데이터브릭스 레이크하우스 모니터링을 통한 품질 예측 보장
작성자: Peter Park
많은 기업에서 미래 동향을 예측하는 데 예측 모델이 핵심적인 역할을 합니다. 그러나 이 모델의 정확도는 입력 데이터의 품질에 크게 의존합니다. 품질이 낮은 데이터는 부정확한 예측을 초래하고, 이는 결국 최적이 아닌 의사결정으로 이어질 수 있습니다. 이런 문제를 해결하기 위해 데이터브릭스 Lakehouse Monitoring이 등장했습니다. 이는 예측 모델에 유입되는 데이터의 품질과 모델 성능을 동시에 모니터링할 수 있는 통합 솔루션을 제공합니다.
예측 모델에서는 모니터링이 특히 중요합니다. 예측은 시계열 데이터를 다루는데, 이 데이터의 시간적 요소와 순차적 특성으로 인해 추가적인 복잡성이 발생합니다. 예를 들어, 시간이 지남에 따라 입력 데이터의 통계적 특성이 변하는 '데이터 드리프트(data drift)' 현상이 일어날 수 있습니다. 이를 신속히 감지하고 대응하지 못하면 예측 정확도가 크게 저하될 수 있습니다.
또한, 예측 모델의 성능은 종종 평균 절대 백분율 오차(MAPE)와 같은 지표로 측정됩니다. 이는 예측값을 실제값과 비교하는 방식인데, 실제값은 예측한 시간이 지난 후에야 얻을 수 있습니다. 이러한 지연된 피드백 루프로 인해, 잠재적 문제를 조기에 식별하기 위해서는 입력 �데이터의 품질과 모델 출력에 대한 선제적 모니터링이 더욱 중요해집니다.
최신 데이터로 통계적 예측 모델을 자주 재훈련하는 것이 일반적이지만, 모니터링은 여전히 가치가 있습니다. 초기에 드리프트를 감지하고 불필요한 계산 비용을 피할 수 있기 때문입니다. PatchTST와 같이 딥러닝을 사용하고 GPU가 필요한 복잡한 모델의 경우, 자원 제약으로 인해 재훈련 빈도가 낮을 수 있어 모니터링이 더욱 중요해집니다.
자동 하이퍼파라미터 튜닝을 사용하면 실행 간 편향(skew)과 일관성 없는 모델 성능이 발생할 수 있습니다. 모니터링을 통해 모델 성능이 저하되었을 때 빠르게 파악하고, 하이퍼파라미터를 수동으로 조정하거나 입력 데이터의 이상을 조사하는 등의 시정 조치를 취할 수 있습니다. 또한 모니터링은 모델 성능과 계산 비용 사이의 적절한 균형을 맞추는 데 도움이 됩니다. 자동 튜닝은 특히 매 재훈련 주기마다 무분별하게 실행될 경우 리소스를 많이 소모할 수 있습니다. 시간에 따른 모델 성능을 모니터링함으로써, 자동 튜닝이 실제로 상당한 개선을 가져오는지 아니면 단순히 불필요한 오버헤드를 추가하는지 판단할 수 있습니다. 이러한 인사이트를 통해 모델 훈련 파이프라인을 최적화할 수 있습니다.
데이터브릭스 Lakehouse Monitoring은 모든 테이블에 걸쳐 데이터의 통계적 특성과 품질을 모니터링하도록 설계되었습니다. 또한 모델 입력과 예측을 포함하는 추론 테이블(inference tables)을 모니터링하여 머신러닝 모델의 성능을 추적하는 특정 기능도 제공합니다. 예측 모델의 경우 다음과 같은 기능을 지원합니다:
- 기준선과 비교하여 시간에 따른 입력 피처(input features)의 데이터 드리프트 모니터링
- 예측 드리프트와 예측 분포 추적
- 실제값이 사용 가능해지면 MAPE, 편향 등의 모델 성능 지표 측정
- 데이터 품질이나 모델 성능이 저하될 경우 알림 설정
데이터브릭스에서 예측 모델 만들기
예측 모델 모니터링 방법을 논의하기 전에, 데이터브릭스 플랫폼에서 이러한 모델을 개발하는 방법에 대해 간략히 살펴보겠습니다. 데이터브릭스는 시계열 예측 모델을 포함한 머신러닝 모델을 대규모로 구축, 훈련, 배포할 수 있는 통합 환경을 제공합니다.
다음은 예측을 생성하는 데 사용할 수 있는 여러 인기 있는 라이브러리와 기술들입니다:
- Prophet: 사용과 튜닝이 쉬운 오픈소스 시계열 예측 라이브러리입니다. 강한 계절성 효과(seasonal effects)가 있는 데이터를 잘 처리하며, 이상치를 부드럽게 처리하여 지저분한 데이터에도 잘 작동합니다. Prophet의 간단하고 직관적인 API는 비전문가도 쉽게 접근할 수 있게 해줍니다. PySpark를 사용하여 클러스터에서 Prophet 모델 훈련을 병렬화하여 각 제품-매장 조합에 대해 수천 개의 모델을 구축할 수 있습니다. (Blog)
- ARIMA/SARIMA: 시계열 예측을 위한 고전적인 통계 방법입니다. ARIMA 모델은 데이터의 자기상관(autocorrelations)을 설명하는 것을 목표로 합니다. SARIMA는 ARIMA를 확장하여 계절성(seasonality)을 모델링합니다. 최근의 벤치마킹 연구에서 SARIMA는 다른 알고리즘에 비해 소매 판매 데이터에서 강력한 성능을 보여주었습니다. (Blog)
Prophet과 ARIMA/SARIMA 같은 인기 있는 라이브러리 외에도, Databricks는 예측을 위한 AutoML을 제공합니다. AutoML은 알고리즘 선택, 하이퍼파라미터 튜닝, 분산 훈련과 같은 작업을 자동으로 처리하여 예측 모델 생성 과정을 단순화합니다. AutoML을 사용하면 다음과 같은 이점이 있습니다:
- 사용자 친화적인 UI를 통해 빠르게 기준 예측 모델과 노트북 생성
- Prophet과 Auto-ARIMA 같은 여러 알고리즘을 내부적으로 활용
- Spark를 사용한 데이터 준비, 모델 훈련 및 튜닝, 분산 계산을 자동으로 처리
AutoML로 만든 모델은 MLflow를 통한 실험 추적과 데이터브릭스 Model Serving을 통한 배포 및 모니터링과 쉽게 통합할 수 있습니다. 생성된 노트북은 커스터마이즈 가능하고 프로덕션 워크플로우에 쉽게 통합할 수 있는 코드를 제공합니다.
모델 개발 워크플로우를 간소화하기 위해 MLflow를 활용할 수 있습니다. MLflow는 머신러닝 수명 주기를 위한 오픈소스 플랫폼으로, Prophet, ARIMA 등의 모델을 기본적으로 지원하여 시계열 실험에 이상적인 실험 추적을 가능하게 합니다. 매개변수, 메트릭, 아티팩트 등을 기록할 수 있습니다. 이는 모델 배포를 단순화하고 재현성을 높이지만, Lakehouse Monitoring을 위해 MLflow 사용이 필수는 아닙니다 - MLflow 없이도 모델을 배포할 수 있으며 Lakehouse Monitoring은 여전히 이를 추적할 수 있습니다.
예측 모델을 훈련한 후에는 사용 사례에 따라 유연하게 추론을 위해 배포할 수 있습니다. 실시간 예측의 경우, 데이터브릭스 Model Serving을 사용하여 몇 줄의 코드만으로 모델을 낮은 지연 시간을 제공하는 REST 엔드포인트에 배포할 수 있습니다. 실시간 추론을 위해 모델이 배포되면 데이터브릭스는 자동으로 입력 특성과 예측을 관리형 Delta 테이블인 추론 로그 테이블(inference log table)에 기록합니다. 이 테이블은 Lakehouse Monitoring을 사용하여 프로덕션 환경에서 모델을 모니터링하는 기반이 됩니다.
하지만 예측 모델은 종종 배치 스코어링 시나리오에서 사용되며, 이 경우 일정에 따라 예측이 생성됩니다(예: 매일 밤 다음 날에 대한 예측 생성). 이런 경우, 별도의 파이프라인을 구축하여 데이터 배치에 대해 모델을 스코어링하고 결과를 Delta 테이블에 기록할 수 있습니다. 데이터브릭스 클러스터에 모델을 직접 로드하고 거기서 데이터 배치를 스코어링하는 것이 더 비용 효율적입니다. 이 방식은 모델을 API 뒤에 배포하고 여러 곳에서 컴퓨팅 리소스에 대한 비용을 지불하는 오버헤드를 피할 수 있습니다. 배치 예측의 로그 테이블도 실시간 추론 테이블과 동일한 방식으로 Lakehouse Monitoring을 사용하여 모니터링할 수 있습니다.
예측 모델에 실시간과 배치 추론이 모두 필요한 경우, 실시간 사용 사례에는 Model Serving을 사용하고 배치 스코어링에는 클러스터에 직접 모델을 로드하는 방식을 고려할 수 있습니다. 이 하이브리드 접근 방식은 필요한 기능을 제공하면서도 비용을 최적화합니다. Lakeview 대시보드를 활용하여 예측 보고서에 대한 ��인터랙티브한 시각화를 구축하고 인사이트를 공유할 수 있습니다. 또한 이메일 구독을 설정하여 일정에 따라 대시보드 스냅샷을 자동으로 전송할 수 있습니다.
어떤 접근 방식을 선택하든, 모델 입력과 출력을 표준화된 Delta 테이블 형식으로 저장함으로써 데이터 드리프트를 모니터링하고, 예측 변화를 추적하며, 시간에 따른 정확도를 측정하는 것이 간단해집니다. 이러한 가시성은 프로덕션 환경에서 신뢰할 수 있는 예측 파이프라인을 유지하는 데 중요합니다.
이제 Databricks에서 시계열 예측 모델을 구축하고 배포하는 방법을 살펴보았으니, Lakehouse Monitoring을 사용하여 이를 모니터링하는 주요 측면을 자세히 살펴보겠습니다.
데이터 드리프트와 모델 성능을 모니터링하기
예측 모델이 프로덕션 환경에서 계속 잘 작동하도록 하려면 입력 데이터와 모델 예측 모두를 잠재적인 문제에 대해 모니터링하는 것이 중요합니다. 데이터브릭스 Lakehouse Monitoring을 사용하면 입력 피처 테이블과 추론 로그 테이블에 대한 모니터를 쉽게 생성할 수 있습니다. Lakehouse Monitoring은 Unity Catalog 위에 구축되어 데이터를 통합적으로 관리하고 모니터링할 수 있게 해주며, 작업 공간에 Unity Catalog가 활성화되어 있어야 합니다.
추론 프로필 모니터 생성하기
예측 모델을 모니터링하려면 모델의 입력 특성, 예측, 그리고 선택적으로 실제 레이블을 포함하는 테이블에 대해 추론 프로필 모니터를 생성해야 합니다. 데이터브릭스 UI 또는 Python API를 사용하여 모니터를 생성할 수 있습니다.
UI에서 추론 테이�블로 이동하여 "품질(Quality)" 탭을 클릭합니다. "시작하기(Get Started)"를 클릭하고 모니터 유형으로 "추론 프로필(Inference Profile)"을 선택합니다. 그런 다음 아래와 같은 주요 매개변수를 구성합니다.
- 문제 유형: 예측 모델의 경우 회귀(regression)를 선택합니다.
- 타임스탬프 열: 각 예측의 타임스탬프를 포함하는 열입니다. 이는 데이터 자체의 타임스탬프가 아닌 추론의 타임스탬프입니다.
- 예측 열: 모델의 예측값을 포함하는 열입니다.
- 레이블 열(선택 사항): 실제 값을 포함하는 열입니다. 실제 값이 도착하면 나중에 채울 수 있습니다.
- 모델 ID 열: 각 예측을 만든 모델 버전을 식별하는 열입니다.
- 세분성(Granularities): 메트릭을 집계할 시간 단위입니다(예: 일별 또는 주별).
선택적으로 다음 사항도 지정할 수 있습니다:
- 데이터 드리프트를 비교할 참조 데이터(예: 훈련 세트)가 포함된 기준 테이블
- 다른 제품 카테고리와 같이 모니터링할 데이터 부분집합을 정의하는 슬라이싱 표현식
- SQL 표현식으로 정의된 사용자 정의 메트릭 계산
- 새로 고침 일정 설정
Python REST API를 사용하여 이와 같은 모니터를 생성하는 코드는 다음과 같습니다:
기준 테이블(baseline table)은 모델의 훈련 데이터와 같은 참조 데이터셋을 포함하는 선택적 테이블로, 프로덕션 데이터와 비교하는 데 사용됩니다. 예측 모델의 경우 자주 재훈련되므로 모델이 빈번히 변경되어 기준 비교가 항상 필요하지는 않습니다. 이전 시간 창과 비교할 수 있으며, 기준 비교가 필요한 경우 하이퍼파라미터 튜닝이나 실제 데이터 업데이트와 같은 큰 변경이 있을 때만 기준을 업데이트하는 것이 좋습니다.
예측 모니터링은 주간이나 월간과 같이 재훈련 주기가 미리 설정된 시나리오에서도 유용합니다. 이러한 경우, 예측 지표가 실제값에서 벗어나거나 실제값이 예측과 맞지 않을 때 예외 기반 예측 관리를 수행할 수 있습니다. 이를 통해 기본 시계열을 재진단(re-diagnose) 해야 하는지(경제계량 모델을 사용할 경우 트렌드, 계절성, 주기성을 개별적으로 식별하는 공식적인 예측 용어로 재훈련을 의미), 또는 개별 편차를 이상치로 분류할 수 있는지 결정할 수 있습니다. 후자의 경우, 재진단하지 않고 해당 편차를 이상치로 표시하고 향후 모델에 캘린더 이벤트나 외생 변수를 추가할 수 있습니다.
Lakehouse Monitoring은 시간에 따른 입력 특성의 통계적 속성을 자동으로 추적하고, 기준이나 이전 시간 창과 비교하여 유의미한 드리프트가 감지되면 알림을 보냅니다. 이를 통해 예측 정확도를 저하시킬 수 있는 데이터 품질 문제를 식별할 수 있습니다. 예를 들어:
- 판매량과 같은 주요 입력 피처의 분포를 모니터링합니다. 갑작스러운 변화가 있다면 예측 정확도를 저하시킬 수 있는 데이터 품질 문제를 나타낼 수 있습니다.
- 누락되거나 이상치인 값의 수를 추적합니다. 최근 기간의 누락 데이터가 증가하면 예측이 왜곡될 수 있습니다.
기본 메트릭 외에도 SQL 표현식을 사용하여 비즈니스 특정 로직이나 복잡한 비교를 캡처하는 사용자 정의 메트릭을 정의할 수 있습니다. 예측과 관련된 몇 가지 예는 다음과 같습니다:
- 계절이나 연도 간 메트릭 비교, 예를 들어 현재 분기와 전년 동기의 평균 판매량 차이를 백분율로 계산
- 예측 대상 항목에 따라 오류에 다른 가중치 부여, 예를 들어 고가 제품의 오류에 더 큰 패널티 부여
- 허용 가능한 오차 범위 내에 있는 예측의 비율 추적
사용자 정의 메트릭은 세 가지 유형이 있습니다:
- 추론 테이블의 열에서 계산된 집계 메트릭
- 다른 집계 메트릭에서 계산된 파생 메트릭
- 시간 창 간 또는 기준과 비교하는 집계 또는 파생 메트릭의 드리프트 메트릭
이러한 사용자 정의 메트릭의 예는 위의 Python API 예제에서 볼 수 있습니다. 특정 예측 사용 사례에 맞는 사용자 정의 메트릭을 통합함으로써 모델 성능과 데이터 품질에 대해 더 깊고 관련성 있는 인사이트를 얻을 수 있습니다.
핵심 아이디어는 모델의 입력 특성, 예측, 실제 레이블을 하나의 추론 로그 테이블로 가져오는 것입니다. 그러면 Lakehouse Monitoring이 시간에 따라 그리고 지정한 차원별로 데이터 드리프트, 예측 드리프트, 성능 메트릭을 자동으로 추적합니다.
예측 모델이 데이터브릭스 외부에서 서빙되는 경우, 요청 로그를 Delta 테이블로 ETL한 다음 모니터링을 적용할 수 있습니다. 이를 통해 외부 모델에 대해서도 모니터링을 중앙 집중화할 수 있습니다.
시계열 또는 추론 프로필 모니터를 처음 만들 때는 모니터 생성 이전 30일 동안의 데이터만 분석한다는 점에 유의해야 합니다. 이러한 제한으로 인해 첫 번째 분석 창이 부분적일 수 있습니다. 예를 들어, 30일 제한이 주나 월 중간에 걸치면 전�체 주나 월이 포함되지 않을 수 있습니다.
이 30일 룩백(lookback) 제한은 모니터가 생성될 때 초기 창에만 영향을 미칩니다. 그 이후에는 추론 테이블로 유입되는 모든 새로운 데이터가 지정된 세분성에 따라 완전히 처리됩니다.
모니터를 새로 고침하여 메트릭 업데이트하기
예측 모델에 대한 추론 프로필 모니터를 생성한 후에는 최신 데이터로 메트릭을 업데이트하기 위해 주기적으로 새로 고침해야 합니다. 모니터를 새로 고침하면 추론 로그 테이블의 현재 내용을 기반으로 프로필 및 드리프트 메트릭 테이블을 재계산합니다. 다음과 같은 경우에 모니터를 새로 고침해야 합니다:
- 모델에서 새로운 예측이 기록될 때
- 이전 예측에 대한 실제 값이 추가될 때
- 새로운 특성 열 추가와 같이 추론 테이블 스키마가 변경될 때
- 추가 사용자 정의 메트릭 추가와 같이 모니터 설정을 수정할 때
모니터를 새로 고침하는 방법에는 일정에 따른 방법과 수동 방법 두 가지가 있습니다.
새로 고침 일정을 설정하려면 UI를 사용하여 모니터를 생성할 때 일정 매개변수를 지정하거나 Python API를 사용하면 됩니다:
CronSchedule을 사용하면 일별, 시간별 등과 같이 새로 고침 빈도를 정의하는 cron 표현식을 제공할 수 있습니다. skip_builtin_dashboard를 True로 설정하면 모니터에 대한 새 대시보드 생성을 건너뛰게 됩니다. 이는 이미 대시보드를 구축했거나 유지하고 싶은 사용자 정의 차트가 대시보드에 있어 새로운 것이 필요 없을 때 특히 유용합니다.
다른 방법으로, UI나 Python API를 사용하여 수�동으로 모니터를 새로 고칠 수 있습니다. Databricks UI에서는 추론 테이블의 "Quality" 탭으로 이동하여 모니터를 선택하고 "Refresh metrics"를 클릭하면 됩니다.
Python API를 사용하면 모니터를 새로 고침하는 파이프라인을 만들어 모델 재훈련 후와 같이 액션 기반으로 실행할 수 있습니다. 노트북에서 모니터를 새로 고침하려면 run_refresh 함수를 사용하세요:
이는 모니터 메트릭 테이블을 업데이트하기 위해 서버리스 작업을 제출합니다. 새로 고침이 백그라운드에서 실행되는 동안 노트북을 계속 사용할 수 있습니다.
새로 고침이 완료되면 SQL을 사용하여 업데이트된 프로필 및 드리프트 메트릭 테이블을 조회할 수 있습니다. 그러나 생성된 대시보드는 별도로 업데이트된다는 점에 유의하세요. DBSQL 대시보드 자체에서 "Refresh" 버튼을 클릭하여 이를 수행할 수 있습니다. 마찬가지로, 대시보드에서 새로 고침을 클릭해도 모니터 계산이 트리거되지 않습니다. 대신, 대시보드가 시각화를 생성하는 데 사용하는 메트릭 테이블에 대한 쿼리를 실행합니다. 대시보드에 나타나는 시각화를 만드는 데 사용되는 테이블의 데이터를 업데이트하려면 모니터를 새로 고친 다음 대시보드를 새로 고쳐야 합니다.
Output 모니터링 출력 이해하기
예측 모델에 대한 추론 프로필 모니터를 만들면 Lakehouse Monitoring은 데이터 드리프트, 모델 성능, 파이프라인의 전반적인 상태를 추적하는 데 도움이 되는 여러 주요 자산을 생성합니다.
프로필 및 드리프트 메트릭 테이블
Lakehouse Monitoring은 두 가지 주요 메트릭 테이블을 생성합니다:
- 프로필 메트릭 테이블: 각 특성 열과 예측에 대한 요약 통계를 포함하며, 시간 창과 슬라이스별로 그룹화됩니다. 예측 모델의 경우 다음과 같은 메트릭이 포함됩니다:
- 숫자형 열에 대한 개수, 평균, 표준편차, 최소값, 최대값
- 범주형 열에 대한 개수, 널 값 수, 고유 값 수
- 예측 열에 대한 개수, 평균, 표준편차, 최소값, 최대값
- 드리프트 메트릭 테이블: 기준선과 비교하여 시간에 따른 데이터 및 예측 분포의 변화를 추적합니다. 예측에 대한 주요 드리프트 메트릭은 다음과 같습니다:
- 숫자형 열에 대한 Wasserstein distance : 분포 형태의 차이를 측정하며, 예측 열에 대해서는 예측 분포의 변화를 감지합니다.
- 범주형 열에 대한 Jensen-Shannon divergence: 확률 분포 간의 차이를 수치화합니다.
이러한 테이블을 SQL을 사용하여 직접 조회하여 다음과 같은 특정 질문을 조사할 수 있습니다:
- 평균 예측은 얼마이며 주간 변화는 어떠한가?
- 제품 카테고리 간 모델 정확도에 차이가 있는가?
- 어제 주요 입력 특성에서 누락된 값의 수가 훈련 데이터와 비교하여 어떠한가?
이렇게 함으로써 예측 모델의 성능과 데이터 품질에 대한 상세한 인사이트를 얻을 수 있습니다.
모델 성능 대시보드
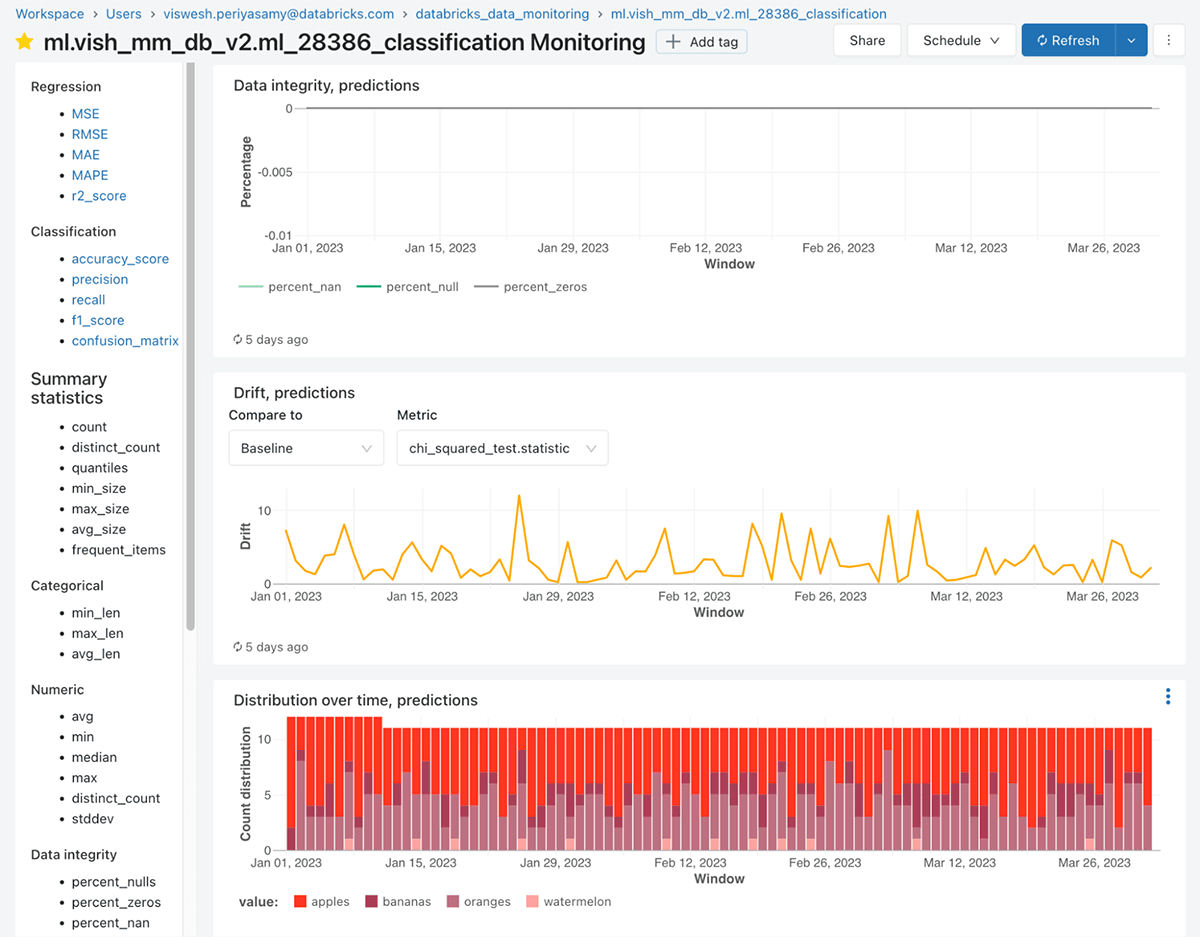
프로필 및 드리프트 메트릭 테이블 외에도 Lakehouse Monitoring은 시간에 따른 예측 모델의 성능을 시각화하는 인터랙티브 대시보드를 자동으로 생성합니다. 이 대시보드는 다음과 같은 주요 구성 요소를 포함합니다:
- 모델 성능 패널: 예측 모델의 주요 정확도 메트릭(예: MAPE, RMSE, bias 등)을 표시합니다. 이러한 메트릭은 예측값을 실제값과 비교하여 계산되며, 실제값은 지연되어 제공될 수 있습니다(예: 일일 예측에 대한 일일 실제값). 이 패널은 시간에 따른 메트릭과 제품 카테고리나 지역과 같은 중요한 슬라이스별 메트릭을 보여줍니다.
- 드리프트 메트릭 패널: 선택된 특성과 예측 열에 대한 시간에 따른 드리프트 메트릭을 시각화합니다.
- 데이터 품질 패널: 숫자형 특성과 범주형 특성 모두에 대해 시간에 따른 누락값 비율, NaN 비율, 개수, 평균, 최소값, 최대값과 같은 다양한 통계, 그리고 기타 데이터 이상을 보여줍니다. 이를 통해 예측 정확도를 저하시킬 수 있는 데이터 품질 문제를 빠르게 발견할 수 있습니다.
이 대시보드는 높은 상호작용성을 제공하여 시간 범위로 필터링하고, 특정 특성과 슬라이스를 선택하며, 개별 메트릭을 자세히 살펴볼 수 있습니다. 대시보드는 생성 후 조직에서 일반적으로 보는 뷰나 차트를 포함하도록 사용자 정의되는 경우가 많습니다. 대시보드에 사용되는 쿼리는 사용자 정의하고 저장할 수 있으며, "view query"를 클릭한 다음 "create alert"를 클릭하여 어떤 뷰에서든 알림을 추가할 수 있습니다. 현재로서는 대시보드에 대한 사용자 정의 템플릿은 지원되지 않습니다.
이 대시보드는 데이터 과학자가 모델 성능을 디버깅하고 비즈니스 이해관계자가 예측에 대한 신뢰를 유지하는 데 모두 유용한 도구입니다.
정확도 모니터링을 위해 실제 데이터 활용하기
MAPE와 같은 모델 성능 지표를 계산하려면 모니터링 시스템이 각 예측에 대한 실제 값에 접근할 수 있어야 합니다. 하지만 예측의 경우, 실제 값은 예측이 이루어진 후 일정 시간이 지나야 확인할 수 있는 경우가 많습니다.
한 가지 전략은 실제 값이 확인되면 이를 추론 로그 테이블에 추가하는 별도의 파이프라인을 설정한 다음, 모니터를 새로고침하여 지표를 업데이트하는 것입니다. 예를 들어, 일일 예측을 생성한다면 매일 밤 전날의 예측에 대한 실제 값을 추가하는 작업을 실행할 수 있습니다.
실제 값을 캡처하고 모니터를 정기적으로 새로고침함으로써 시간에 따른 예측 정확도를 추적하고 성능 저하를 조기에 식별할 수 있습니다. 이는 예측 파이프라인에 대한 신뢰를 유지하고 정보에 기반한 비즈니스 결정을 내리는 데 중요합니다.
더불어, 실제 값과 예측을 별도로 모니터링하면 강력한 예외 관리 기능을 사용할 수 있습니다. 예외 관리는 수요 계획에서 인기 있는 기법으로, 예상 결과에서 크게 벗어난 경우를 사전에 식별하고 해결합니다. 예측 정확도나 편향 같은 지표에 대한 경고를 설정하면 모델의 성능이 저하됐을 때 빠르게 파악하고 모델 매개변수 조정이나 입력 데이터 이상 조사 등의 시정 조치를 취할 수 있습니다.
Lakehouse Monitoring은 주요 지표를 자동으로 �추적하고 맞춤형 경고를 제공하여 예외 관리를 간소화합니다. 계획 담당자는 방대한 데이터를 분석하는 대신 가장 영향력 있는 예외에 집중할 수 있습니다. 이러한 타겟팅된 접근 방식은 효율성을 높이고 최소한의 수동 개입으로 높은 예측 품질을 유지하는 데 도움이 됩니다.
요약하자면, Lakehouse Monitoring은 프로덕션 환경에서 예측 모델을 모니터링하기 위한 종합적인 도구 세트를 제공합니다. 생성된 지표 테이블과 대시보드를 활용하면 데이터 품질 문제를 사전에 감지하고, 모델 성능을 추적하며, 드리프트를 진단하고, 비즈니스에 영향을 미치기 전에 예외를 관리할 수 있습니다. 제품, 지역, 시간과 같은 차원에 걸쳐 지표를 다각도로 분석할 수 있어 문제의 근본 원인을 신속하게 파악하고 예측의 건전성과 정확성을 유지하기 위한 타겟팅된 조치를 취할 수 있습니다.
모델 메트릭에 대한 Alert 설정하기
예측 모델에 대한 추론 프로파일 모니터를 설정하면, 주요 지표에 대한 알림을 정의하여 비즈니스 결정에 영향을 미치기 전에 문제를 사전에 식별할 수 있습니다. 데이터브릭스 Lakehouse Monitoring은 Databricks SQL과 통합되어 생성된 프로파일 및 드리프트 메트릭 테이블을 기반으로 알림을 만들 수 있습니다.
예측 모델에 대해 알림을 설정하고 싶은 일반적인 시나리오는 다음과 같습니다:
- 7일 이동 평균 예측 오차(MAPE)가 10%를 초과할 경우 알림. 이는 모델의 정확도가 떨어져 재학습이 필요할 수 있음을 나타낼 수 있습니다.
- 주요 입력 특성의 결측값 수가 학습 데이터에 비해 크게 증가한 경우 알림. 결측 데이터는 예측을 왜곡할 수 있습니다.
- 특성의 분포가 기준선 대비 임계값을 초과하여 변동된 경우 알림. 이는 데이터 품질 문제나 새로운 데이터 패턴에 맞춰 모델 업데이트가 필요함을 의미할 수 있습니다.
- 지난 24시간 동안 새로운 예측이 기록되지 않은 경우 알림. 이는 추론 파이프라인에 문제가 생겼음을 의미할 수 있습니다.
- 모델 편향(평균 오차)이 지속적으로 양수 또는 음수인 경우 알림. 이는 모델이 체계적으로 과대 또는 과소 예측하고 있음을 나타낼 수 있습니다.
대시보드 뷰를 구축하기 위한 내장 쿼리가 이미 생성되어 있습니다. 알림을 생성하려면 프로파일 또는 드리프트 지표 테이블에서 모니터링하려는 지표를 계산하는 SQL 쿼리로 이동하세요. 그런 다음 Databricks SQL 쿼리 편집기에서 "알림 생성(Create Alert)"을 클릭하고 MAPE가 0.1을 초과할 때 트리거되는 것과 같은 알림 조건을 구성하세요. 알림이 시간별 또는 일별과 같은 일정에 따라 실행되도록 설정하고 이메일, Slack, PagerDuty 등을 통해 알림을 받을 방법을 지정할 수 있습니다.
기본 지표에 대한 알림 외에도 특정 사용 사례에 맞는 맞춤형 지표를 계산하기 위해 사용자 정의 SQL 쿼리를 작성할 수 있습니다. 예를 들어, 고가 제품의 MAPE에 저가 제품과 다른 임계값을 적용하고 이를 초과할 경우 알림을 받고 싶다면, 프로파일 지표를 제품 테이블과 조인하여 MAPE 계산을 세분화할 수 있습니다.
핵심은 모든 특성 및 예측 데이터가 지표 테이블에서 사용 가능하므로 비즈니스에 의미 있는 사용자 정의 지표를 정의하기 위해 SQL을 유연하게 작성할 수 있다는 것입니다. 그런 다음 동일한 프로세스를 사용하여 이러한 사용자 정의 지표에 대한 알림을 생성할 수 있습니다.
예측 모델 지표에 대한 대상 지정 알림을 설정함으로써 수동 모니터링 없이도 모델의 성능을 지속적으로 파악할 수 있습니다. 알림을 통해 이상 징후에 신속하게 대응하고 모델 예측에 대한 신뢰를 유지할 수 있습니다. Lakehouse Monitoring이 제공하는 다차원 분석과 결합하면 문제를 효율적으로 진단하고 해결하여 예측 품질을 높게 유지할 수 있습니다.
Lakehouse Monitoring 비용을 모니터링하기
예측 모델에만 국한된 것은 아니지만, Lakehouse Monitoring 자체의 사용량과 비용을 추적하는 방법을 이해하는 것이 중요합니다. Lakehouse Monitoring을 사용할 계획이라면 관련 비용을 이해하여 적절히 예산을 책정할 수 있어야 합니다. Lakehouse Monitoring 작업은 서버리스 컴퓨팅 인프라에서 실행되므로 직접 클러스터를 관리할 필요가 없습니다. Lakehouse Monitoring 비용을 추정하려면 다음 단계를 따르세요:
- 생성할 모니터의 수와 빈도를 결정합니다. 각 모니터는 지표를 갱신하기 위해 일정에 따라 실행됩니다.
- 모니터에 대한 데이터 양과 SQL 표현식의 복잡성을 추정합니다. 데이터 크기가 크고 쿼리가 복잡할수록 더 많은 DBU를 소비합니다.
- Databricks 티어와 클라우드 제공업체에 따른 서버리스 워크로드의 DBU 요금을 확인합니다.
- 추정 DBU에 해당 요금을 곱하여 예상 Lakehouse Monitoring 비용을 계산합니다.
실제 비용은 특정 모니터 정의와 데이터에 따라 다르며, 시간이 지남에 따라 변동될 수 있습니다. 데이터브릭스는 Lakehouse Monitoring 비용을 모니터링할 수 있는 두 가지 방법을 제공합니다: SQL 쿼리 사용 또는 청구 포털 사용. 자세한 정보는 Lakehouse ��비용 문서를 참조하세요.
데이터브릭스 Lakehouse Monitoring으로 예측 모델 모니터링을 시작할 준비가 되셨나요? 무료 체험(Free trial)에 가입하여 시작해 보세요. 이미 데이터브릭스 고객이신가요? 문서를 확인하여 오늘 바로 첫 번째 추론 프로파일 모니터를 설정해 보세요.
(번역: Youngkyong Ko) Original Post
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.