メインコンテンツへジャンプ
![4 Personas Analytics AIBI 6]()
回復力のある分散データセット (RDD) とは何ですか?
分散型、フォールトトレラントな並列処理のための Spark の基本的なデータ構造を理解する

Summary
- RDDとは何か、そしてApache Sparkにおける並列処理のための不変かつパーティション化されたデータコレクションとしてRDDがどのように機能するのかを理解します。
- 非構造化データや低レベルの変換制御など、RDDが最適な選択肢となる5つの主要なシナリオを学習します。
- RDDとDataFrameおよびDatasetの関係、そして各APIをいつ使用するかを探ります。
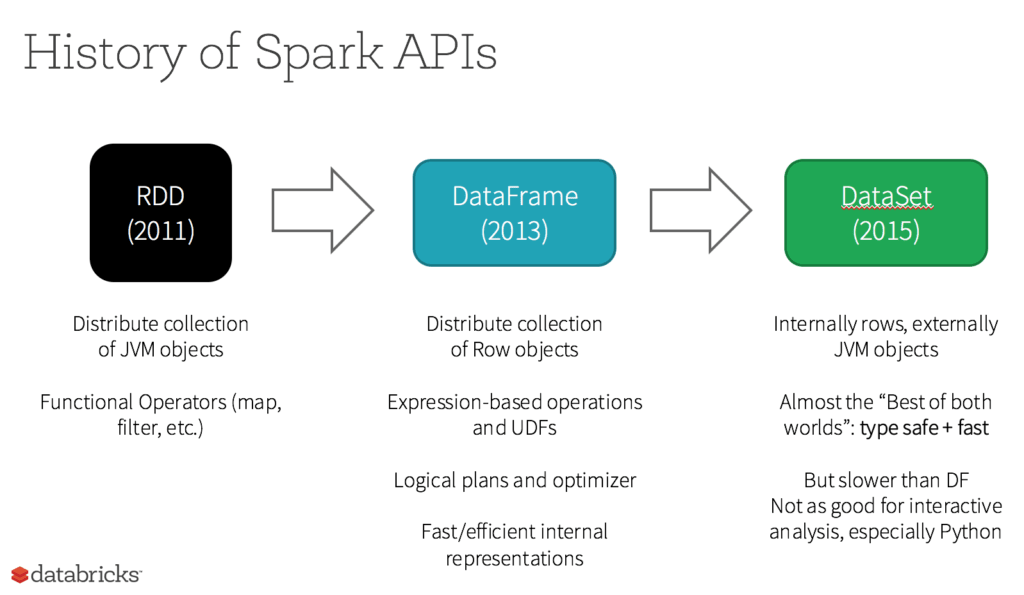
耐障害性分散データセット(RDD)とは、Spark のリリース以降、Spark の主要なユーザー向け API として利用されてきました。RDD は、クラスタ内の複数のノードに配置されたデータ要素の不変の集合体であり、変換その他の操作のための基礎的な API と並行して使用することが可能です。
RDD の使用が適した 5 つのケース
- データセットに対し、低レベルの変換やアクション、管理を実行する場合
- 所有データがメディアストリームやテキストストリームなどの非構造化データである場合
- ドメイン固有言語ではなく、関数型プログラミングでデータを処理する場合
- 名前や列によるデータ属性の処理や、アクセスの際に、列指向フォーマットなどのスキーマの指定を厭わない場合
- 構造化・半構造�化データに対する DataFrames や Datasets の最適化機能や性能を必要としない場合
レポート
エンタープライズ向けエージェントAIプレイブック

Apache Spark 2.0 における RDD の役割
RDD が不要になり、廃止されることはありません。さらに言うと、DataFrame や Dataset と RDD の間では、シンプルな API メソッドを呼び出すことによりシームレスな移動が可能で、DataFrame や Dataset は、RDD を基盤としています。
関連資料
Databricksの投稿を見逃さないようにしましょう
興味のあるカテゴリを購読し��て、最新の投稿を受信トレイに届けましょう