Pipeline di dati affidabili semplificate
Semplifica i processi ETL in batch e streaming con affidabilità automatizzata e qualità dei dati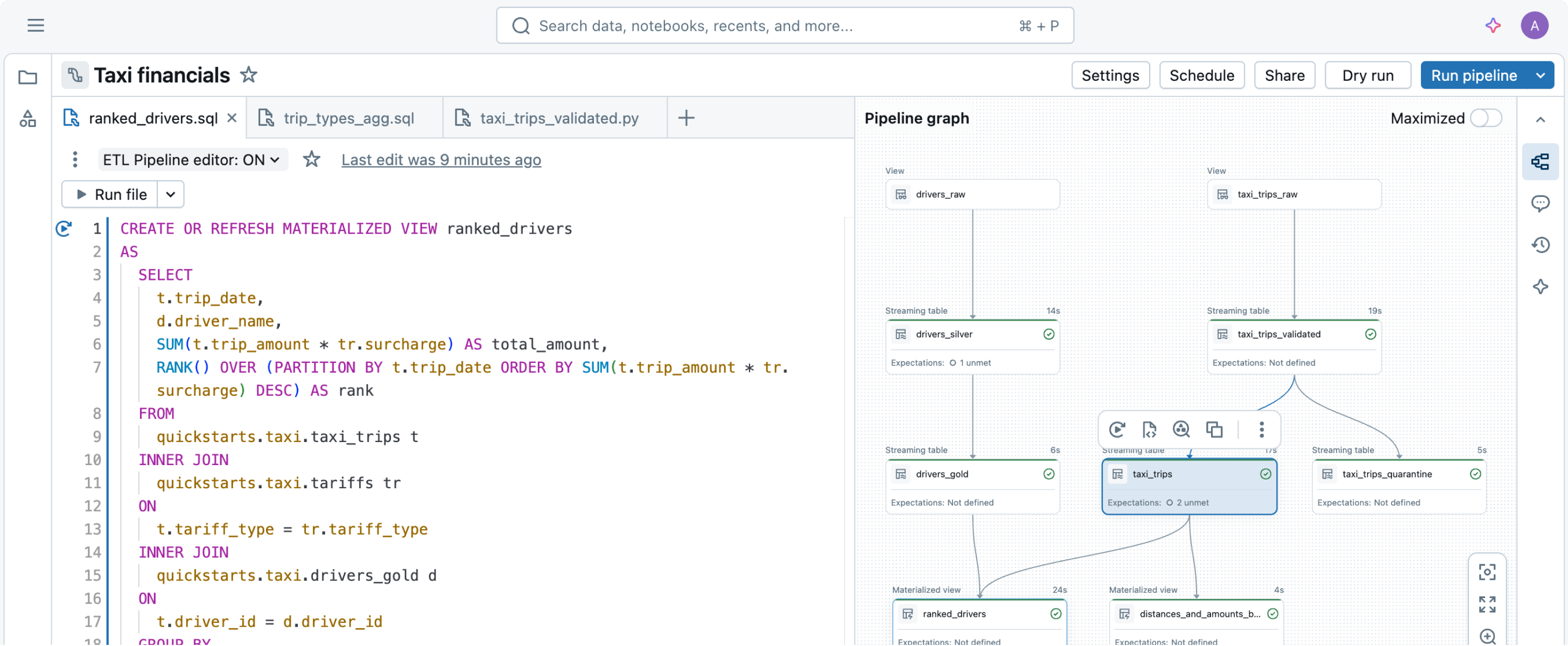
IL SUCCESSO DEI MIGLIORI TEAM POGGIA SU PIPELINE DI DATI INTELLIGENTI
Le best practice per le pipeline di dati, codificate
Dichiara semplicemente le trasformazioni dei dati di cui hai bisogno e lascia che Spark Declarative Pipelines si occupi del resto.Acquisizione efficiente
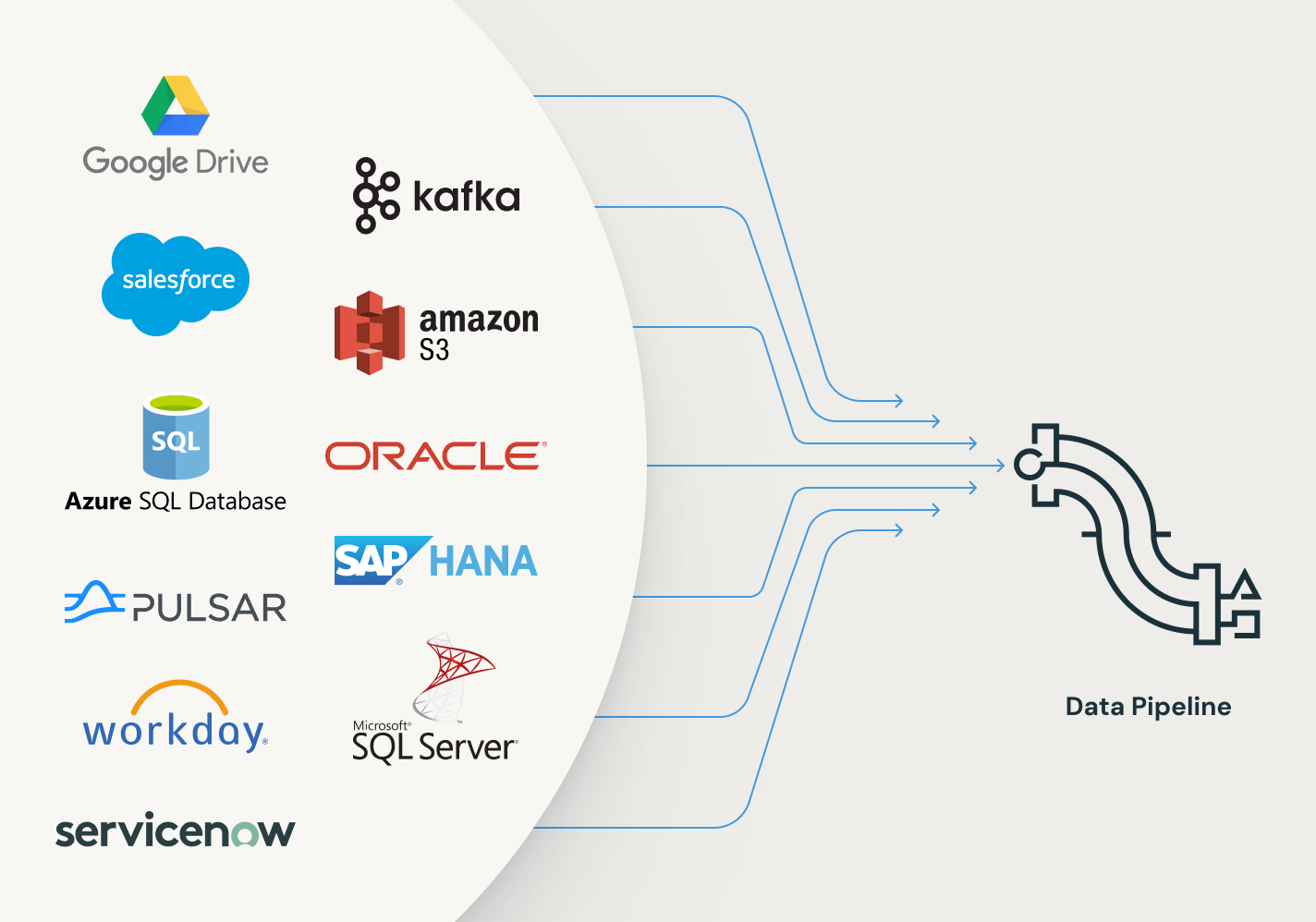
La costruzione di pipeline ETL pronte per la produzione comincia con l'acquisizione dei dati. Spark Declarative Pipelines consente un'acquisizione efficiente a data engineer, sviluppatori in Python, data scientist e analisti SQL. Carica dati da qualsiasi sorgente supportata da Apache Spark™ su Databricks, in batch, streaming o CDC.
Trasformazione intelligente
Con poche righe di codice, Spark Declarative Pipelines riesce a determinare il modo più efficiente per costruire ed eseguire pipeline di dati in batch o in streaming, ottimizzando automaticamente in base al costo o alle prestazioni e riducendo al minimo la complessità.
Operazioni automatizzate
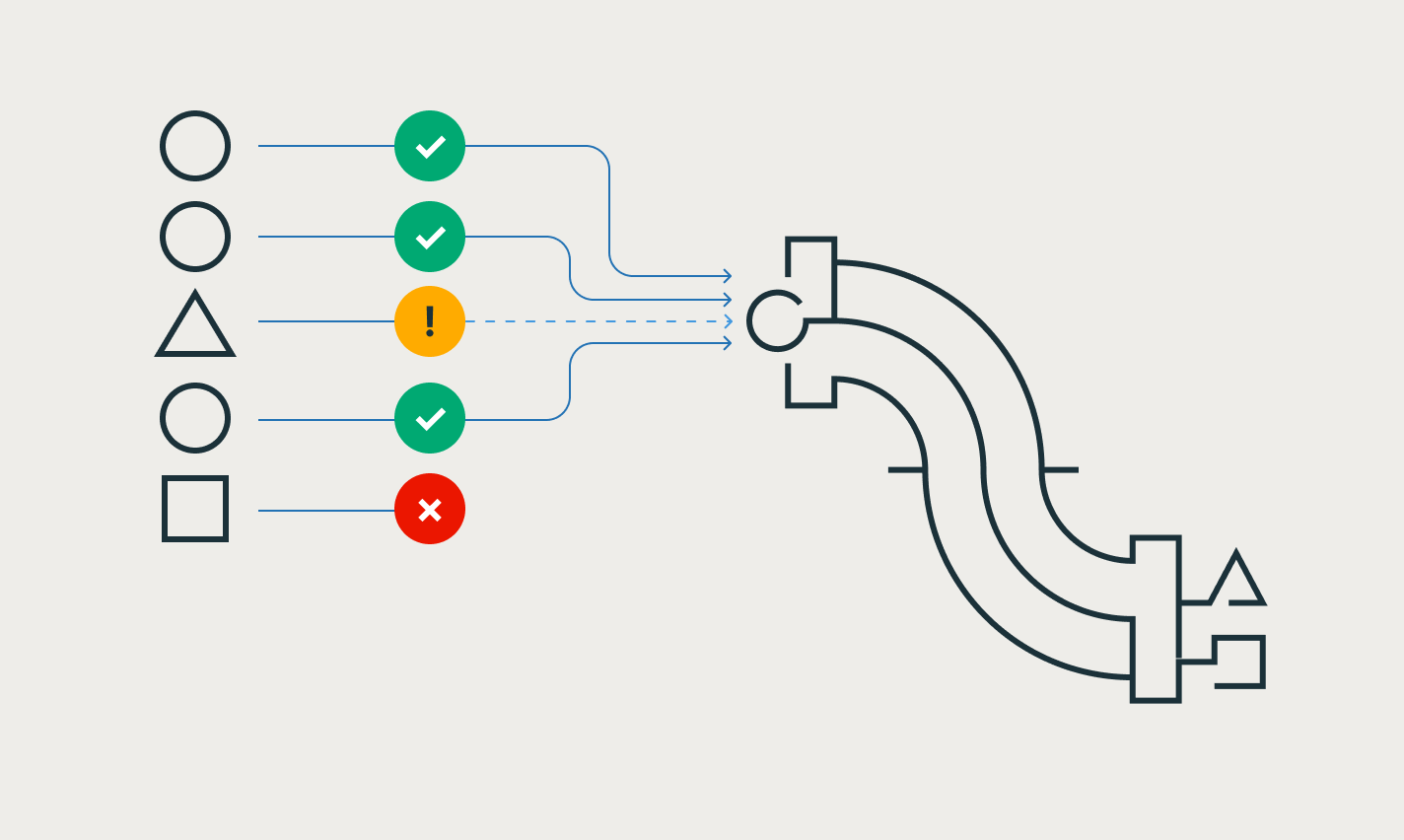
Spark Declarative Pipelines semplifica lo sviluppo di processi ETL codificando le best practice fin dall'inizio e automatizzando le complessità operative. Grazie a Spark Declarative Pipelines, i tecnici possono concentrarsi sull'obiettivo di fornire dati di alta qualità invece di doversi preoccupare di gestire e manutenere l'infrastruttura delle pipeline.
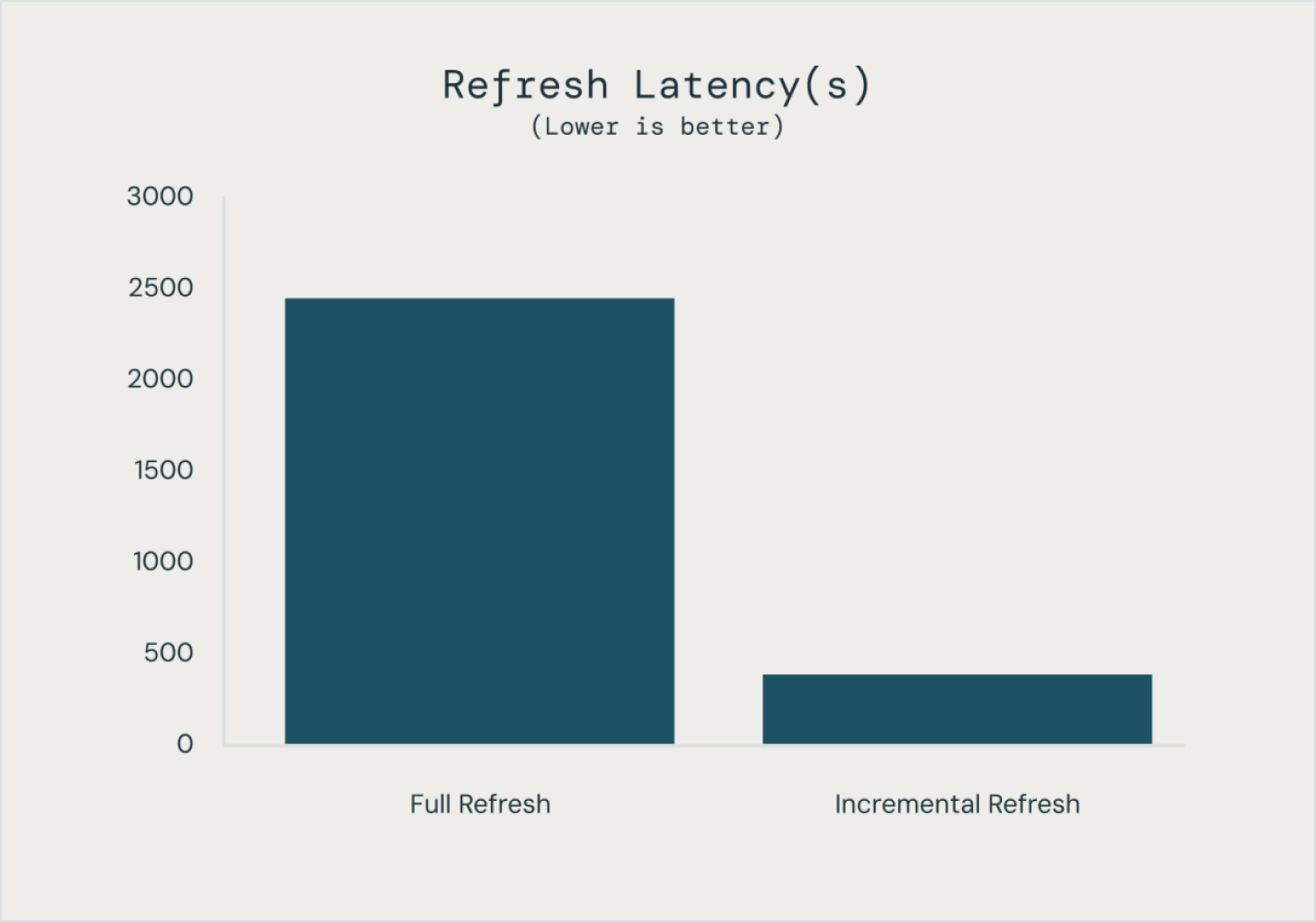
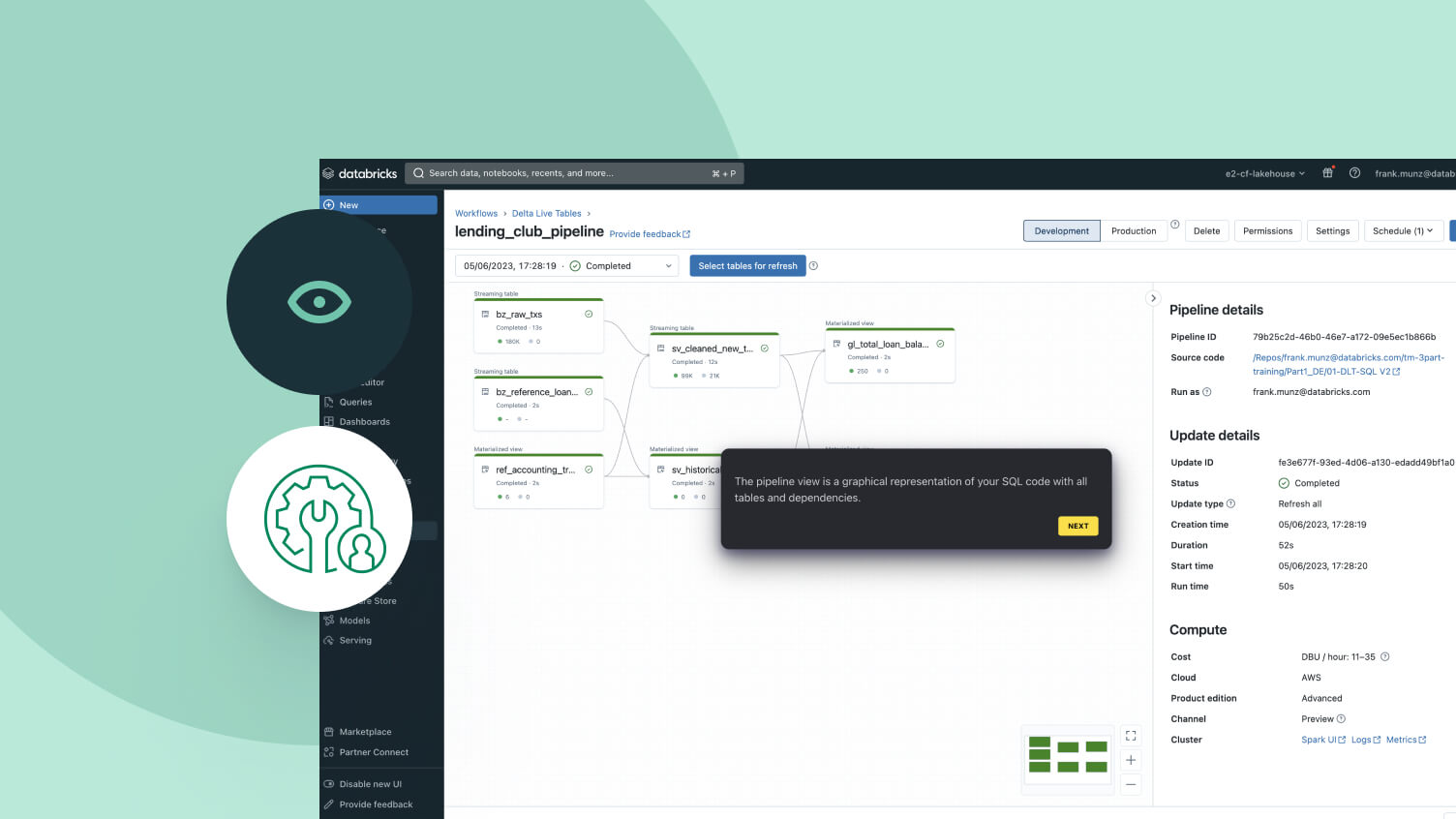
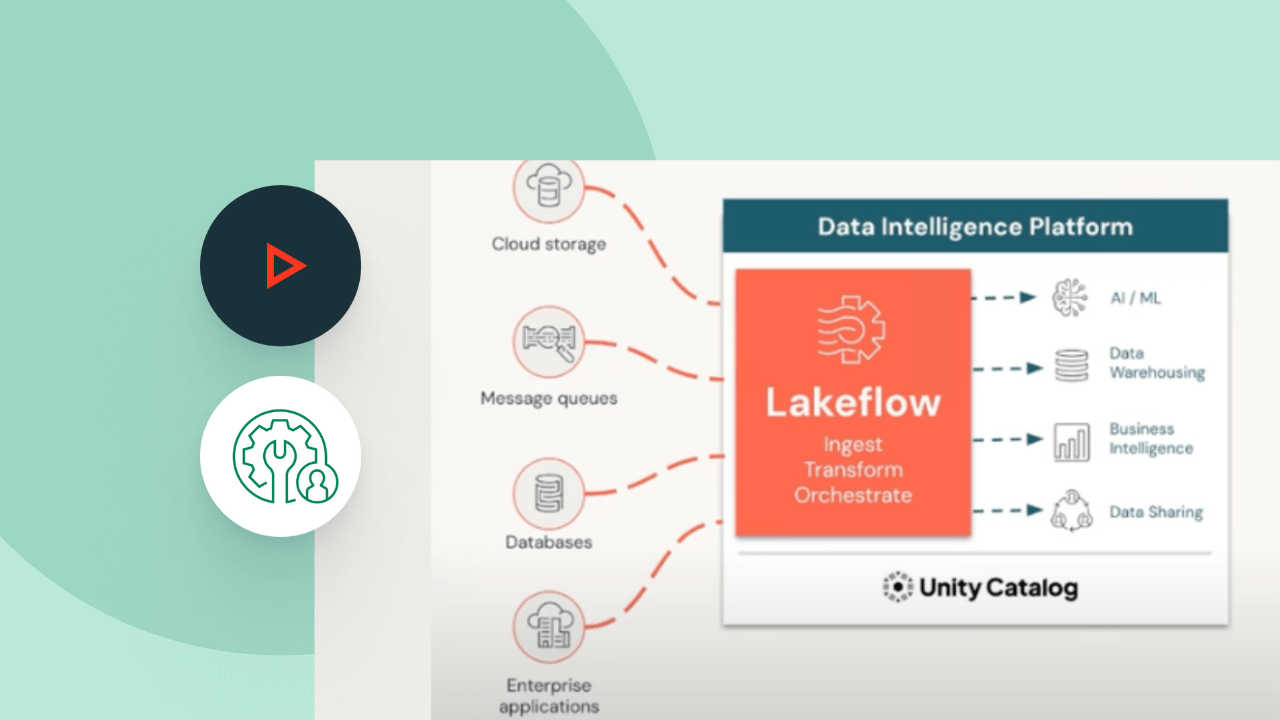
Costruito per semplificare il pipelining dei dati
Costruire e gestire pipeline di dati non deve necessariamente essere difficile. Spark Declarative Pipelines è stato progettato per combinare potenza e semplicità, così da consentirti di eseguire robusti processi ETL con appena qualche riga di codice.Sfruttando l'API unificata di Spark per l'elaborazione sia in batch che in streaming, Spark Declarative Pipelines permette di passare facilmente da una modalità di elaborazione all'altra.

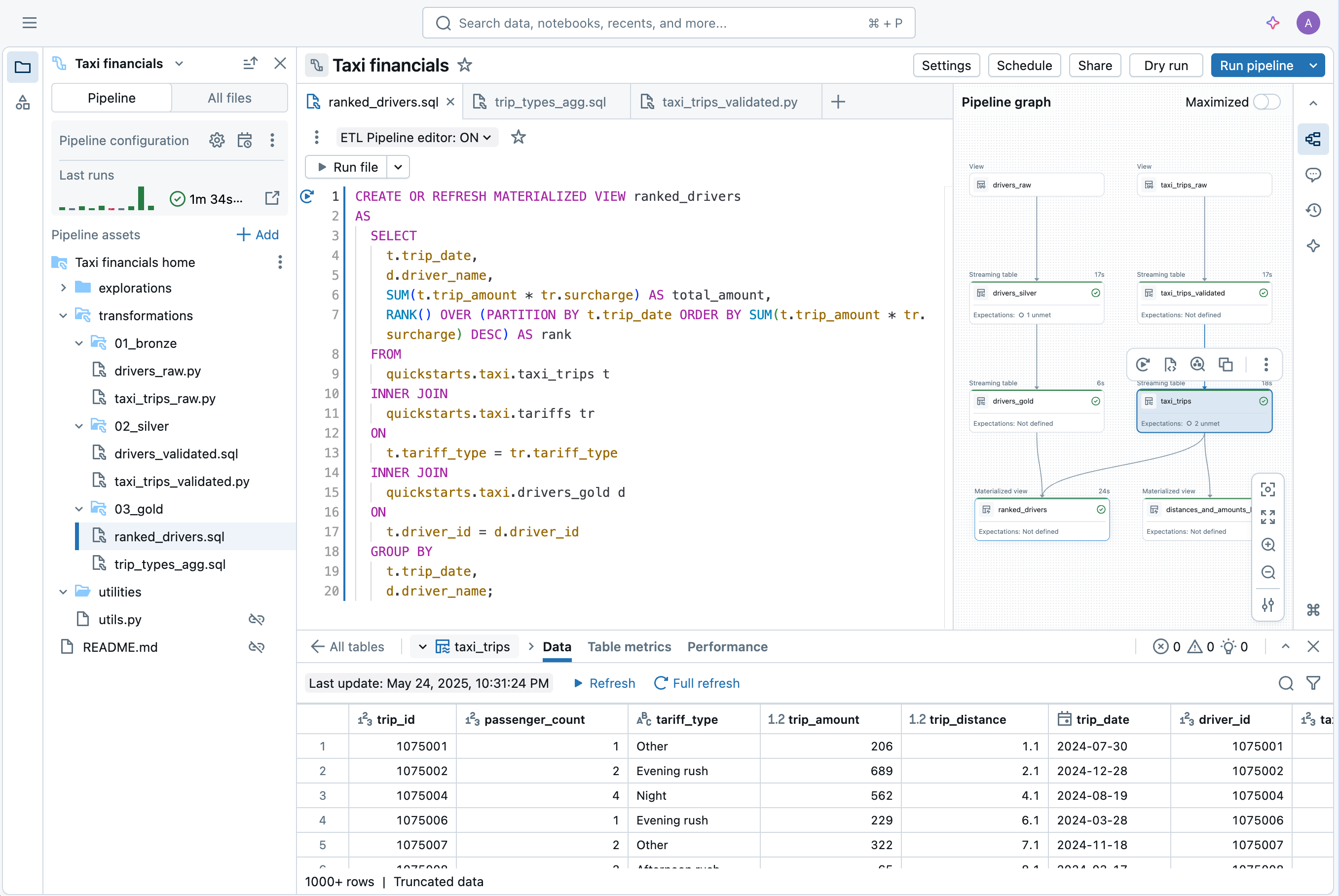
Altre funzioni
Semplifica le tue pipeline di dati

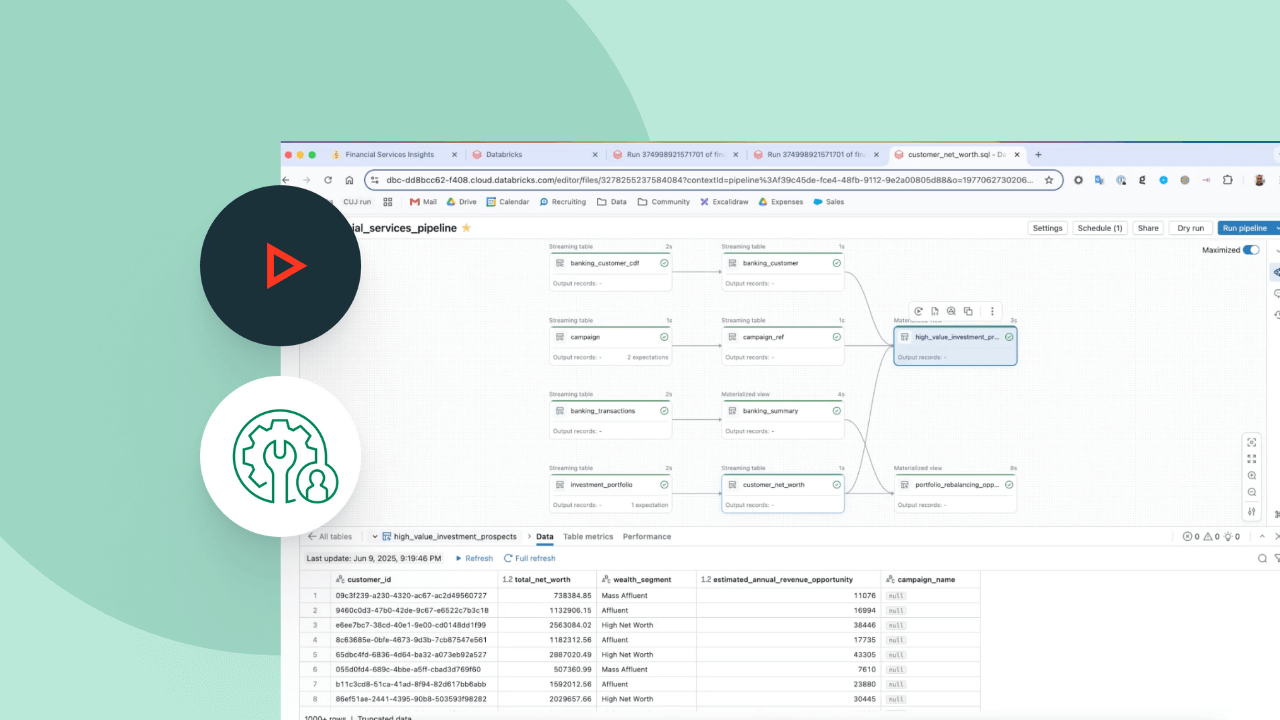
Garantisci facilmente l'integrità e la coerenza dei dati
Semplifica l'acquisizione delle modifiche con le API APPLY CHANGES per feed di dati di modifica e snapshot del database. Spark Declarative Pipelines gestisce automaticamente i record fuori sequenza per SCD Tipo 1 e 2, semplificando le parti più complesse della CDC.
Sblocca potenti casi d'uso in tempo reale senza strumenti aggiuntivi
Le pipeline in batch e in streaming possono essere costruite ed eseguite in un unico luogo, con impostazioni di aggiornamento controllabili e automatizzate, risparmiando tempo e riducendo la complessità operativa. Rendi operativo lo streaming dei dati per migliorare immediatamente la precisione e la fruibilità di analisi e AI.
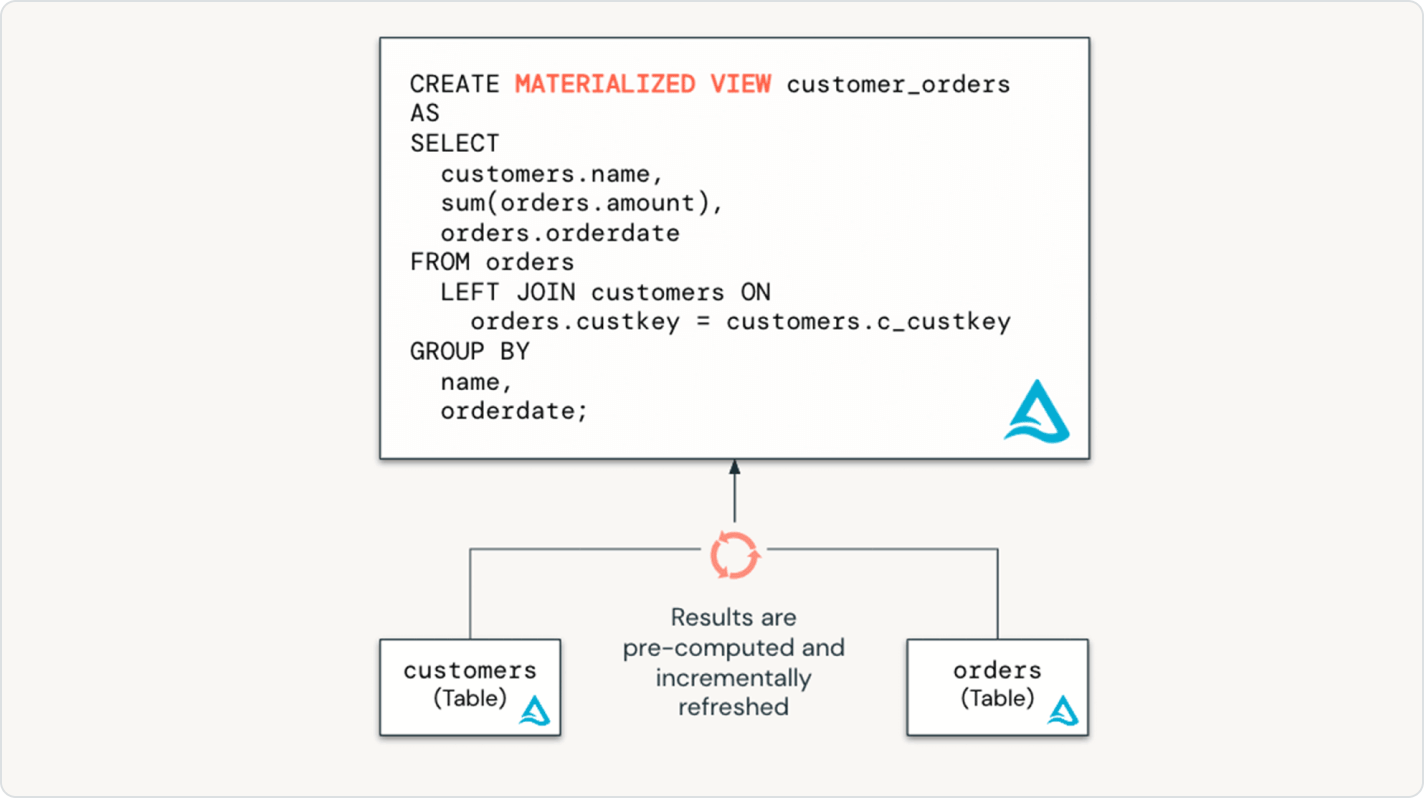
Porta facilmente le best practice del data engineering nel mondo del data warehousing
Con Spark Declarative Pipelines, gli utenti del data warehouse possono attingere a tutto il potere dell'ETL dichiarativo tramite un'interfaccia SQL accessibile. Offri ai tuoi analisti SQL pipeline di dati low-code e senza infrastruttura, sbloccando dati aggiornati per l'azienda con un minimo di configurazione o dipendenze.
I prezzi basati sull'utilizzo tengono sotto controllo la spesa
Si pagano solo i prodotti utilizzati e conteggiati al secondo.Scopri di più
Esplora altre offerte integrate e intelligenti sulla Data Intelligence Platform.
LakeFlow Connect
Connettori efficienti per l'acquisizione di dati da qualsiasi fonte e integrazione nativa con la Data Intelligence Platform facilitano l'accesso all'analisi e all'AI, con una governance unificata.

Job di Lakeflow
Definisci, gestisci e monitora facilmente flussi di lavoro multitasking per pipeline di ETL, analisi e machine learning. Grazie a un'ampia gamma di tipologie di task supportati, funzioni di osservabilità approfondita e alta affidabilità, i team di gestione dei dati saranno in grado di automatizzare e orchestrare meglio qualsiasi pipeline e diventare più produttivi.

Archiviazione nel lakehouse
Unifica i dati nel tuo lakehouse, di qualunque formato e tipo, per tutti i tuoi carichi di lavoro di analisi e AI.

Unity Catalog
Gestisci tutti i tuoi asset di dati con l'unica soluzione di governance unificata e aperta del settore per dati e AI, integrata nella Databricks Data Intelligence Platform.
La Data Intelligence Platform
Scopri come la Databricks Data Intelligence Platform abilita i tuoi carichi di lavoro di dati e AI.
Fai il passo successivo
Contenuti associati




FAQ SU Spark Declarative Pipelines
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il percorso di trasformazione