Présentation de Delta Sharing : un protocole ouvert pour le partage sécurisé de données
par Matei Zaharia, Michael Armbrust, Steve Weis, Todd Greenstein et Cyrielle Simeone
Delta Sharing a évolué pour devenir OpenSharing, le premier protocole ouvert et neutre vis-à-vis des fournisseurs pour partager en toute sécurité des ressources d'IA, notamment des compétences d'agent, des modèles d'IA et des données non structurées. Lisez l'annonce.
Mise à jour : Delta Sharing est désormais généralement disponible sur AWS et Azure.
Découvrez en avant-première le nouvel e-book d'O'Reilly pour obtenir les conseils étape par étape nécessaires pour commencer à utiliser Delta Lake.
Le partage de données est devenu essentiel dans l'économie moderne, car les entreprises cherchent à échanger des données en toute sécurité avec leurs clients, fournisseurs et partenaires. Par exemple, un détaillant peut vouloir publier des données de vente pour ses fournisseurs en temps réel, ou un fournisseur peut vouloir partager ses stocks en temps réel. Mais jusqu'à présent, le partage de données était fortement limité, car les solutions de partage sont liées à un seul fournisseur. Cela crée des frictions tant pour les fournisseurs que pour les consommateurs de données, qui utilisent naturellement des plateformes différentes.
Aujourd'hui, nous lançons un nouveau projet open source qui simplifie le partage entre organisations : Delta Sharing, un protocole ouvert pour l'échange sécurisé et en temps réel de grands ensembles de données, qui permet pour la première fois un partage de données sécurisé entre différents produits. Nous développons Delta Sharing avec des partenaires figurant parmi les plus grands fournisseurs de logiciels et de données au monde.
Pour comprendre pourquoi les solutions actuelles de partage de données créent des frictions, prenons l'exemple d'un détaillant qui souhaite partager des données avec un analyste chez l'un de ses fournisseurs. Aujourd'hui, le détaillant pourrait utiliser l'un des nombreux data warehouses cloud qui proposent le partage de données, mais l'analyste devrait alors collaborer avec ses équipes IT, de sécurité et d'approvisionnement pour déployer le même produit de data warehouse dans son entreprise, un processus qui peut prendre des mois. De plus, une fois le data warehouse déployé, la première chose que ferait l'analyste serait d'en exporter les données vers son outil de science des données préféré, tel que pandas ou Tableau.
Avec Delta Sharing, les utilisateurs de données peuvent se connecter directement aux données partagées via pandas, Tableau ou des dizaines d'autres systèmes qui implémentent le protocole ouvert, sans avoir à déployer de plateforme spécifique au préalable. Cela réduit leur temps d'accès de plusieurs mois à quelques minutes, et simplifie grandement le travail des fournisseurs de données qui souhaitent toucher un maximum d'utilisateurs.
Nous collaborons avec un écosystème dynamique de partenaires sur Delta Sharing, notamment des équipes produit chez les principaux fournisseurs de cloud, de BI et de données :

Écosystème Delta Sharing
Dans cet article, nous expliquerons le fonctionnement de Delta Sharing et pourquoi nous sommes si enthousiastes à l'idée d'une approche ouverte du partage de données.
Objectifs de Delta Sharing
Delta Sharing est conçu pour être facile à utiliser, tant pour les fournisseurs que pour les consommateurs, avec leurs données et workflows existants. Nous l'avons conçu avec quatre objectifs en tête :
- Partager des données en direct directement sans les copier : Nous voulons faciliter le partage des données existantes en temps réel. Aujourd'hui, la majorité des données d'entreprise sont stockées dans des systèmes de data lake et de lakehouse cloud. Delta Sharing fonctionne sur ces derniers ; il vous permet notamment de partager en toute sécurité tout ensemble de données existant aux formats Delta Lake ou Apache Parquet.
- Prendre en charge un large éventail de clients : Les destinataires doivent pouvoir consommer directement les données à partir des outils de leur choix, sans avoir à installer une nouvelle plateforme. Le protocole Delta Sharing est conçu pour être facilement pris en charge directement par les outils. Il repose sur Parquet, déjà pris en charge par la plupart des outils, ce qui facilite l'implémentation d'un connecteur.
- Sécurité, audit et gouvernance renforcés : Le protocole est conçu pour vous aider à respecter les exigences de confidentialité et de conformité. Delta Sharing vous permet d'accorder, de suivre et d'auditer l'accès aux données partagées à partir d'un point de contrôle unique.
- S'adapter à des ensembles de données massifs : Le partage de données doit de plus en plus prendre en charge des ensembles de données de l'ordre du téraoctet, comme des données industrielles ou financières détaillées, ce qui représente un défi pour les solutions existantes. Delta Sharing tire parti du coût et de l'élasticité des systèmes de stockage cloud pour partager des ensembles de données massifs de manière économique et fiable.
Comment fonctionne Delta Sharing ?
Delta Sharing est un protocole REST simple qui partage de manière sécurisée l'accès à une partie d'un ensemble de données cloud. Il tire parti des systèmes de stockage cloud modernes, tels que S3, ADLS ou GCS, pour transférer de grands ensembles de données de manière fiable. Deux parties sont impliquées : les fournisseurs de données et les destinataires.
En tant que fournisseur de données, Delta Sharing vous permet de partager des tables existantes ou des parties de celles-ci (par exemple, des versions de table spécifiques ou des partitions) stockées sur votre data lake cloud au format Delta Lake. Une table Delta Lake est essentiellement une collection de fichiers Parquet, et il est facile d'encapsuler des tables Parquet existantes dans Delta Lake si nécessaire. Le fournisseur de données décide des données qu'il souhaite partager et exécute un serveur de partage en amont qui implémente le protocole Delta Sharing et gère l'accès pour les destinataires. Nous avons publié un serveur de partage de référence en open source ; et nous en proposons un hébergé sur Databricks, comme le feront probablement d'autres fournisseurs.
En tant que destinataire des données, tout ce dont vous avez besoin est l'un des nombreux clients Delta Sharing qui prennent en charge le protocole. Nous avons publié des connecteurs open source pour pandas, Apache Spark, Rust et Python, et nous collaborons avec des partenaires pour en proposer bien d'autres.
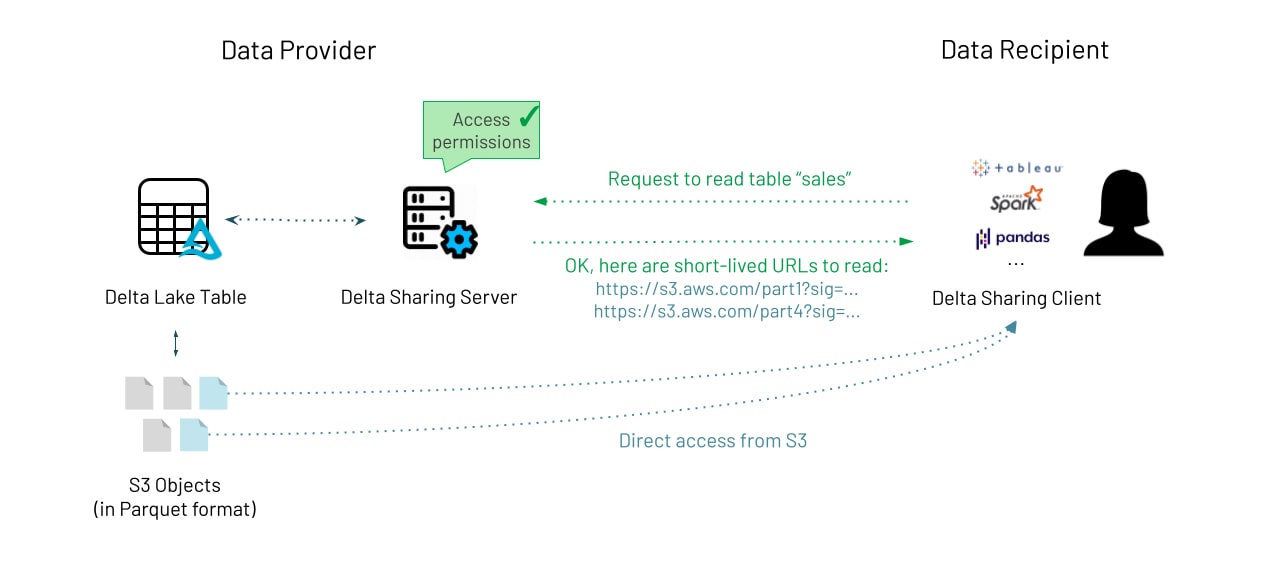
L'échange proprement dit est soigneusement conçu pour être efficace en tirant parti des fonctionnalités des systèmes de stockage cloud et de Delta Lake. Le protocole fonctionne comme suit :
- Le client du destinataire s'authentifie auprès du serveur de partage (via un jeton bearer ou une autre méthode) et demande à interroger une table spécifique. Le client peut également fournir des filtres sur les données (par exemple, « country=US ») pour indiquer qu'il ne souhaite lire qu'un sous-ensemble des données.
- Le serveur vérifie si le client est autorisé à accéder aux données, enregistre la demande, puis détermine les données à renvoyer. Il s'agira d'un sous-ensemble des objets de données dans S3 ou d'autres systèmes de stockage cloud qui composent réellement la table.
- Pour transférer les données, le serveur génère des URL pré-signées à courte durée de vie qui permettent au client de lire ces fichiers Parquet directement auprès du fournisseur cloud, de sorte que le transfert puisse s'effectuer en parallèle avec une bande passante massive, sans passer par le serveur de partage. Cette fonctionnalité puissante, disponible sur tous les principaux clouds, rend le partage de très grands ensembles de données rapide, économique et fiable.
Avantages de cette conception
La conception de Delta Sharing offre de nombreux avantages tant pour les fournisseurs que pour les consommateurs :
- Les fournisseurs de données peuvent facilement partager une table entière, ou seulement une version ou une partition de celle-ci, car les clients n'ont accès qu'à un sous-ensemble spécifique des objets qu'elle contient.
- Les fournisseurs de données peuvent mettre à jour les données de manière fiable et en temps réel grâce aux transactions ACID sur Delta Lake, et les destinataires bénéficieront toujours d'une vue cohérente.
- Les destinataires des données n'ont pas besoin d'utiliser la même plateforme que le fournisseur, ni même d'être sur le cloud : le partage fonctionne entre différents clouds et même depuis le cloud vers des utilisateurs sur site.
- Le protocole Delta Sharing est très facile à implémenter pour les clients s'ils comprennent déjà Parquet. La plupart de nos implémentations de prototypes avec des moteurs open source et des outils BI n'ont pris que 1 à 2 semaines à développer.
- Le transfert est rapide, économique, fiable et parallélisable grâce au système cloud sous-jacent.
Un écosystème ouvert
Comme mentionné précédemment, nous sommes ravis de mettre en place une approche ouverte du partage de données. Les fournisseurs de données, comme Nasdaq, nous ont tous indiqué qu'il est trop difficile de distribuer des données à des consommateurs divers, qui utilisent tous des outils d'analyse différents.
« Nous soutenons Delta Sharing et sa vision d'un protocole ouvert qui simplifiera le partage sécurisé de données et la collaboration entre les organisations. Delta Sharing améliorera notre façon de travailler avec nos partenaires, réduira les coûts opérationnels et permettra à un plus grand nombre d'utilisateurs d'accéder à une gamme complète de la suite de données de Nasdaq pour découvrir des insights et développer des stratégies financières », a déclaré Bill Dague, responsable des données alternatives chez Nasdaq.
Avec Delta Sharing, des dizaines de systèmes populaires pourront se connecter directement aux données partagées afin que n'importe quel utilisateur puisse les utiliser, ce qui réduit les frictions pour tous les participants. Nous travaillons avec des dizaines de partenaires pour définir la norme Delta Sharing, et nous vous invitons à y participer.
Bon nombre de ces entreprises ont apporté leur soutien au lancement d'aujourd'hui :
Outils BI : Tableau, Qlik, Power BI, Looker
Analytique : AtScale, Dremio, Starburst, Microsoft Azure, Google BigQuery
Gouvernance : Collibra, Immuta, Alation, Privacera
Fournisseurs de données : FactSet, Nasdaq, Precisely, Safegraph, Atlassian, AWS, Foursquare, ICE, Qandl, S&P, SequenceBio
Delta Sharing sur Databricks
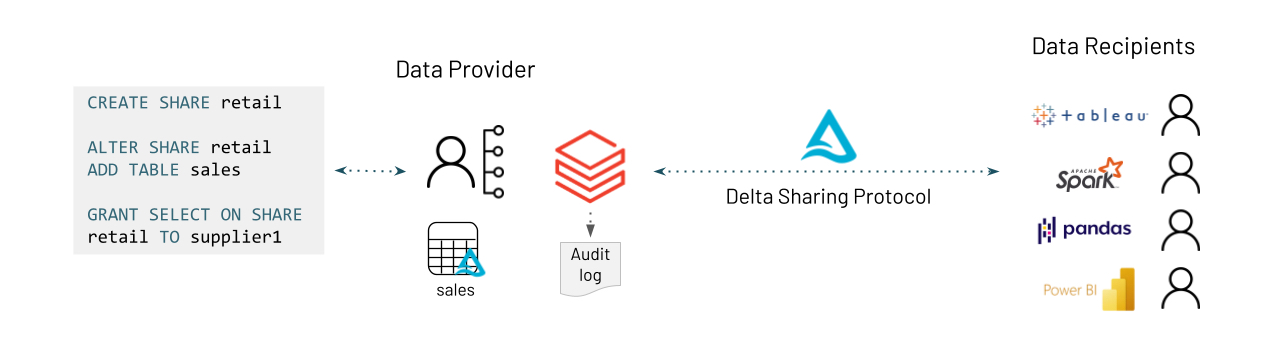
Les clients de Databricks bénéficieront d'une intégration native de Delta Sharing dans notre Unity Catalog, offrant une expérience simplifiée pour le partage de données au sein de l'organisation et entre organisations. Les administrateurs pourront gérer les partages à l'aide d'une nouvelle syntaxe SQL CREATE SHARE ou d'API REST, et auditer tous les accès de manière centralisée. Les destinataires pourront consommer les données depuis n'importe quelle plateforme. Inscrivez-vous pour rejoindre notre liste d'attente afin d'accéder à la version préliminaire et recevoir des mises à jour.
Feuille de route
Cette première version de Delta Sharing n'est qu'un début. À mesure que nous développons le projet, nous prévoyons de l'étendre au partage d'autres objets, tels que des flux, des vues SQL ou des fichiers arbitraires comme des modèles de machine learning. Nous sommes convaincus que l'avenir du partage de données est ouvert, et nous sommes ravis d'apporter cette approche à d'autres flux de travail de partage.
Premiers pas avec Delta Sharing
Pour essayer la version open source de Delta Sharing, suivez les instructions sur delta.io/sharing. Ou, si vous êtes client de Databricks, inscrivez-vous pour recevoir des mises à jour sur notre service. Nous avons hâte de recevoir vos commentaires !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.