머신 러닝 모델(Machine Learning Model)
머신 러닝 모델이란 무엇입니까?
머신 러닝 모델이란 이전에 접한 적 없는 데이터 세트에서 패턴을 찾거나 이를 근거로 결정을 내릴 수 있는 프로그램입니다. 예를 들어 자연어 처리의 경우, 머신 러닝 모델은 파싱을 통해 이전에 접한 적 없는 문장이나 단어 조합의 배후 의도를 올바로 인식할 수 있습니다. 이미지 인식의 경우, 머신 러닝 모델이 자동차나 개 등 사물을 인식하도록 교육할 수 있습니다. 머신 러닝 모델은 대규모 데이터 세트로 '교육'하면 이러한 작업을 수행할 수 있게 됩니다. 교육을 하면서 머신 러닝 알고리즘이 데이터 세트에서 특정 패턴이나 출력(작업 종류에 따라)을 찾아내도록 최적화합니다. 이 프로세스의 출력물은 대개 특정 규칙과 데이터 구조를 포함한 컴퓨터 프로그램의 형태를 띠는데, 이것을 머신 러닝 모델이라고 합니다.
자세히 보기


머신 러닝 알고리즘이란 무엇입니까?
머신 러닝 알고리즘은 일련의 데이터에서 패턴을 찾기 위한 수학적인 방식입니다. 머신 러닝 알고리즘은 대개 통계, 미적분, 선형 대수에서 도출합니다. 머신 러닝의 보편적인 예를 들자면 선형 회귀, 결정 트리, 랜덤 포레스트와 XGBoost 등이 있습니다.
머신 러닝에서 모델 훈련이란 무엇입니까?
어느 데이터 세트(이를 교육 데이터라 함)에서 머신 러닝 알고리즘을 수행하고 이 알고리즘을 특정 패턴이나 출력을 찾게 최적화하는 프로세스를 모델 훈련이라고 합니다. 그 결과로 도출된, 규칙과 데이터 구조를 포함한 함수를 훈련된 머신 러닝 모델이라고 합니다.
머신 러닝의 여러 가지 유형으로는 어떤 것이 있습니까?
전반적으로, 대부분의 머신 러닝 기법은 지도학습, 비지도학습과 강화학습으로 분류할 수 있습니다.
지도학습 머신 러닝이란 무엇입니까?
지도학습 머신 러닝의 경우, 알고리즘에 입력 데이터 세트가 제공되며 특정 출력 세트에 부합하도록 보상이 주어지거나 최적화됩니다. 예를 들어 지도학습 머신 러닝은 이미지 인식에 광범위하게 활용되는데, 이 경우 분류라는 기법을 활용합니다. 지도학습 머신 러닝은 인구 성장이나 건강 지표와 같은 인구통계 예측에도 쓰이며, 이 경우 회귀라는 기법을 활용합니다.
비지도학습 머신 러닝이란 무엇입니까?
지도학습 머신 러닝의 경우, 알고리즘에 입력 데이터 세트는 제공하지만 특정 출력으로 보상되거나 최적화되지는 않고, 그 대신 공통된 특징에 따라 개체를 그룹으로 묶도록 교육합니다. 예컨대 온라인 매장의 추천 엔진은 비지도학습 머신 러닝, 그중에서��도 특히 클러스터링이라는 기법을 주로 이용합니다.
강화학습 머신 러닝이란 무엇입니까?
강화학습(reinforcement learning)의 경우, 알고리즘이 수많은 시행착오 실험을 통해 자체적으로 훈련하도록 설정됩니다. 강화학습은 알고리즘이 훈련 데이터에 의존하는 것이 아니라 주변 환경과 계속 상호작용을 주고받을 때 일어납니다. 강화학습의 가장 보편적인 예시가 바로 자율 주행입니다.
여러 가지 머신 러닝 모델의 예를 들면 어떤 것이 있습니까?
머신 러닝 모델에도 여러 가지 종류가 있으며, 거의 전부가 특정 머신 러닝 알고리즘 기반입니다. 보편적인 분류와 회귀 알고리즘은 지도학습(Supervised) 머신 러닝에 속하며, 클러스터링 알고리즘은 대개 비지도학습(unsupervised) 머신 러닝 시나리오로 배포됩니다.
지도학습 머신 러닝
- 로지스틱 회귀: 로지스틱 회귀(Logistic Regression)는 어느 입력이 특정 그룹에 속하는지 아닌지 판단하는 데 쓰입니다.
- SVM: SVM, 즉 서포트 벡터 머신(Support Vector Machine)은 n차원 공간에서 각 개체의 좌표를 만들고, 초평면을 사용해 여러 개체를 공통된 특징에 따라 그룹으로 묶습니다.
- Naive Bayes: Naive Bayes는 변수 간에 비종속성이 성립한다고 가정하고 확률을 사용해 기능에 따라 개체를 분류하는 알고리즘입니다.
- 결정 트리: 결정 트리도 분류자의 일종으로, 트리의 리프와 노드를 횡단 이동하면서 입력이 어느 카테고리에 속하는지 판단하는 데 사용됩니다.
- 선형 회귀: 선형 회귀는 관심사와 입력 변수 사이의 관계를 파악하고, 입력 변수 값에 따라 그 값을 예측하는 데 쓰입니다.
- kNN: k Nearest Neighbors 기법은 가장 가까운 개체를 하나의 데이터 세트로 그룹화한 다음 개체 중에서 가장 자주 나타나거나 평균적인 특징을 찾아내는 것 위주입니다.
- 랜덤 포레스트(Random Forest): 랜덤 포레스트(Random forest)는 무작위 데이터 하위 집합에서 가져온 수많은 결정 트리를 모은 컬렉션입니다. 따라서 결정 트리 하나만 사용할 때보다 좀 더 정확한 예측을 내놓을 수 있는 트리 조합이 생깁니다.
- Boosting 알고리즘: Gradient Boosting Machine, XGBoost와 LightGBM 등의 Boosting 알고리즘은 앙상블 학습을 사용합니다. 이 알고리즘은 여러 알고리즘(예: 결정 트리)에서 가져온 예측을 조합하되, 이전 알고리즘에서 발생한 오류를 고려합니다.
비지도학습 머신 러닝
- K-Means: K-Means 알고리즘은 여러 개체의 유사상을 찾아 이를 K개의 서로 다른 클러스터로 그룹화합니다.
- 계층적 클러스터링: 계층적 클러스터링의 경우 클러스터 수를 지정할 필요 없이 중첩된 클러스터 트리를 구축합니다.
머신 러닝(ML)에서 결정 트리란 무엇입니까?
결정 트리란 ML에서 어느 개체가 어느 클래스에 속하는지 판단하는 데 사용하는 예측 방식입니다. 이름에서 알 수 있듯이, 결정 트리는 일종의 나무 모양 순서도 형태를 띠며, 몇 가지 알려진 조건을 사용해 단계별로 개체의 클래스를 결정하게 됩니다.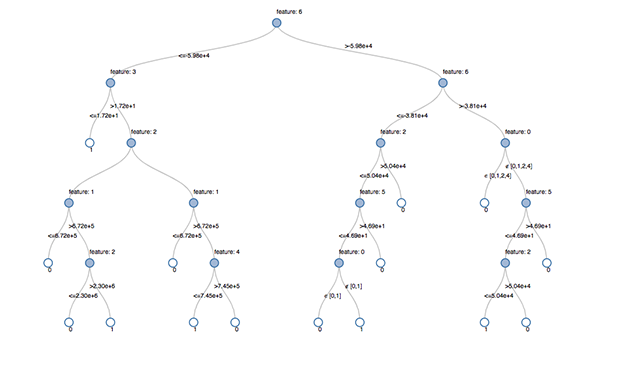 Databricks 레이크하우스에 표시한 결정 트리. 출처: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Databricks 레이크하우스에 표시한 결정 트리. 출처: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
머신 러닝에서 회귀란 무엇입니까?
데이터 사이언스와 머신 러닝에서 회귀란 일련의 입력 변수를 근거로 결과를 예측하게 해주는 통계적인 방식을 말합니다. 여기서 도출된 결과는 보통 여러 입력 변수의 조합에 따라 달라집니다.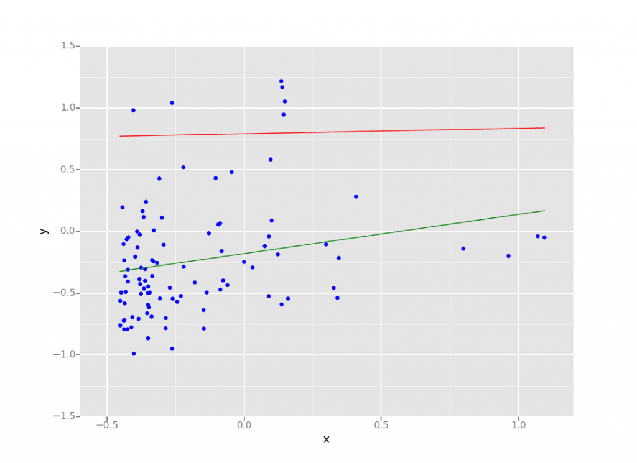 Databricks 레이크하우스에서 수행한 선형 회귀 모델. 출처: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Databricks 레이크하우스에서 수행한 선형 회귀 모델. 출처: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
머신 러닝에서 분류자란 무엇입니까?
분류자란 어느 개체를 카테고리나 그룹의 구성원으로 할당하는 머신 러닝 알고리즘입니다. 예를 들어 분류자를 사용하여 이메일이 스팸인지 아닌지, 트랜잭션이 사기 행위인지 아닌지 탐지할 수 있습니다.
머신 러닝 모델은 몇 개나 됩니까?
많습니다! 머신 러닝은 지금도 발전 중인 분야이며, 개발 중인 머신 러닝 모델은 계속 늘어나고 있습니다.
머신 러닝에 가장 좋은 모델은 무엇입니까?
특정 상황에 가장 적합한 머신 러닝 모델은 바람직한 결과가 무엇이냐에 따라 다릅니다. 예를 들어 어느 도시에서 과거 데이터를 바탕으로 차량 구매 �수를 예측하려 하는 경우, 선형 회귀와 같은 지도학습 기법이 가장 유용할 수 있습니다. 반면 이 도시의 어느 잠재 고객이 차량을 구매할지 그 고객의 소득과 통근 기록에 따라 결과를 알아보고자 하는 경우, 결정 트리가 가장 효과적일 수 있습니다.
머신 러닝(ML)에서 모델 배포란 무엇입니까?
모델 배포는 테스트나 프로덕션 목적으로 대상 환경에서 사용할 수 있는 머신 러닝 모델을 제공하는 프로세스를 말합니다. 이 모델은 보통 API를 통해 환경 내 다른 애플리케이션(예: 데이터베이스, UI 등)과 통합하게 됩니다. 배포는 기업에서 모델 배포에 거액을 투자한 후 실제로 수익을 낼 수 있는 단계를 말합니다.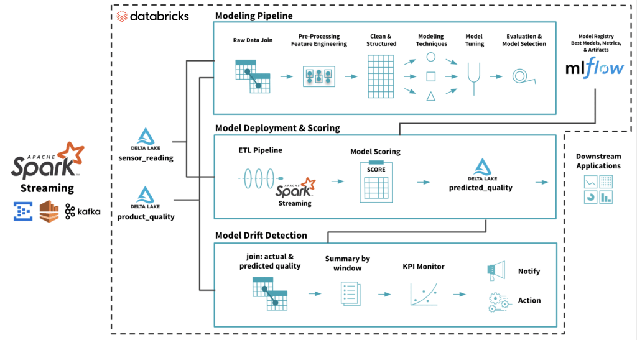 Databricks 레이크하우스의 머신 러닝 모델 수명 주기 전체. 출처: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Databricks 레이크하우스의 머신 러닝 모델 수명 주기 전체. 출처: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
딥러닝 모델이란 무엇입니까?
딥러닝 모델은 ML 모델의 한 집단으로, 사람이 정보를 처리하는 방식을 모방하는 모델입니다. 이 모델은 여러 개의 처리 계층으로 구성되어 있어(그래서 '딥(심층)'이라는 말을 씀) 제공된 데이터로부터 간략한 특징을 추출합니다. 각각의 처리 계층이 다음 계층에 점점 더 추상적으로 표현한 데이터를 전달하고, 마지막 계층에서 좀 더 사람에 가까운 인사이트를 제공하는 것입니다. 데이터�를 레이블링해야 하는 기존 ML과는 달리 딥러닝 모델은 대량의 비구조적 데이터를 수집할 줄 압니다. 이 모델은 얼굴 인식이나 자연어 처리와 같은, 좀 더 사람의 능력과 닮은 기능을 수행하는 데 사용됩니다. 간단하게 나타낸 딥러닝. 출처: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
간단하게 나타낸 딥러닝. 출처: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
시계열 머신 러닝이란 무엇입니까?
시계열 머신 러닝 모델의 경우, 독립된 변수 중 하나가 연속된 시간 길이(분, 일, 년 등)이며 이것이 종속된 변수나 예측된 변수에 의미를 지니는 모델입니다. 시계열 머신 러닝 모델은 다가오는 어느 주의 날씨, 다음 어느 달의 예상 고객 수, 다음 어느 해 매출 지표 등 시간이 제한된 이벤트를 예측하는 데 쓰입니다.