Apache Spark
Che cos'è Apache Spark?
Apache Spark è un motore di analisi open-source utilizzato per carichi di lavoro Big Data. È in grado di gestire l'analisi e l'elaborazione dei dati sia in batch sia in tempo reale. Apache Spark è nato nel 2009 come progetto di ricerca presso l'Università di Berkeley, in California con l'obiettivo di trovare un modo per velocizzare l'elaborazione dei dati nei sistemi Hadoop. Apache Spark si basa su Hadoop MapReduce e ne estende il modello per utilizzarlo in modo efficiente durante altri tipi di operazioni, incluse query interattive ed elaborazione di flussi di dati. Spark offre binding nativi per i linguaggi di programmazione Java, Scala, Python e R. Inoltre, include diverse librerie per supportare la creazione di applicazioni per il machine learning [MLlib], l'elaborazione di dati in streaming [streaming Spark] e l'elaborazione di grafici [GraphX]. Apache Spark è composto da Spark Core e da una serie di librerie. Spark Core è il cuore di Apache Spark ed è responsabile della trasmissione distribuita dei task, della pianificazione e delle funzionalità di I/O. Il motore Spark Core utilizza Resilient Distributed Dataset (RDD) come tipo di dati sottostante. L'RDD è progettato in modo da nascondere la maggior parte della complessità computazionale agli utenti. Spark opera sui dati in modo intelligente; dati e partizioni vengono aggregati su un cluster di server, dove possono essere elaborati e successivamente spostati in un altro archivio di dati o eseguiti attraverso un modello analitico. Non è necessario che l'utente specifichi la destinazione dei file o le risorse di calcolo da utilizzare per archiviarli o recuperarli. 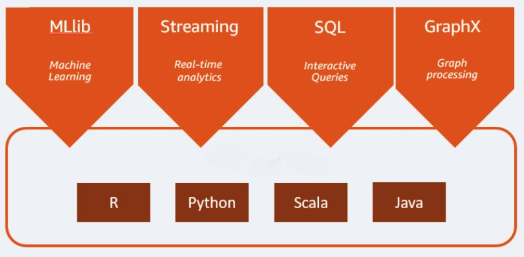
Ecco altre informazioni utili



Quali sono i vantaggi di Apache Spark?
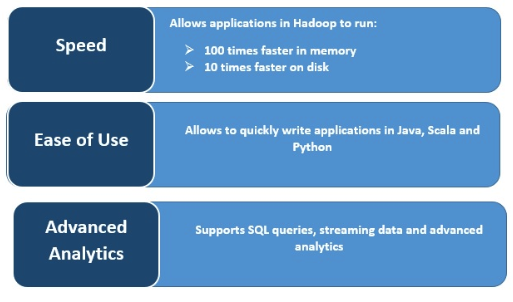
Velocità
Spark velocizza l'elaborazione memorizzando i dati nella cache per riutilizzarli in più operazioni parallele. La caratteristica principale di Spark è il suo motore in-memory che aumenta la velocità di elaborazione, rendendolo fino a 100 volte più veloce di MapReduce nell'elaborazione in-memory e 10 volte più veloce in quella su disco, quando si tratta di elaborare dati su larga scala. Spark ottiene questo risultato riducendo il numero di operazioni di lettura/scrittura su disco.
Elaborazione di dati in streaming in tempo reale
Apache Spark può gestire lo streaming in tempo reale insieme all'integrazione di altri framework. Spark acquisisce i dati in piccoli batch ed esegue trasformazioni RDD su di essi.
Supporta carichi di lavoro multipli
Apache Spark può eseguire molteplici carichi di lavoro, tra cui query interattive, analisi in tempo reale, machine learning ed elaborazione di grafici. Una sola applicazione può combinare più carichi di lavoro senza soluzione di continuità.
Maggiore usabilità
La capacità di supportare diversi linguaggi di programmazione lo rende dinamico e permette di scrivere rapidamente applicazioni in Java, Scala, Python e R, offrendo una varietà di linguaggi per la creazione di applicazioni.
Analisi avanzate
Spark supporta query SQL, machine learning, elaborazione in streaming ed elaborazione di grafici.