LAKEFLOW를 사용하는 주요 회사들
고품질 데이터를 제공하는 종단간 솔루션.
모든 팀이 분석 및 AI를 위한 신뢰할 수 있는 데이터 파이프라인을 구축하기 쉽게 하는 도구입니다.통합 도구 스택
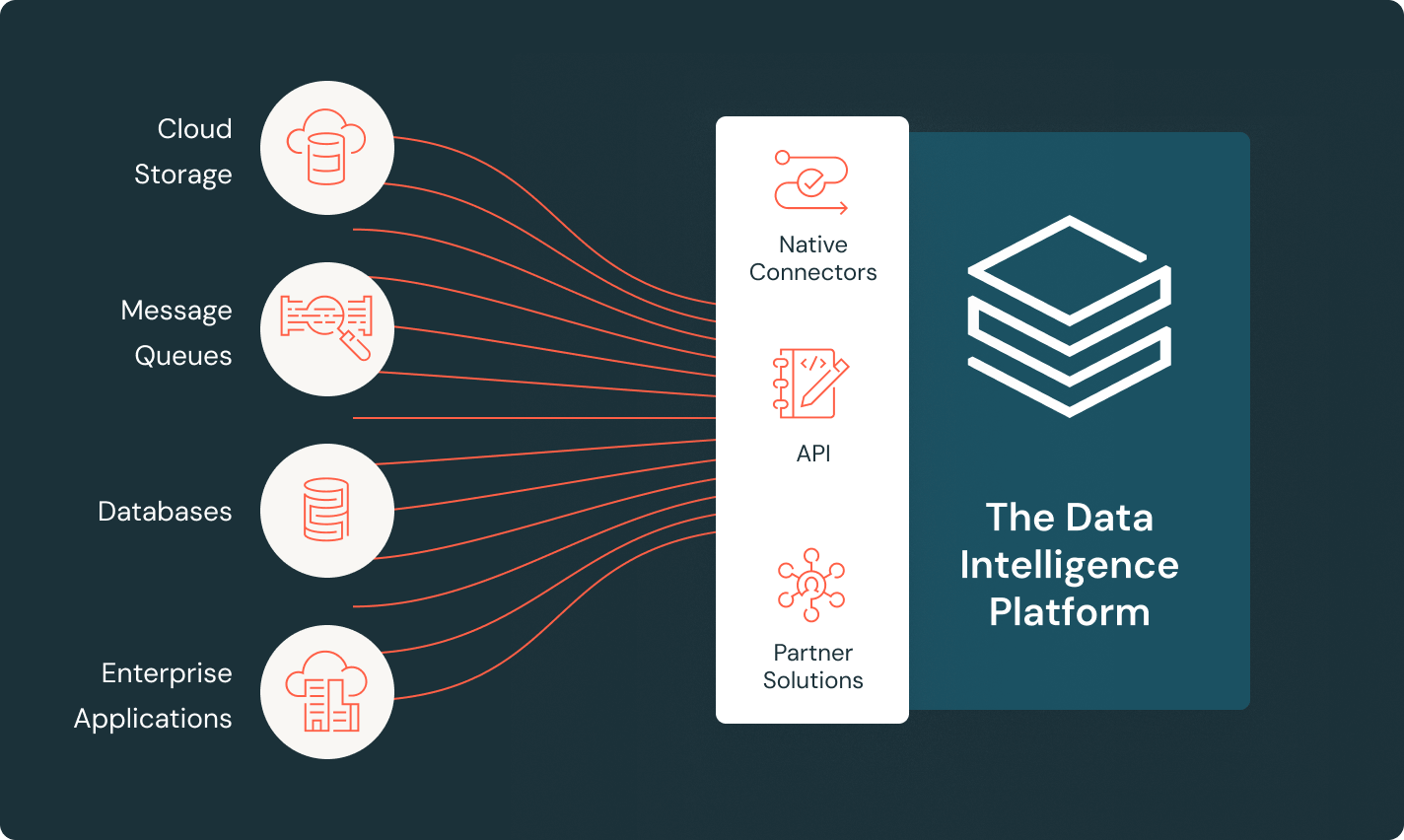
모든 데이터를 수집하고 정리하는 단일 솔루션으로 비용과 통합 오버헤드를 줄입니다. 내장된 통합 거버넌스와 라인리지로 항상 제어하십시오.
간편화된 ETL 개발
코드 없는 데이터 커넥터, 선언적 변환, AI 지원 코드 작성을 사용하여 모든 팀이 더 빠르게 구축할 수 있게 합니다.
효율적인 데이터 처리
강력한 엔진이 배치 및 저 지연 실시간 사용 사례에 대한 가격/성능을 개선하기 위해 리소스 사용을 자동 최적화합니다.
85% 빠른 개발
99% 파이프라인 지연 감소
데이터 엔지니어를 위한 통합 도구

LakeFlow Connect
효율적인 데이터 수집 커넥터와 Data Intelligence Platform과의 기본 통합을 통해 분석 및 AI에 쉽게 접근할 수 있으며, 통합된 거버넌스를 제공합니다.

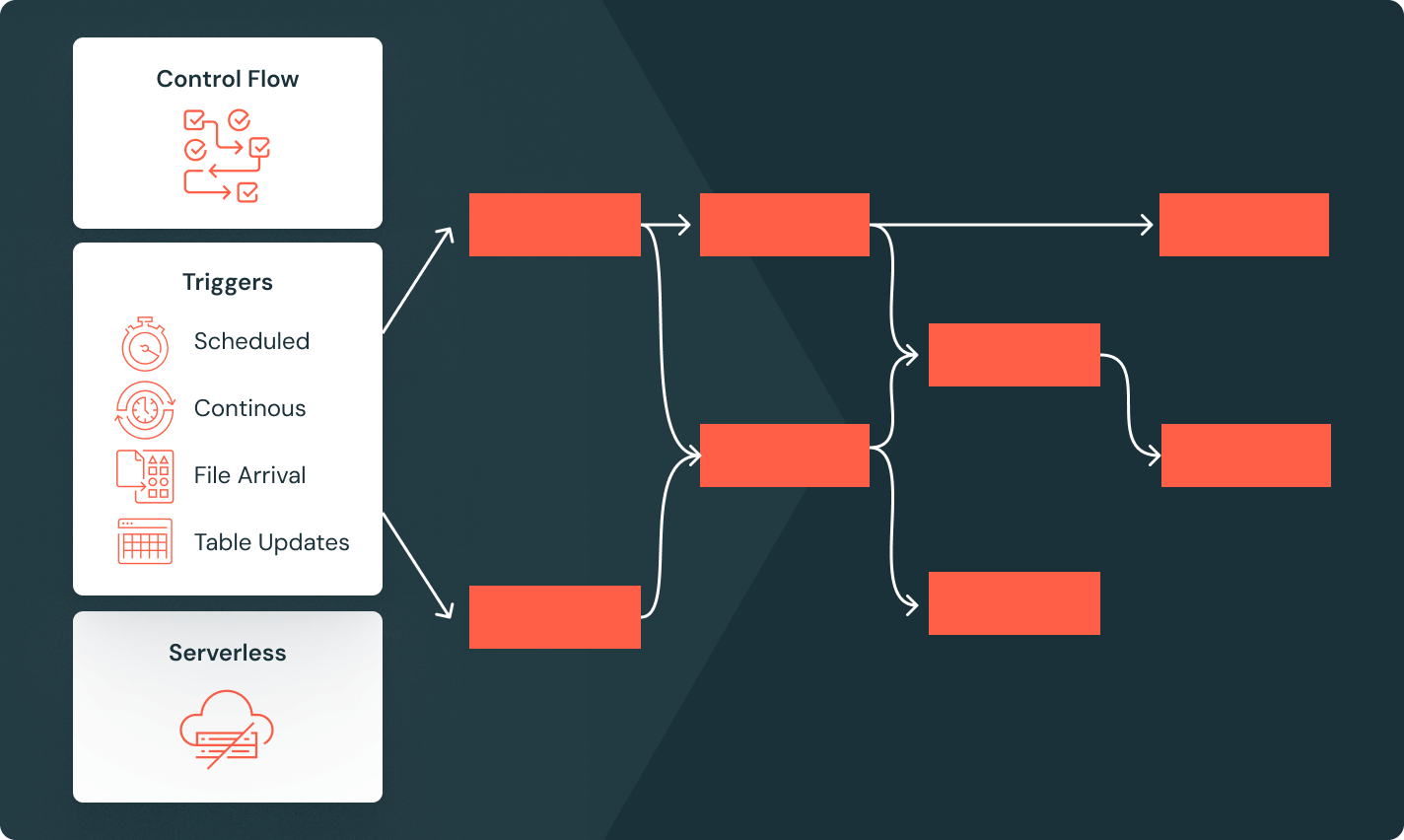
Spark 선언형 파이프라인
자동화된 데이터 품질, 변경 데이터 캡처(CDC), 데이터 수집, 변환, 통합 거버넌스를 통해 배치 및 스트리밍 ETL을 단순화합니다.

Lakeflow 작업
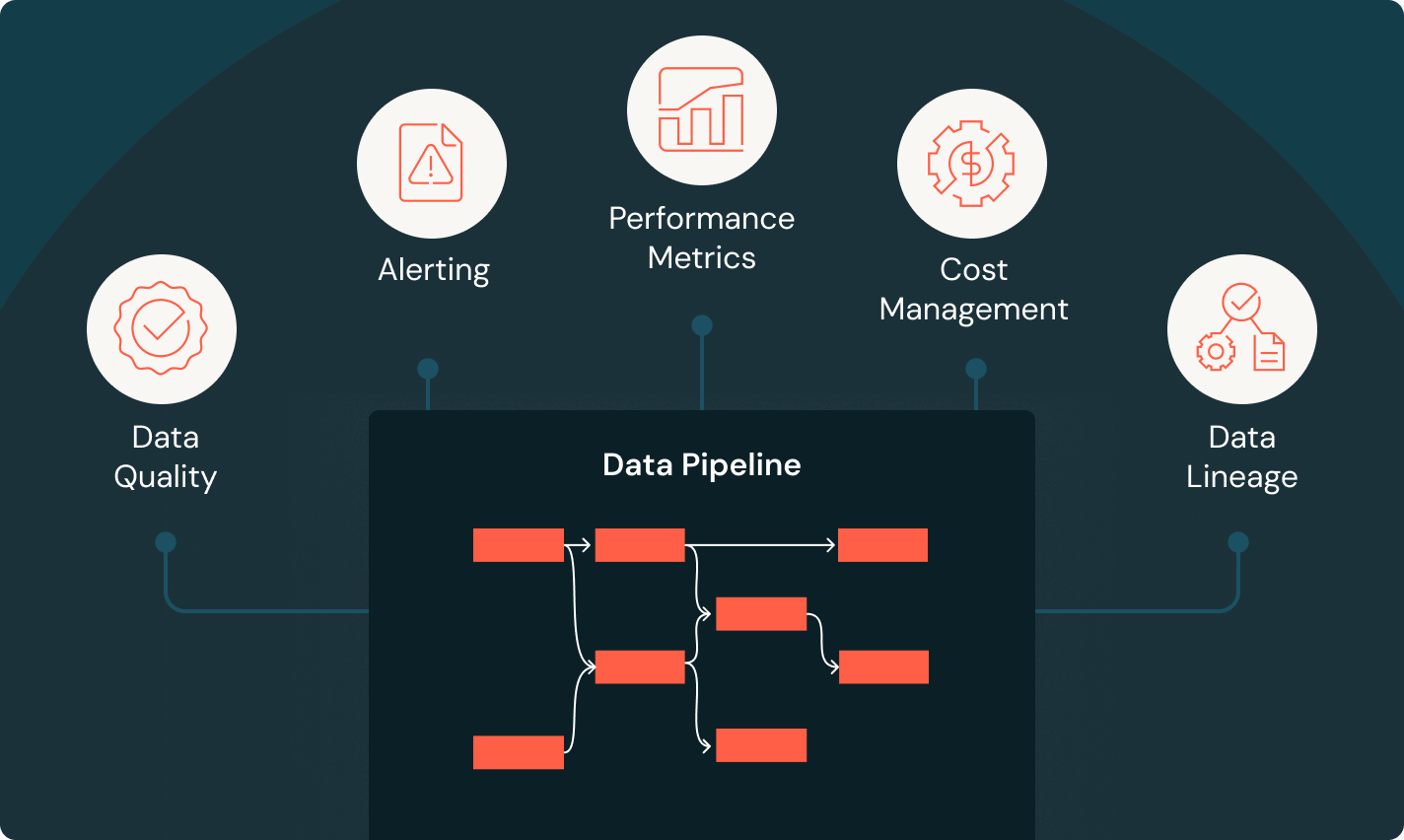
팀이 깊은 관찰성, 높은 신뢰성, 넓은 작업 유형 지원을 통해 모든 ETL, 분석, AI 워크플로우를 더 잘 자동화하고 조정할 수 있도록 장비를 갖춥니다.

Unity Catalog
업계 유일의 통합된 오픈 거버넌스 솔루션을 통해 모든 데이터 자산을 원활하게 관리하십시오. 이 솔루션은 Databricks Data Intelligence Platform에 내장되어 있습니다.

레이크하우스 스토리지
레이크하우스의 모든 형식과 유형의 데이터를 통합하여 모든 분석 및 AI 작업에 사용합니다.
Data Intelligence Platform
Databricks 데이터 인텔리전스 플랫폼에서 제공하는 다양한 도구를 활용하여 조직 전체에서 데이터와 AI를 원활하게 통합하세요.
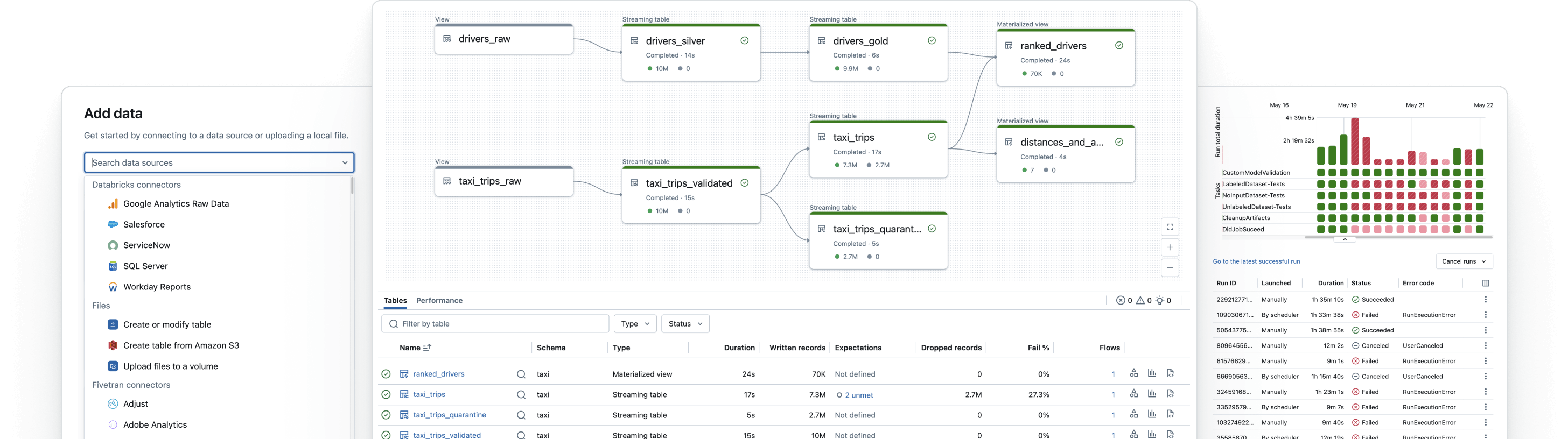
신뢰할 수 있는 데이터 파이프라인 구축

원시 데이터를 고품질 골드 테이블로 변환합니다
ETL 파이프라인을 구현하여 데이터를 필터링, 풍부하게 만들고, 정리하고, 집계하여 분석, AI 및 BI에 적합하게 만듭니다. 브론즈에서 실버를 거쳐 골드 테이블로 데이터를 처리하는 메달리온 아키텍처를 따릅니다.