
Data + AI 전략
데이터와 AI 활용을 조직 전반으로 확대하려는 조직들
모든 기업이 GenAI 이니셔티브의 혁신적 효과를 활용하고 싶어합니다. 그리고 모든 직원이 데이터 인텔리전스의 강력한 기능을 활용하기를 바랍니다. 하지만 정보가 사일로에 갇혀 있고 데이터 관리가 여러 도구에 분산되어 있어 이러한 프로젝트를 진전시키는 데 어려움을 겪고 있는 팀이 많습니다.
현대의 비즈니스 리더들은 다음과 같은 시급한 질문에 대한 답을 찾아야 합니다. "GenAI 경험을 제공하는 가장 빠르고 효과적인 방법은 무엇일까요?"
Data + AI 현황 보고서에서는 조직이 데이터 및 AI 이니셔티브의 우선순위를 어떻게 정하고 있는지에 대한 스냅샷을 제공합니다. Databricks는 포춘 500대 기업 중 300개 이상을 포함한 1만 개 고객사가 사용하는 Databricks Data Intelligence Platform의 익명화된 사용 데이터를 분석해, 기업들이 비즈니스 전반에 생성형 AI(GenAI)를 빠르게 도입하려는 흐름과 이를 뒷받침하는 도구에 대한 독보적인 인사이트를 제공할 수 있게 되었습니다.
가장 혁신적인 기업들이 머신 러닝을 성공적으로 활용하고, GenAI를 채택하여 진화하는 거버넌스 요구 사항에 대응하는 방법을 알아��보세요. 그리고 진화하는 엔터프라이즈 AI 시대에 적합한 데이터 전략을 개발하는 방법을 알아보세요.
확인된 사실을 요약하면 다음과 같습니다.
프로덕션에 AI 활용
11배 더 많은 AI 모델을 프로덕션에 활용
수년 동안 많은 기업들이 AI의 핵심 구성 요소인 머신 러닝(ML)을 실험해 왔습니다. 이 기업들은 통제된 ML 실험을 실제 애플리케이션의 프로덕션으로 전환하는 과정에서 데이터 사일로, 복잡한 배포 워크플로, 거버넌스 등의 문제에 직면했습니다. 그런데 현재 성공률이 증가하고 있다는 증거가 발견되고 있습니다. 모든 조직 전반에서 작년에 비해 올해 1,018% 더 많은 모델이 프로덕션용으로 등록되었습니다. 실제로 이번 조사에서 처음으로 모델 등록의 증가율이 진행 중인 실험의 증가율을 앞질렀습니다(로깅된 실험도 여전히 134% 증가함).
그러나 산업마다 ML에 대한 요구 사항과 목표가 다릅니다. 이에 이러한 트렌드를 더 잘 이해하기 위해 6개의 주요 산업을 분석하여 실험 중인 모델과 등록된 모델의 비율을 살펴봤습니다. 연구 결과, 가장 효율적이었던 3개 산업에서 모델의 25%를 프로덕션에 활용한 것으로 나타났습니다.
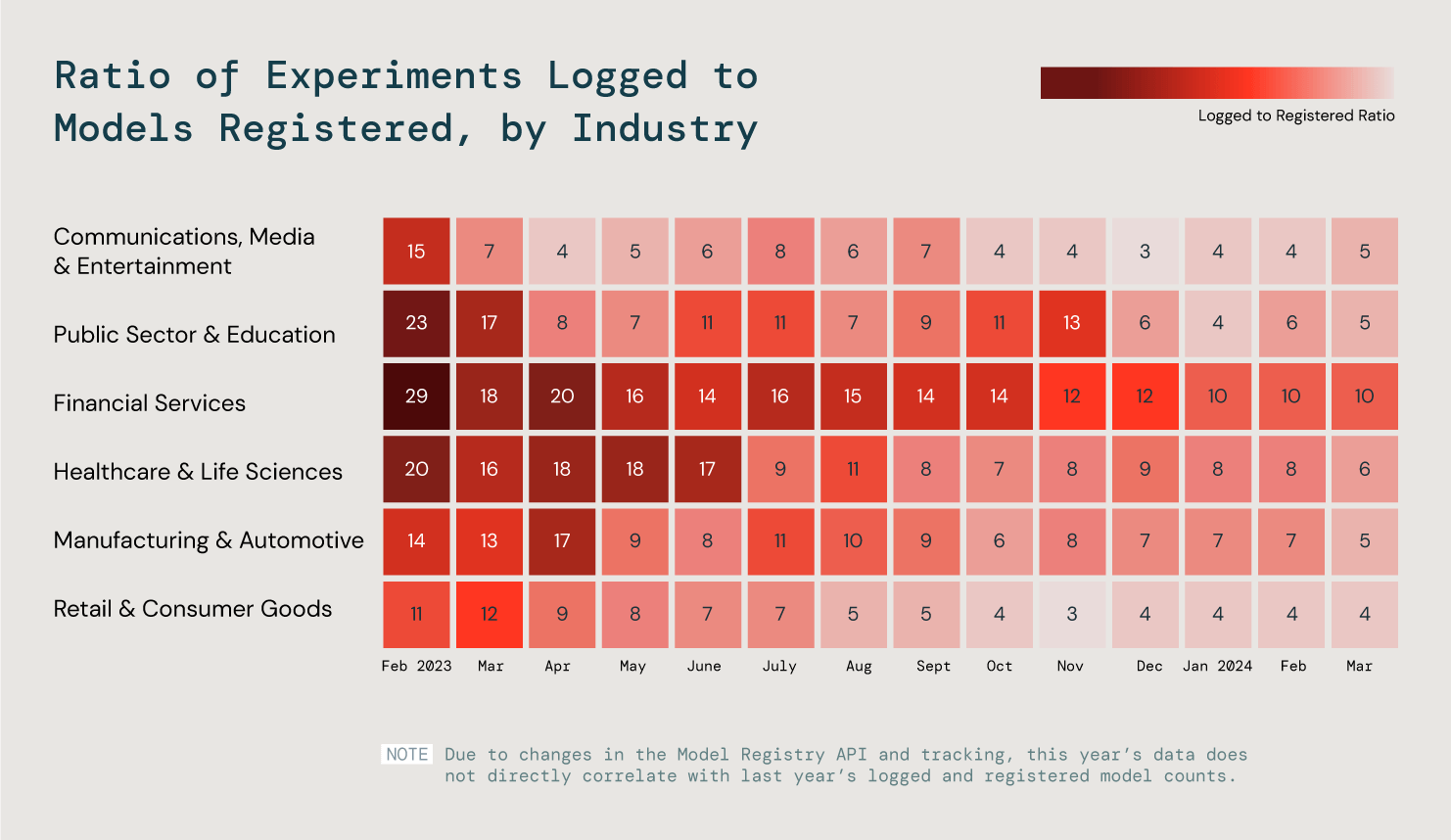
모든 고객사 전반에 걸쳐 실험 중인 모델과 등록된 모델의 비율을 분석하여 ML 프로덕션 진행 상황을 평가했습니다.
프로덕션 단계에서는 내부 팀을 위한 제품이든, 고객을 위한 제품이든 AI의 진정한 가치가 실현됩니다. ML의 성공 사례가 늘어남에 따라 프로덕션 품질의 GenAI 애플리케이션을 더욱 성공적으로 구축할 수 있는 길이 열릴 것으로 예상됩니다.
LLM 맞춤 구성
벡터 데이터베이스 사용량 377% 증가
GenAI 여정의 성숙도가 높아짐에 따라 자체 비공개 데이터를 사용하는 기존 LLM을 특정 요구 사항에 맞게 조정하고자 하는 기업들이 점점 더 많아지고 있습니다.
검색 증강 생성(RAG)은 기업이 오픈 소스 및 폐쇄형 LLM에서 더 나은 성능을 얻을 수 있게 해주는 중요한 메커니즘입니다. RAG를 사용하면 벡터 데이터베이스를 사용해 비공개 데이터로 기본 모델을 학습시켜 기업의 고유한 운영과 관련성이 매우 높은 보다 정확한 결과물을 생성할 수 있습니다.
그리고 기업들은 이러한 맞춤 구성을 적극적으로 추진하고 있습니다. 지난 해 벡터 데이터베이스의 사용량은 377% 증가했습니다.
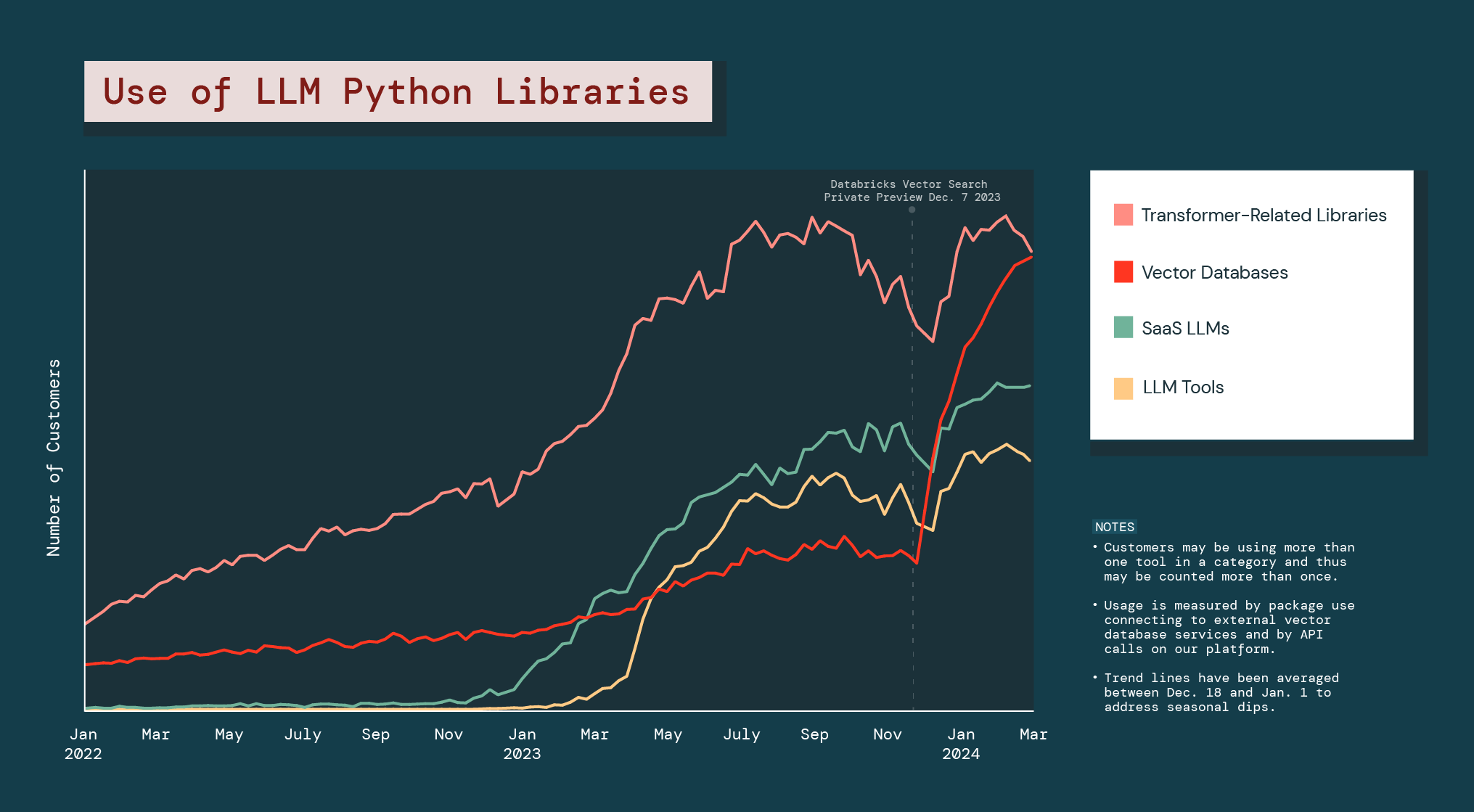
Databricks Vector Search의 공개 미리 보기 출시 이후 전체 벡터 데이터베이스 카테고리는 186% 성장했는데, 이는 다른 어떤 LLM Python 라이브러리보다 훨씬 높은 수치입니다.
벡터 데이터베이스의 폭발적인 증가는 기업들이 문제를 해결하거나 비즈니스에 특화된 기회를 창출할 수 있는 GenAI 대안을 모색하고 있음을 나타냅니다. 그리고 이는 기업이 운영 전반에 걸쳐 다양한 유형의 GenAI 모델을 조합하여 사용하게 될 가능성이 높다는 것을 시사합니다.
오픈 소스 LLM
소형 모델을 선호하는 기업들
오픈 소스 LLM의 가장 큰 장점 중 하나는 특히 기업 환경에서 특정 사용 사례에 맞게 맞춤 구성할 수 있다는 점입니다. 실제로 고객들은 여러 모델과 모델 제품군을 사용해 봅니다. 이에 가장 큰 두 가지 오픈 소스 모델인 Meta Llama와 Mistral의 사용 현황을 분석했습니다.
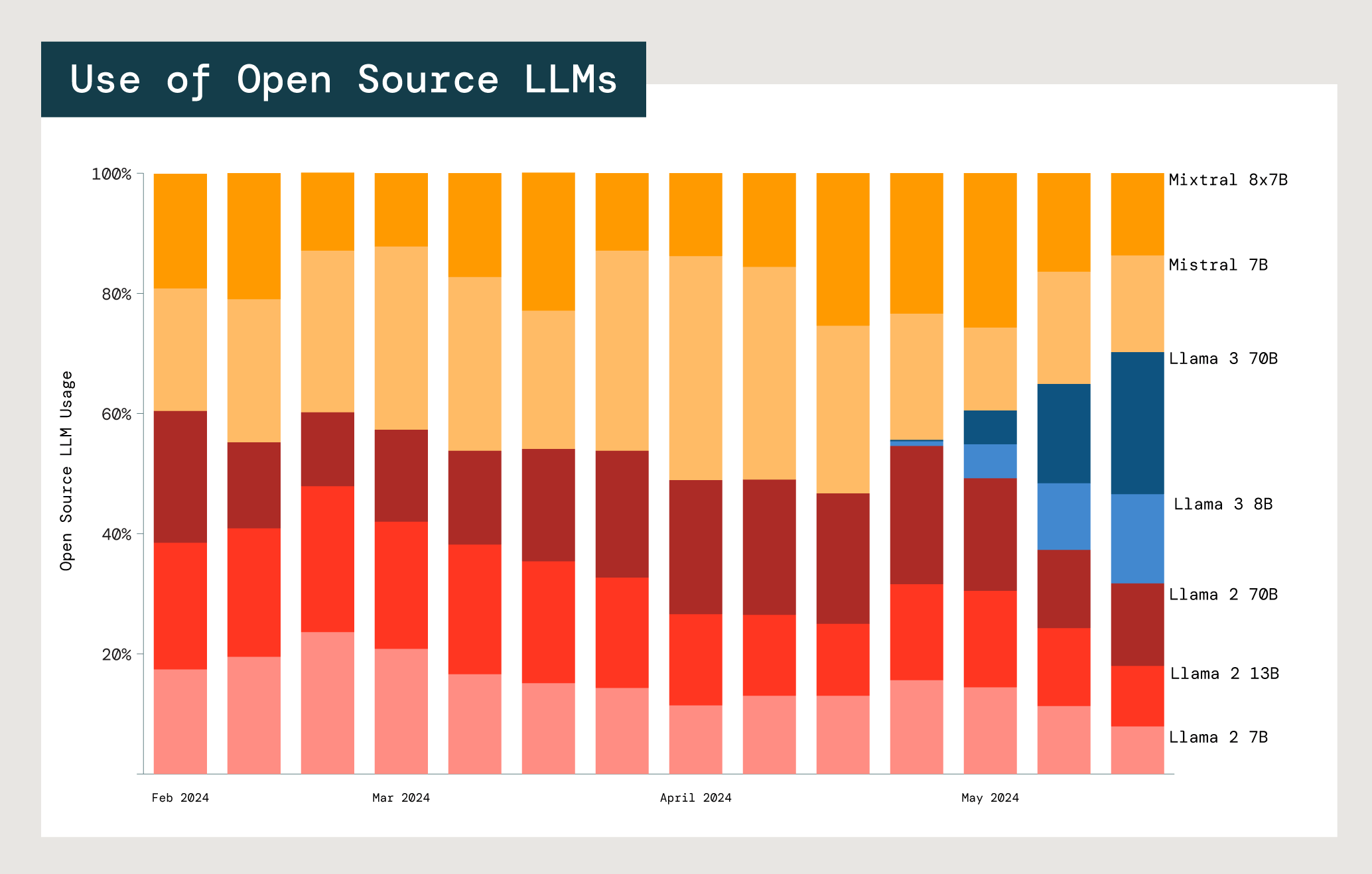
Databricks 파운데이션 모델 API에 Mistral 및 Meta Llama 오픈 소스 모델 도입
각 모델마다 비용, 레이턴시, 성능 측면의 장단점이 있습니다. 가장 작은 두 Meta Llama 2 모델(70억 및 130억 매개변수)의 사용량이 가장 큰 Meta Llama 2 모델의 700억 매개변수 사용량보다 훨씬 높습니다. Llama 및 Mistral의 전체 사용자 중 77%가 130억 이하의 매개변수 모델을 선택한 것으로 나타났습니다. 이는 기업들이 특정 사용 사례에 적합한 모델을 선택할 때 모델 크기에 따른 비용과 이점을 비교 검토하고 있음을 시사합니다.
