Simplifier le cycle de vie du machine learning
Passez des silos organisationnels et technologiques à une plateforme ouverte et unifiée, au service de l'intégralité du cycle de vie des données et du ML.

Développer des modèles ML est ardu. Les mettre en production l'est plus encore. Il faut maintenir la qualité des données et la précision du modèle au fil du temps, et ce n'est pas le seul défi à relever. Databricks est une plateforme unique qui rationalise le développement du ML, de la préparation des données au déploiement, en passant par l'entraînement des modèles, à grande échelle.
Les défis
La diversité considérable des frameworks ML ajoute beaucoup de complexité aux environnements ML.
Les tâches sont difficiles à transmettre d'une équipe à l'autre. En cause : l'hétérogénéité des outils et des processus au fil des étapes de préparation des données, d'expérimentation et de mise en production.
Les difficultés de suivi des expérimentations, des modèles, des dépendances et des artefacts nuisent à la reproductibilité des résultats
Risques de sécurité et de conformité
La solution
Accès en un clic à des environnements de ML prêts à l'emploi, optimisés et évolutifs qui couvrent l'ensemble du cycle de vie
Une même plateforme pour l'importation des données, la création de fonctionnalités, le développement, l'ajustement et la mise en production des modèles, ce qui simplifie considérablement la collaboration des équipes
Suivez automatiquement les expérimentations, le code, les résultats et les artefacts, tout en centralisant la gestion des modèles
Remplissez vos obligations de conformité grâce à un contrôle d'accès granulaire, au data lineage et à la gestion des versions.
Databricks pour le machine learning
Découvrez comment Databricks facilite la collaboration autour de la préparation des données, du développement, du déploiement et de la gestion. Élaborez des modèles ML de pointe, de l'expérimentation à la production, à une échelle sans précédent.
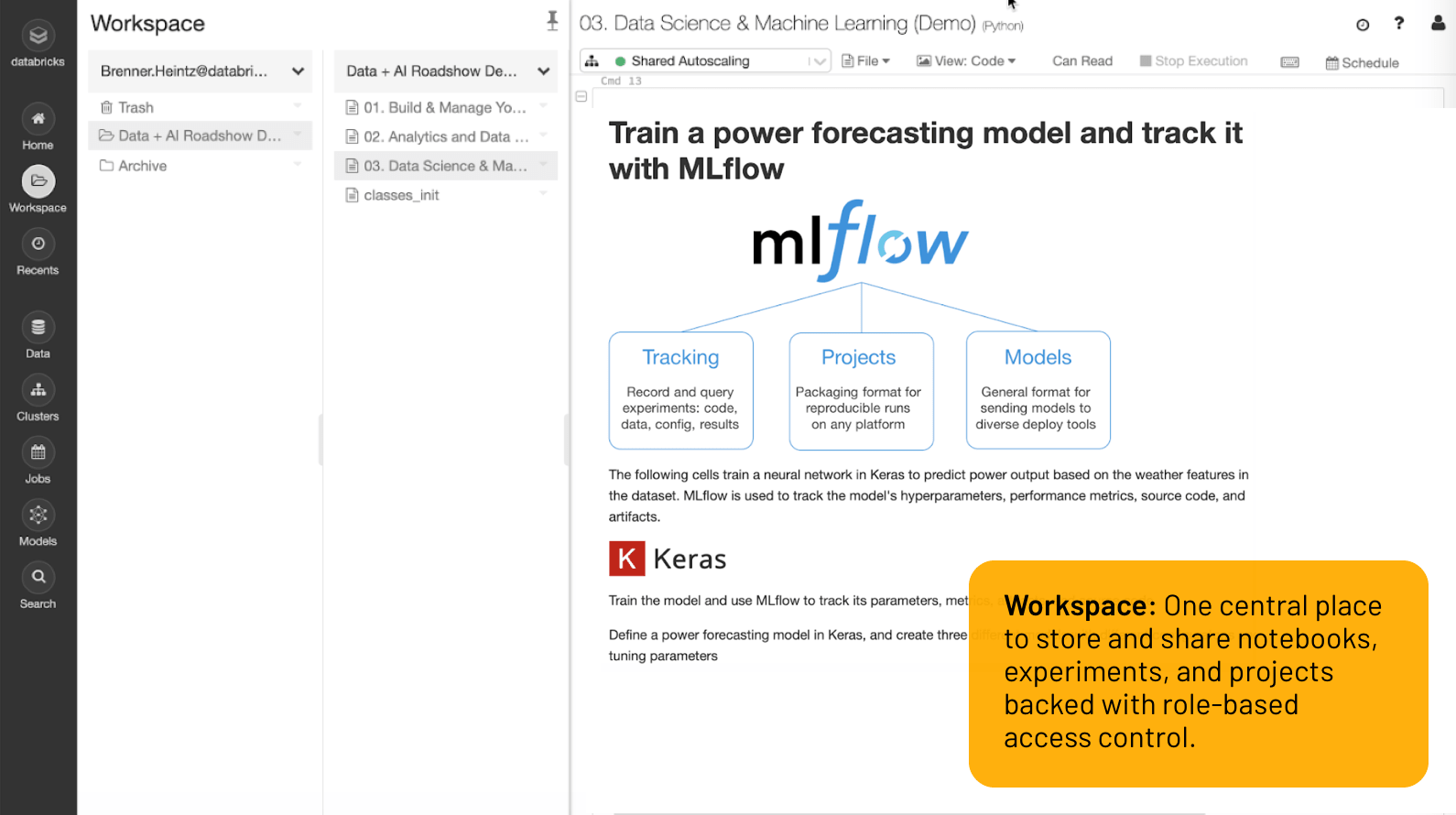
Espace de travail
Un emplacement centralisé pour stocker et partager des notebooks, des expérimentations et des projets, protégé par le contrôle d'accès basé sur les rôles.
De l'expérimentation à la production, le ML à une échelle sans précédent
Un environnement de développement haut de gamme
Tout ce dont vous avez besoin pour faire votre travail est à portée de clic dans l'Espace de travail : datasets, environnements de ML, notebooks, fichiers, expérimentations, modèles... Tout est stocké de façon centralisée et sécurisée.
Les notebooks collaboratifs prennent en charge plusieurs langages (Python, R, Scala, SQL) pour faciliter le co-développement. Et grâce à l'intégration de Git, à la gestion des versions, au contrôle d'accès basé sur les rôles et à bien d'autres outils, vous gardez le contrôle sur tout le processus. Mais vous pouvez également utiliser des outils courants comme Jupyter Lab, PyCharm, IntelliJ, RStudio avec Databricks pour profiter de possibilités illimitées de stockage et de calcul.
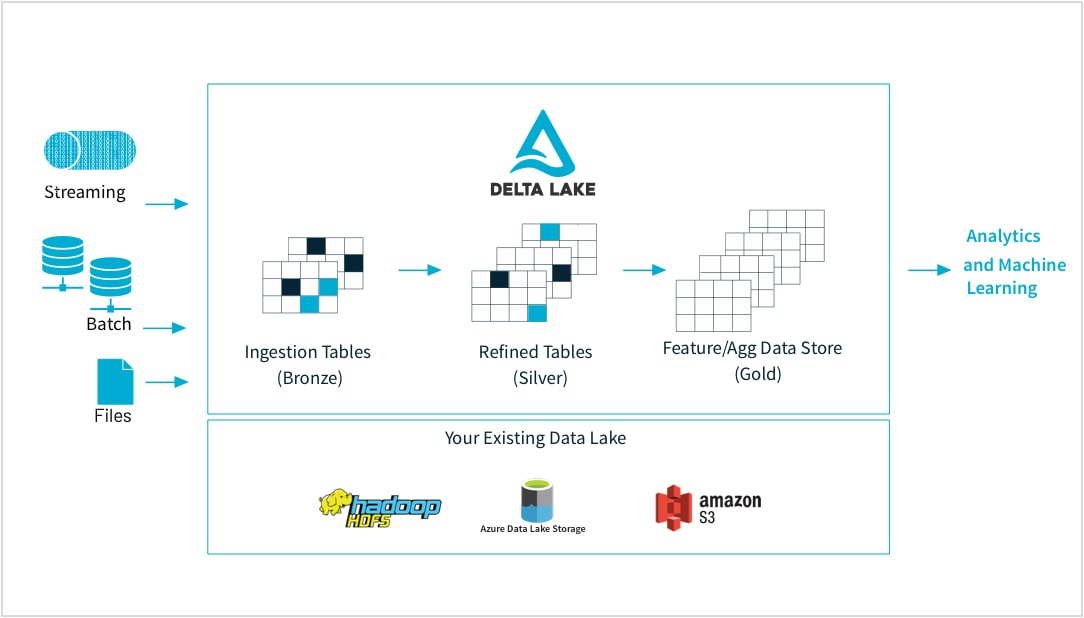
Des données brutes au magasin de fonctionnalités de haute qualité
Les professionnels du machine learning entraînent leurs modèles sur des données très diverses par leur forme et leur nature : petits et grands datasets, DataFrames, texte, images, en batch ou en streaming. Et toutes ces variantes exigent des pipelines et des transformations spécifiques.
Databricks vous permet d'importer des données brutes provenant de presque toutes les sources, de fusionner les données en batch et en streaming, de planifier des transformations, de conserver différentes versions des tables et de réaliser des contrôles de qualité. Tous ces outils garantissent l'intégrité des données qui serviront à réaliser de l'analytique dans le reste de l'organisation. Vous pouvez maintenant travailler de façon fiable et transparente sur n'importe quel type de données, qu'il s'agisse de fichiers CSV ou de données massives importées d'un data lake, selon les besoins de votre application.

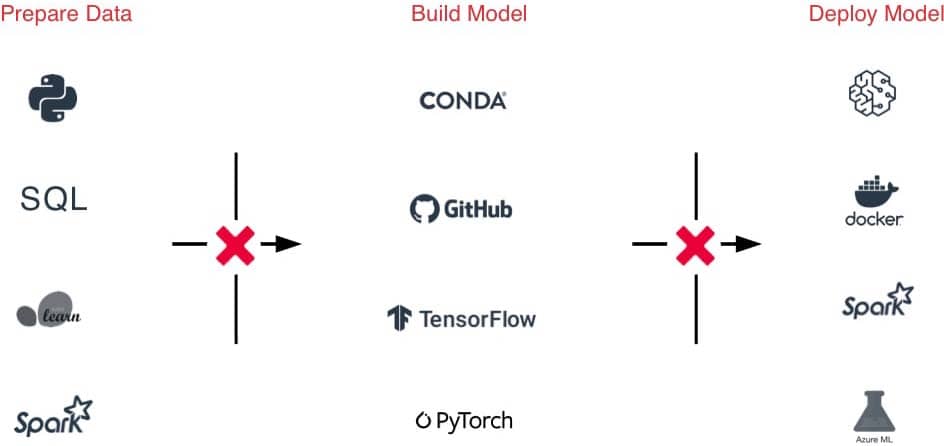
Le meilleur environnement pour scikit-learn, TensorFlow, PyTorch et bien d'autres
Les frameworks ML évoluent à un rythme sans précédent, ce qui complique considérablement la maintenance des environnements. Le runtime ML de Databricks fournit des environnements ML optimisés et prêts à l'emploi. Ceux-ci intègrent les frameworks ML les plus populaires (scikit-learn, TensorFlow, etc.) et prennent en charge Conda.
L'intégration d'AutoML – avec l'ajustement des hyperparamètres, par exemple – permet d'obtenir des résultats plus rapidement et de passer des petits datasets aux big data sans effort. Ne vous inquiétez plus de la capacité de calcul disponible. Vous pouvez, par exemple, entraîner plus rapidement des modèles de deep learning en distribuant le calcul sur vos clusters avec HorovodRunner, et extraire davantage de performance de chaque GPU en exécutant la version optimisée CUDA de TensorFlow.
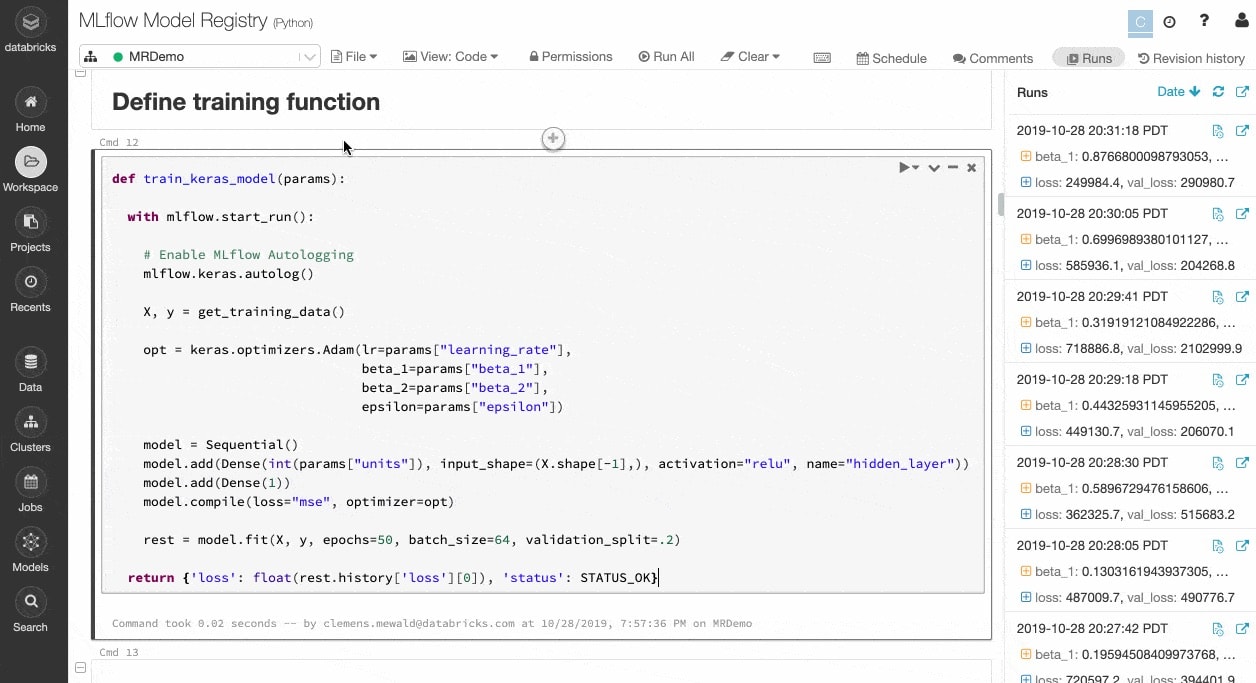
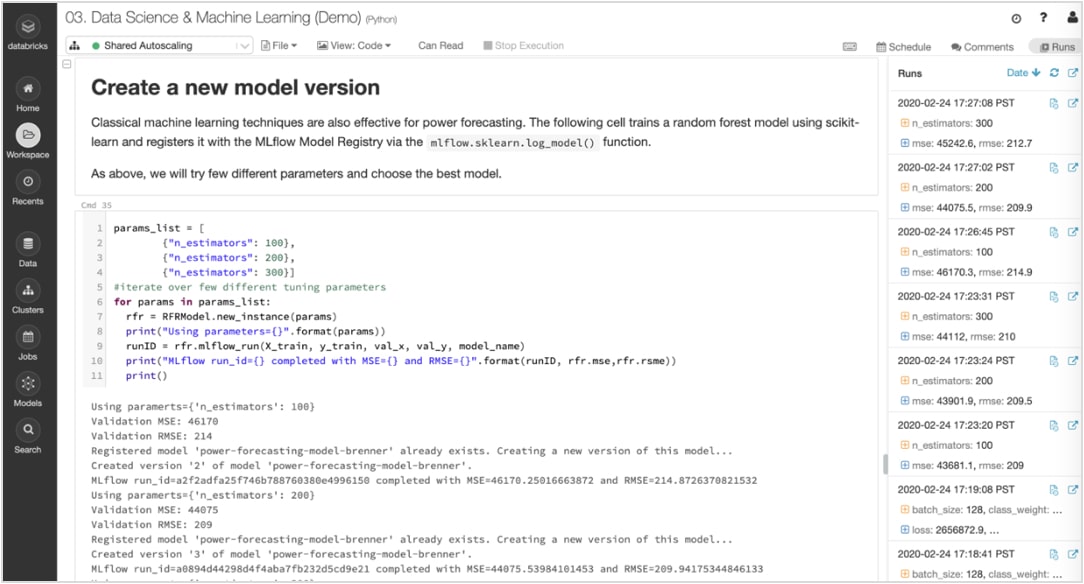
Assurez le suivi des expérimentations et des artefacts pour reproduire vos cycles par la suite
Les algorithmes de ML ont des dizaines de paramètres configurables. Que le travail se fasse seul ou en équipe, il est souvent difficile de suivre les paramètres, le code et les données appliqués à chaque expérimentation.
MLflow assure le suivi automatique de vos expérimentations et de vos artefacts – données, code, paramètres, résultats – pour chaque cycle d'entraînement, directement dans les notebooks. Grâce à cette excellente visibilité sur les cycles précédents, vous pouvez comparer les résultats et revenir à une version antérieure de votre code au besoin. Une fois que vous avez identifié la meilleure version d'un modèle pour la mise en production, enregistrez-la dans un référentiel central pour simplifier le déploiement et la transmission aux autres équipes.
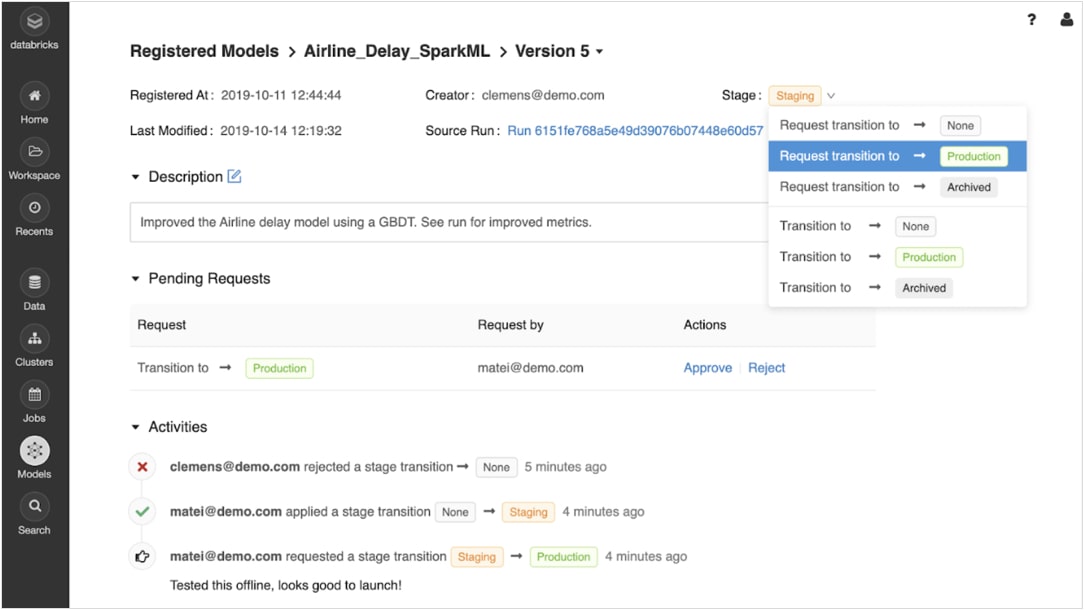
Passez du prototypage à la production en toute confiance
Une fois que les modèles entraînés sont enregistrés, vous pouvez les gérer de manière collaborative, tout au long de leur cycle de vie, à l'aide du registre des modèles de MLflow.
Les modèles peuvent être versionnés et passer par différentes étapes, comme l'expérimentation, la pré-production, la production et l'archivage. Toutes les parties prenantes peuvent ajouter des commentaires et soumettre des requêtes de modification. La gestion du cycle de vie s'intègre entièrement aux workflows d'approbation et de gouvernance, ainsi qu'au contrôle d'accès basés sur les rôles.
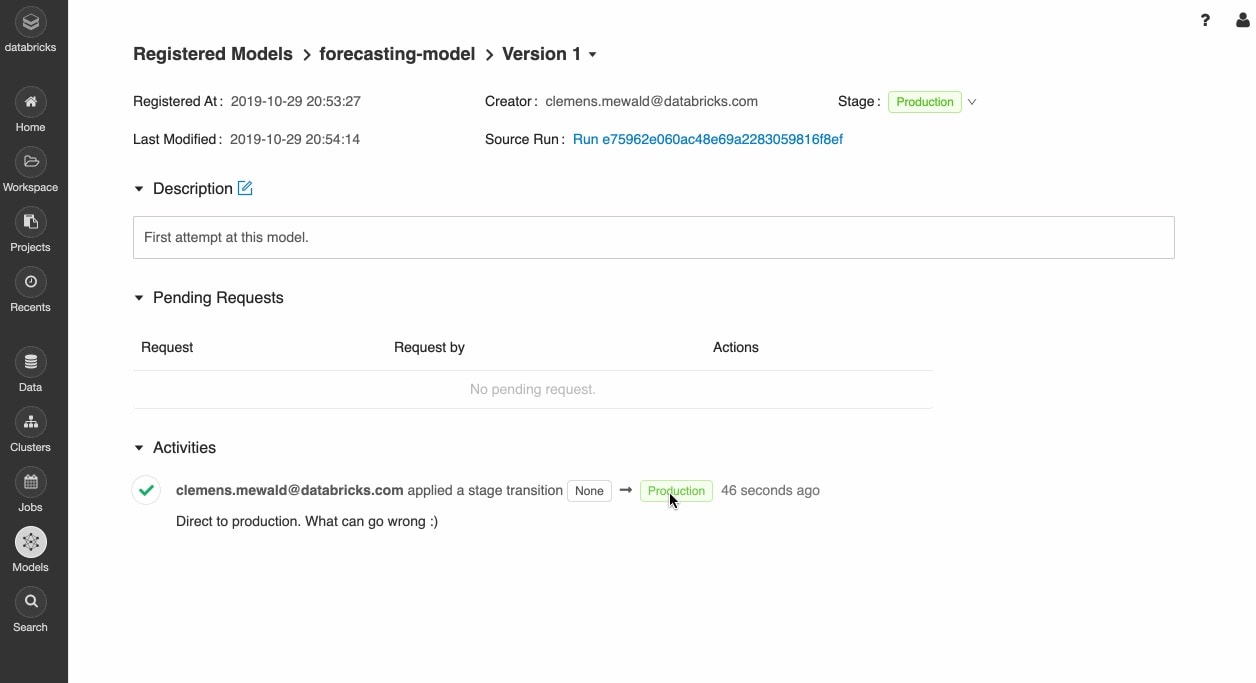
Déployez des modèles partout
Déployez rapidement des modèles en production pour les inférences par batch sur Apache Spark™ ou sous forme d'API REST grâce aux intégrations natives avec les conteneurs Docker, Azure ML et Amazon SageMaker.
Opérationnalisez les modèles de production à l'aide d'ordonnanceurs et de clusters autogérés pour monter en charge en fonction des besoins métier.
Mettez rapidement les dernières versions de vos modèles en production et surveillez la dérive avec Delta Lake et MLflow.
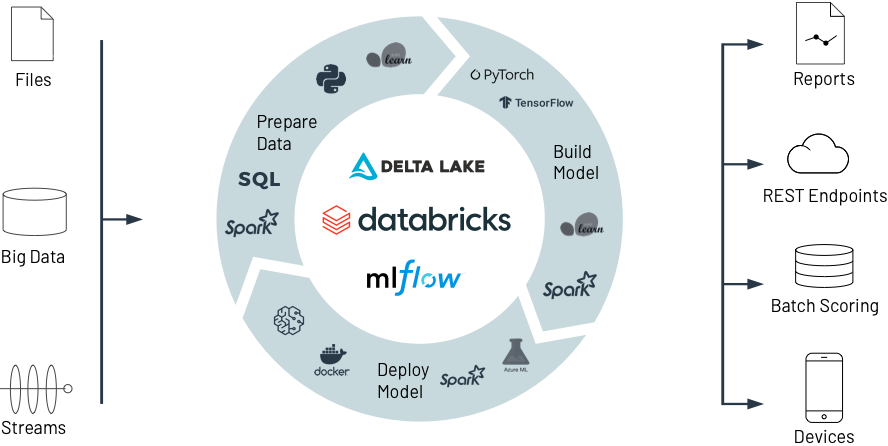
Comment ça marche
L'intégralité du cycle de vie du machine learning centralisé sur Databricks
Ressources
Rapport

e-book

e-book

Ready to get started?