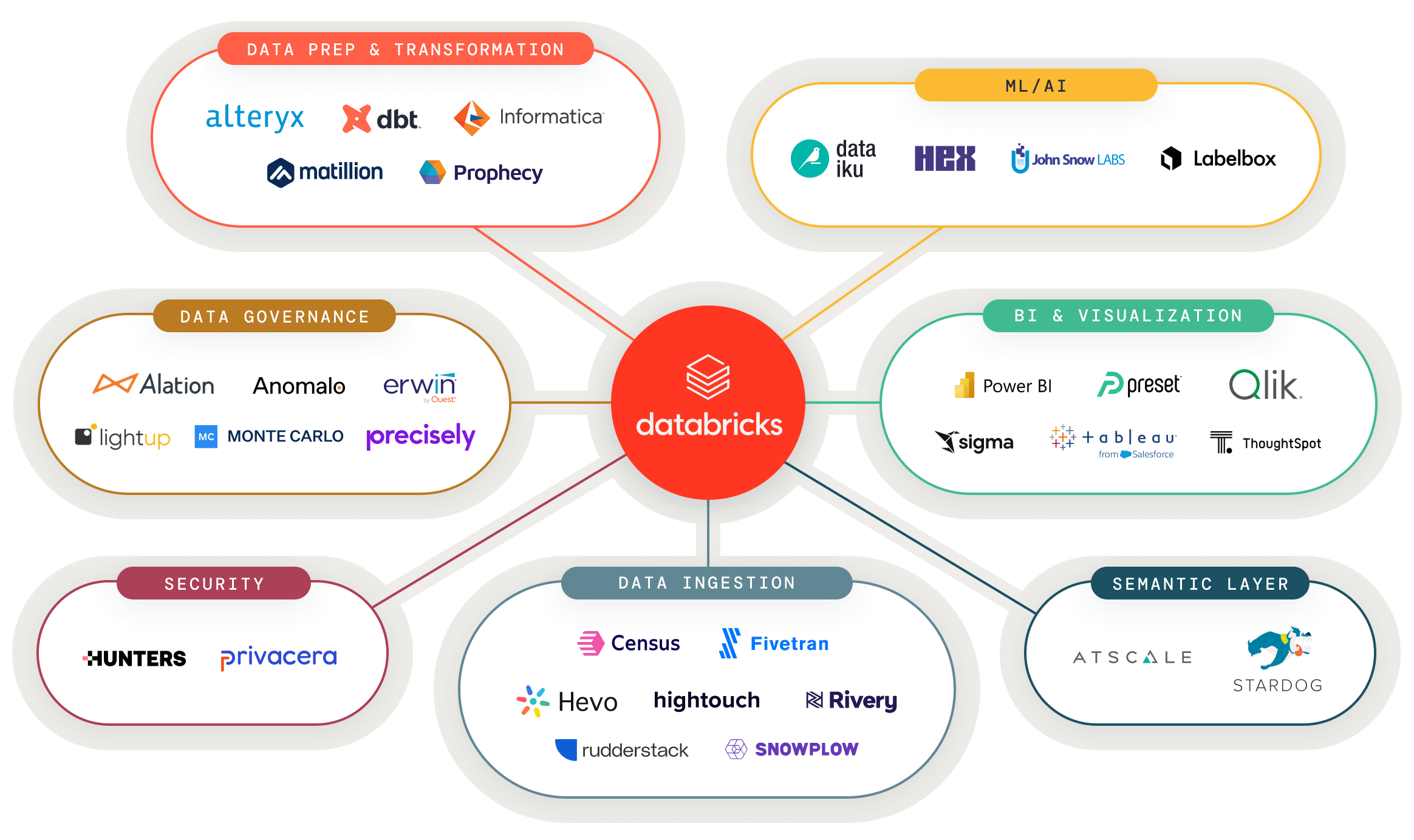
Partner Connect를 사용하면 Databricks 플랫폼에서 직접 데이터, 분석 및 AI 도구를 손쉽게 탐색하고, 현재 사용하고 있는 도구에 빠르게 통합할 수 있습니다. Partner Connect에서는 클릭 몇 번만으로 도구 통합을 간소화하고 레이크하우스의 기능을 신속히 확장할 수 있습니다.
데이터와 AI 도구를 레이크하우스에 연결
원하는 데이터 및 AI 도구를 레이크하우스에 간편하게 연결하고 모든 분석 사용 사례 지원

새로운 사용 사례를 위한 검증된 데이터 및 AI 솔루션 탐색
검증된 파트너 솔루션으로 이루어진 원스톱 포털을 통해 다음 데이터 애플리케이션 구축 기간 단축
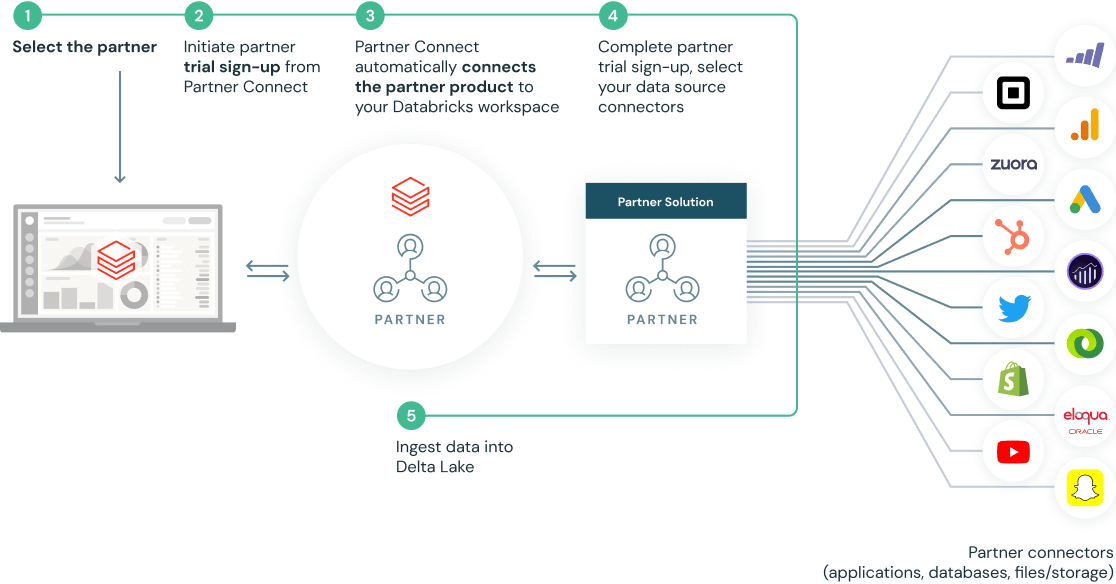
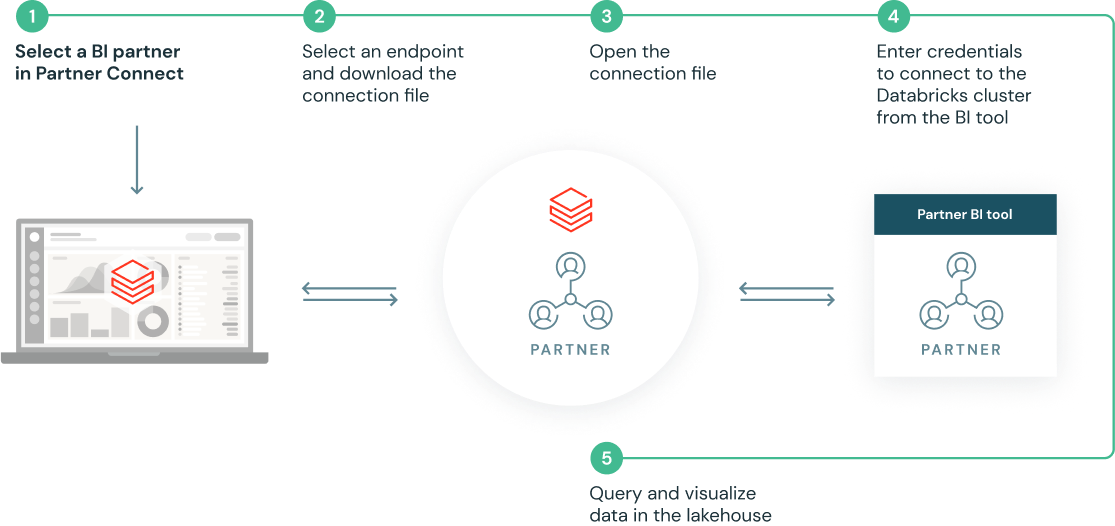
클릭 몇 번으로 사전 구축된 통합 설정
Partner Connect는 클러스터, 토큰, 연결 파일 등의 리소스를 자동으로 구성하여 파트너 솔루션에 연결함으로써 통합 작업 간소화