Qu'est-ce que MLOps ?
Pratiques et outils pour le déploiement, la surveillance et la gouvernance des modèles d'apprentissage automatique en vue de systèmes d'apprentissage automatique fiables et reproductibles
- Couvre l'intégralité du cycle de vie du ML, incluant le suivi des expériences, le versionnage des modèles, les gestionnaires de fonctionnalités, les tests automatisés, les pipelines CI/CD, la conteneurisation et le registre de modèles pour des flux de développement et de déploiement reproductibles.
- Met en œuvre des systèmes de surveillance des performances des modèles, de la dérive des données, de la latence de prédiction, de l'utilisation des ressources et des KPI métier, avec des alertes automatisées et des déclencheurs de réentraînement pour garantir la qualité des modèles en production.
- Répond aux exigences de gouvernance grâce à des pistes d'audit, des contrôles d'accès, le suivi de la lignée des modèles, des outils d'explicabilité et une documentation de conformité, permettant des pratiques d'IA responsables et le respect des réglementations.
Que sont les MLOps ?
MLOps signifie Machine Learning Operations, ou opérations de machine learning. Fonction fondamentale de l'ingénierie du machine learning, les MLOps ont pour mission de normaliser le processus de mise en production des modèles de machine learning puis d'en assurer la maintenance et la supervision. Les MLOps sont une fonction collaborative qui réunit généralement des data scientists, des ingénieurs DevOps et l'IT.
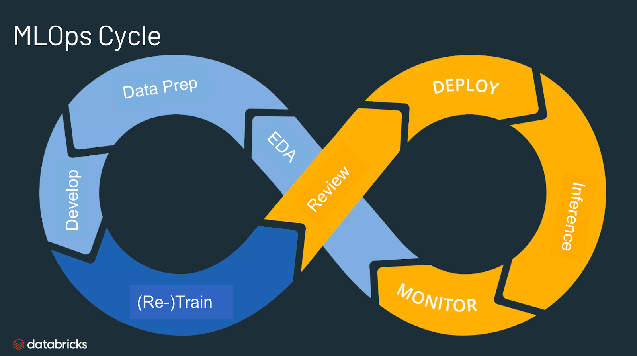
Quelle est l'utilité des MLOps ?
Les MLOps offrent une approche utile pour encadrer la création et la qualité des solutions de machine learning et d'IA. En adoptant les MLOps, les data scientists et les ingénieurs en machine learning collaborent plus facilement. Grâce aux pratiques de déploiement et d'intégration continus (CI/CD), qui assurent la qualité de la supervision, de la validation et de la gouvernance des modèles ML, les équipes développent et produisent plus rapidement des modèles.
Pourquoi avons-nous besoin des MLOps ?
Le machine learning est difficile à mettre en production. Le cycle de vie du machine learning comprend de nombreux composants complexes : ingestion des données, préparation, entraînement des modèles, ajustement et déploiement, surveillance des modèles, explicabilité et bien plus encore. Il nécessite également la collaboration et des passages de relais entre différentes équipes : data engineering, data science et ingénierie ML. Et bien sûr, tous ces processus doivent être synchronisés et coordonnés avec la plus grande rigueur opérationnelle. Les MLOps englobent l'expérimentation, l'itération et l'amélioration continue du cycle de vie du machine learning.
Quels sont les avantages des MLOps ?
Les principaux atouts des MLOps sont l'efficacité, l'évolutivité et la réduction des risques. Efficacité : les MLOps permettent aux équipes de données d'accélérer le développement des modèles, de produire des modèles ML de qualité supérieure, et de passer plus rapidement au déploiement et à la production. Évolutivité : les MLOps offrent des possibilités de gestion à très grande échelle. Des milliers de modèles peuvent ainsi être supervisés, contrôlés, gérés et surveillés à des fins d'intégration, de livraison et de déploiement continus. Spécifiquement, les MLOps permettent la reproductibilité des pipelines de ML et facilitent une collaboration plus étroite entre les équipes de données en réduisant les conflits avec les DevOps et l'IT, ce qui a pour effet de réduire le délai de publication. Réduction des risques : les modèles de machine learning doivent souvent faire l'objet d'examens réglementaires et de contrôle de dérive. Les MLOps apportent davantage de transparence et de réactivité vis-à-vis de ces obligations. C'est l'assurance d'une conformité plus grande aux politiques de l'entreprise ou du secteur.
Quels sont les composants des MLOps ?
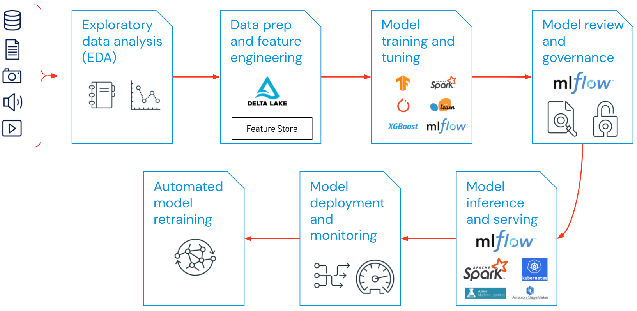
Dans un projet de machine learning, le périmètre d'action des MLOps peut être aussi ciblé ou large qu'il le faut. Dans certains cas, les MLOps peuvent englober l'intégralité des étapes allant du pipeline de données à la production du modèle, tandis que d'autres ne feront intervenir les MLOps que pour le processus de déploiement du modèle. Une majorité d'entreprises applique les principes MLOps aux activités suivantes :
- Analyse exploratoire des données (EDA)
- Préparation des données et ingénierie des fonctionnalités
- Entraînement et ajustement des modèles
- Examen et gouvernance des modèles
- Inférence et mise à disposition des modèles
- Supervision des modèles
- Réentraînement automatisé des modèles
Le guide pratique de l'IA agentique pour l'entreprise

Quelles sont les bonnes pratiques des MLOps ?
Les bonnes pratiques des MLOps dépendent de la phase à laquelle les principes MLOps sont appliqués.
- Analyse exploratoire des données (EDA) : explorez, partagez et préparez les données par itération pour le cycle de vie du machine learning en créant des datasets, des tables et des visualisations que vous pourrez ensuite reproduire, éditer et partager.
- Préparation des données et ingénierie des fonctionnalités : transformez, agrégez et dédupliquez les données par itération pour créer des fonctionnalités sophistiquées. Surtout, mettez ces fonctionnalités à disposition de toutes les équipes de données au sein d'un magasin de fonctionnalités.
- Entraînement et ajustement des modèles : utilisez des bibliothèques open source populaires comme scikit-learn et hyperopt pour entraîner les modèles et améliorer leurs performances. Une alternative, plus simple, consiste à utiliser des outils de machine learning automatisés comme AutoML pour effectuer automatiquement des cycles d'essai et créer du code facile à examiner et à déployer.
- Examen et gouvernance des modèles : suivez la généalogie des modèles et leurs versions, et gérez les artefacts et les transitions tout au long de leur cycle de vie. Découvrez et partagez des modèles ML pour collaborer entre équipes à l'aide d'une plateforme MLOps open source comme MLflow.
- Inférence et mise à disposition des modèles : gérez la fréquence d'actualisation des modèles, le délai des requêtes d'inférence et d'autres spécificités de production du même type en phase de test et de QA. Utilisez des outils CI/CD comme les dépôts et les orchestrateurs pour automatiser le pipeline de pré-production en vous inspirant des principes DevOps.
- Déploiement et surveillance des modèles : automatisez la gestion des permissions et la création de clusters pour mettre en production des modèles enregistrés. Utilisez des points de terminaison de modèles API REST
- Réentraînement automatisé des modèles : créez des alertes et des automatisations pour prendre des mesures de correction en cas de dérive due à un écart entre les données d'entraînement et d'inférence.
Quelle est la différence entre les MLOps et les DevOps ?
Les MLOps sont un ensemble de pratiques d'ingénierie propres aux projets de machine learning qui s'inspirent des principes DevOps largement adoptés dans l'ingénierie logicielle. Les DevOps proposent une approche rapide, itérative et continue de la livraison d'applications. Les MLOps appliquent ces principes à la mise en production des modèles de machine learning. Dans les deux cas, le résultat est le même : des logiciels de meilleure qualité, des versions et des correctifs publiés plus rapidement, et une satisfaction client accrue.
Est-ce que l'entraînement des grands modèles de langage (LLMOps) diffère des MLOps traditionnelles ?
Si un grand nombre de concepts MLOps s'appliquent aussi aux LLM, d'autres facteurs interviennent dans l'entraînement de grands modèles comme Dolly. Voyons les différences clés qui séparent l'entraînement des LLM de l'approche MLOps classique :
- Ressources de calcul : l'entraînement et l'ajustement de grands modèles de langage implique généralement des quantités de calcul supérieures de plusieurs ordres de grandeur sur de grands ensembles de données. Pour accélérer ce processus, du matériel spécialisé est utilisé, comme des GPU bien plus performants pour réaliser des opérations en parallèle. L’accès à ces ressources de calcul spécialisées devient essentiel pour l’entraînement comme pour le déploiement des grands modèles de langage. Le coût de l’inférence peut également faire de la compression des modèles et des techniques de distillation un facteur clé.
- Apprentissage par transfert : contrairement à de nombreux modèles de ML traditionnels créés et entraînés à partir de zéro, beaucoup de LLM s'appuient sur un modèle de base. Ils sont ajustés à l'aide de nouvelles données pour améliorer leurs performances dans un domaine plus spécifique. Cet ajustement permet d’atteindre des performances de pointe dans des applications spécifiques utilisant moins de données et de ressources de calcul.
- Feedback humain : l'entraînement des grands modèles de langage a connu une amélioration considérable avec l'apprentissage par renforcement qui implique un feedback humain (Reinforcement learning from human feedback / RLHF). Plus généralement, dans la mesure où les tâches LLM sont souvent très ouvertes, le feedback humain des utilisateurs finaux de votre application est essentiel pour évaluer les performances de votre modèle. L'intégration de cette boucle de feedback dans vos pipelines LLMOps peut souvent accroître les performances de votre grand modèle de langage entraîné.
- Ajustement des hyperparamètres : avec le ML classique, l'ajustement des hyperparamètres est souvent axé sur l'amélioration de la précision ou d'autres métriques. Pour les LLM, l’ajustement est également crucial pour réduire le coût, ainsi que les besoins en puissance de calcul de l’entraînement et de l’inférence. Par exemple, de petites modifications des tailles de lot et des taux d’apprentissage peuvent considérablement affecter la vitesse et le coût de l’entraînement. Par conséquent, le ML classique comme les LLM bénéficient du suivi et de l'optimisation du processus d'ajustement, mais à différents degrés.
- Métriques de performance : les modèles ML traditionnels ont des métriques de performance très clairement définies, comme la précision, l'AUC, le score F1, etc. Ces métriques sont assez simples à calculer. Mais lorsqu'il s'agit d'évaluer les LLM, c'est un tout autre ensemble de métriques standards et de scores qui s'applique. Pensez par exemple aux métriques BLEU (Bilingual Evaluation Understudy) et ROUGE (Recall-Oriented Understudy for Gisting Evaluation), qui demandent une attention particulière lors de leur implémentation.
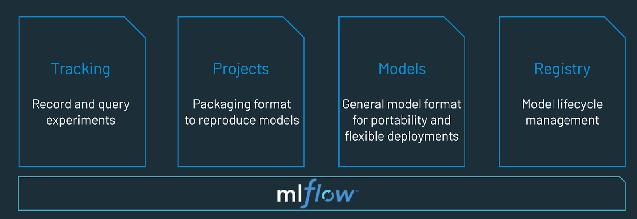
Qu'est-ce qu'une plateforme MLOps ?
Une plateforme MLOps offre aux data scientists et aux ingénieurs logiciels un environnement de collaboration qui facilite l'exploration des données par itération, offre des capacités de collaboration en temps réel à des fins de suivi expérimental, d'ingénierie de fonctionnalités et de gestion de modèles. Elle permet également de contrôler la transition, le déploiement et la surveillance des modèles. Une plateforme MLOps automatise les aspects opérationnels et de synchronisation du cycle de vie du machine learning.
Essayez Databricks, un environnement entièrement managé pour MLflow, la plateforme MLOps ouverte numéro 1. https://www.databricks.com/try/databricks-free-ml
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.