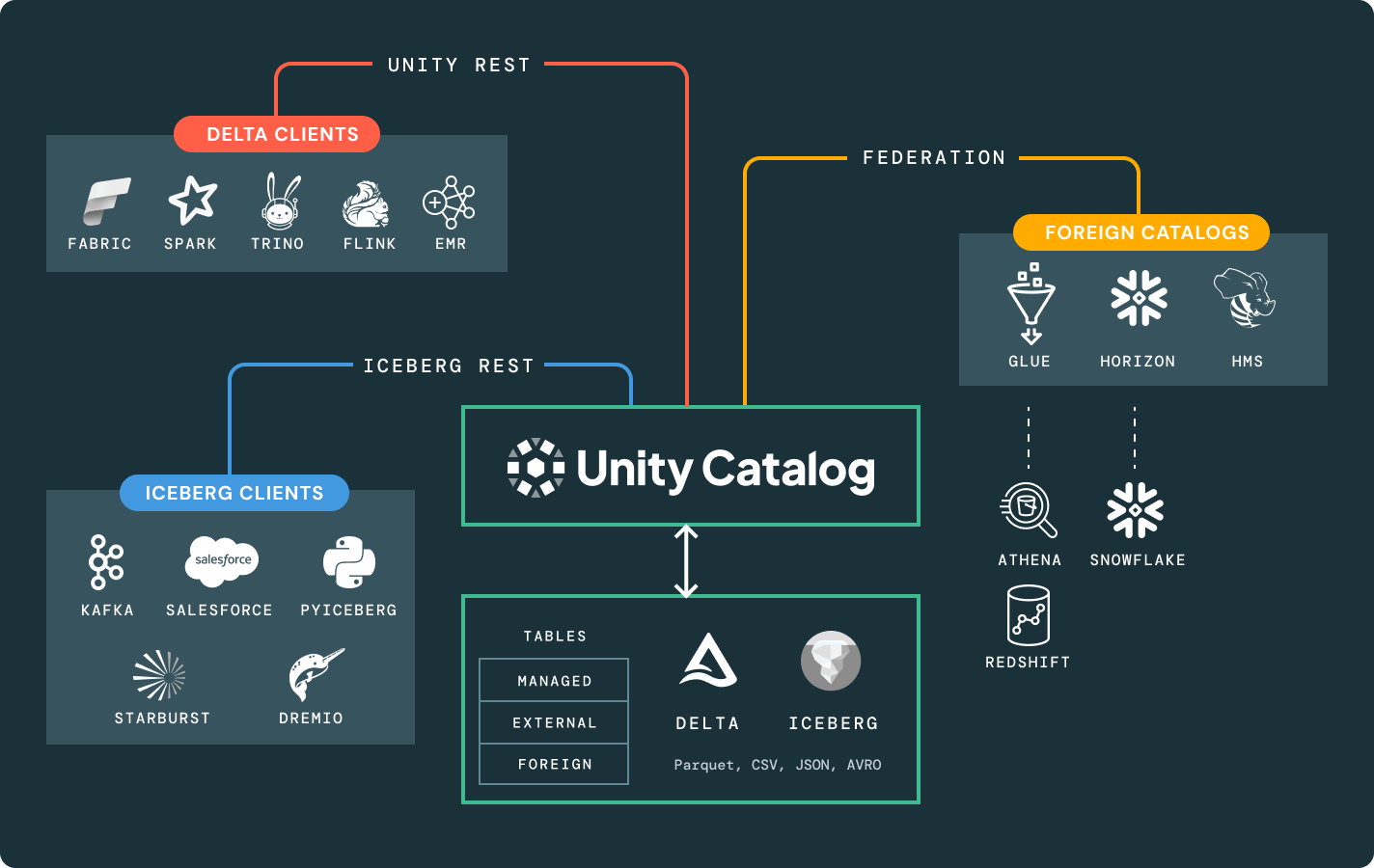
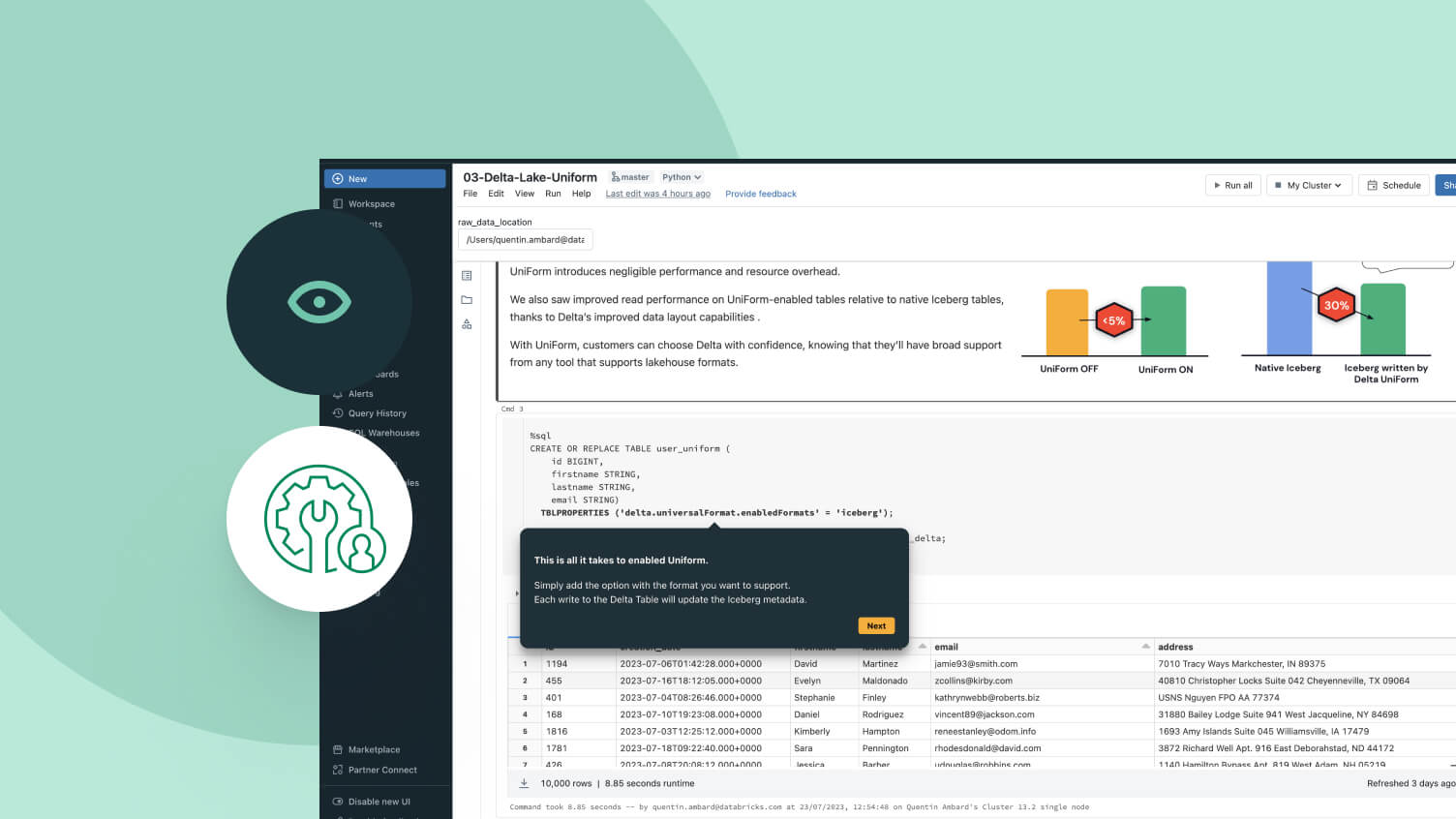
Une seule copie des données sources dans Delta Lake ou Apache Iceberg™ qui peut être accessible par n'importe quel moteur.
Gouvernance unifiée
Un seul catalogue pour la découverte de données et la gouvernance, à travers vos données et vos actifs d'IA.
L'IA au service de la performance
Les modèles alimentés par l'IA optimisent et maintiennent automatiquement les données pour une vitesse et un coût faibles.
Vos données, à votre manière
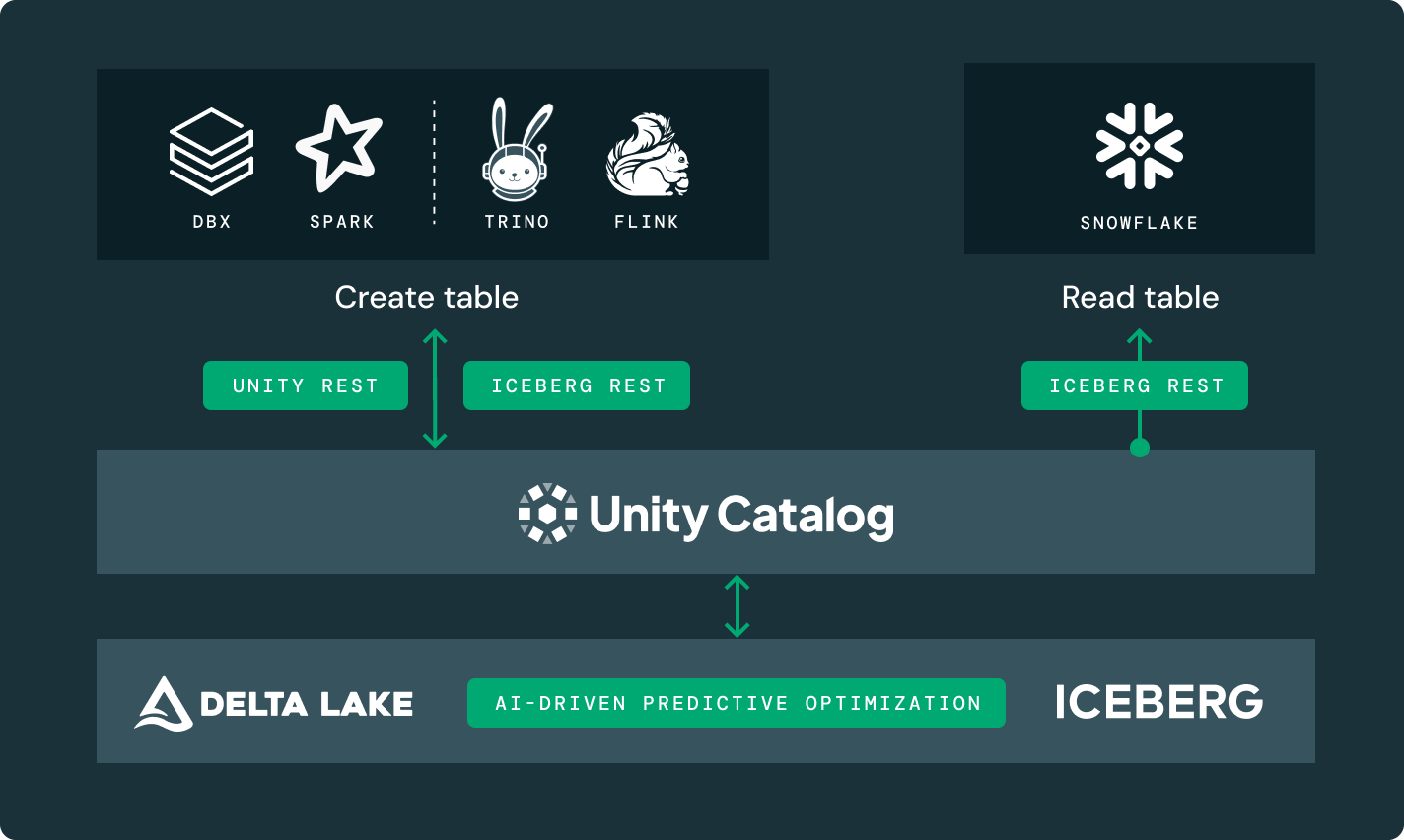
Choisissez l'emplacement de stockage et le format ouvert qui vous convient. Gardez vos données portables, sans être verrouillé par un fournisseur.Performance de lecture et d'écriture de premier ordre pour les tables Delta Lake et Apache Iceberg™, prêtes à l'emploi, avec des optimisations de stockage non disponibles dans n'importe quel autre lakehouse.
Autres fonctionnalités
Pour toutes vos charges de travail analytiques et d'IA

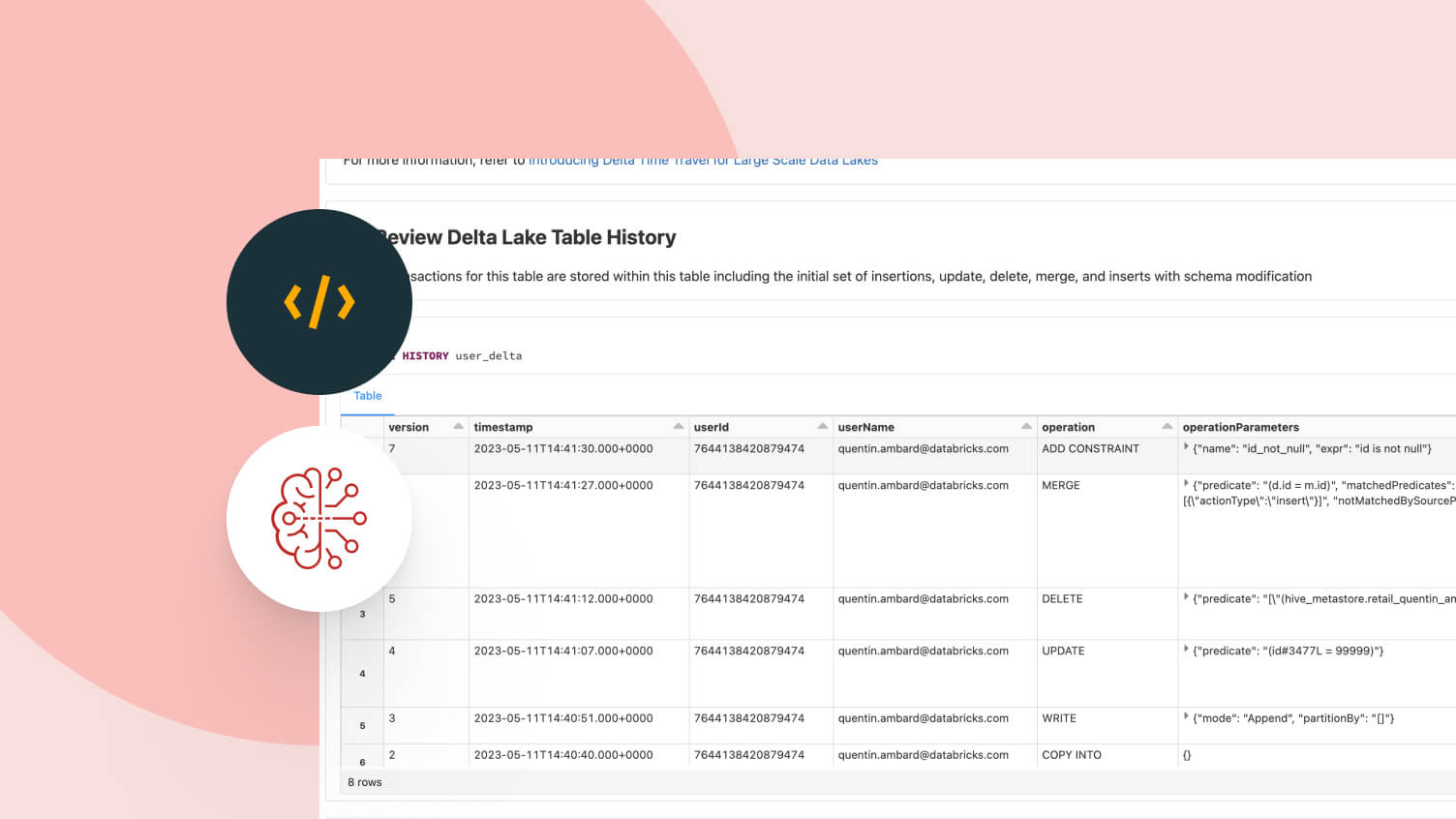
Construire et gérer des pipelines de données fiables
Les tables gérées agissent à la fois comme des tables de lots et une source et un puits de streaming. L'ingestion de données en streaming, le remplissage historique par batch et les requêtes interactives fonctionnent sans aucun effort supplémentaire, s'intégrant directement à Spark Structured Streaming.

Découvrez, gérez et partagez vos données et vos actifs d'IA
Découvrez comment la Databricks Data Intelligence Platform donne du pouvoir à vos équipes data sur l'ensemble de vos charges de travail de données et d'IA.
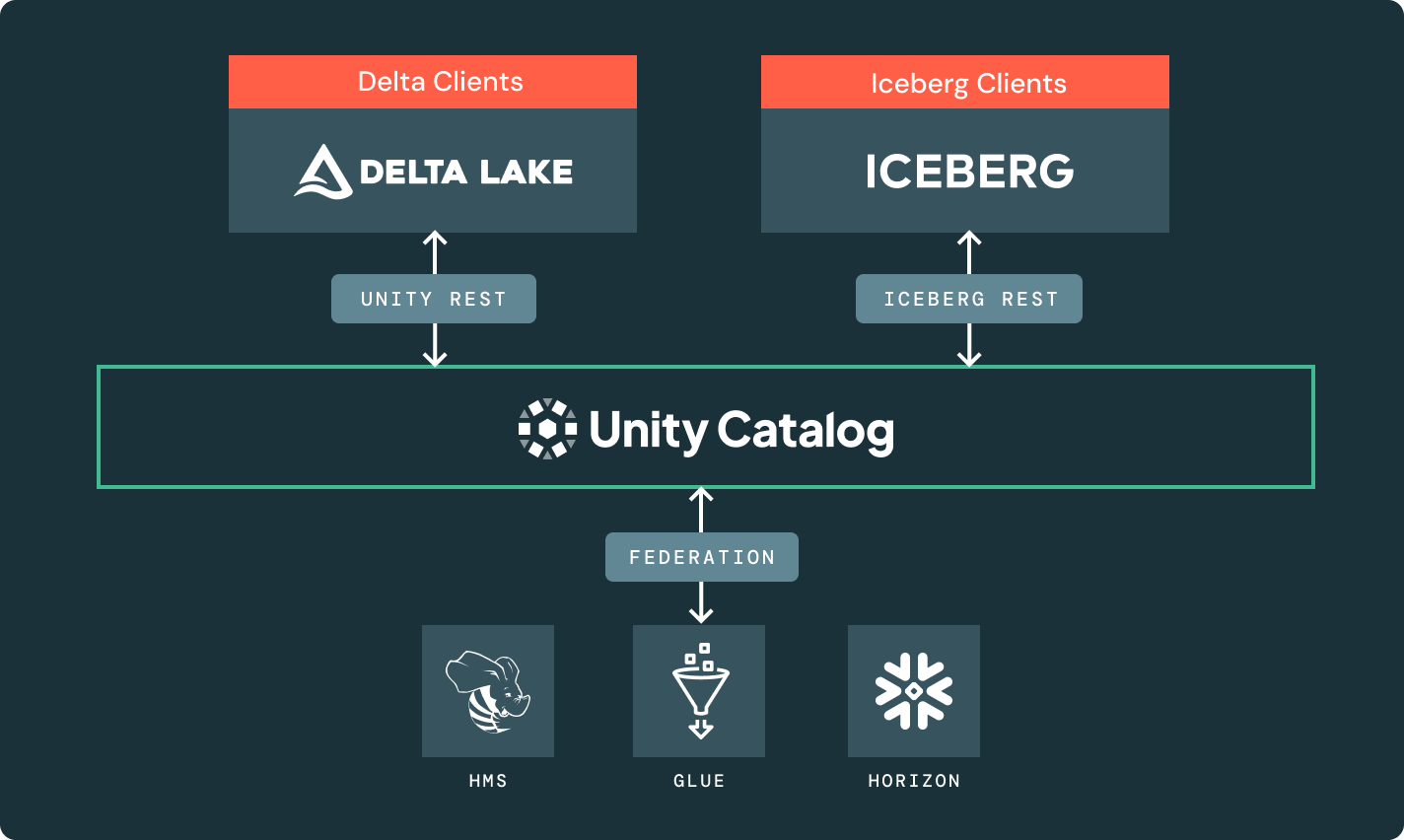
Unity Catalog
Directement intégré à la Data Intelligence Platform de Databricks, c'est la seule solution de gouvernance ouverte et unifiée pour les données et l'IA.

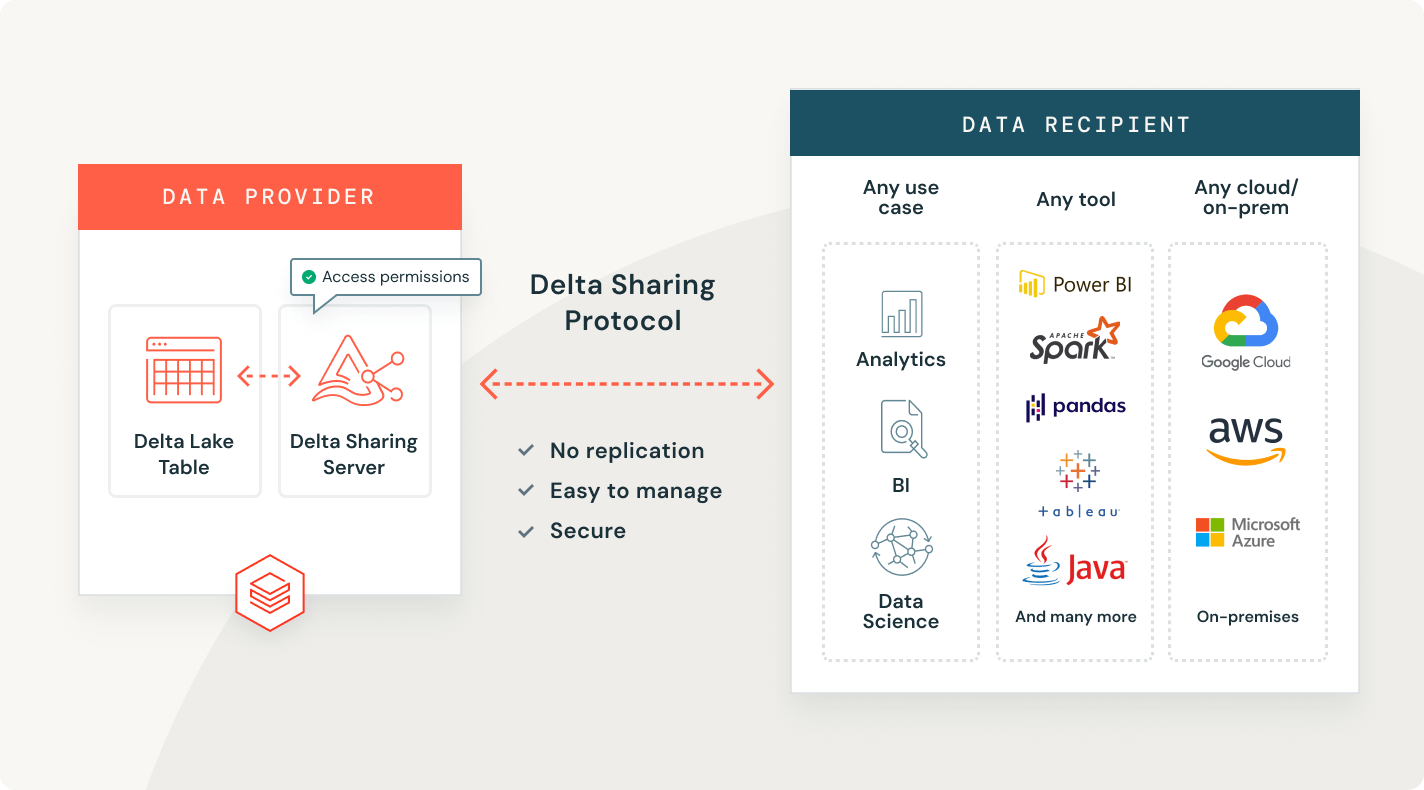
Delta Sharing
La première approche open source pour le partage de données à travers les données, l'analytique et l'IA. Partagez en toute sécurité des données en direct à travers des plateformes, des nuages et des régions.

Data Intelligence Platform
Explorez tout l'éventail des outils disponibles sur la Databricks Data Intelligence Platform pour intégrer les données et l'IA de toute votre organisation de façon fluide et transparente.
En savoir plus
Explorez nos documents
Tout ce dont vous avez besoin pour commencer à utiliser Delta Lake ou Iceberg dans Databricks, dans n'importe quel environnement.
Explorez le Regroupement Liquide
Apprenez à propos de la disposition flexible des données qui remplace les partitions de table et optimise les performances des requêtes.




FAQ sur le stockage Lakehouse
Prêts à devenir une entreprise axée sur les données et l'IA ?
Faites le premier pas de votre transformation