Spark Streaming이란 무엇인가요?
Spark Streaming이 DStreams를 사용하여 실시간 데이터의 마이크로 배치 처리를 수행하는 방법과 구조화 스트리밍이 현재 선호되는 엔진인 이유

Summary
- Apache Spark Streaming이 무엇인지, Spark 핵심 API를 어떻게 확장하는지, 그리고 Structured Streaming에 밀려 현재는 레거시 스트리밍 엔진으로 여겨지는 이유를 알아보세요.
- Spark Streaming이 Kafka, Flume, Amazon Kinesis와 같은 소스에서 데이터를 수집하고, 마이크로 배치 단위로 처리한 후, DStreams를 사용하여 파일, 데이터베이스 또는 대시보드로 결과를 출력하는 방식을 살펴보세요.
- Spark Streaming이 제공하는 주요 이점, 예를 들어 통합 배치 및 스트리밍 처리, 내결함성, MLlib 및 Spark SQL과의 통합 등을 살펴보세요.
Apache Spark Streaming은 Apache Spark 스트리밍 엔진의 이전 세대입니다. Spark Streaming은 더 이상 업데이트되지 않는 레거시 프로젝트입니다. Apache Spark에는 Structured Streaming이라는 새롭고 간편한 스트리밍 엔진이 있습니다. 애플리케이션과 파이프라인 스트리밍을 위해서는 Spark Structured Streaming을 사용해야 합니다. Structured Streaming을 참조하세요.
Spark Streaming이란 무엇입니까?
Apache Spark Streaming은 확장할 수 있는 내결함성(fault-tolerant) 스트리밍 처리 시스템으로, 배치 및 스트리밍 워크로드를 둘 다 기본적으로 지원합니다. Spark Streaming은 코어 Spark API의 확장 프로그램으로, 데이터 엔지니어와 데이터 사이언티스트가 Kafka, Flume 및 Amazon Kinesis 등을 비롯한(여기에만 국한되는 것은 아님) 여러 소스에서 가져온 실시간 데이터를 처리할 수 있게 해줍니다. 이렇게 처리한 데이터를 파일 시스템, 데이터베이스나 사용 중인 대시보드로 보낼 수 있습니다. 여기에 속한 주요 추상화를 Discretized Stream, 줄여서 DStream이라고 하는데, 이것은 데이터 스트림 하나를 여러 개의 작은 배치로 나눈 것을 말합니다. DStream은 Spark의 코어 데이터 추상화인 RDD 기반입니다. 이것을 이용하면 Spark Streaming이 MLlib나 Spark SQL과 같은 여타 모든 Spark 구성 요소와 원활하게 통합됩니다. Spark Streaming이 다른 여러 시스템과 다른 점은, 스트리밍만을 위해 고안된 처리 엔진이 있거나 이와 비슷한 배치 및 스트리밍 API가 있어도 여러 가지 엔진으로 내부에서 컴파일링한다는 데 있습니다. Spark의 배치, 스트리밍용 단일 실행 엔진과 통합형 프로그래밍 모델은 기존의 다른 스트리밍 시스템과 비교해 몇 가지 독보적인 장점이 있습니다.
Spark Streaming의 4대 주요 측면
- 오류, 지연 작업 발생 시 신속한 복구
- 로드 밸런싱과 리소스 사용률 개선
- 정적 Dataset와 인터랙티브 쿼리를 사용해 스트리밍 데이터 결합
- 고급 처리 라이브러리(SQL, 머신 러닝, 그래프 처리)와 네이티브 방식으로 통합
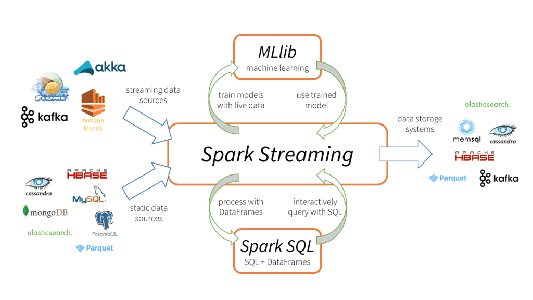
이렇게 이질적인 데이터 처리 기능을 통합하는 기능이 Spark Streaming이 급속히 도입된 주된 이유입니다. 이것을 사용하면 개발자가 처리 요구사항 전체에 모두 부합하는 단 하나의 프레임워크만 간편하게 사용할 수 있습니다.
기업을 위한 에이전틱 AI 플레이북

Apache Spark Streaming 관련 FAQ
Apache Spark Streaming은 여전히 실무에서 사용할 수 있나요?
Spark Streaming은 현재 더 이상 업데이트되지 않는 레거시(legacy) 프로젝트로, 유지보수나 기능 개선이 중단되었습니다. Databricks와 Apache Spark 커��뮤니티는 대신 새로운 스트리밍 엔진인 Structured Streaming 사용을 권장합니다.
Spark Streaming과 Structured Streaming의 주요 차이점은 무엇인가요?
Spark Streaming은 DStream(RDD 기반)을 사용해 데이터를 마이크로 배치 단위로 처리하지만, Structured Streaming은 DataFrame과 Dataset API를 기반으로 하며 완전한 이벤트 기반 스트리밍을 지원합니다. Structured Streaming은 더 단순한 코드 구조와 낮은 지연 시간, 그리고 자동 시점 복구 기능을 제공합니다.
기존 Spark Streaming 애플리케이션을 Structured Streaming으로 마이그레이션하려면 어떻게 해야 하나요?
우선 DStream 기반 로직을 Dataset 또는 DataFrame API로 전환해야 합니다. Kafka 또는 Kinesis 같은 입력 소스와 Sink를 동일하게 유지할 수 있으며, 대부분의 경우 비즈니스 로직을 SQL 또는 Dataset 연산으로 변환하면 Structured Streaming으로 손쉽게 이전할 수 있습니다.