
대규모 언어 모델이란?
대규모 언어 모델(LLM)은 번역, 질문 응답, 채팅, 콘텐츠 요약, 코드 생성 등 다양한 언어 관련 작업을 효과적으로 처리하는 머신 러닝 모델입니다. LLM은 방대한 데이터 세트에서 학습한 지식을 활용하여 즉시 가치 있는 정보를 제공합니다. Databricks에서는 이러한 LLM에 간편하게 액세스하여 워크플로에 통합할 수 있을 뿐만 아니라 도메인 성능 향상을 위해 자체 데이터를 사용하여 LLM을 미세 조정할 수 있는 플랫폼 기능을 제공합니다.

LLM으로 자연어 처리
S&P Global은 Databricks의 대규모 언어 모델을 사용해 회사 자료에서 주요 차이점과 유사점을 정확하게 파악하여 자산 관리자가 보다 다양한 포트폴리오를 구축하도록 돕습니다.
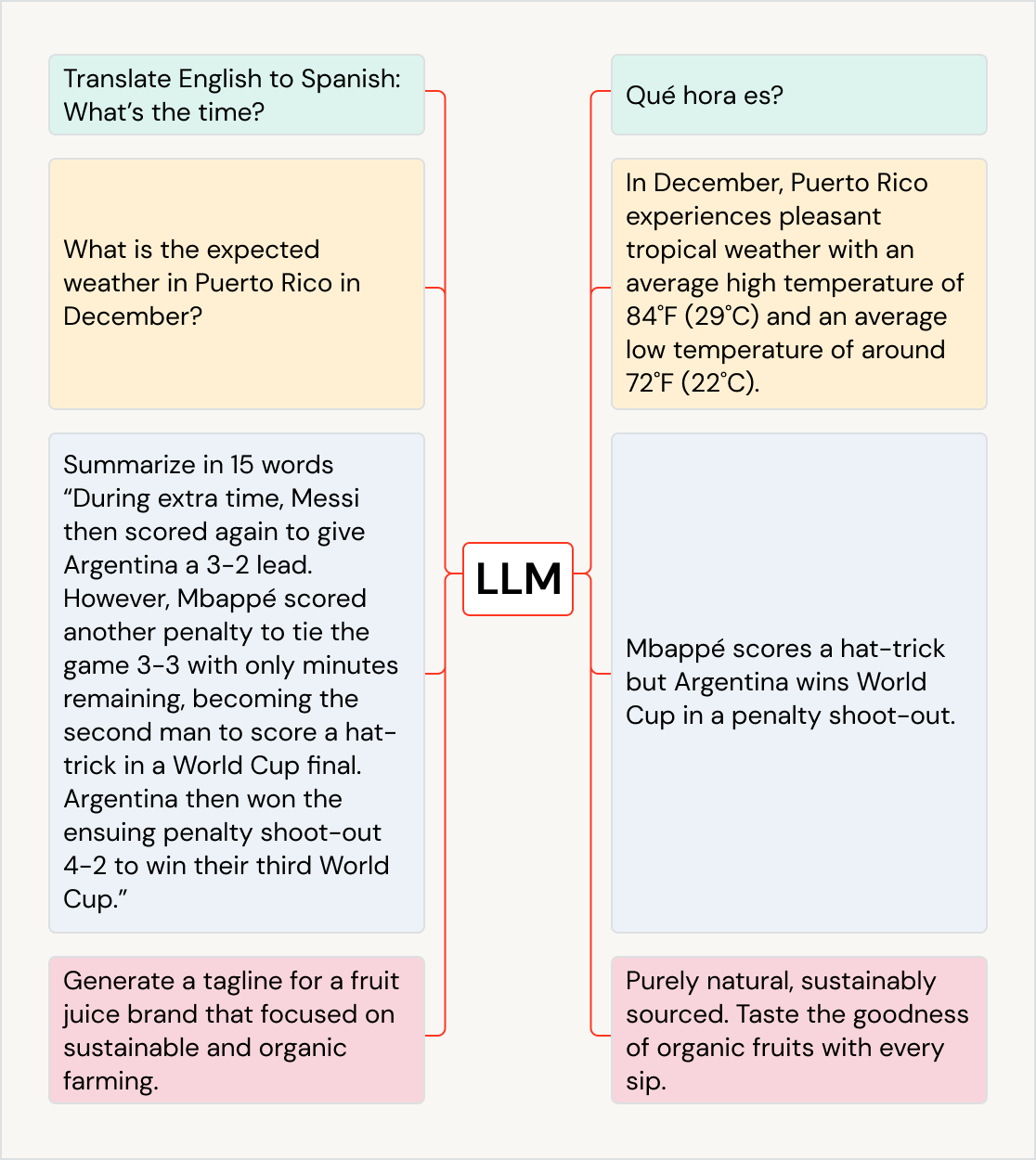
다양한 사례에 사용되는 LLM
LLM은 사용 사례 및 산업 전반에서 비즈니스 영향력을 이끌어낼 수 있습니다. 즉, 텍스트를 다른 언어로 번역하고, 챗봇 및 AI 어시스턴트로 고객 경험을 개선하고, 고객 피드백을 올바른 부서로 정리 및 분류하고, 실적 발표 및 법률 문서와 같은 대용량 문서를 요약하고, 새로운 마케팅 콘텐츠를 작성하고, 자연어에서 소프트웨어 코드를 생성합니다. LLM은 예술을 만들어내는 것과 같이 다른 모델에 공급하는 데 사용될 수도 있습니다. 많이 사용되는 LLM에는 GPT 모델 제품군(예: ChatGPT), BERT, T5, BLOOM이 있습니다.
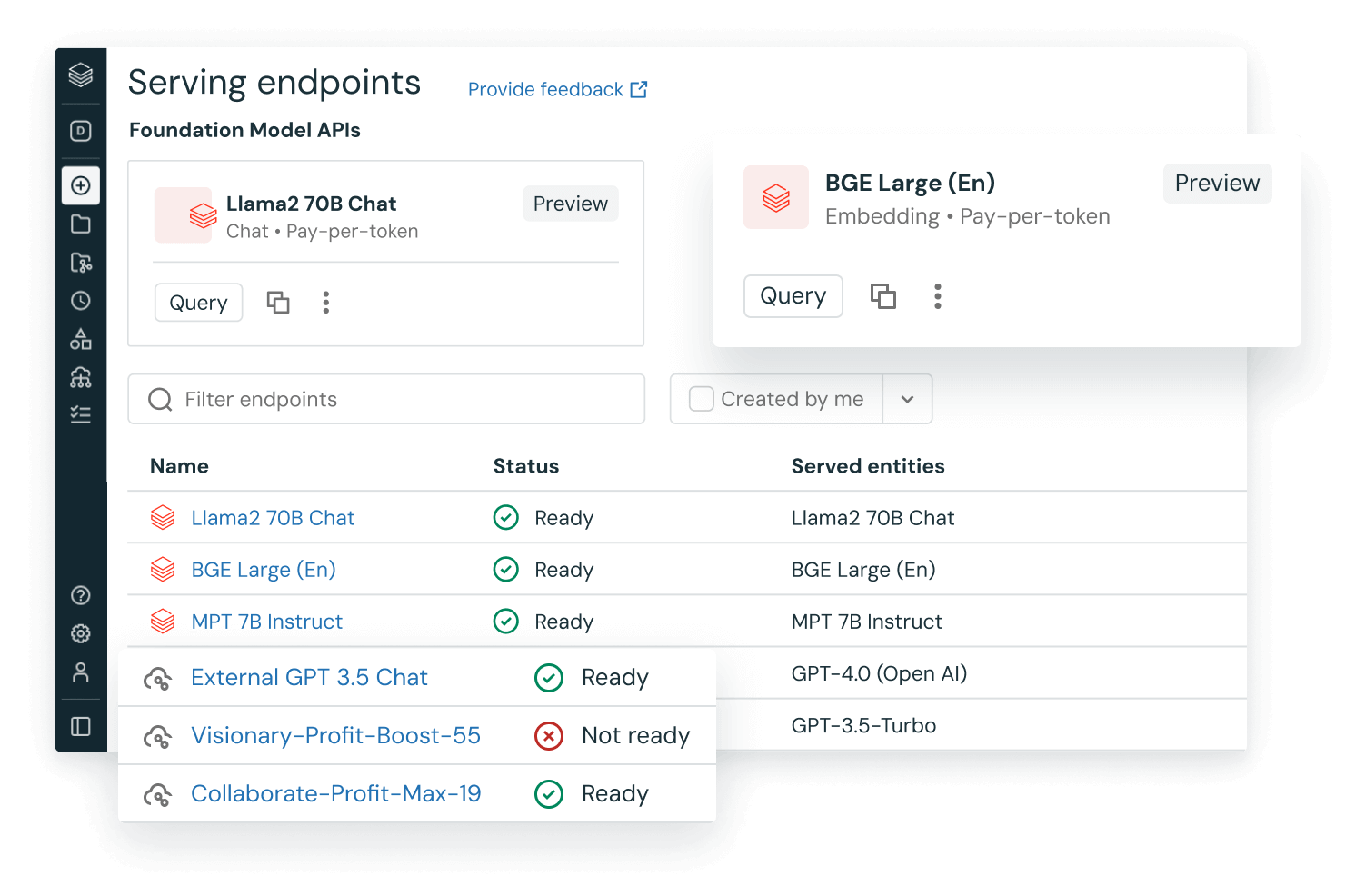
내 앱에서 사전 학습된 LLM 사용
Hugging Face의 Transformer 라이브러리 또는 기타 오픈 소스 라이브러리의 모델과 같은 선행 학습된 기존 모델을 워크플로에 통합합니다. Transformer 파이프라인을 사용하면 손쉽게 GPU를 사용하고 GPU로 전송된 항목을 배치 처리하여 처리량을 높일 수 있습니다.
Hugging Face Transformer용 MLflow 버전을 사용하면 변환 파이프라인, 모델 및 처리 구성 요소를 MLflow 추적 서비스에 기본적으로 통합할 수 있습니다. Databricks의 워크플로에서 OpenAI 모델 또는 John Snow Labs와 같은 파트너의 솔루션을 통합할 수도 있습니다.
SQL 데이터 애널리스트는 AI 기능을 사용하여 데이터 파이프라인과 워크플로 내에서 직접 OpenAI와 같은 LLM 모델에 쉽게 액세스할 수 있습니다.
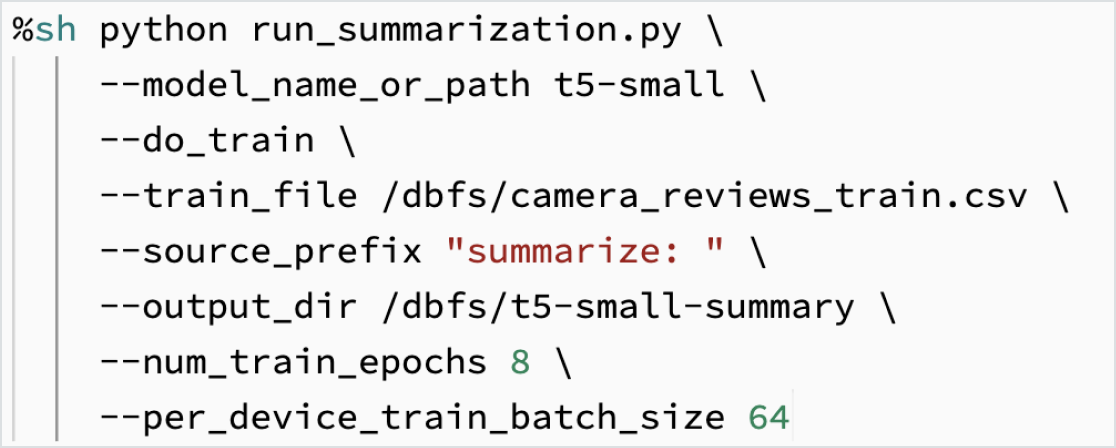
데이터를 사용한 LLM 미세 조정
특정 ��작업을 위한 자체 데이터의 모델을 맞춤 구성합니다. Hugging Face, DeepSpeed 등 오픈 소스 도구를 활용하면 기본 LLM을 빠르게 적용하고 자체 데이터를 이용해 도메인 특화 학습으로 정확도를 높일 수 있습니다. 이렇게 하면 학습에 사용되는 데이터를 직접 제어할 수 있어 AI를 책임감 있게 사용할 수 있습니다.

Dolly 2.0은 Databricks에서 훈련한 대규모 언어 모델로, 자체 LLM을 저렴한 비용으로 빠르게 훈련할 수 있는 방법을 보여줍니다. 모델을 훈련하는 데 사용되는 고품질 인간 생성 데이터 세트(databricks-dolly-15k)도 오픈 소스였습니다. Dolly 2.0을 통해 고객은 이제 자신의 LLM을 소유, 운영 및 사용자 정의 할 수 있습니다. 기업은 독점 LLM에 데이터를 보낼 필요 없이 자체 데이터로 LLM을 구축하고 훈련할 수 있습니다. Dolly 2.0 코드, 모델 가중치 또는 databricks-dolly-15k 데이터 세트를 얻으려면 Hugging Face를 방문하세요.
내장형 LLMOps(LLM용 MLOps)
모델 추적, 관리 및 배포를 위한 관리형 MLflow와 함께 프로덕션에 바로 사용할 수 있는 내장형 MLOps를 사용합니다. 모델이 배포되면 엔드 투 엔드 LLMOps를 위한 동일한 통합 Databricks 레이크하우스 플랫폼에서 파이프라인 재학습을 실행하는 기능을 사용하여 레이턴시, 데이터 드리프트 등을 모니터링할 수 있습니다.
통합 플랫폼의 데이터 및 모델
대부분의 모델은 두 번 이상 학습을 거치므로 동일한 ML 플랫폼에 학습 데이터를 보관하는 것이 성능과 비용 측면에서 중요합니다. 비용 효율적인 레이크하우스에서 LLM을 학습시키면 최고의 툴과 컴퓨팅에도 액세스할 수 있을 뿐만 아니라 장기적으로 데이터의 발전 속도에 맞춰 모델을 계속 재학습시킬 수 있습니다.