
Databricks Vector Search를 통해 생성형 AI의 잠재력 극대화
Vector Search는 서버리스 벡터 데이터베이스로
데이터 인텔리전스 플랫폼에 원활하�게 통합됩니다.
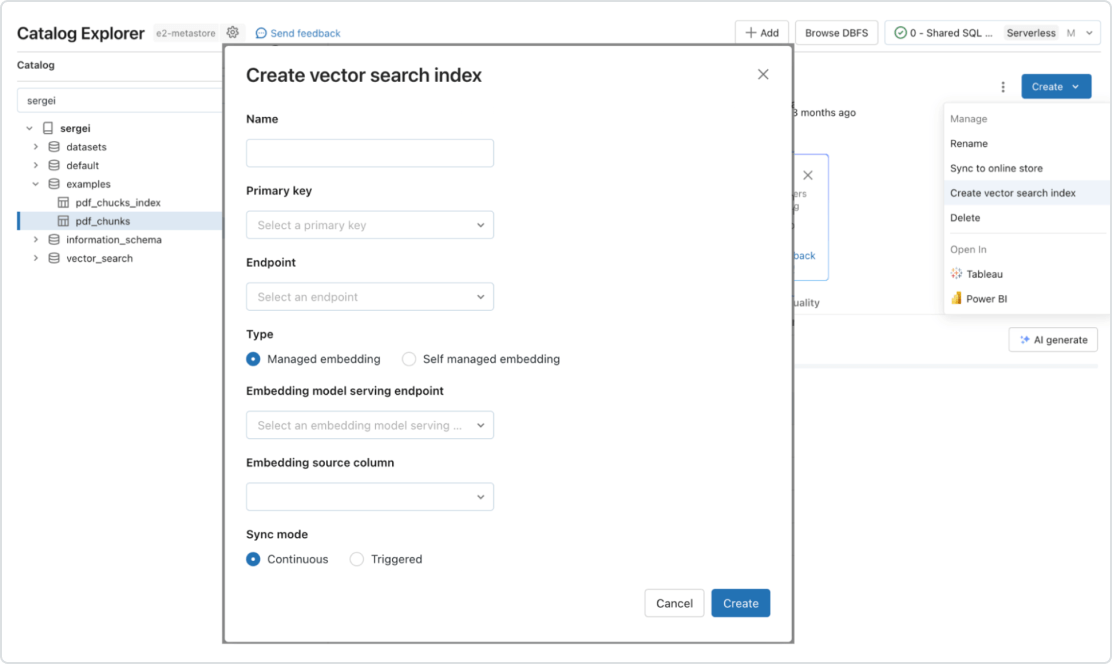
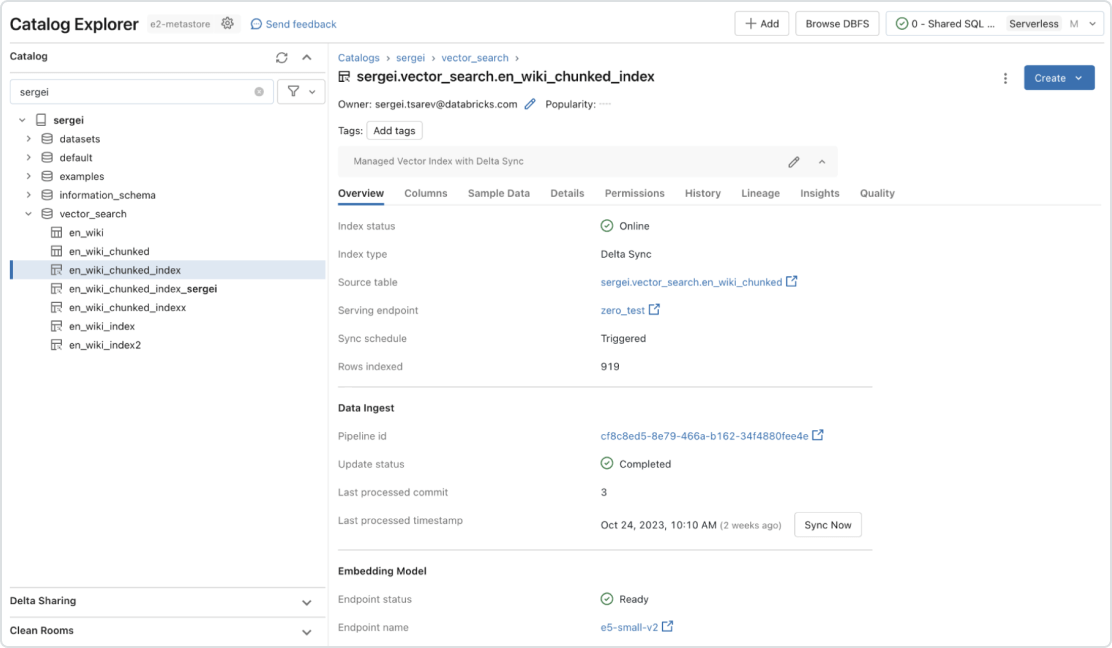
다른 데이터베이스와 달리 Databricks Vector Search는 소스에서 인덱스로의 자동 데이터 동기화를 지원하므로 복잡하고 비용이 많이 드는 파이프라인 유지 보수가 필요하지 않습니다. 이는 조직이 안심하고 사용할 수 있도록 이미 구축한 것과 동일한 보안 및 데이터 거버넌스 도구를 활용합니다. Databricks Vector Search는 서버리스 설계를 통해 초당 수십억 개의 임베딩과 수천 개의 실시간 쿼리를 지원하도록 쉽게 확장됩니다.
검색 증강 생성(RAG)을 고려한 설계
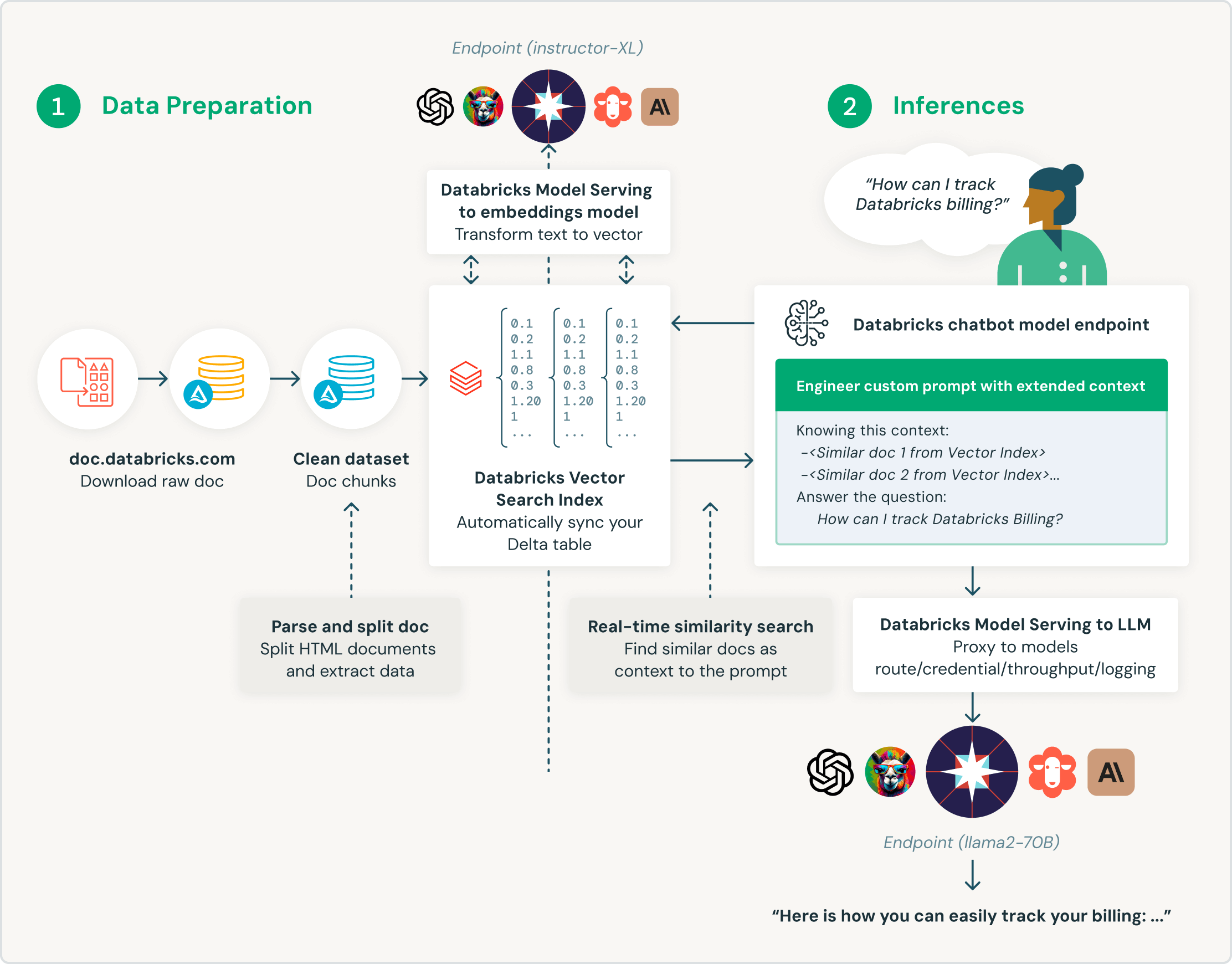
Databricks Vector Search는 고객이 엔터프라이즈 데이터로 대규모 언어 모델(LLM)을 강화할 수 있도록 특별히 설계되었습니다. 검색 증강 생성(RAG) 애플리케이션을 위해 특별히 설계된 Databricks Vector Search는 유사성이 높은 검색 결과를 제공하여 컨텍스트와 도메인 지식으로 LLM 쿼리를 강화하고 결과의 정확성과 품질을 개선합니다.
자동화된 실시간 파이프라인
새로운 데이터가 도입, 수정, 제거될 때 해당하는 벡터 인덱스를 자동으로 업데이트��하여 소스 데이터를 실시간으로 동기화합니다. 내부적으로 Databricks는 임베딩 벡터 생성 및 관리, 오류 자동 관리, 재시도 처리, 처리량 최적화뿐만 아니라 어떠한 개입도 없이 자동 배치 크기 조정 및 자동 확장을 수행합니다.
거버넌스 기본 제공
통합 인터페이스는 임베딩에 대한 세분화된 액세스 제어 권한으로 데이터에 대한 정책을 정의합니다. Unity Catalog와 기본적으로 통합되는 Vector Search는 추가 도구나 보안 정책 없이 자동으로 데이터 리니지와 추적을 보여 줍니다. 따라서 LLM 모델은 액세스가 허용되지 않은 사용자에게 기밀 데이터를 노출하지 않게 됩니다.
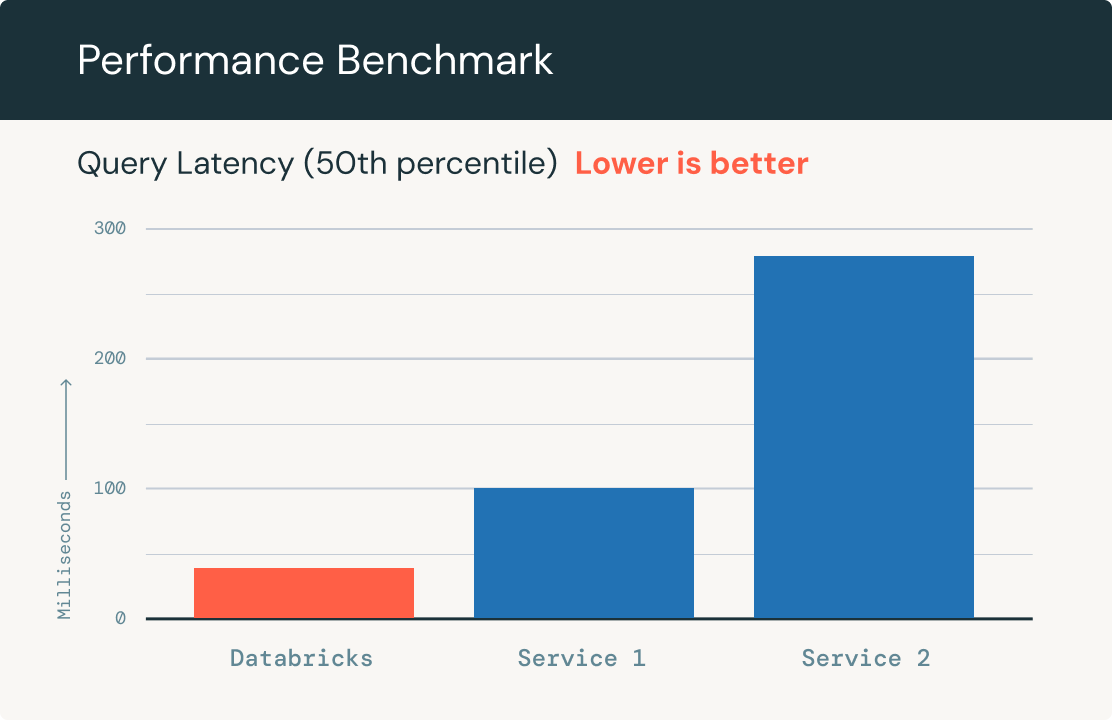
빠른 쿼리 성능
인덱스에 포함된 수십억 개의 임베딩과 초당 수천 개의 쿼리를 처리하도록 자동으로 확장됩니다. 최대 100만 개의 OpenAI 임베딩 데이터 세트에서 다른 주요 벡터 데이터베이스보다 최대 5배 빠른 성능을 보여 줍니다.