Des pipelines de données fiables en toute simplicité
Simplifiez l'ETL par batch et en streaming en automatisant la fiabilité et la qualité des donnée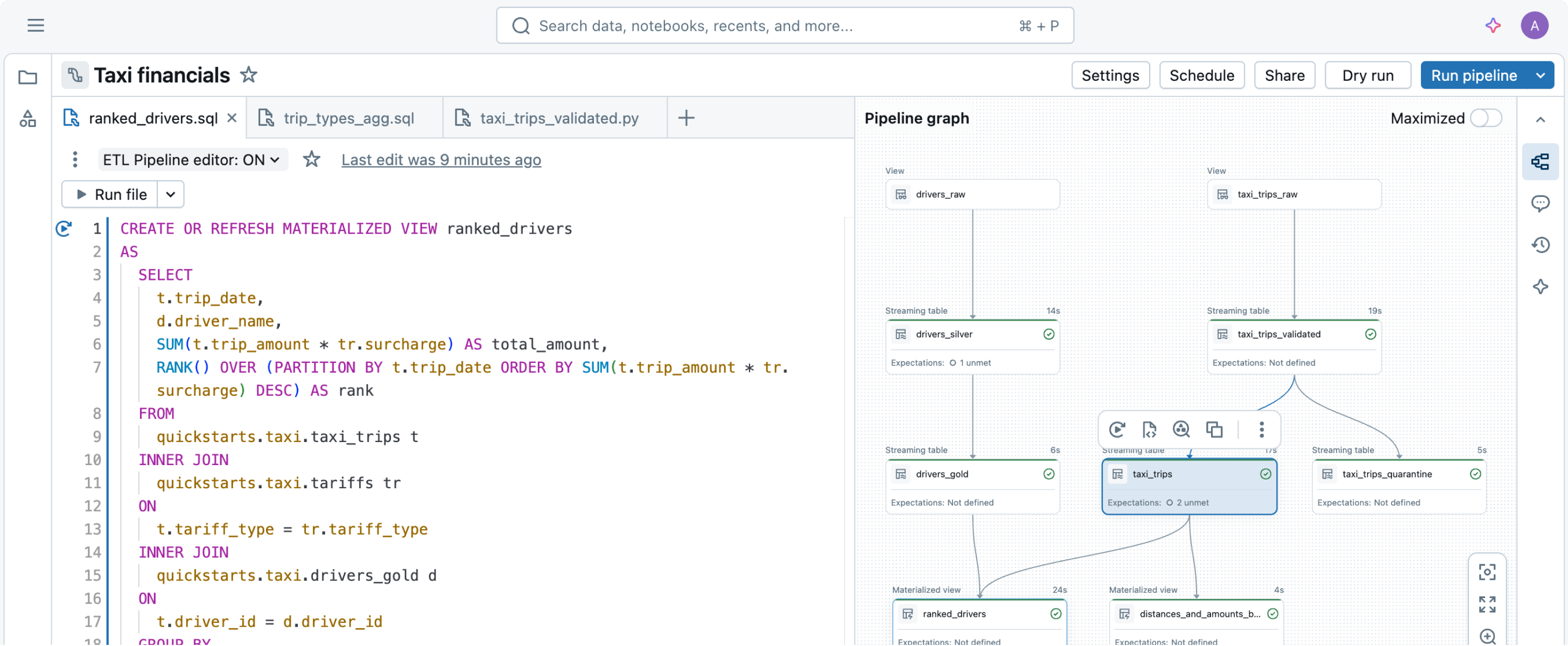
LES ÉQUIPES LES PLUS PERFORMANTES CHOISISSENT DES PIPELINES DE DONNÉES INTELLIGENTS
Encoder les bonnes pratiques des pipelines de données
Déclarez simplement les transformations de données dont vous avez besoin, et laissez les pipelines déclaratifs Lakeflow faire le reste.Efficacité de l'ingestion
La création de pipelines ETL prêts pour la production commence par l’ingestion. Les pipelines déclaratifs Lakeflow permettent une ingestion efficace pour les data engineers, les développeurs Python, les data scientists et les analystes SQL. Chargez des données à partir de n'importe quelle source compatible avec Apache Spark™ sur Databricks, par batch, en streaming ou en CDC.
Transformation intelligente
En quelques lignes de code seulement, les pipelines déclaratifs Lakeflow déterminent la meilleure façon de créer et d’exécuter vos pipelines de données en streaming ou en batch, afin d'optimiser automatiquement le coût ou la performance tout en minimisant la complexité.
Opérations automatisées
Spark Declarative Pipelines simplifie le développement de pipelines en codifiant les bonnes pratiques prêtes à l'emploi, en automatisant la gestion des dépendances, la mise à l'échelle et la récupération, les règles de qualité des données et plus encore. Grâce aux pipelines déclaratifs Lakeflow, les ingénieurs peuvent se consacrer à fournir des données de haute qualité plutôt qu'à administrer et maintenir l'infrastructure des pipelines.
Pensé pour simplifier la création de pipeline de données
Créer et exploiter des pipelines de données n'a rien de simple, mais ce n'est pas une fatalité. Les pipelines déclaratifs Lakeflow sont conçus pour conjuguer simplicité et puissance pour mettre sur pied un ETL robuste en quelques lignes de code.Utilisez Genie Code pour automatiser les charges de travail ETL, optimiser les requêtes et créer des pipelines grâce à une conversation naturelle.
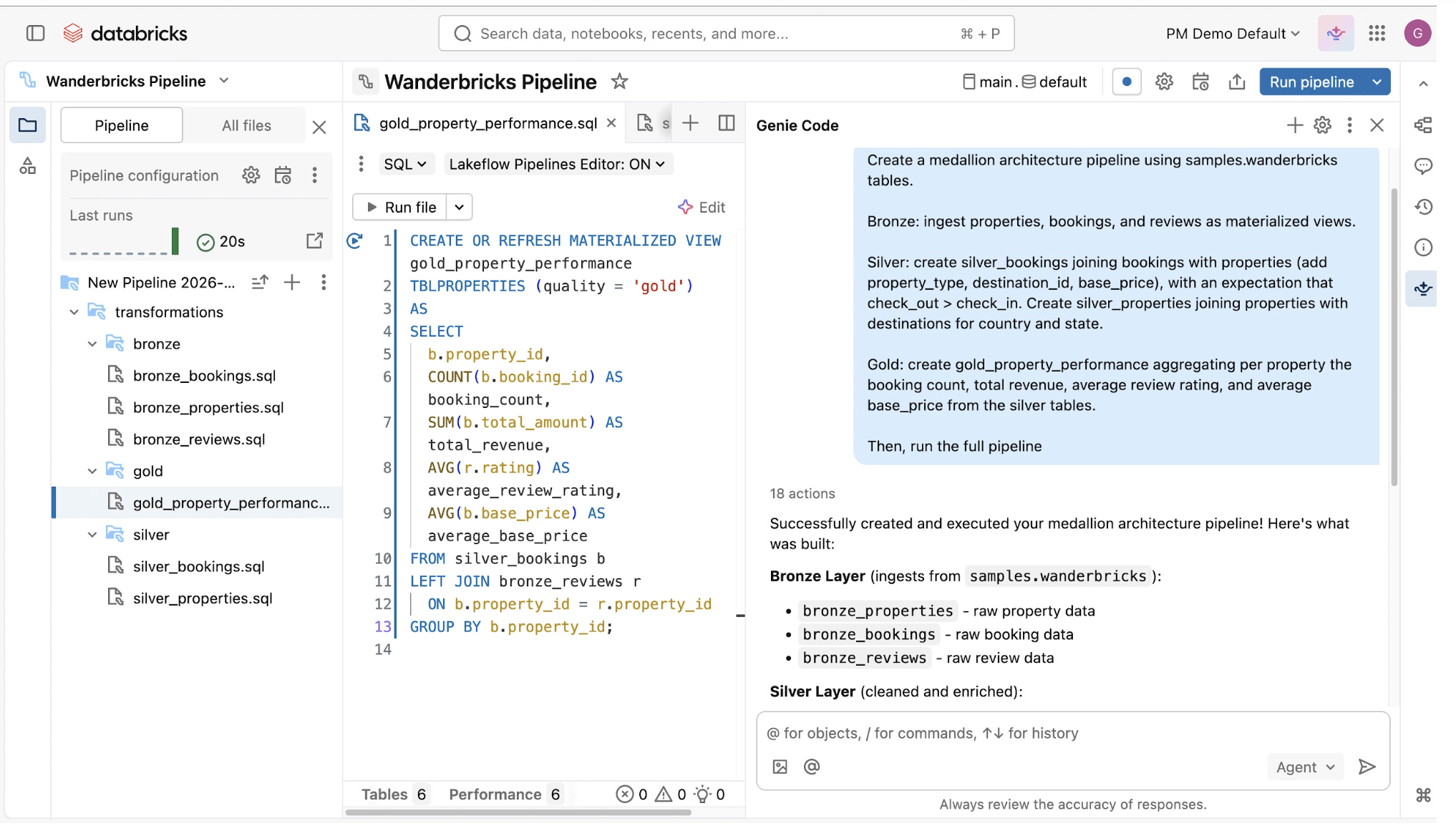
Grâce à l'API unifiée de Spark pour le traitement par batch et en streaming, les pipelines déclaratifs Lakeflow vous permettent d'alterner facilement entre les modes de traitement.

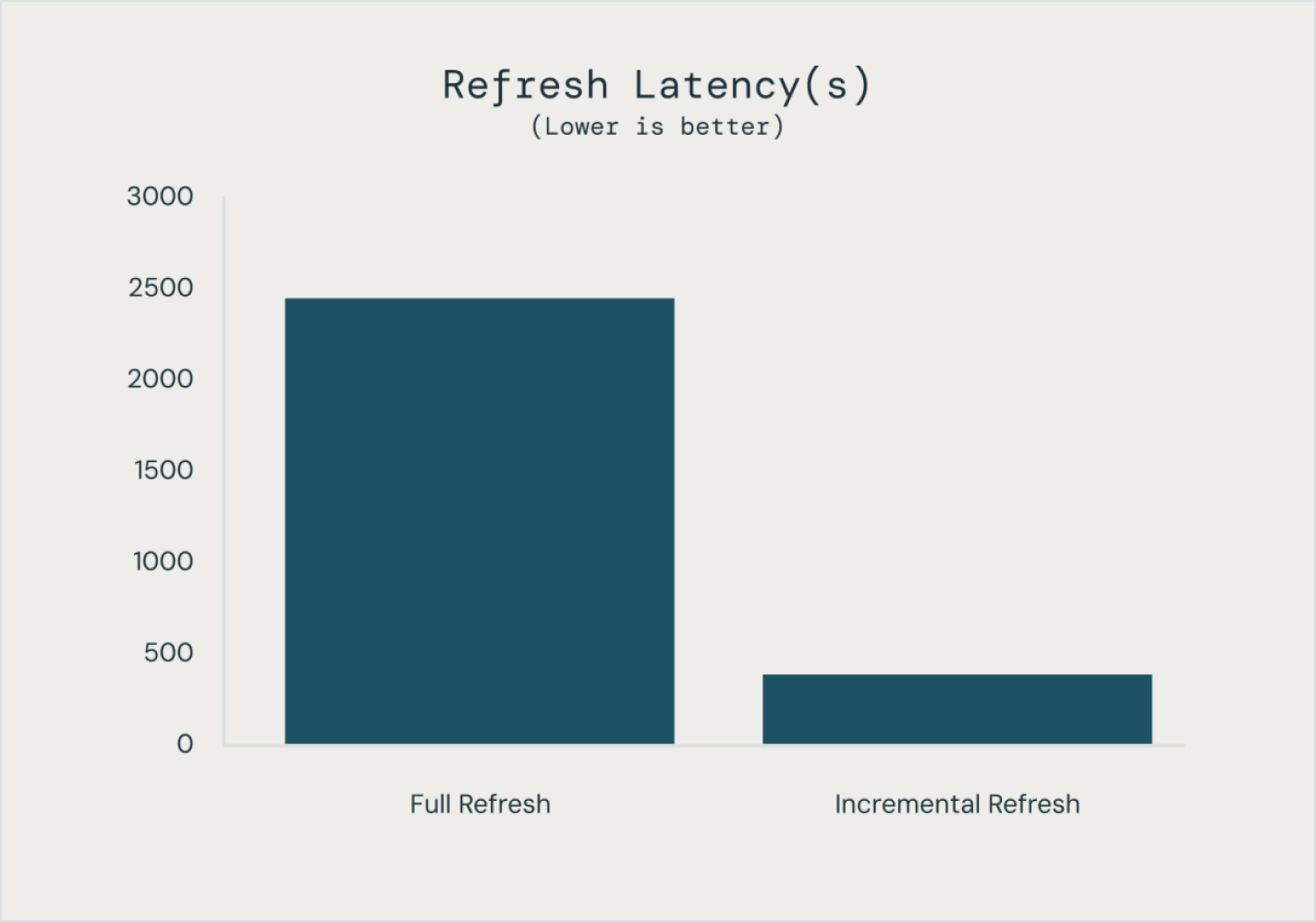
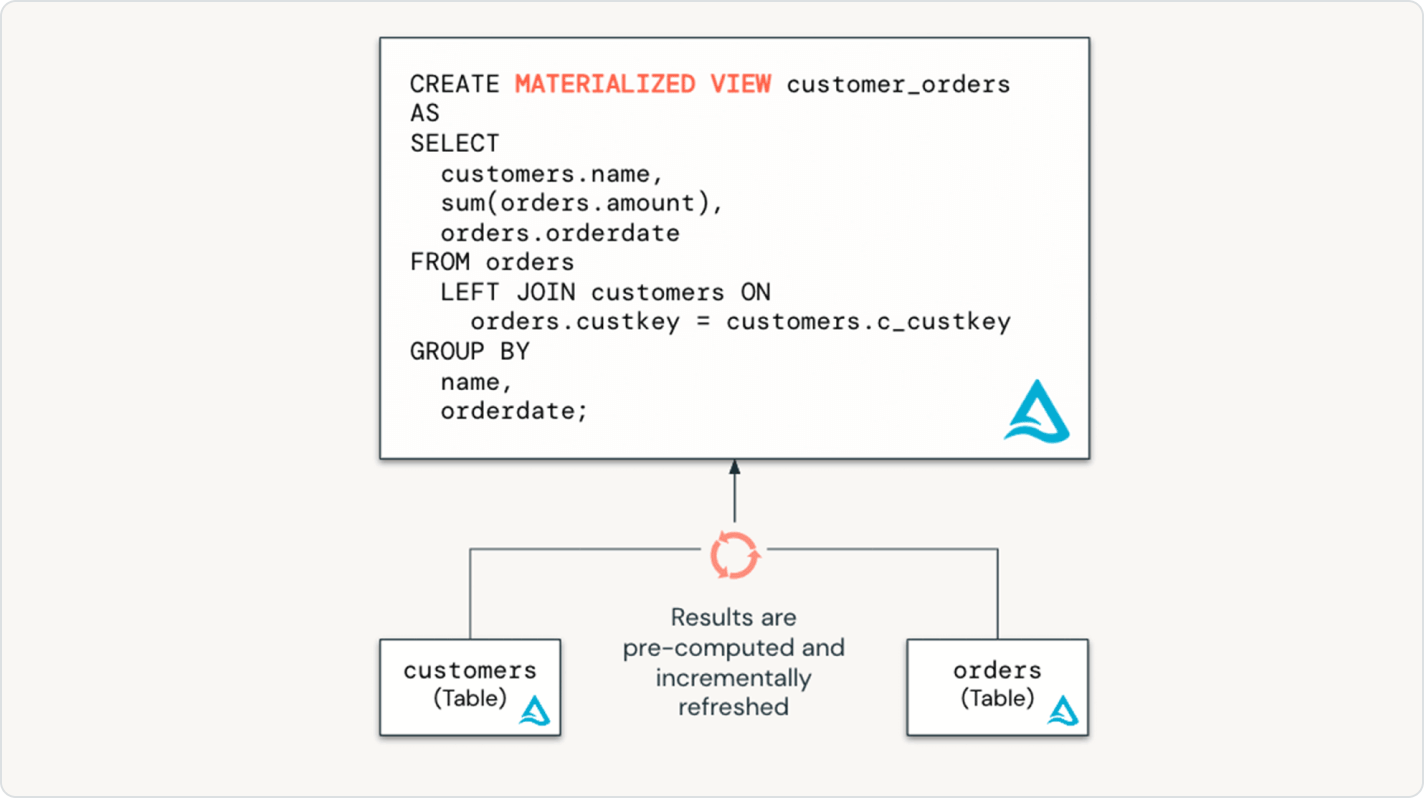
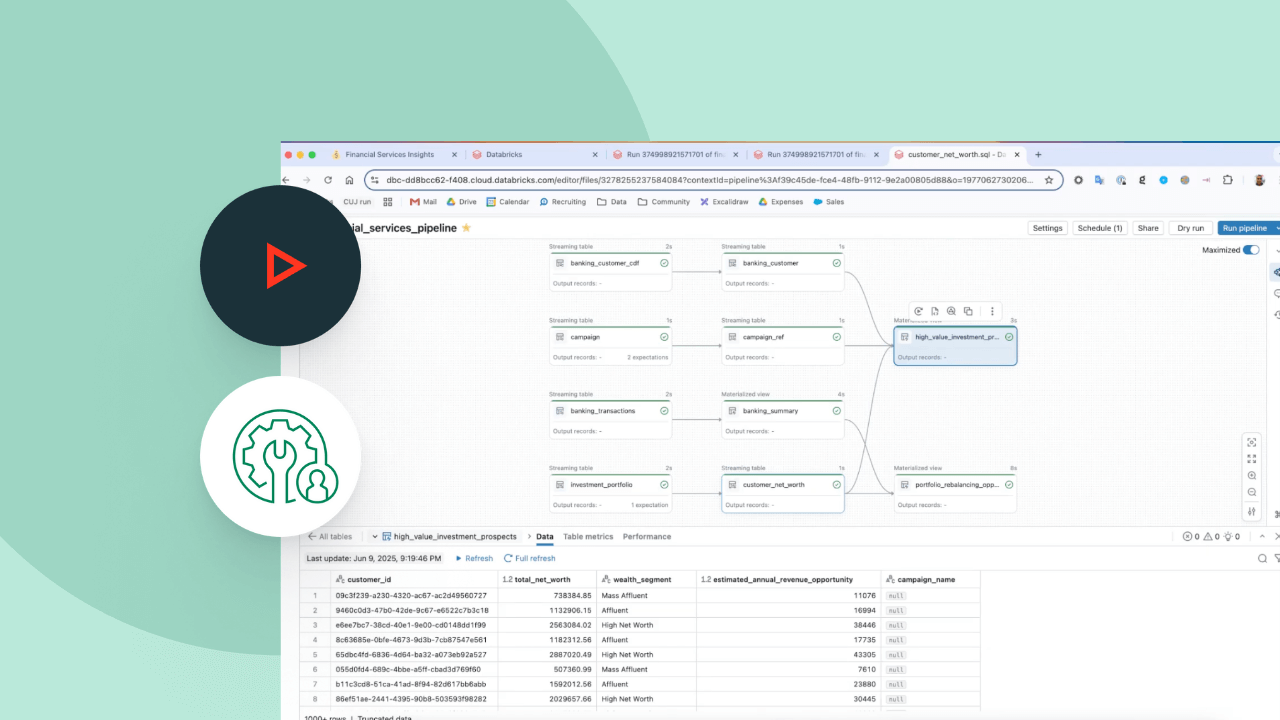
Les pipelines déclaratifs Lakeflow permettent d'optimiser facilement les performances du pipeline en déclarant un pipeline de données incrémentiel complet, accompagné de tables de streaming et de vues matérialisées.
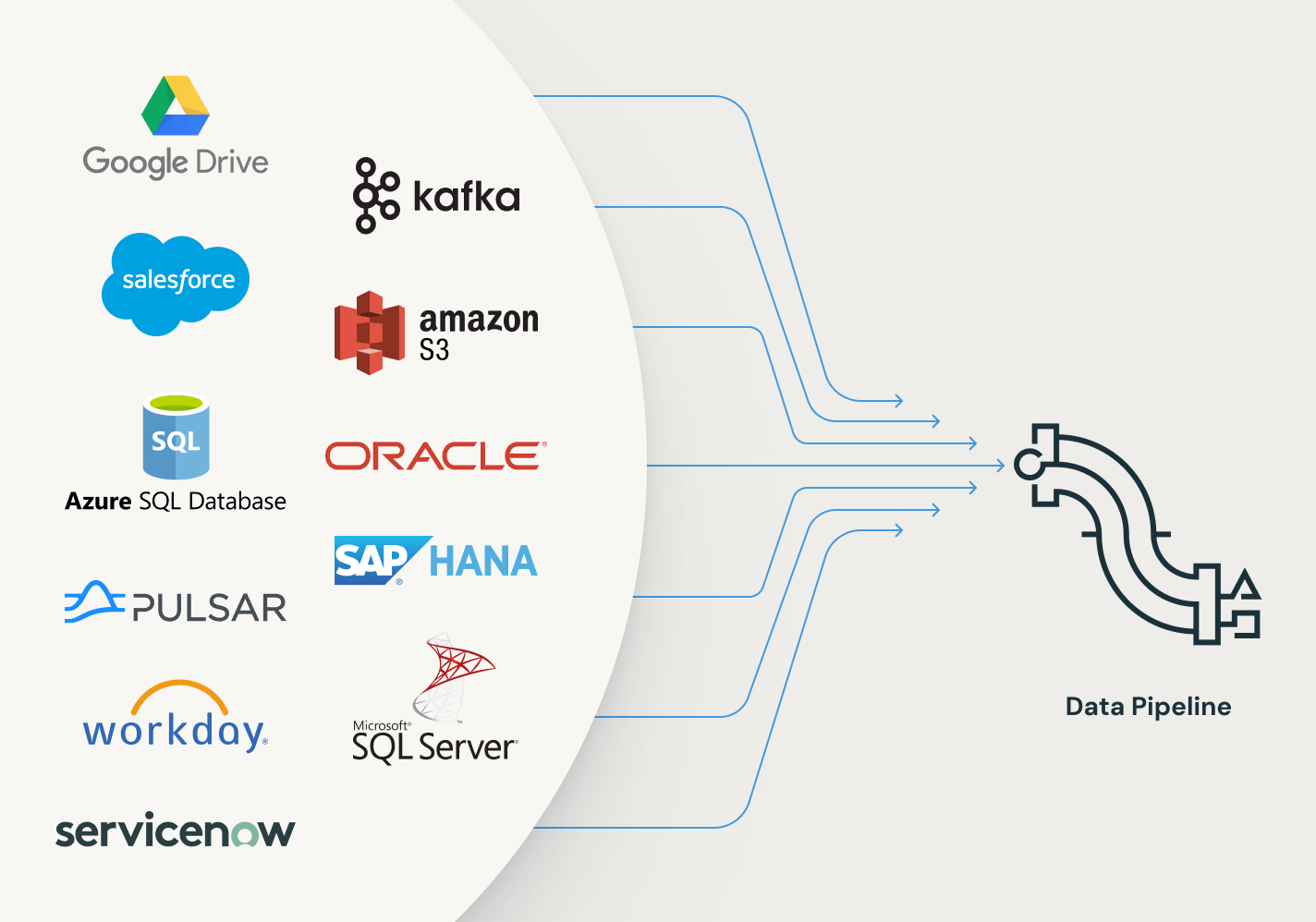
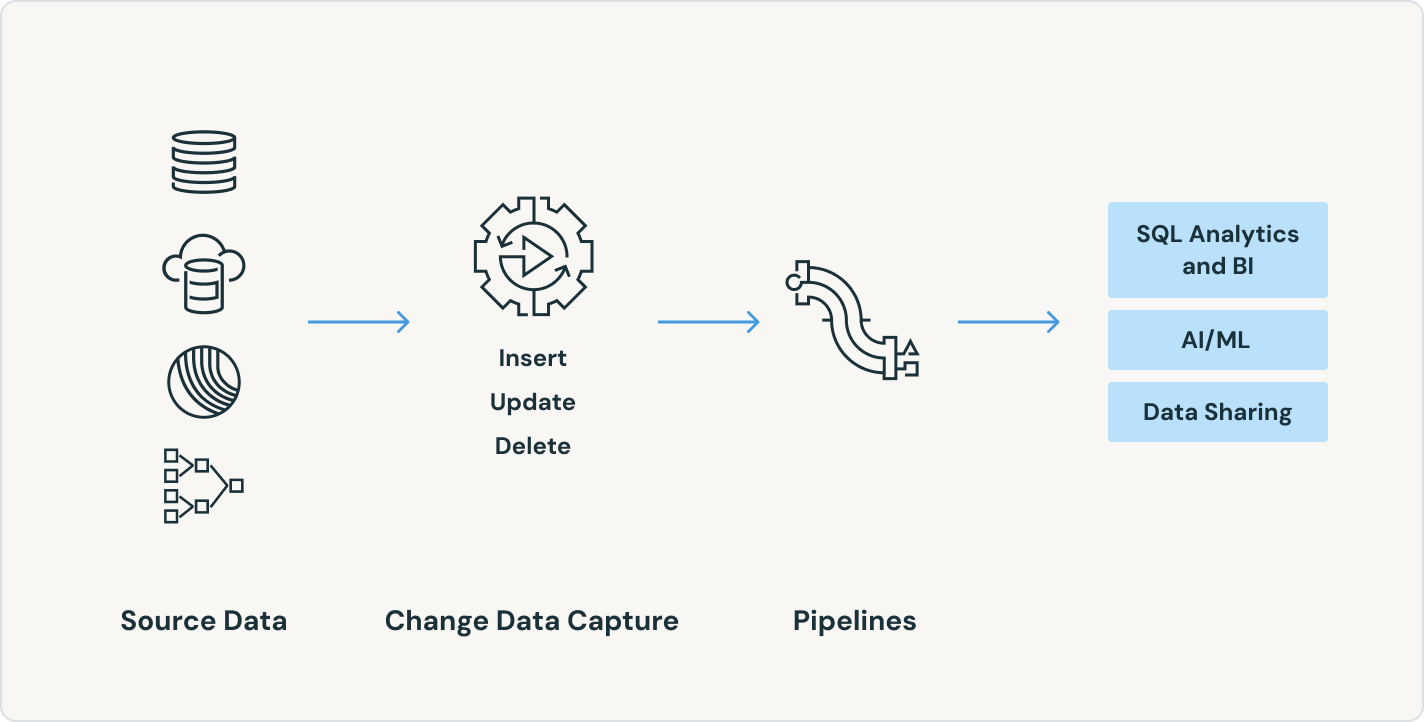
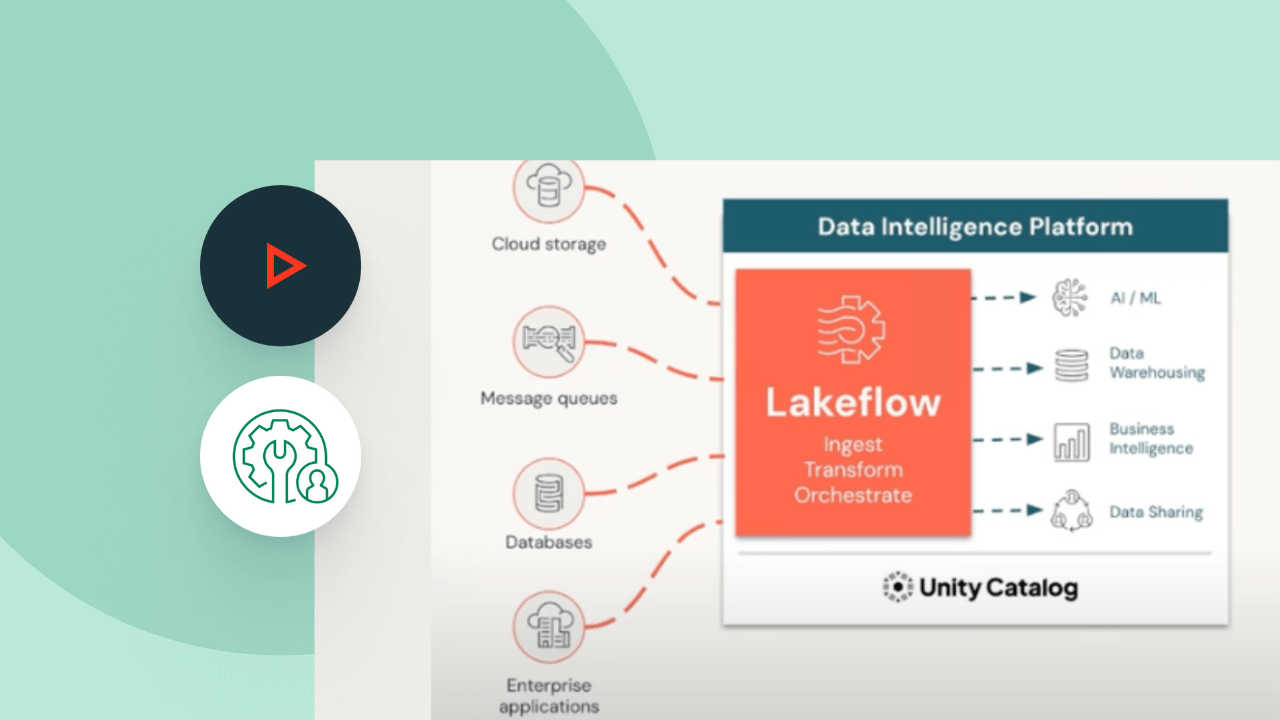
Les pipelines déclaratifs Lakeflow prennent en charge un large écosystème de sources et de dépôts. Chargez les données de n'importe quelle source : stockage cloud, bus de messages, flux de données de changement, bases de données et applications d'entreprise.
Définissez des attentes pour garantir que les données arrivant dans les tables répondent à vos exigences de qualité, et obtenez des informations sur la qualité des données à chaque mise à jour des pipelines.
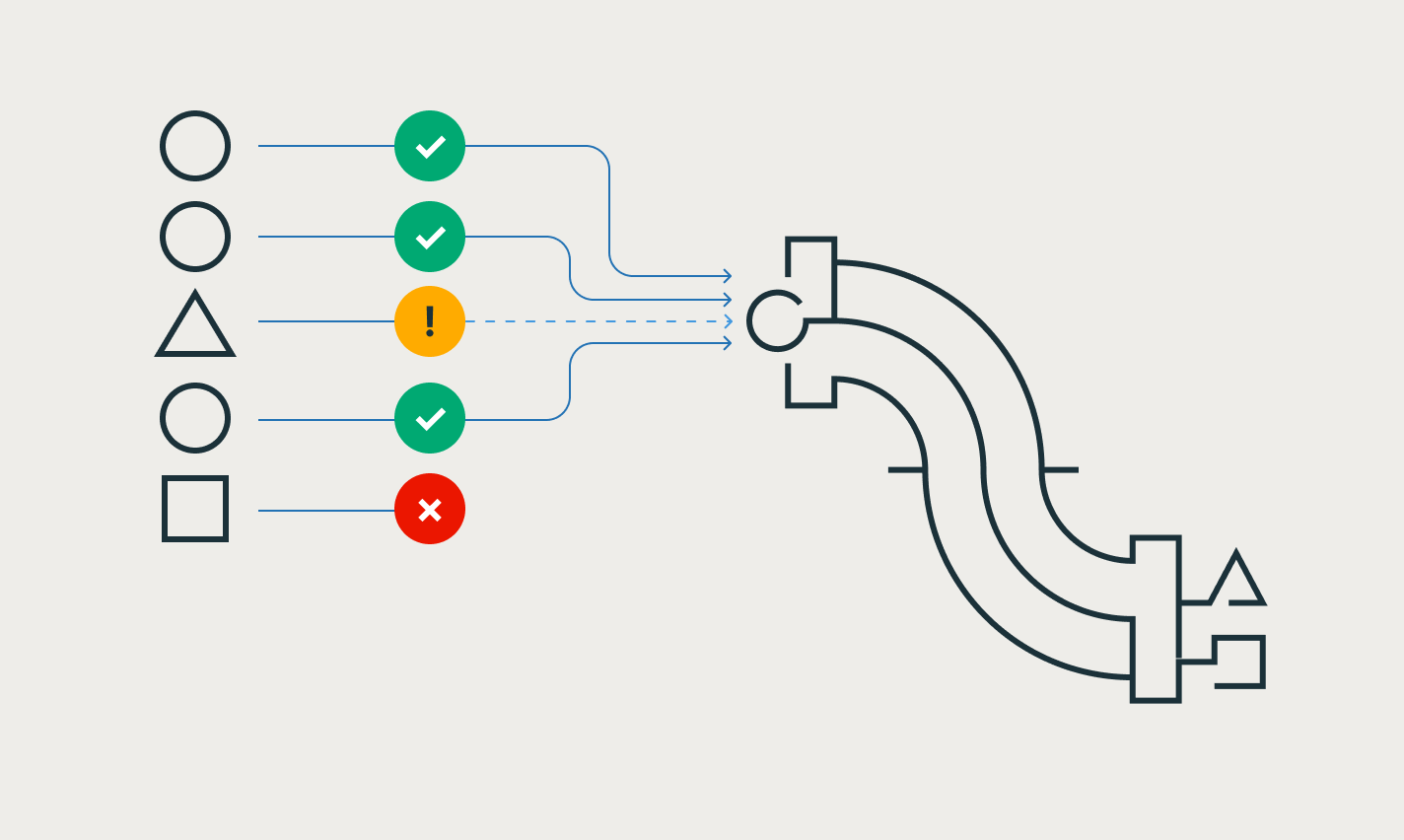
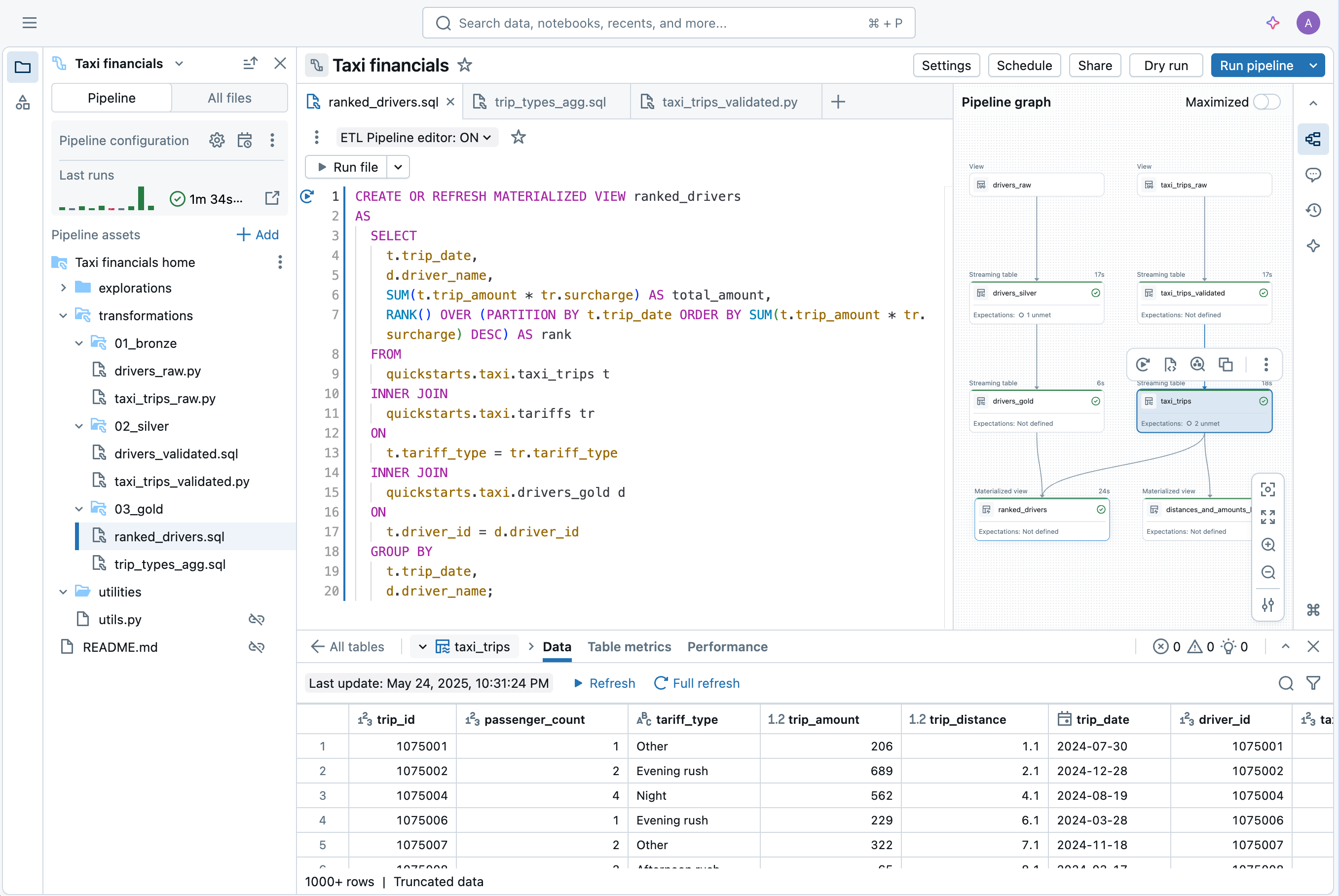
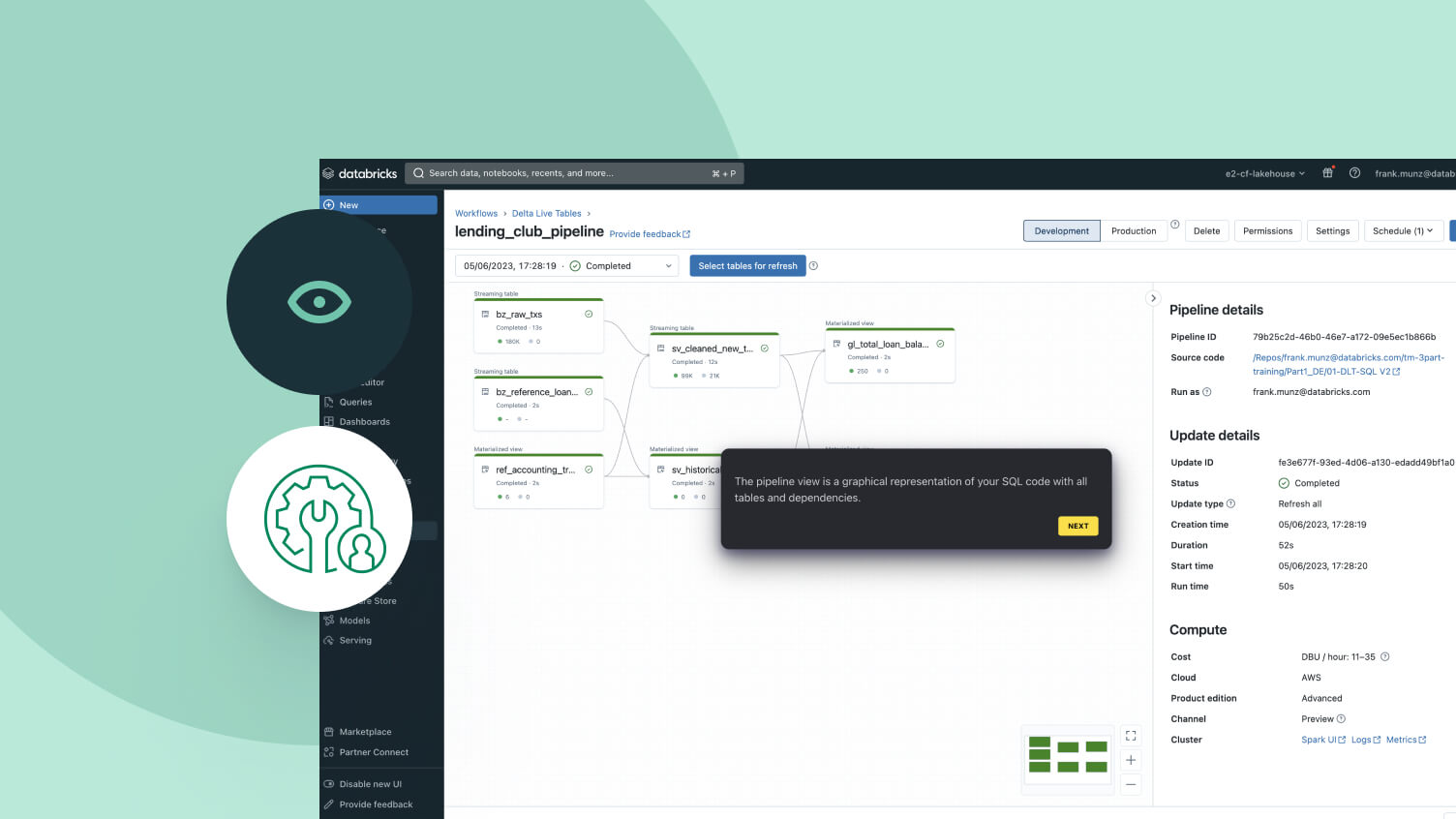
Développez des pipelines dans l'IDE de data engineering sans changer de contexte. Visualisez le DAG, l'aperçu des données et les informations d'exécution dans une seule interface utilisateur. Développez facilement du code avec l'autocomplétion, l'affichage intégré des erreurs et les diagnostics.
Autres fonctionnalités
Rationalisez vos pipelines de données

Simplifiez la gestion des sources, des transformations et des destinations simples
Grâce à la programmation déclarative, vous pouvez exploiter la puissance de l'ETL sur la Data Intelligence Platform en quelques lignes de code.
Les tarifs basés sur l'utilisation permettent de maîtriser les dépenses
Ne payez que les produits que vous utilisez, à la seconde près.En savoir plus
Explorez d'autres offres intelligentes et intégrées sur la Databricks Platform.
LakeFlow Connect
Avec des connecteurs d'ingestion de données efficaces pour tous les types de source et une intégration native à la Databricks Platform, les équipes accèdent en toute simplicité à l'analytique et à l'IA avec une gouvernance unifiée.

Tâches Lakeflow
Définissez, gérez et supervisez en toute simplicité des workflows multitâche pour vos pipelines ETL, d'analytique et de machine learning. Grâce à la prise en charge d'un large éventail de types de tâches, une observabilité approfondie et une grande fiabilité, vos équipes sont en mesure de mieux automatiser et orchestrer tout type de pipeline pour gagner en productivité.

Genie Code
Votre partenaire IA autonome pour travailler avec les données

Stockage en lakehouse
Unifiez les données du lakehouse, quels que soient leur format et leur type, pour les mettre à disposition de toutes vos charges d'analytique et d'IA.

Unity Catalog
Encadrez sans problème tous vos assets de données avec la seule solution de gouvernance unifiée et ouverte de l'industrie pour les données et l'IA, intégrée à la Databricks Platform.
La Databricks Platform
Découvrez comment la Databricks Platform prend en charge vos charges de travail de données et d'IA.
Passez à l'étape suivante
Explorez la documentation de Spark Declarative Pipelines
Tout ce dont vous avez besoin pour commencer à utiliser des pipelines déclaratifs Lakeflow sur les environnements AWS, Microsoft Azure ou Google Cloud Platform.
Démarrez votre essai gratuit
Essayez gratuitement la plateforme Databricks dans son intégralité.




Pipelines déclaratifs Spark
Prêts à devenir une entreprise axée sur les données et l'IA ?
Faites le premier pas de votre transformation