노트북, 워크플로우, Delta Live Tables를 위한 서버리스 컴퓨팅 일반 출시 발표
이제 노트북, 작업, 파이프라인을 실행하기 위한 빠르고 간편한 컴퓨팅을 Azure와 AWS에서 일반적으로 사용할 수 있습니다

AWS와 Azure에서 노트북, 작업, 그리고 Delta Live Tables(DLT)를 위한 서버리스 컴퓨팅의 일반 출시(GA)을 발표하게 되어 기쁩니다. Databricks 고객들은 이미 Databricks SQL과 Databricks Model Serving을 위한 빠르고, 간단하며, 신뢰할 수 있는 서버리스 컴퓨팅을 즐기고 있습니다. 이제 동일한 기능이 Apache Spark와 Delta Live Tables를 포함한 데이터 인텔리전스 플랫폼의 모든 ETL 워크로드에 사용 가능합니다. 여러분이 코드를 작성하면 데이터브릭스가 빠른 워크로드 시작, 자동 인프라 스케일링, 그리고 Databricks Runtime의 원활한 버전 업그레이드를 제공합니다. 중요한 점은, 서버리스 컴퓨팅을 사용하면 클라우드 제공업체로부터 인스턴스를 획득하고 초기화하는 데 소요된 시간이 아닌, 실제 수행한 작업에 대해서만 요금이 청구된다는 것입니다.
현재 우리��의 서버리스 컴퓨팅 제품은 빠른 시작, 확장성, 그리고 성능에 최적화되어 있습니다. 사용자들은 곧 더 낮은 비용과 같은 다른 목표를 설정할 수 있게 될 것입니다. 현재 우리는 서버리스 컴퓨팅에 대한 소개 프로모션 할인을 제공하고 있으며, 이는 지금부터 2024년 10월 31일까지 이용 가능합니다. 이 프로모션을 통해 워크플로우와 DLT를 위한 서버리스 컴퓨팅에 대해 50% 가격 할인을, 그리고 노트북을 위한 서버리스 컴퓨팅에 대해 30% 가격 할인을 받으실 수 있습니다.
"클러스터 구동은 우리의 중요한 우선순위 작업이며, 서버리스 노트북과 워크플로는 여기에 큰 변화를 가져왔습니다. 노트북용 서버리스 컴퓨팅을 사용하면 클릭 한 번으로 워크플로우에 원활하게 통합되는 서버리스 컴퓨팅을 쉽게 사용할 수 있습니다. 게다가 안전합니다. 오랫동안 기다려온 이 기능은 획기적인 기능입니다. 감사합니다, 데이터브릭스!" - Chiranjeevi Katta, 데이터 엔지니어, Airbus
서버리스 컴퓨팅이 해결하는 과제와 데이터 팀에 제공하는 고유한 이점을 살펴보세요.
컴퓨팅 인프라는 관리하기 복잡하고 비용이 많이 듭니다
Spark 클러스터와 같은 컴퓨팅을 구성하고 관리하는 것은 데이터 엔지니어와 데이터 과학자들에게 오랫동안 어려운 과제였습니다. 컴퓨팅을 구성하고 관리하는 데 소요되는 시간은 비즈니스에 가치를 제공할 수 없는 시간입니다.
올바른 인스턴스 유형과 크기를 선택하는 데는 많은 시간이 소요되며, 주어진 워크로드에 대한 최적의 선택을 결정하기 위한 실험이 필요합니다. 클러스터 정책, 자동 확장 및 Spark 구성을 파악하는 것은 이 작업을 더욱 복잡하게 만들며 전문 지식이 필요합니다. 클러스터를 설정하고 실행한 후에는 새로운 기능을 활용할 수 있도록 성능을 유지 및 조정하고 데이터브릭스 런타임 버전을 업데이트하는 데 시간을 투자해야 합니다.
유휴 시간(워크로드 처리에 사용되지는 않지만 여전히 비용을 지불하고 있는 시간)은 자체 컴퓨팅 인프라 관리로 인해 발생하는 또 다른 비용 손실입니다. 컴퓨팅 초기화 및 확장 중에는 인스턴스를 부팅해야 하고, 데이터브릭스 런타임을 비롯한 소프트웨어를 설치해야 하는 등의 작업이 필요합니다. 이 시간 동안 클라우드 제공업체에 비용을 지불합니다. 둘째, 너무 많은 인스턴스를 사용하거나 메모리, CPU 등이 너무 많은 인스턴스 유형을 사용하여 컴퓨팅을 오버프로비저닝하면 컴퓨팅 자원이 제대로 활용되지 않으면서도 프로비저닝된 모든 컴퓨팅 용량에 대한 비용을 지불하게 됩니다.
수백만 개의 고객 워크로드에서 이러한 비용과 복잡성을 관찰한 결과 서버리스 컴퓨팅으로 혁신을 이루게 되었습니다.
서버리스 컴퓨팅은 빠르고, 간단하며, 신뢰할 수 있습니다
기존 컴퓨팅에서는 복잡한 클라우드 정책(policy)과 역할(role)을 통해 데이터브릭스에게 위임된 권한을 부여하여 워크로드에 필요한 인스턴스의 수명 주기를 관리합니다. 서버리스 컴퓨팅은 데이터브릭스가 사용자를 대신해 방대하고 안전한 컴퓨팅을 관리하므로 이러한 복잡성을 제거합니다. 아무런 설정 없이 바로 데이터브릭스 사용을 시작할 수 있습니다.
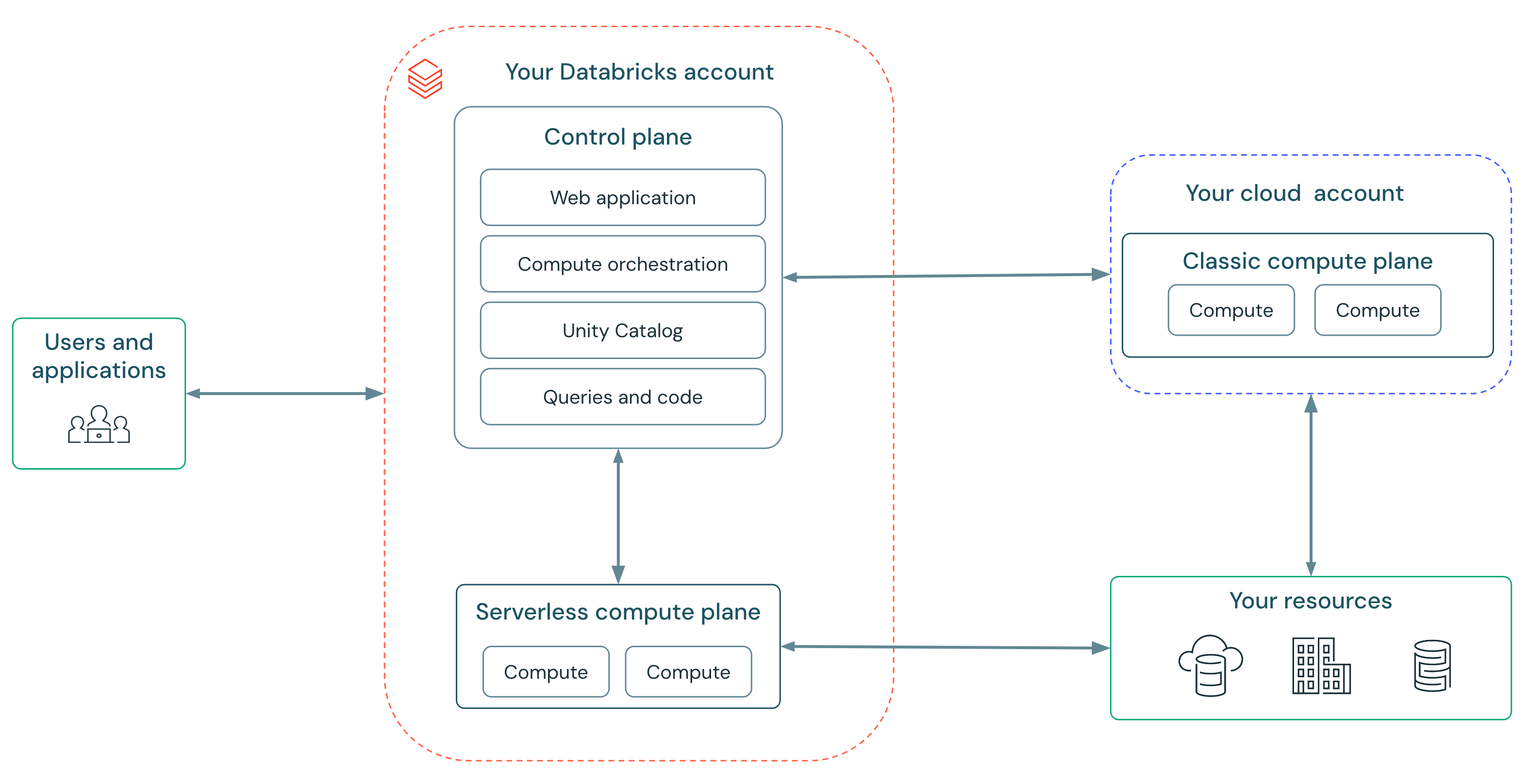
서버리스 컴퓨팅을 통해 빠르고, 간단하며, 신뢰할 수 있는 서비스를 제공할 수 있습니다:
- 빠름: 더 이상 클러스터를 기다릴 필요가 없습니다 — 컴퓨팅은 몇 분이 아닌 몇 초 안에 시작됩니다. Databricks는 "warm pool" 인스턴스를 실행하여 여러분이 준비되었을 때 컴퓨팅이 바로 사용 가능하도록 합니다.
- 간단함: 더 이상 인스턴스 유형, 클러스터 스케일링 매개변수를 선택하거나 Spark 설정을 구성할 필요가 없습니다. 서버리스에는 기존 컴퓨팅의 자동 스케일러보다 더 스마트하고 워크로드 요구에 더 민감하게 반응하는 새로운 자동 스케일러가 포함되어 있습니다. 이는 이제 모든 사용자가 인프라 전문가의 도움 없이 워크로드를 실행할 수 있다는 것을 의미합니다. 데이터브릭스는 워크로드를 자동으로 업데이트하고 안전하게 최신 Spark 버전으로 업그레이드하여 항상 최신 성능과 보안 혜택을 받을 수 있도록 합니다.
- 신뢰성: 데이터브릭스의 서버리스 컴퓨팅은 자동 인스턴스 유형 장애 대응(failover)와 가용 인스턴스 부족을 버퍼링하는 "warm pool" 을 통해 고객을 클라우드 장애로부터 보호합니다.
"워커 유형을 선택할 필요 없이 워크플로우를 개발에서 프로덕션으로 이동하는 것이 매우 쉽습니다. 클러스터 구동 시간의 상당한 개선과 DataOps 구성 및 유지 관리 감소로 생산성과 효율성이 크게 향상됩니다." — Gal Doron, AnyClip 데이터 책임자
서버리스 컴퓨팅은 수행한 작업에 대해서만 요금을 청구합니다
서버리스 컴퓨팅을 위한 탄력적인 과금 모델을 도입하게 되어 매우 기쁩니다. 컴퓨팅이 워크로드에 할당될 때만 요금이 청구되며, 컴퓨팅 인스턴스를 획득하고 설정하는 시간에 대해서는 청구되지 않습니다.
지능형 서버리스 자동 스케일러는 워크스페이스가 항상 적절한 용량을 프로비저닝하도록 보장하여 수요에 대응할 수 있습니다. 예를 들어, 사용자가 노트북에서 명령을 실행할 때 자동으로 대응합니다. 이는 워크스페이스 용량을 단계별로 자동 확장 및 축소하여 필요에 맞춥니다. 리소스를 현명하게 관리하기 위해, 지능형 자동 스케일러가 더 이상 필요하지 않다고 예측하면 몇 분 후에 프로비저닝된 용량을 줄일 것입니다.
"DLT를 위한 서버리스 컴퓨팅은 설정하고 실행하기가 믿을 수 없을 정도로 쉬웠으며, 우리는 이미 구체화된 뷰에서 주요 성능 향상을 보고 있습니다. 과거에는 원시 데이터에서 실버 레이어로 가는 데 약 16분이 걸렸지만, 서버리스로 전환한 후에는 약 7분밖에 걸리지 않습니다. 시간과 비용 절감이 엄청날 것입니다." — Aaron Jespen, Jetlinx IT 운영 이사
서버리스 컴퓨팅은 관리하기 쉽습니다
서버리스 컴퓨팅에는 관리자�가 비용과 예산을 관리할 수 있는 도구가 포함되어 있습니다. 단순함이 예산 초과와 예상치 못한 청구서를 의미해서는 안 되니까요!
서버리스 컴퓨팅의 사용량과 비용에 대한 데이터는 시스템 테이블에서 확인할 수 있습니다. 비용의 개요를 볼 수 있고 특정 워크로드를 자세히 살펴볼 수 있는 미리 만들어진 대시보드를 제공합니다.
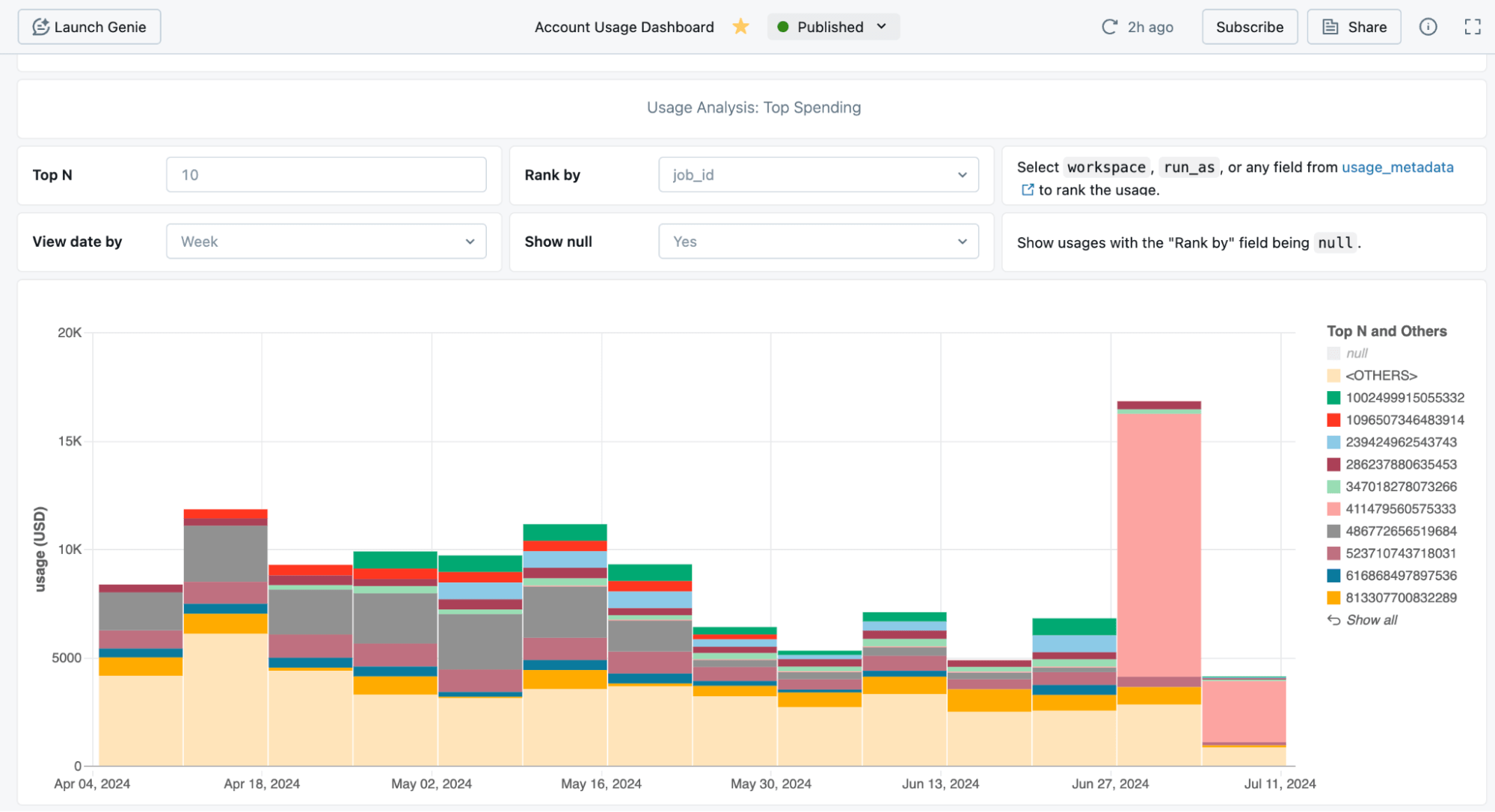
관리자는 예산 알림(프리뷰)을 사용하여 비용을 그룹화하고 알림을 설정할 수 있습니다. 예산 관리를 위한 친숙한 UI가 있습니다.
서버리스 컴퓨팅은 현대적인 Spark 워크로드를 위해 설계되었습니다
내부적으로 서버리스 컴퓨팅은 Lakeguard를 사용하여 샌드박싱 기술로 사용자 코드를 격리합니다. 이는 서버리스 환경에서 절대적으로 필요한 요소입니다. 이런 이유로, 일부 워크로드는 서버리스에서 계속 작동하기 위해 코드 변경이 필요할 수 있습니다. 서버리스 컴퓨팅은 데이터 자산에 대한 안전한 접근을 위해 Unity Catalog를 필요로 하므로, Unity Catalog를 사용하지 않고 데이터에 접근하는 워크로드는 변경이 필요할 수 있습니다.
워크로드가 서버리스 컴퓨팅에 준��비되었는지 테스트하는 가장 간단한 방법은 먼저 DBR 14.3 이상에서 공유 접근 모드(shared access mode)를 사용하여 기존 클러스터에서 실행해 보는 것입니다.
서버리스 컴퓨팅이 사용 준비 완료되었습니다
앞으로 몇 달 동안 서버리스 컴퓨팅을 더욱 개선하기 위해 열심히 노력하고 있습니다:
- GCP 지원: 현재 GCP에서 서버리스 컴퓨팅의 비공개 프리뷰를 시작하고 있습니다. 공개 프리뷰와 GA 발표를 기대해 주세요.
- 사설 네트워킹 및 egress 제어: 사설 네트워크 내의 리소스에 연결하고, 서버리스 컴퓨팅 리소스가 공용 인터넷에서 접근할 수 있는 것을 제어할 수 있습니다.
- 강제 속성 부여: 모든 노트북, 워크플로우 및 DLT 파이프라인에 적절한 태그를 지정하여 특정 비용 센터에 비용을 할당할 수 있습니다(예: 내부 비용 청구용).
- 환경: 관리자는 사설 저장소 접근, 특정 Python 및 라이브러리 버전, 환경 변수 등이 포함된 워크스페이스의 기본 환경을 설정할 수 있게 됩니다.
- 비용 대 성능: 현재 서버리스 컴퓨팅은 빠른 시작, 확장 및 성능에 최적화되어 있습니다. 사용자는 곧 더 낮은 비용과 같은 다른 목표를 설정할 수 있게 될 것입니다.
- Scala 지원: 사용자는 서버리스 컴퓨팅에서 Scala 워크로드를 실�행할 수 있게 될 것입니다. 서버리스가 사용 가능해질 때 원활하게 이동할 준비를 하려면, Scala 워크로드를 공유 접근 모드(Shared Access mode)의 기존 컴퓨팅으로 이동하세요.
오늘부터 서버리스 컴퓨팅을 시작하려면:
- AWS 또는 Azure 계정에서 서버리스 컴퓨팅을 활성화하세요.
- 워크스페이스가 Unity Catalog를 사용할 수 있도록 설정되어 있고 AWS 또는 Azure의 지원되는 지역에 있는지 확인하세요.
- 기존 PySpark 워크로드의 경우, 공유 접근 모드(shared access mode) 및 DBR 14.3+ 와 호환되는지 확인하세요.
- Notebooks, Workflows, Delta Live Tables 에 대한 구체적인 지침을 따르세요.
- Databricks Connect를 사용하여 모든 타사 시스템에서 서버리스 컴퓨팅을 사용하세요. 예를 들어, IDE에서 로컬로 개발할 때나 Python 애플리케이션을 Databricks와 직접 통합할 때 사용할 수 있습니다.
(번역: Youngkyong Ko) Original Post

