Apache Kylin(온라인 분석 처리 엔진)
Apache Kylin이란 무엇입니까?
Apache Kylin은 인터랙티브 분석 빅 데이터에 적합한 분산형 오픈 소스 온라인 분석 처리(Online Analytics Processing, OLAP) 엔진입니다. Apache Kylin은 하둡/Spark에서 SQL 인터페이스와 다차원 분석(OLAP)을 제공하기 위해 고안되었습니다. 또한 ODBC 드라이버, JDBC 드라이버 및 REST API를 사용해 BI 툴과 손쉽게 통합할 수도 있습니다. 이 엔진은 2014년에 eBay에서 만들어 단 1년만인 2015년에 Apache Software Foundation에서 Top Level Project로 인정받았으며 2015년과 2016년 연속으로 최우수 오픈 소스 빅데이터 툴 상을 받기도 했습니다. 지금은 전 세계 수천 곳의 기업에서 빅데이터용 중요 분석 애플리케이션으로 쓰이고 있습니다. 여타 OLAP 엔진은 데이터 볼륨 때문에 고전하지만, Kyliln은 밀리초 단위로 쿼리 응답을 지원합니다. Kylin은 페타바이트급으로 확장되는 Dataset를 상대로 1초 미만의 쿼리 레이턴시를 제공합니다. 다양한 차원 조합을 사전 연산하여 엄청난 속도를 달성하며, Hive 쿼리를 통해 집계 데이터를 측정하고 그 결과로 HBase를 채웁니다.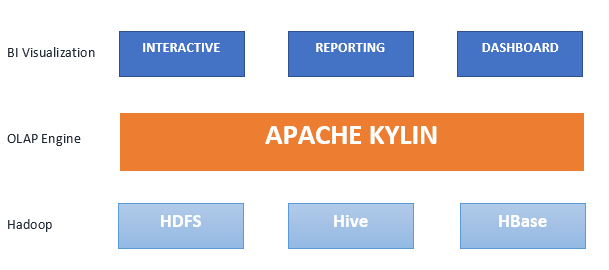
Apache Kylin의 작동 원리는 무엇입니까?
Kylin 쿼리 엔진은 Kylin의 사용자 친화적 UI를 사용해 API나 JDBC를 통해 액세스하면 됩니다. 이는 Apache Calcite 쿼리 프로세서나 HBase 기능을 활용하여 초고속 검색을 수행합니다. Kylin은 하둡 에코시스템에 의존합니다.
- Hive – 큐브 작성 중에 소스 입력, 별모양 스키마를 미리 조인(pre-join)
- MapReduce – 큐브 작성 중에 메트릭 집계
- HDFS – 큐브 작성 중에 중간 파일 보관
- HBase – 데이터 큐브 보관 및 쿼리
- Calcite – SQL 파싱, 코드 생성, 최적화 Apache Kylin이 귀사에 어떤 면에서 도움이 됩니까?
- 매우 빠른 대규모 OLAP 엔진 - Kylin은 100억 건 이상의 데이터를 처리할 때 하둡(Hadoop) 상에서의 쿼리 지연 시간을 몇 초로 줄이도록 설계되었습니다.
- ANSI SQL Interface on Hadoop - Kylin은 ANSI SQL on Hadoop을 제공하며 대부분의 ANSI SQL 쿼리 함수를 지원하며, 프로그래밍이 필요 없으므로 애널리스트도 엔지니어도 손쉽게 사용 가능합니다.
- BI 툴과 원활한 통합 - 현재 Kylin은 Tableau, JDBC/ODBC/Rest API와 같은 BI 툴과의 통합 기능을 제공합니다.
- 인터랙티브 쿼리 기능 - Kylin을 통해 하둡 데이터를 1초 미만의 레이턴시��로 조회합니다.
- 수십억 개 행을 처리하는 MOLAP 큐브 쿼리 - 데이터 모델을 정의한 다음 Kylin에서 미리 구축할 수 있으며, 원시 데이터 레코드가 100억 개가 넘는 대용량 데이터에 대해서도 Kylin에서 데이터 모델을 정의하고 미리 구축할 수 있습니다.
오픈 소스 ODBC 드라이버 - Kylin의 ODBC 드라이버는 처음부터 자체 구축한 것이며 Tableau와 함께 쓰기 매우 좋습니다.