Vector Search
Uma base de dados vetorial de alto desempenho com governança integrada

Desbloqueie todo o potencial da IA generativa com o Vector Search da Databricks
O Vector Search é uma base de dados vetorial serverless
perfeitamente integrada à plataforma de inteligência de dados
Ao contrário de outras bases de dados, o Vector Search da Databricks oferece suporte à sincronização automática de dados da origem ao índice, eliminando a complexa e dispendiosa manutenção do pipeline. Ele usa as mesmas ferramentas de segurança e governança de dados que as organizações já criaram para maior tranquilidade. Com design serverless, o Vector Search da Databricks pode ser facilmente dimensionado para suportar bilhões de incorporações e milhares de queries em tempo real por segundo.
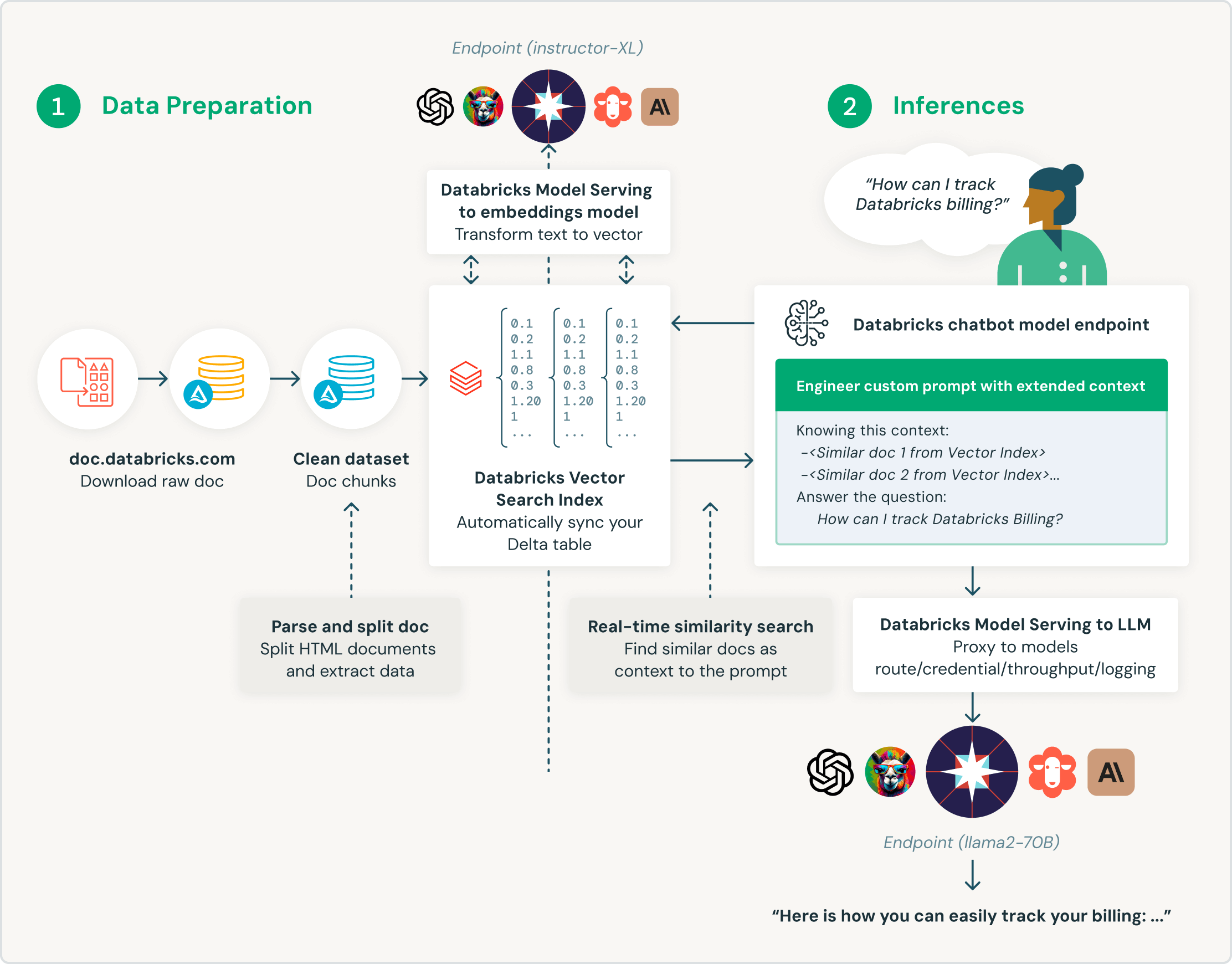
Construído para geração aumentada de recuperação (RAG)
O Vector Search da Databricks foi criado especificamente para que os clientes aumentem seus grandes modelos de linguagem (LLMs) com dados corporativos. Especificamente projetado para aplicativos de geração aumentada de recuperação (RAG), o Vector Search da Databricks oferece resultados de pesquisa de similaridade, enriquecendo consultas de LLM com contexto e conhecimento de domínio e melhorando a precisão e a qualidade dos resultados.
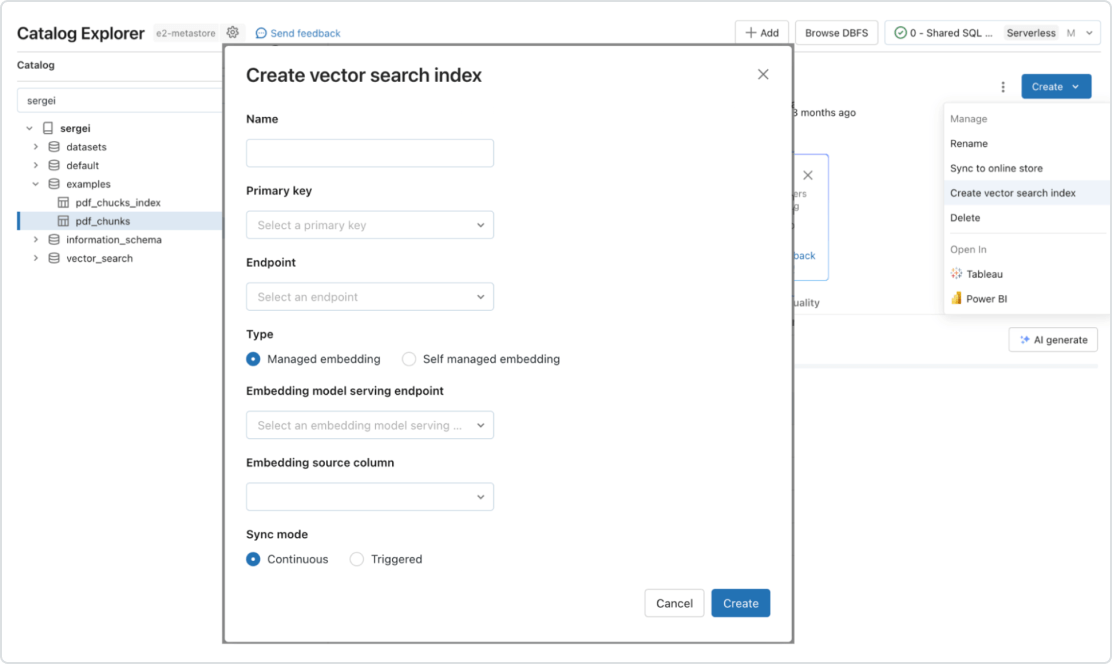
Pipelines automatizados em tempo real
Sincronização em tempo real dos dados de origem, atualizando automaticamente o índice vetorial correspondente à medida que novos dados são introduzidos, modificados ou removidos. Nos bastidores, a Databricks faz a geração e o gerenciamento do vetor de incorporação e gerencia automaticamente as falhas, lida com novas tentativas, otimiza o throughput e faz o ajuste automático do tamanho do batch e o dimensionamento automático sem a necessidade de intervenção.
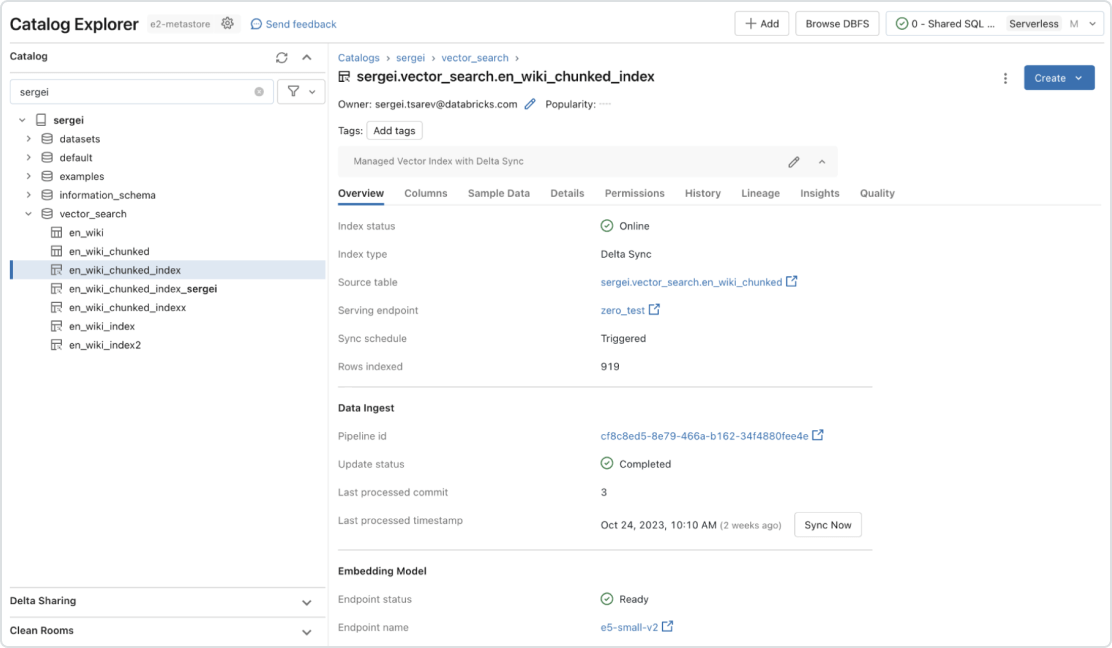
Governança integrada
A interface unificada define políticas de dados, com controle de acesso refinado em incorporações. Com integração integrada ao Unity Catalog, o Vector Search mostra automaticamente a linhagem de dados e o acompanhamento sem a necessidade de ferramentas adicionais ou políticas de segurança. Isso garante que os modelos de LLM não exponham dados confidenciais aos usuários que não deveriam ter acesso.
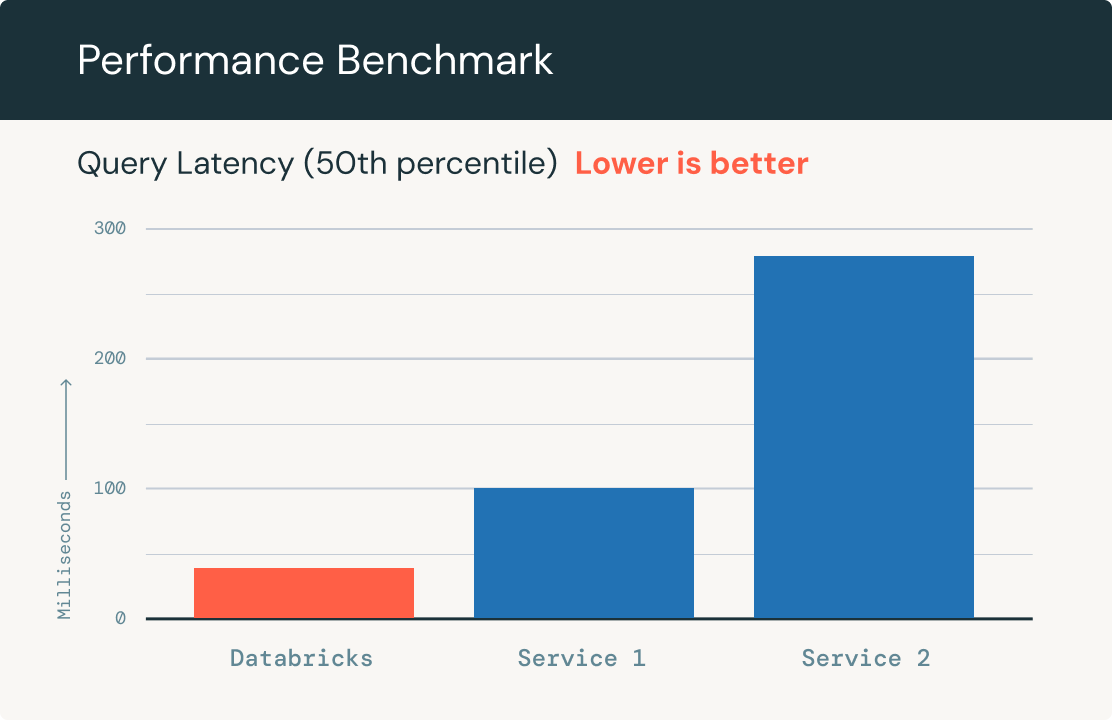
Desempenho rápido para queries
Dimensionamento automático para lidar com bilhões de incorporações em um índice e milhares de queries por segundo. Ele mostra desempenho até 5 vezes mais rápido do que outras bases de dados vetoriais líderes em até 1 milhão de datasets incorporados do OpenAI.