Spark 애플리케이션
Spark 애플리케이션은 driver 프로세스 하나와 일련의 executor 프로세스로 구성됩니다. driver 프로세스는 main() 함수를 실행하고 클러스터 내 노드에 위치하며 세 가지 작업을 담당합니다. 첫째, Spark 애플리케이션 관련 정보를 유지하는 것, 둘째, 사용자의 프로그램이나 입력에 대응하는 것, 셋째는 executor 작업을 분석, 배포, 예약하는 것입니다. driver 프로세스는 매우 핵심적인 역할을 합니다. 이것이 Spark 애플리케이션의 심장과 같으며, 애플리케이션 수명 내내 각종 주요 정보를 모두 유지합니다. executors는 driver가 할당한 작업을 실제로 실행하는 역할을 담당합니다. 이는 다시 말해 각각의 executor마다 맡은 일은 두 개씩이 다라는 뜻입니다. driver가 할당한 코드를 실행하면, 해당 executor에서 연산 상태를 도로 driver 노드에 보고합니다.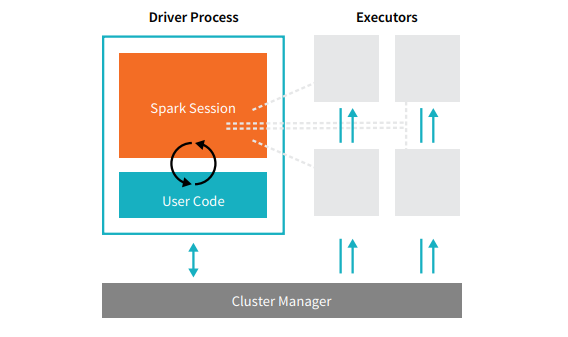 실물 시스템을 제어하고 Spark 애플리��케이션에 리소스를 할당하는 작업은 클러스터 관리자가 맡습니다. 이 경우 다음과 같은 여러 코어 클러스터 관리자 중 하나로, Spark의 독립 실행형 클러스터 관리자, YARN 또는 Mesos 등이 이에 해당합니다. 이것은 다시 말해 한 클러스터에서 동시에 여러 개의 Spark 애플리케이션을 실행할 수 있다는 뜻입니다. 클러스터 관리자에 관해서는 이 책 제4부: 프로덕션 애플리케이션에서 좀 더 자세히 다뤄보겠습니다. 앞서 본 그림에서 왼쪽에 있는 것이 driver이고 오른쪽이 네 개의 executor입니다. 이 다이어그램에서는 클러스터 노드라는 개념을 없앴습니다. 사용자가 구성을 통해 노드마다 몇 개의 executor를 포함할지 지정할 수 있습니다. [glossary-cta]
실물 시스템을 제어하고 Spark 애플리��케이션에 리소스를 할당하는 작업은 클러스터 관리자가 맡습니다. 이 경우 다음과 같은 여러 코어 클러스터 관리자 중 하나로, Spark의 독립 실행형 클러스터 관리자, YARN 또는 Mesos 등이 이에 해당합니다. 이것은 다시 말해 한 클러스터에서 동시에 여러 개의 Spark 애플리케이션을 실행할 수 있다는 뜻입니다. 클러스터 관리자에 관해서는 이 책 제4부: 프로덕션 애플리케이션에서 좀 더 자세히 다뤄보겠습니다. 앞서 본 그림에서 왼쪽에 있는 것이 driver이고 오른쪽이 네 개의 executor입니다. 이 다이어그램에서는 클러스터 노드라는 개념을 없앴습니다. 사용자가 구성을 통해 노드마다 몇 개의 executor를 포함할지 지정할 수 있습니다. [glossary-cta]