Évolution du schéma dans les opérations de fusion et métriques opérationnelles dans Delta Lake
Delta Lake 0.6.0 introduit l'évolution du schéma et des améliorations de performance dans les métriques de fusion et opérationnelles dans l'historique des tables
par Tathagata Das et Denny Lee
Obtenez un aperçu anticipé du nouveau livre blanc O'Reilly d' O'Reilly pour obtenir les instructions étape par étape dont vous avez besoin pour commencer à utiliser Delta Lake.
Essayez ce notebook pour reproduire les étapes décrites ci-dessous.
Nous avons récemment annoncé la sortie de Delta Lake 0.6.0, qui introduit l'évolution du schéma et des améliorations de performance dans les opérations de fusion (merge) et les métriques opérationnelles dans l'historique des tables. Les principales fonctionnalités de cette version sont :
- Prise en charge de l'évolution du schéma dans les opérations de fusion (#170) - Vous pouvez désormais faire évoluer automatiquement le schéma de la table avec l'opération de fusion. Ceci est utile dans les scénarios où vous souhaitez mettre à jour des données modifiées dans une table et que le schéma des données change avec le temps. Au lieu de détecter et d'appliquer les modifications de schéma avant la mise à jour, la fusion peut simultanément faire évoluer le schéma et mettre à jour les modifications.
- Amélioration des performances de fusion avec repartitionnement automatique (#349) - Lors de la fusion dans des tables partitionnées, vous pouvez choisir de repartitionner automatiquement les données par les colonnes de partition avant l'écriture dans la table. Dans les cas où l'opération de fusion sur une table partitionnée est lente car elle génère trop de petits fichiers (#345), l'activation du repartitionnement automatique (spark.delta.merge.repartitionBeforeWrite) peut améliorer les performances.
- Amélioration des performances lorsqu'il n'y a pas de clause d'insertion (#342) - Vous pouvez désormais obtenir de meilleures performances dans une opération de fusion si celle-ci ne contient pas de clause d'insertion.
- Métriques d'opération dans DESCRIBE HISTORY (#312) - Vous pouvez désormais voir les métriques d'opération (par exemple, le nombre de fichiers et de lignes modifiés) pour toutes les écritures, mises à jour et suppressions sur une table Delta dans l'historique de la table.
- Prise en charge de la lecture des tables Delta depuis n'importe quel système de fichiers (#347) - Vous pouvez désormais lire les tables Delta sur n'importe quel système de stockage avec une implémentation Hadoop FileSystem. Cependant, l'écriture dans les tables Delta nécessite toujours la configuration d'une implémentation LogStore qui offre les garanties nécessaires sur le système de stockage.
Évolution du schéma dans les opérations de fusion
Comme noté dans les versions précédentes de Delta Lake, Delta Lake inclut la capacité d'exécuter des opérations de fusion pour simplifier vos opérations d'insertion/mise à jour/suppression en une seule opération atomique, ainsi que la capacité d'appliquer et faire évoluer votre schéma (plus de détails peuvent également être trouvés dans ce tech talk). Avec la sortie de Delta Lake 0.6.0, vous pouvez désormais faire évoluer votre schéma au sein d'une opération de fusion.
Démontrons cela en utilisant un exemple pertinent ; vous pouvez trouver l'exemple de code original dans ce notebook. Nous commencerons avec un petit sous-ensemble du référentiel de données 2019 Novel Coronavirus COVID-19 (2019-nCoV) par Johns Hopkins CSSE que nous avons rendu disponible dans /databricks-datasets. C'est un jeu de données couramment utilisé par les chercheurs et les analystes pour obtenir un aperçu du nombre de cas de COVID-19 dans le monde. L'un des problèmes avec les données est que le schéma change avec le temps.
Par exemple, les fichiers représentant les cas de COVID-19 du 1er mars au 21 mars (au 30 avril 2020) ont le schéma suivant :
Mais les fichiers du 22 mars et suivants (au 30 avril) contenaient des colonnes supplémentaires, notamment FIPS, Admin2, Active et Combined_Key.
Dans notre exemple de code, nous avons renommé certaines colonnes (par exemple, Long_ -> Longitude, Province/State -> Province_State, etc.) car elles sont sémantiquement identiques. Au lieu de faire évoluer le schéma de la table, nous avons simplement renommé les colonnes.
Si la principale préoccupation était simplement de fusionner les schémas, nous pourrions utiliser la fonctionnalité d'évolution de schéma de Delta Lake en utilisant l'option « mergeSchema » dans DataFrame.write(), comme indiqué dans l'instruction suivante.
Mais que se passe-t-il si vous avez besoin de mettre à jour une valeur existante et de fusionner le schéma en même temps ? Avec Delta Lake 0.6.0, cela peut être réalisé avec l'évolution du schéma pour les opérations de fusion. Pour visualiser cela, commençons par examiner les anciennes données qui représentent une seule ligne.
Ensuite, simulons une entrée de mise à jour qui suit le schéma de new_data.
et fusionnons simulated_update et new_data avec un total de 40 lignes.
Nous avons défini le paramètre suivant pour configurer votre environnement pour l'évolution automatique du schéma :
Nous pouvons maintenant exécuter une opération atomique unique pour mettre à jour les valeurs (à partir du 21/03/2020) ainsi que pour fusionner le nouveau schéma avec l'instruction suivante.
Examinons la table Delta Lake avec l'instruction suivante :
Métriques Opérationnelles
Vous pouvez examiner de plus près les métriques opérationnelles en consultant l'historique de la table Delta Lake (colonne operationMetrics) dans l'interface utilisateur Spark en exécutant l'instruction suivante :
Ci-dessous, un aperçu résumé de la commande précédente.
Vous remarquerez deux versions de la table, une pour l'ancien schéma et une autre pour le nouveau schéma. En examinant les métriques opérationnelles ci-dessous, vous constaterez que 39 lignes ont été insérées et 1 ligne a été mise à jour.
Vous pouvez en apprendre davantage sur les détails de ces métriques opérationnelles en accédant à l'onglet SQL dans l'interface utilisateur Spark.
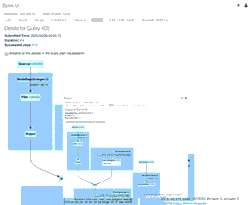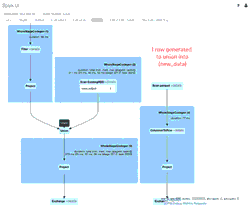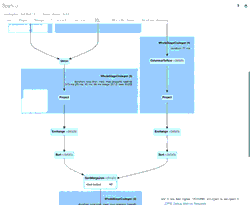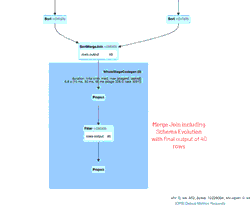
Le GIF animé met en évidence les principaux composants de l'interface utilisateur Spark pour votre examen.
- 39 lignes initiales provenant d'un fichier (pour le 11/04/2020 avec le nouveau schéma) qui ont créé le DataFrame new_data initial
- 1 ligne de mise à jour simulée générée qui serait unie au DataFrame new_data
- 1 ligne provenant du fichier (pour le 21/03/2020 avec l'ancien schéma) qui a créé le DataFrame old_data.
- Un SortMergeJoin utilisé pour joindre les deux DataFrames afin d'être persistés dans notre table Delta Lake.
Pour approfondir l'interprétation de ces métriques opérationnelles, consultez la conférence Diving into Delta Lake Part 3: How do DELETE, UPDATE, and MERGE work tech talk.

Commencer avec Delta Lake 0.6.0
Essayez Delta Lake avec les extraits de code précédents sur votre instance Apache Spark 2.4.5 (ou supérieure) (sur Databricks, essayez ceci avec DBR 6.6+). Delta Lake rend vos data lakes plus fiables (que vous en créiez un nouveau ou que vous migriez un data lake existant). Pour en savoir plus, consultez https://delta.io/, et rejoignez la communauté Delta Lake via Slack et le Google Group. Vous pouvez suivre toutes les prochaines versions et fonctionnalités prévues dans les jalons GitHub. Vous pouvez également essayer Delta Lake géré sur Databricks avec un compte gratuit.
Crédits
Nous souhaitons remercier les contributeurs suivants pour les mises à jour, les modifications de documentation et les contributions à Delta Lake 0.6.0 : Ali Afroozeh, Andrew Fogarty, Anurag870, Burak Yavuz, Erik LaBianca, Gengliang Wang, IonutBoicuAms, Jakub Orłowski, Jose Torres, KevinKarlBob, Michael Armbrust, Pranav Anand, Rahul Govind, Rahul Mahadev, Shixiong Zhu, Steve Suh, Tathagata Das, Timothy Zhang, Tom van Bussel, Wesley Hoffman, Xiao Li, chet, Eugene Koifman, Herman van Hovell, hongdd, lswyyy, lys0716, Mahmoud Mahdi, Maryann Xue
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.