Azure의 데이터 레이크
레이크하우스를 강화하는 완전하고 권위 있는 데이터 소스

Azure 데이터 레이크란 무엇인가요?
Azure 데이터 레이크에는 확장 가능한 클라우드 데이터 스토리지 및 분석 서비스가 포함됩니다. Azure 데이터 레이크 스토리지를 통해 조직은 다양한 처리, 분석 및 Data Science 사용 사례를 위해 모든 크기, 형식 및 속도의 데이터를 저장할 수 있습니다. 다른 Azure 서비스(예: Azure Databricks - Azure )와 함께 사용할 경우, 데이터 레이크 스토리지는 조직 전체에서 데이터를 저장하고 검색하는 데 훨씬 더 비용 효율적인 방법입니다.
데이터가 크든 작든, 빠르든 느리든, 정형이든 비정형이든, Azure 데이터 레이크는 Azure ID, 관리 및 보안과 통합되어 데이터 관리 및 거버넌스를 간소화합니다. Azure 스토리지는 자동으로 데이터를 암호화하며, Azure Databricks 는 조직의 보안 및 규정 준수 요구 사항을 충족하는 데이터 보호 도구를 제공합니다.

Azure 데이터 레이크가 필요한 이유는 무엇인가요?
데이터 레이크는 개방형 형식이므로 사용자는 데이터 웨어하우스와 같은 독점 시스템에 종속되지 않습니다. 개방형 표준과 형식은 최신 데이터 아키텍처에서 점점 더 중요해지고 있습니다. 또한 데이터 레이크는 오브젝트 스토리지를 확장하고 활용할 수 있기 때문에 내구성이 뛰어나고 비용이 저렴합니다. 또한, 비정형 데이터에 대한 고급 분석과 머신 러닝은 오늘날 기업의 가장 중요한 전략적 우선순위 중 하나입니다. 가공되지 않은 데이터를 정형, 비정형, 반정형 등 다양한 형식으로 수집할 수 있는 고유한 기능과 앞서 언급한 다른 이점 덕분에 데이터 레이크는 데이터 스토리지를 위한 확실한 선택이 될 수 있습니다.
데이터 레이크는 적절하게 설계된 경우 다음과 같은 기능을 제공합니다:
- Power Data Science 및 머신 러닝
- 데이터 중앙 집중화, ��통합 및 카탈로그화
- 다양한 데이터 소스 및 형식의 빠르고 원활한 통합
- 사용자에게 셀프 서비스 도구를 제공하여 데이터를 민주화하세요.
Azure 데이터 레이크와 Azure 데이터 웨어하우스의 차이점은 무엇인가요?
데이터 레이크는 대량의 데이터를 원시 형식으로 보관하는 중앙 위치이자 매우 다양한 대량의 데이터를 정리할 수 있는 방법입니다. 파일이나 폴더에 데이터를 저장하는 계층형 데이터 웨어하우스에 비해, 데이터 레이크는 플랫 아키텍처를 사용하여 데이터를 저장합니다. 데이터 레이크는 일반적으로 확장 가능한 상용 하드웨어 클러스터에 구성됩니다. 따라서 데이터 형식, 크기, 저장 용량에 대한 걱정 없��이 나중에 필요할 때를 대비해 가공되지 않은 데이터를 레이크에 저장할 수 있습니다.
또한 데이터 레이크 clusters 는 온프레미스 또는 클라우드 내에 존재할 수 있습니다. 과거에는 "데이터 레이크" 라는 용어가 종종 Hadoop 지향 객체 스토리지와 연관되었지만, 오늘날 이 용어는 일반적으로 더 넓은 범주의 객체 스토리지를 지칭합니다. 오브젝트 스토리지는 메타데이터 태그와 고유 식별자를 사용하여 데이터를 저장하므로 여러 지역에서 데이터를 쉽게 찾고 검색할 수 있으며 성능도 향상됩니다. Databricks 레이크하우스 플랫폼은 데이터 레이크의 모든 데이터를 데이터 기반 사용 사례에 얼마든지 사용할 수 있게 해줍니다.

데이터 레이크에 형식을 사용하는 이유는 무엇인가요?Delta Lake Azure
Apache Parquet, CSV, JSON 및 기타 형식에서 데이터 레이크를 Delta Lake 형식으로 변환해야 하는 5가지 주요 이유는 다음과 같습니다:
- 데이터 손상 방지
- 더 빠른 쿼리
- 데이터 최신성 향상
- ML 모델 재현
- 규정 준수 달성
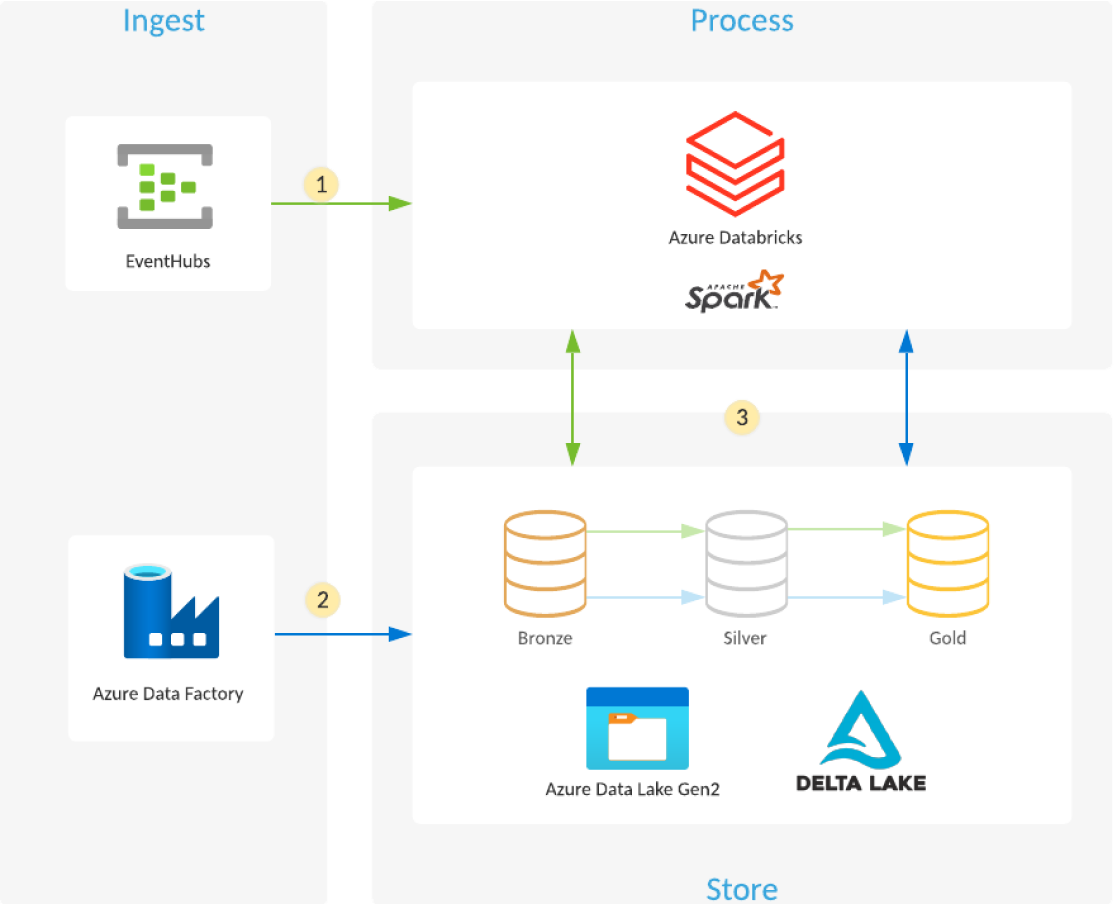
Azure Databricks 및 Azure 데이터 레이크 스토리지를 사용하여 데이터 레이크를 구축하려면 어떻게 해야 하나요?
관리되는 Delta Lake ( Azure Databricks )는 클라우드에서 데이터 레이크의 가치를 큐레이션, 분석 및 도출할 수 있는 안정성의 계층을 제공합니다.
- Azure Databricks 는 이벤트 Azure 허브, Azure IoT 허브 또는 과 Kafka Delta Lake 같은 Azure 이벤트 대기열에서 스트리밍 데이터를 읽고, 원시 이벤트를 데이터 레이크 스토리지에 저장된 최적화된 압축된 테이블 및 폴더(브론즈 레이어)로 로드합니다.
- 예약 또는 트리거된 Azure 데이터 팩토리 파이프라인은 다양한 데이터 소스에서 원시 형식의 데이터를 Azure 데이터 레이크 스토리지로 복사합니다. 의 Auto Loader 은 Azure Databricks 파일이 도착하면 이를 Delta Lake 처리하여 Azure 데이터 레이크 스토리지에 저장된 최적화된 압축된 테이블 및 폴더(브론즈 레이어)에 로드합니다.
- 스트리밍 또는 예약/트리거된 Azure Databricks 작업은 브론즈 계층에서 새 트랜잭션을 읽은 다음, ACID 트랜잭션(INSERT, UPDATE, 삭제, 병합)을 사용해 Delta Lake Azure 데이터 레이크 스토리지의 에 저장된 큐레이팅된 데이터 세트(실버 및 골드 레이어)로 로드합니다.
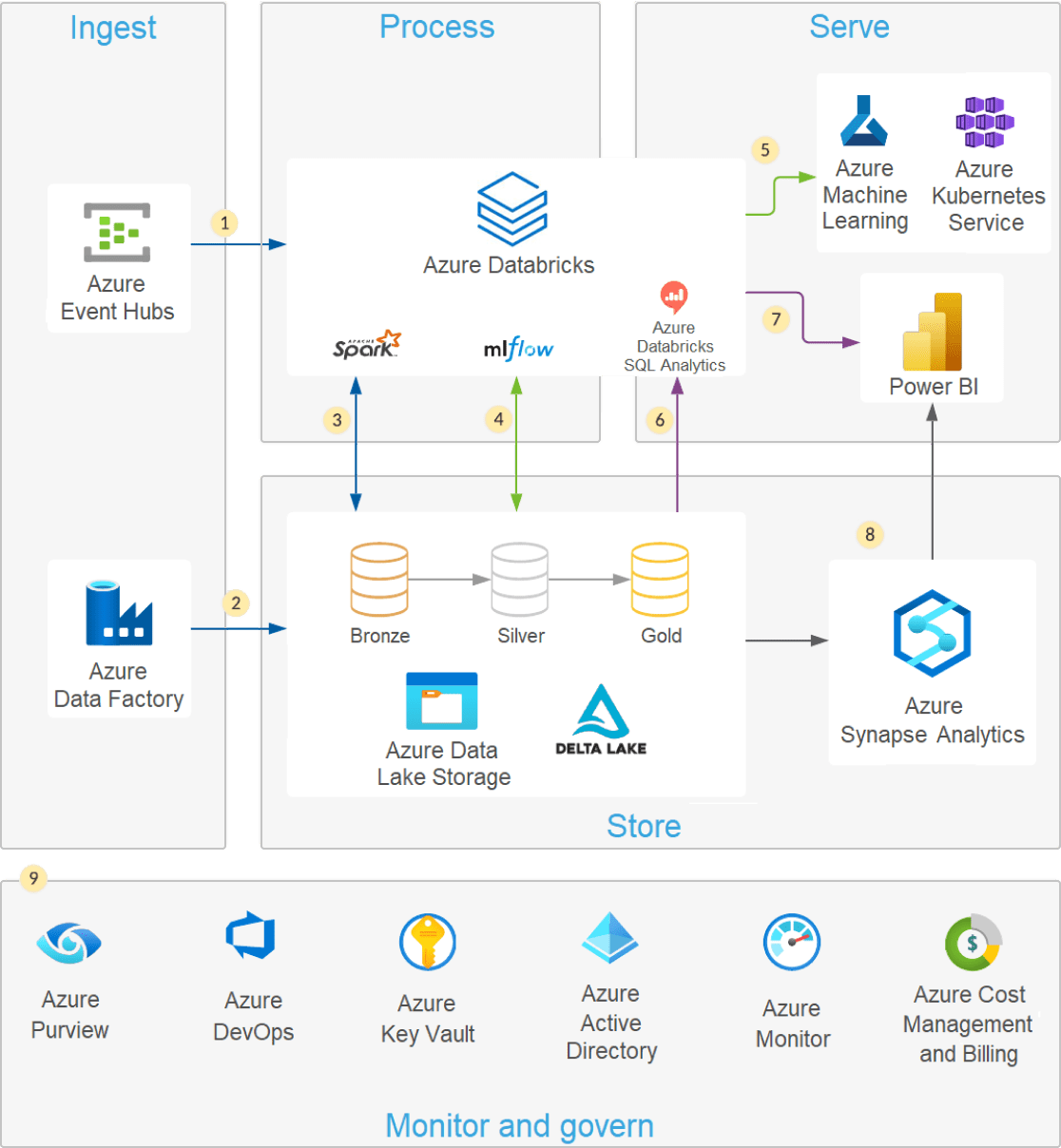
최신 데이터 레이크 아키텍처
웨어하우스의 성능, 안정성 및 데이터 무결성과 데이터 레이크에서 사용할 수 있는 유연성, 확장성 및 비정형 데이터에 대한 지원을 결합한 최신 레이크하우스 아키텍처입니다.
최신 데이터 레이크는 클라우드 탄력성을 활용하여 스키마나 구조를 강요할 필요 없이 사실상 무제한의 데이터 "(" )를 있는 그대로 저장할 수 있습니다. SQL(구조화된 쿼리 언어)은 데이터를 탐색하고 가치 있는 인사이트를 발견할 수 있는 강력한 쿼리 언어입니다. Delta Lake 는 ACID 트랜잭션, 확장 가능한 메타데이터 처리, 통합 스트리밍 및 배치 데이터 처리로 데이터 레이크에 안정성을 제공하는 오픈 소스 스토리지 계층입니다. Delta Lake는 완벽하게 호환되며 기존 데이터 레이크에 안정성을 제공합니다.
SQL 및 Delta Lake 과 Azure Databricks 를 사용하여 데이터 레이크를 쉽게 쿼리할 수 있습니다. Delta Lake를 사용하면 데이터를 이동하거나 복사하지 않고도 스트리밍 데이터와 배치 데이터 모두에서 SQL 쿼리를 실행할 수 있습니다. Azure Databricks Delta Lake 을 사용하면 클라우드 서비스와의 기본 통합을 통해 데이터 레이크를 보호하고, 최적의 성능을 제공하며, 데이터 파이프라인을 감사하고 문제를 해결하는 데 도움이 되는 추가적인 이점을 얻을 수 있습니다.
- Delta Lake 확장 가능한 클라우드 스토리지와 통합 또는 HDFS 데이터 사일로를 제거하는 데 도움이 됩니다.
- 데이터 레이크에서 직접 데이터 사용 SQL 쿼리 및 ACID 호환 트랜잭션 레이어 살펴보기
- 골드, 실버 및 브론즈 메달리온 테이블 "" 을 활용하여 데이터 파이프라인 및 분석 워크플로우의 데이터 품질을 통합하고 간소화하세요.
- Delta Lake 시간 이동을 사용하여 시간이 지남에 따라 데이터가 어떻게 변했는지 확인하세요.
- Azure Databricks Delta 캐시, 파일 압축 및 데이터 건너뛰기와 같은 기능으로 성능을 최적화합니다.