포톤(Photon)은 Databrick 레이크하우스 플랫폼의 차세대 엔진으로, 데이터 레이크에서 직접 저렴한 비용으로 데이터 수집, ETL, 스트리밍, 데이터 사이언스, 대화형 쿼리 등을 매우 빠르게 처리합니다. Photon은 Apache Spark™ API와 호환되므로 코드 변경이나 벤더 종속 없이 켜기만 하면 시작됩니다.
더 저렴하고 더 빠르게
최고의 성능을 더 낮은 비용으로 제공하도록 처음부터 설계된 Photon은 데이터 및 분석 워크로드를 최대 12배까지 가속화하면서, 최대 80%의 총소유비용(TCO) 절감을 실현합니다.
모든 사용 사례에 적합
Photon은 데이터 팀이 배치 및 스트리밍 환경에서 ETL, 분석, 데이터 사이언스 등 모든 워크로드를 하나의 API 세트로 통합해 표준화할 수 있도록 지원하는 최초의 엔진입니다.
코드 변경 없이 사용 가능
Photon은 ANSI 표준을 준수하며 최신 Apache Spark API와 호환되도록 설계되어, SQL, Python, R, Scala, Java 등 기존 코드 그대로 작동합니다. 별도의 코드 수정이나 재작성 없이 바로 사용할 수 있습니다.
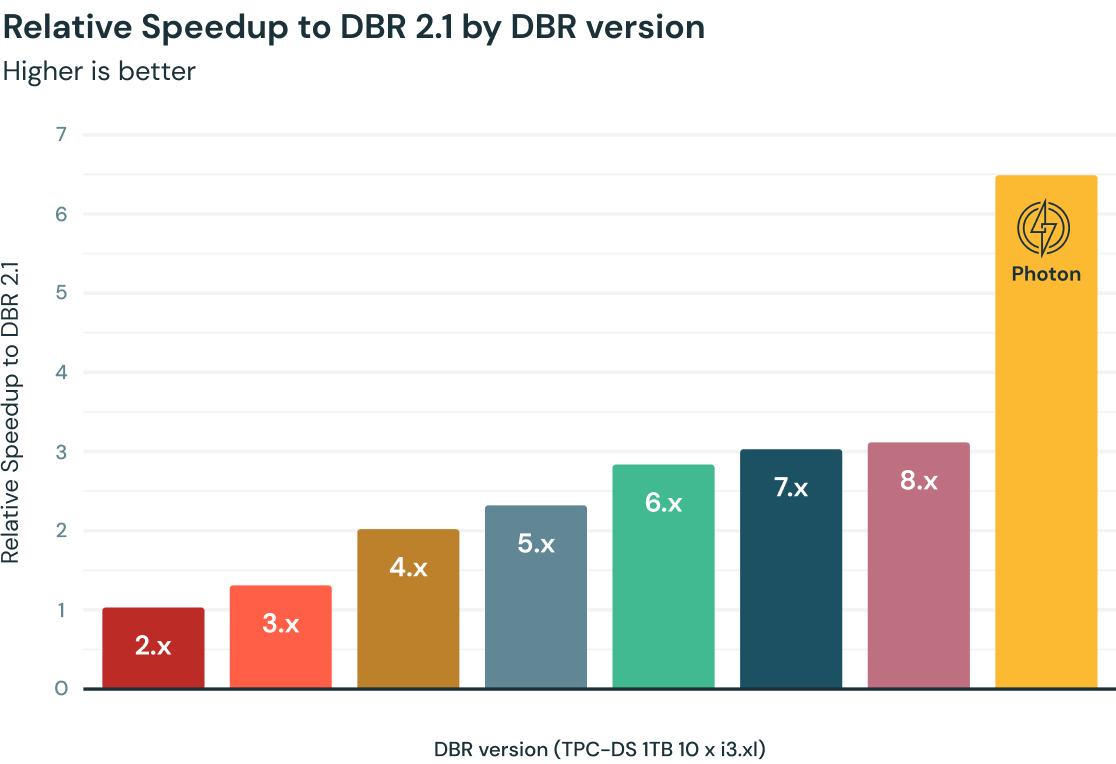
Photon을 선택해야 하는 이유
Databricks의 쿼리 성능은 Apache Spark와 Databricks Runtime(DBR)의 일부로 패키징된 수천 개의 최적화를 통해 몇 년 동안 꾸준히 증가했습니다. C++로만 작성된 새로운 네이티브 벡터 엔진인 Photon은 TPC-DS 1TB 벤치마크당 속도가 2배 이상 빨라지며, 고객은 최신 DBR 버전에 비해 워크로드를 기준으로 평균 3~8배의 속도 향상을 경험했습니다.
사용 사례

프로덕션 작업
SQL 및 Spark DataFrame 기반의 대규모 프로덕션 작업을 가속화합니다.

IoT 애플리케이션
Photon을 사용하면 Spark 및 기존 Databricks Runtime보다 더 빠르게 시계열 분석을 수행할 수 있습니다.

데이터 프라이버시 및 컴플라이언스
Delta Lake, 프로덕션 작업, Photon을 활용해 데이터를 복제하지 않고도 페타바이트 규모의 데이터셋에서 레코드를 식별하고 삭제할 수 있습니다.

Delta Lake 및 Parquet로 데이터 적재
Photon의 벡터화된 I/O는 Delta Lake 및 Parquet 테이블로의 데이터 적재 속도를 높여 전체 실행 시간을 줄이고 데이터 엔지니어링 작업의 비용을 절감합니다.
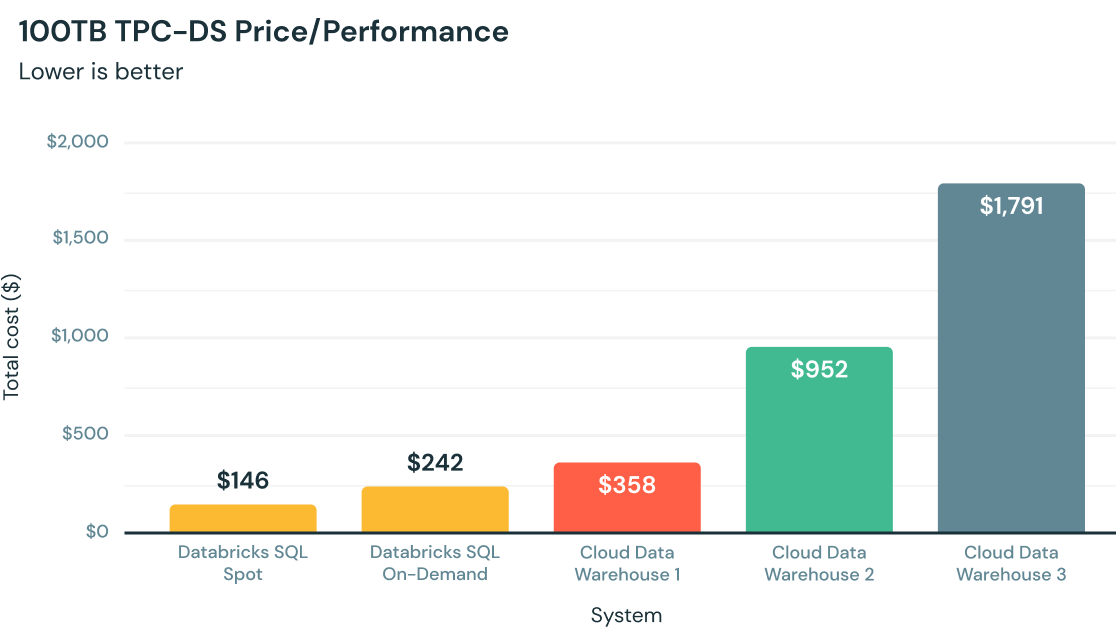
어떻게 작동하나요?
클라우드 분석 시 탁월한 가성비 제공
처음부터 C++로 작성된 Photon은 쿼리 실행 속도를 높이기 위해 최신 하드웨어를 활용하여 다른 클라우드 데이터 웨어하우스에 비해 최대 12배 향상된 가성비를 제공하며, 모두 기본적으로 데이터 레이크를 기반으로 합니다.
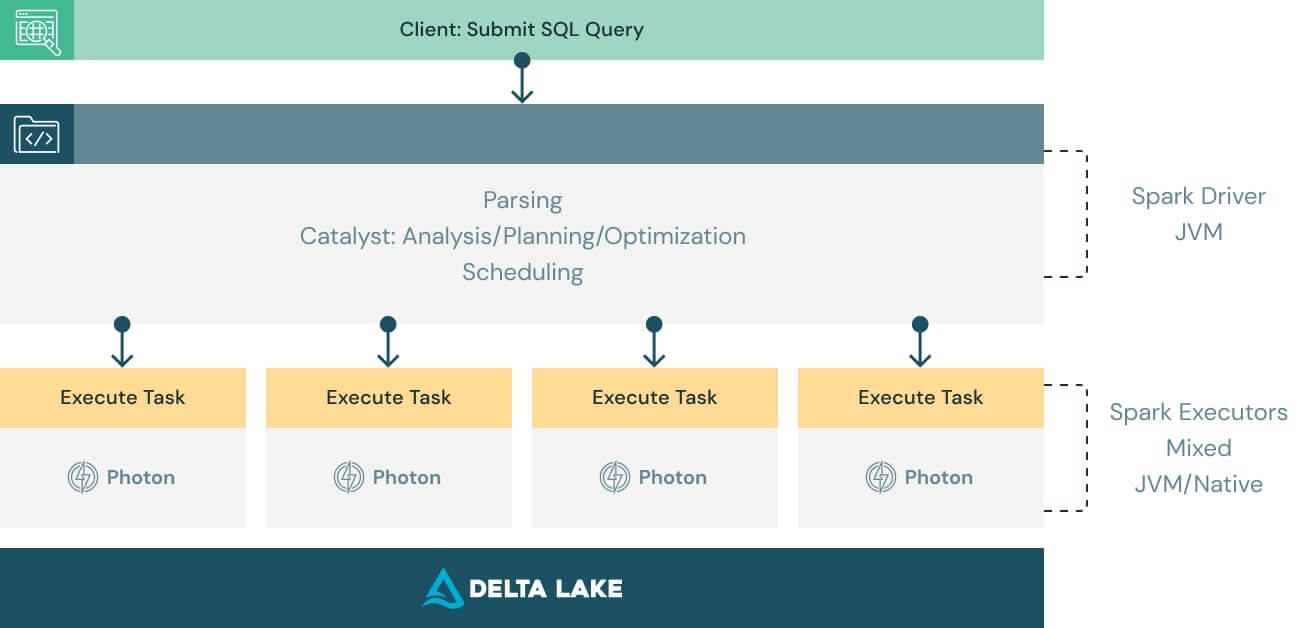
기존 코드 활용 및 벤더 종속 방지
Photon은 Apache Spark DataFrame 및 SQL API와 호환되도록 설계되어 코드 변경 없이도 워크로드가 원활하게 실행되도록 합니다. Photon의 이점을 누리기 위해서는 시스템을 켜기만 하면 됩니다. Phonton은 작업과 리소스를 원활하게 조정하고 SQL 및 Spark 쿼리의 일부를 투명한 방식으로 가속화합니다. 조정이나 사용자 개입이 필요하지 않습니다.

모든 데이터 사용 사례 및 워크로드에 최적화
초기에 Photon은 고객에게 데이터 레이크에 대한 세계 최고 수준의 데이터 웨어하우징 성능을 제공하기 위해 SQL에 주력했지만, 이후 Photon이 지원하는 수집 소스, 형식, API 및 방법의 범위를 크게 늘렸습니다. 그 결과, 고객은 Spark SQL 및 DataFrame과 같은 모든 최신 Spark 워크로드에서 Photon의 인프라 비용을 획기적으로 절감하고 속도를 높일 수 있었습니다.
리소스
리소스
백서
이벤트
블로그
시작할 준비가 되셨나요?