LAKEHOUSE 저장소
오픈하고, 지능적인 데이터 저장을 위해 구축되었습니다.
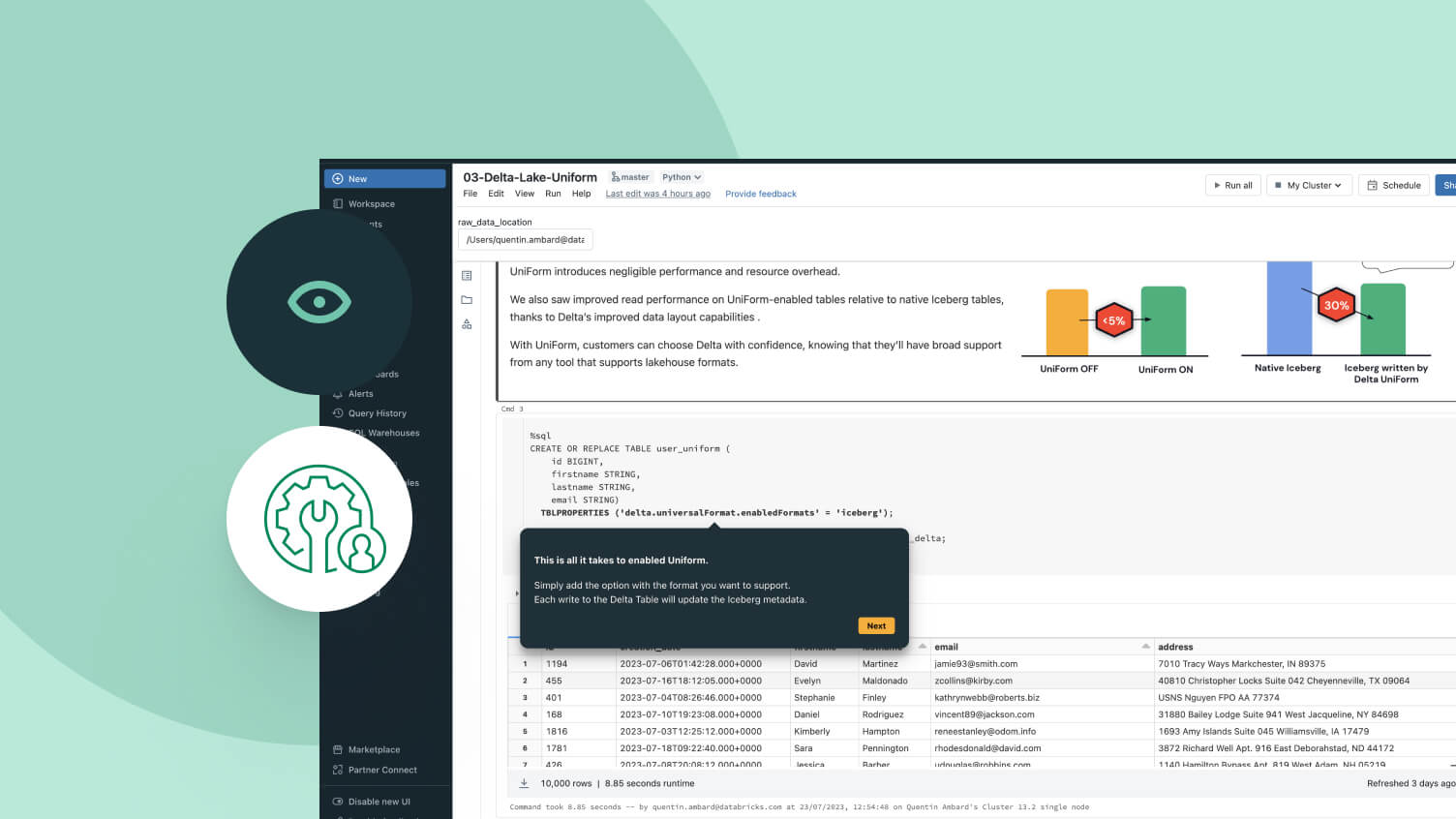
당신의 데이터를 완전히 소유하고 이동할 수 있도록 저장 위치와 형식을 선택하세요.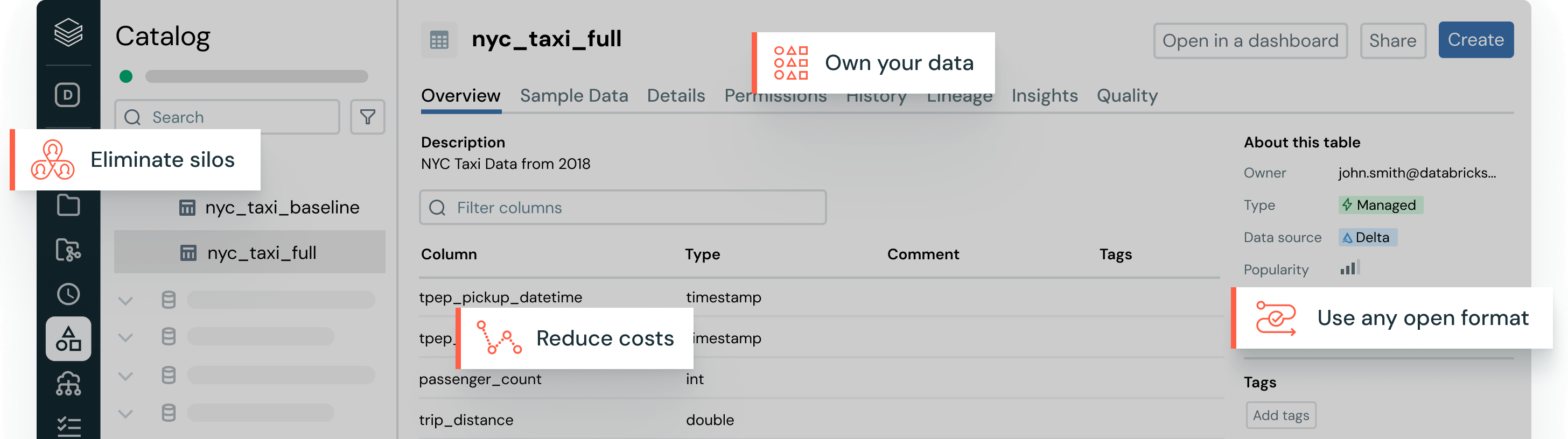
TOP 팀들은 데이터 인텔리전스로 성공합니다
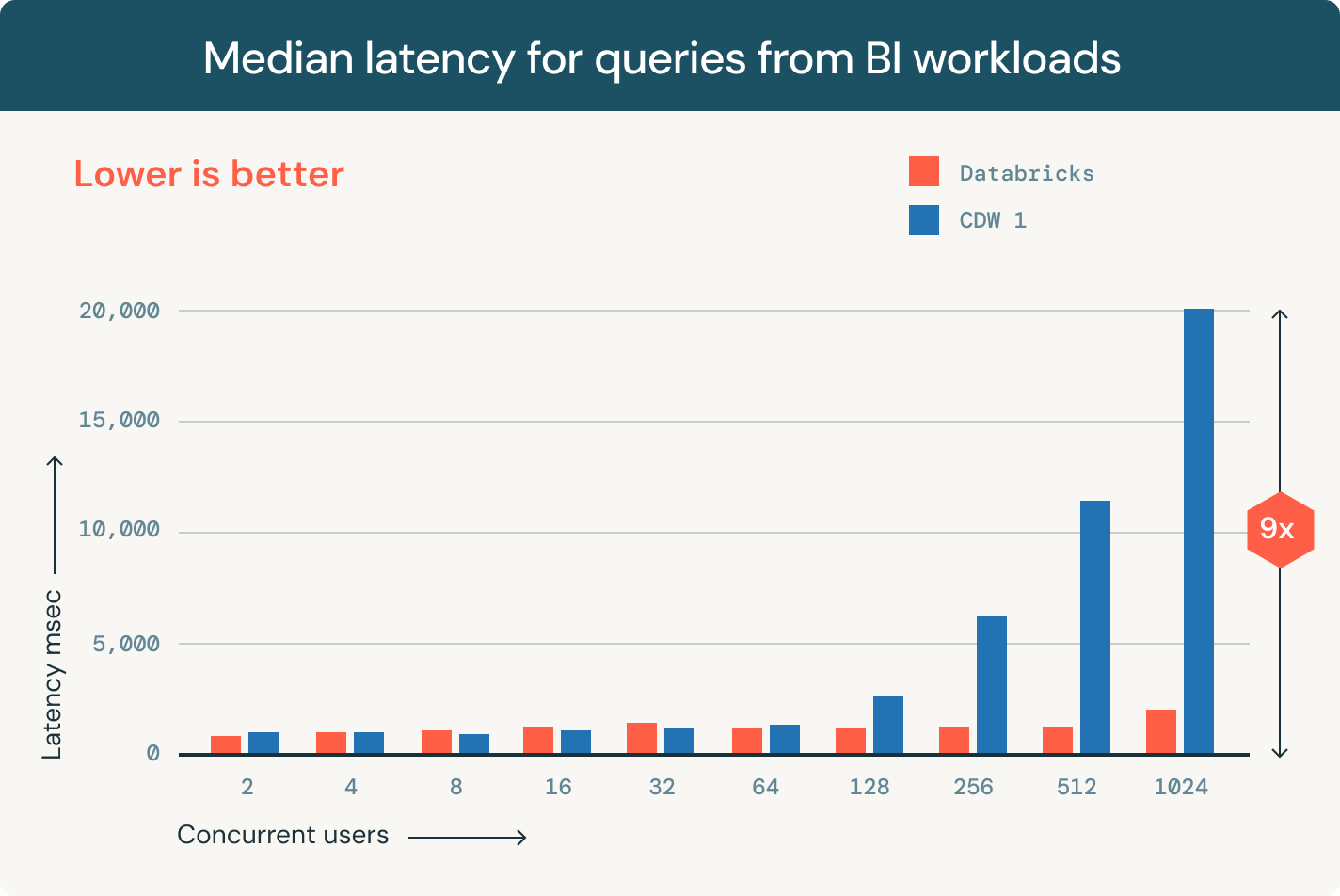
유연하고 빠른 Lakehouse 저장소
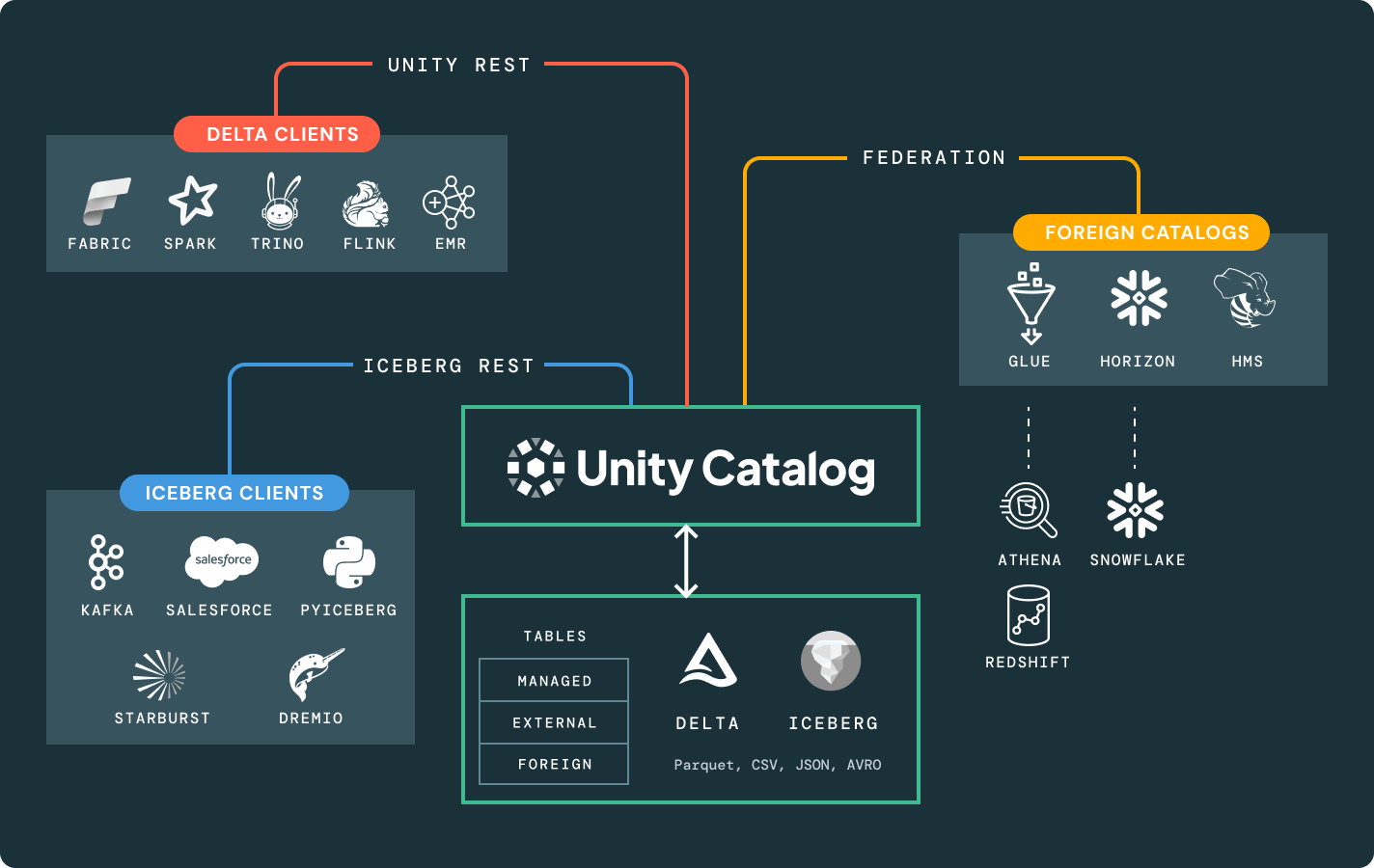
오픈 테이블 형식, 중앙화된 거버넌스 및 자동 데이터 최적화를 통해 데이터 관리의 고민을 해결하세요.호환 가능한 형식
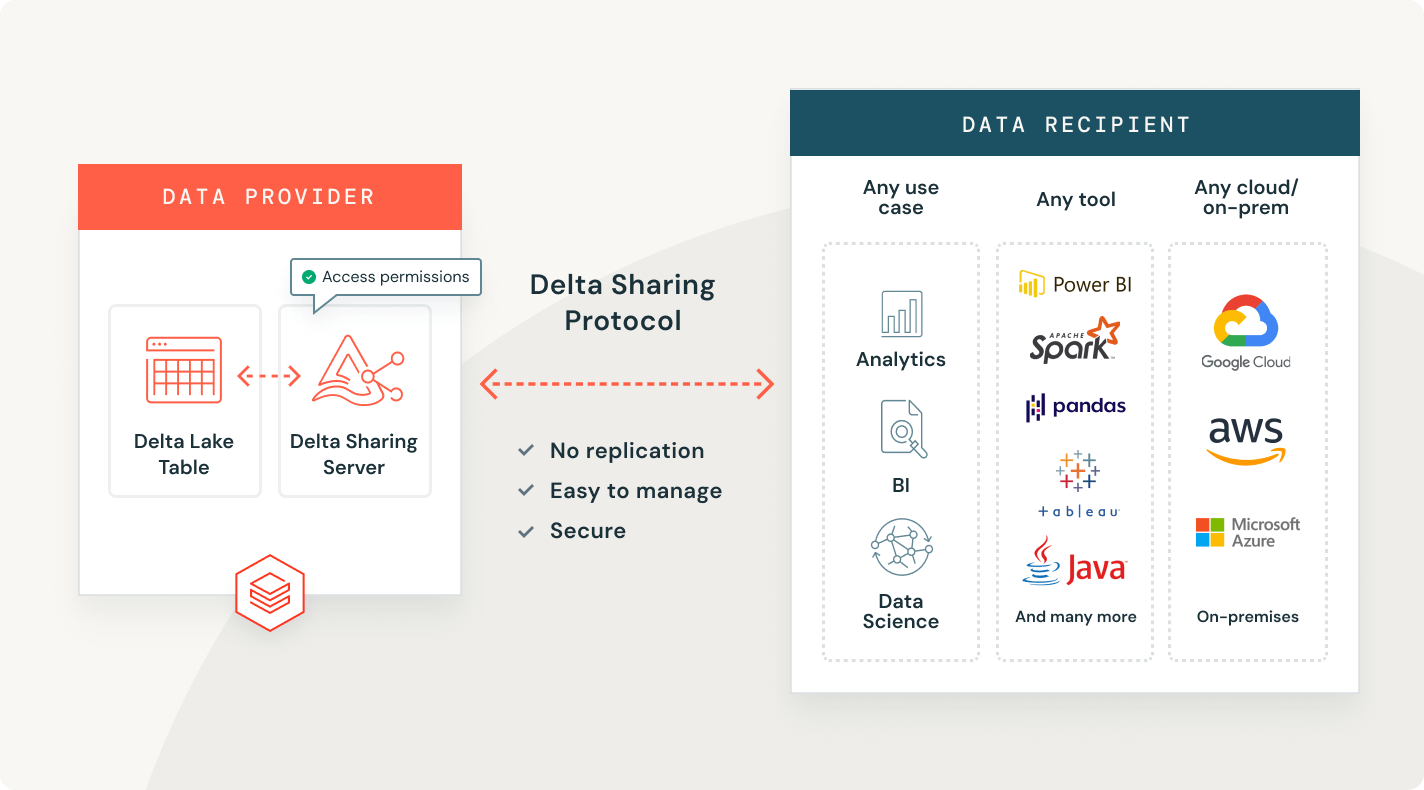
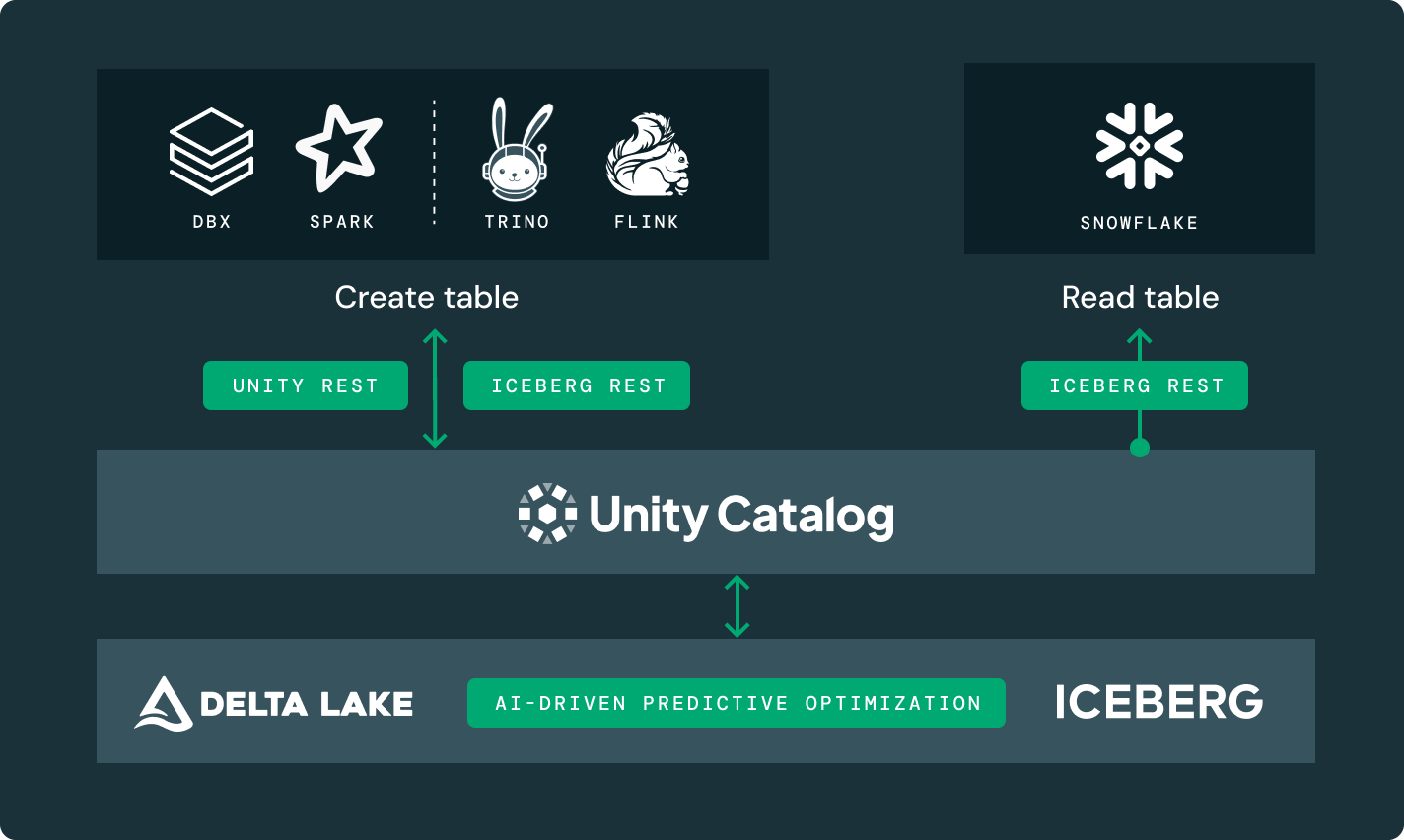
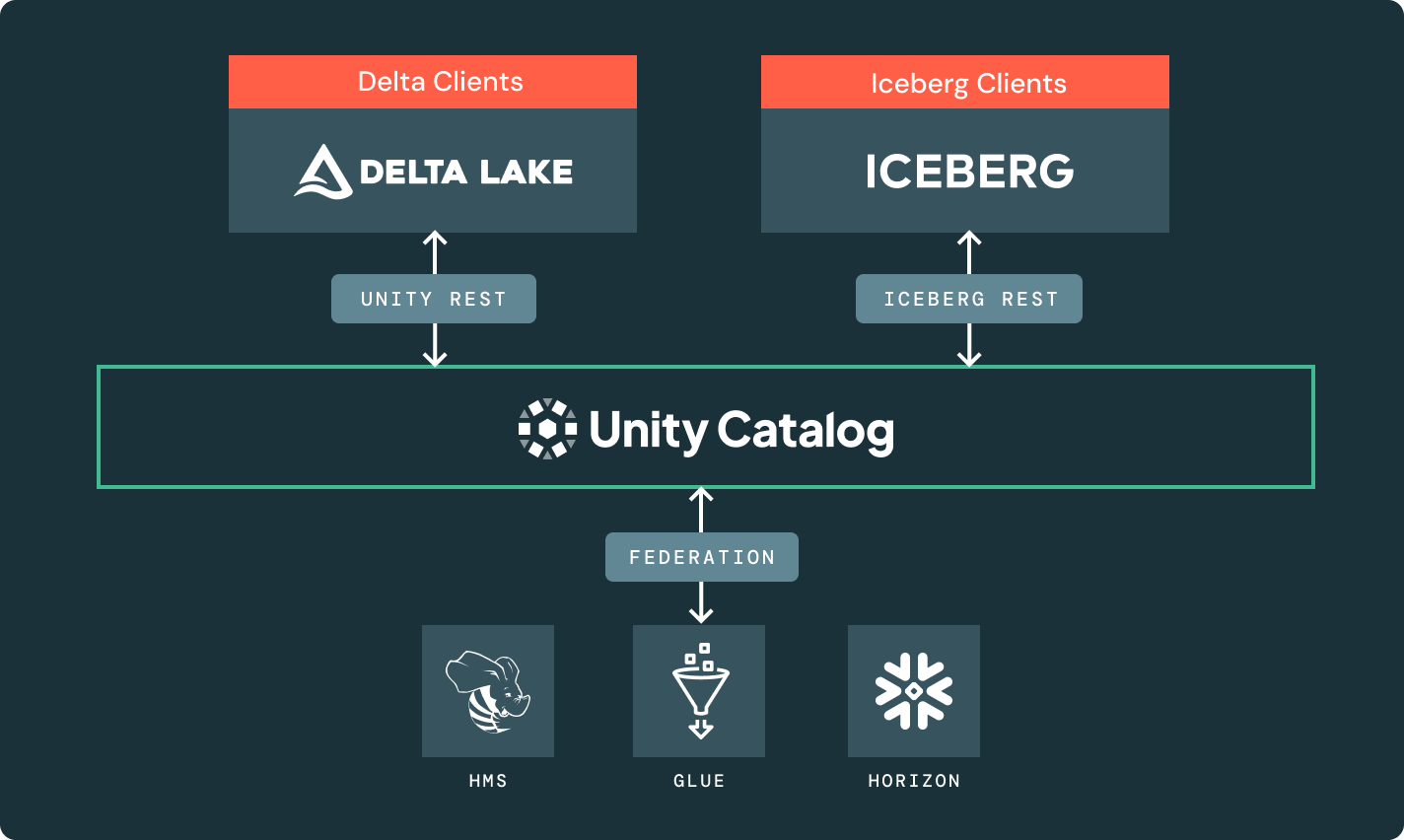
Delta Lake 또는 Apache Iceberg™에 있는 원본 데이터의 단일 복사본은 어떤 엔진에서도 접근할 수 있습니다.
통합 거버넌스
당신의 데이터와 AI 자산을 가로질러 데이터 발견과 거버넌스를 위한 단일 카탈로그.
AI 기반 성능
AI 기반 모델은 속도와 저비용을 위해 데이터를 자동으로 최적화하고 유지합니다.
당신의 데이터, 당신의 방식
당신에게 적합한 저장 위치와 열린 형식을 선택하세요. 벤더에 구속되지 않고 데이터를 이동 가능하게 유지하세요.델타 레이크와 아파치 아이스버그™ 테이블에 대한 최고 수준의 읽기 및 쓰기 성능, 다른 어떤 레이크하우스에서도 사용할 수 없는 저장소 최적화와 함께 제공됩니다.
기타 기능
모든 분석 및 AI 작업에 대해

신뢰할 수 있는 데이터 파이프라인 구축 및 관리
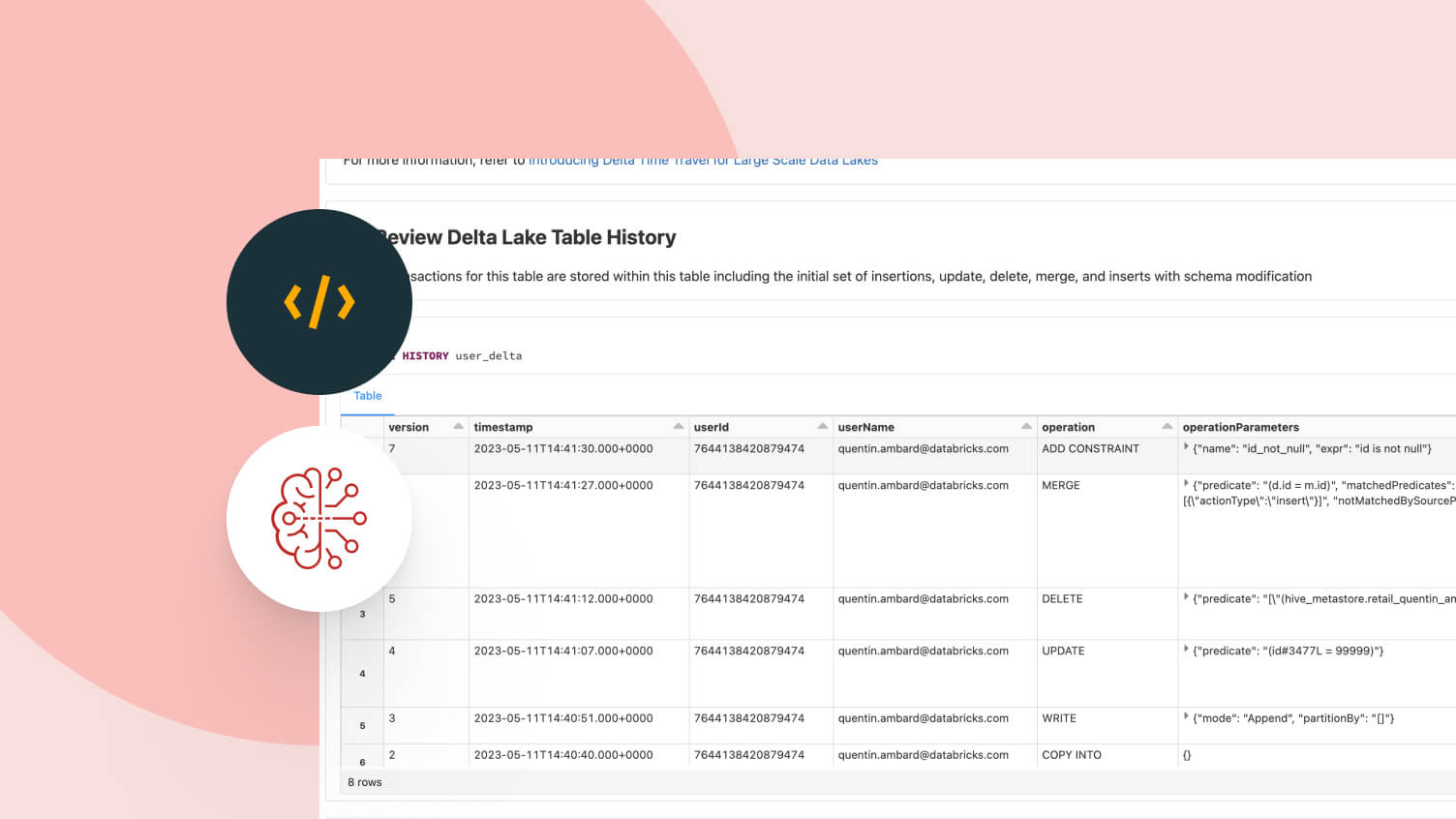
관리 테이블은 배치 테이블과 스트리밍 소스 및 싱크 역할을 합니다. 스트리밍 데이터 수집, 과거 백필(backfill)) 배치 처리와 대화형 쿼리 모두 바로 사용�할 수 있으며 Spark Structured Streaming과 직접 통합됩니다.