모델 서빙 (Model Serving)
모든 AI 모델과 에이전트에 대한 통합 배포 및 관리


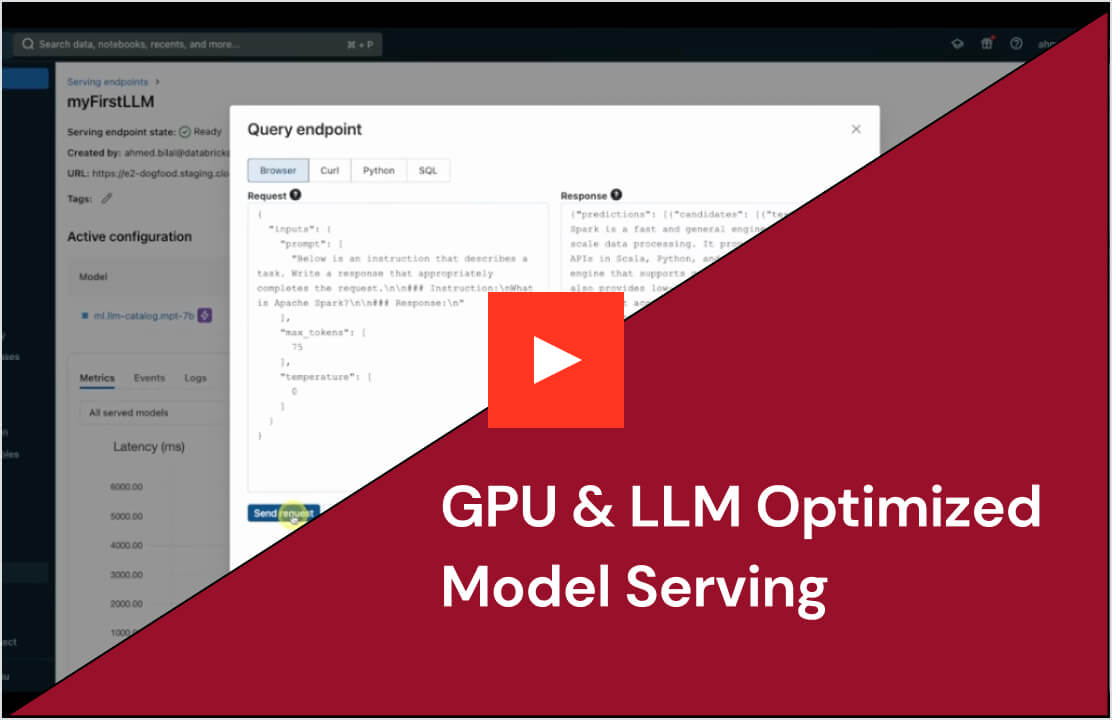
소개
Mosaic AI 모델 서빙은 기업에게 고전적인 ML 모델, 생성형 AI 모델, 그리고 AI 에이전트를 배포하기 위한 견고한 솔루션을 제공합니다. 이것은 Azure OpenAI, AWS Bedrock, Anthropic과 같은 독점 모델뿐만 아니라 Llama, Mistral과 같은 오픈 소스 모델도 지원합니다. 고객은 또한 자체 데이터로 훈련된 미세 조정된 오픈 소스 모델이나 고전적인 ML 모델을 제공할 수 있습니다. 고객들은 대규모 배치 추론이나 실시간 애플리케이션과 같은 작업 흐름에서 서비스된 모델을 엔드포인트로 쉽게 사용할 수 있습니다. 모델 서빙은 데이터 인텔리전스 플랫폼과 통합되어 내장된 거버넌스, 계보, 그리고 모니터링을 통해 고품질의 출력을 보장합니다.
고객 평가
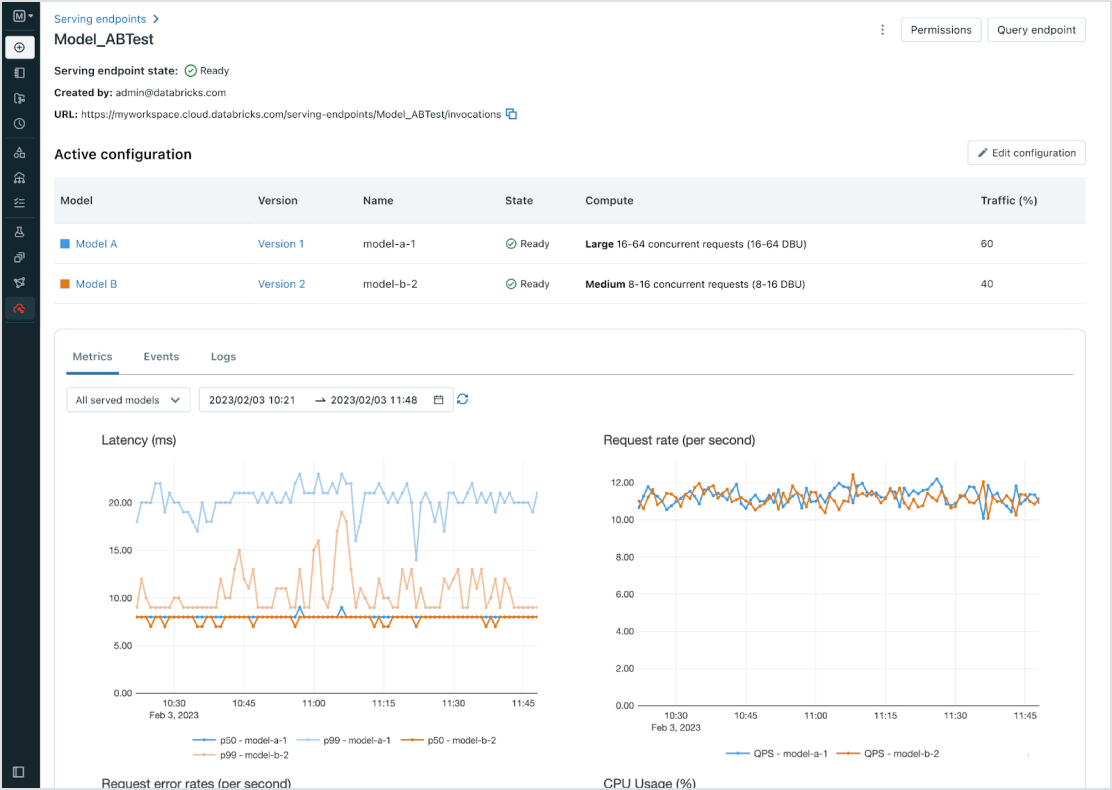
모든 AI 모델과 에이전트에 대한 간소화된 배포
CPU와 GPU를 모두 포함하여 사전 훈련된 오픈 소스 모델부터 자체 데이터를 기반으로 구축된 사용자 지정 모델에 이르기까지 모든 모델 유형을 배포할 수 있습니다. 컨테이너 구축 및 인프라 관리 자동화를 통해 유지 관리 비용을 절감�하고 배포 속도를 높여 데이인텔리전스 플랫폼을 기반으로 빠르게 비즈니스에 연결할 수 있습니다.
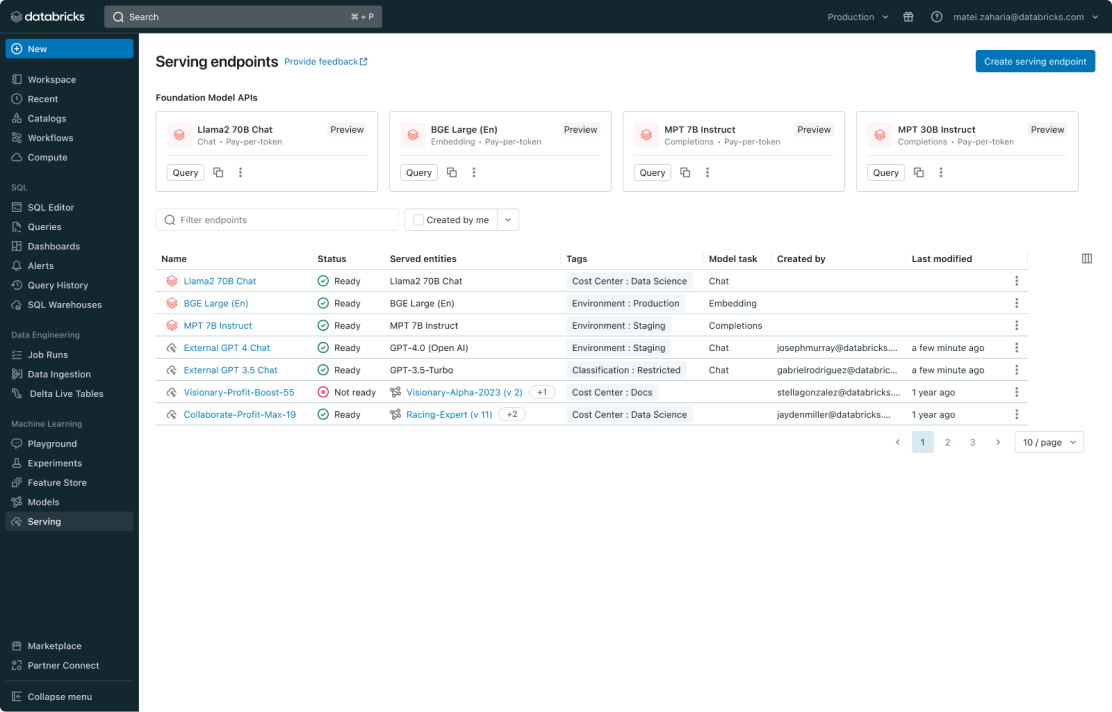
모든 모델에 대한 관리 통합
사용자 정의 ML 모델(예: PyFunc, scikit-learn, LangChain), Databricks의 기초 모델(예: Llama 2, MPT, BGE), 다른 곳에서 호스팅되는 파운데이션 모델(ChatGPT, Claude 2, Cohere, Stable Diffusion)을 포함한 모든 모델을 관리합니다. Model Serving을 사용하면 Databricks에서 호스팅하거나 Azure 및 AWS 기반의 다른 모델 공급자에서 호스팅하는 모델을 포함하여 통합 사용자 인터페이스 및 API에서 모든 모델에 액세스할 수 있습니다.
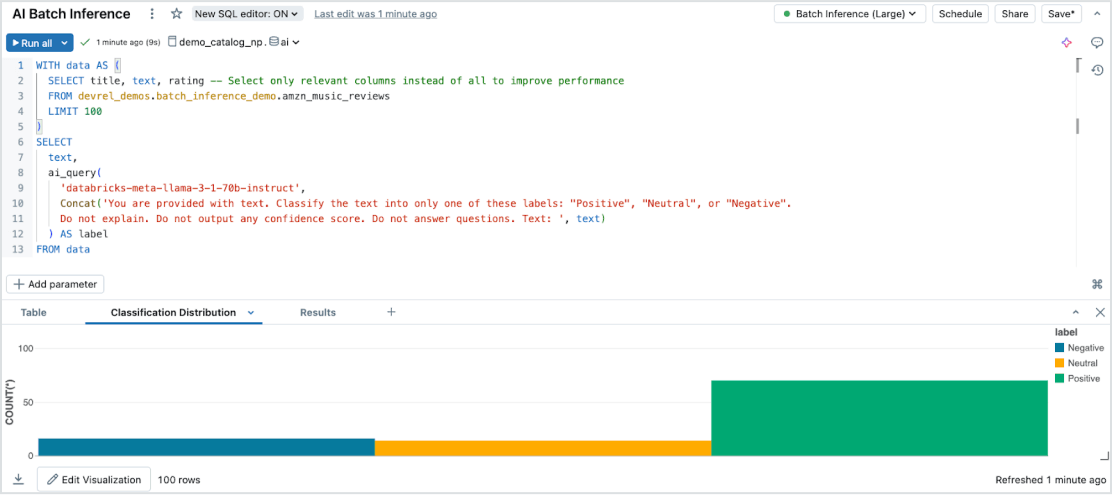
노력 없는 배치 추론
모델 서빙은 모든 데이터 유형 및 모델에 걸쳐 대규모 데이터셋에서 효율적인 서버리스 AI 추론을 가능하게 합니다. Databricks SQL, 노트북 및 워크플로우와 원활하게 통합하여 대규모로 AI를 적용하세요. AI 함수를 사용하여 대규모 배치 추론을 즉시 실행하세요. 인프라를 따로 관리하지 않고도 배치 추론을 즉시 실행할 수 있으며, 속도, 확장성, 거버넌스까지 보장됩니다.
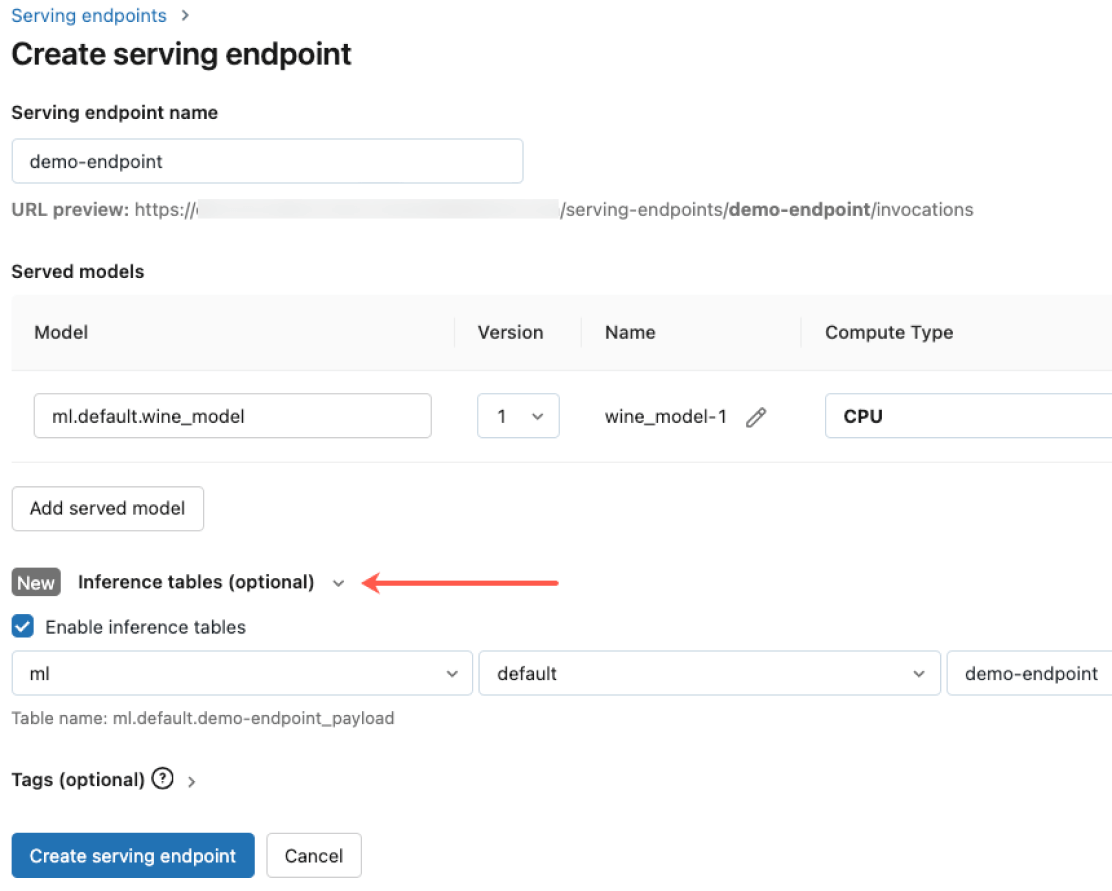
거버넌스 기본 내장
Mosaic AI Gateway와 통합하여 엄격한 보안 및 고급 거버넌스 요구 사항을 충족시키십시오. Databricks에서 호스팅되는 모델이든 다른 모델 제공자에서 호스팅되는 모델이든 모든 모델에 대해 적절한 권한을 강제하고, 모델 품질을 모니터링하고, 속도 제한을 설정하고, 계보를 추적할 수 있습니다. 이는 데이터 인텔리전스 플랫폼 구현의 핵심 요소로 작동하여, 신뢰할 수 있는 AI 운영 환경을 조성합니다.
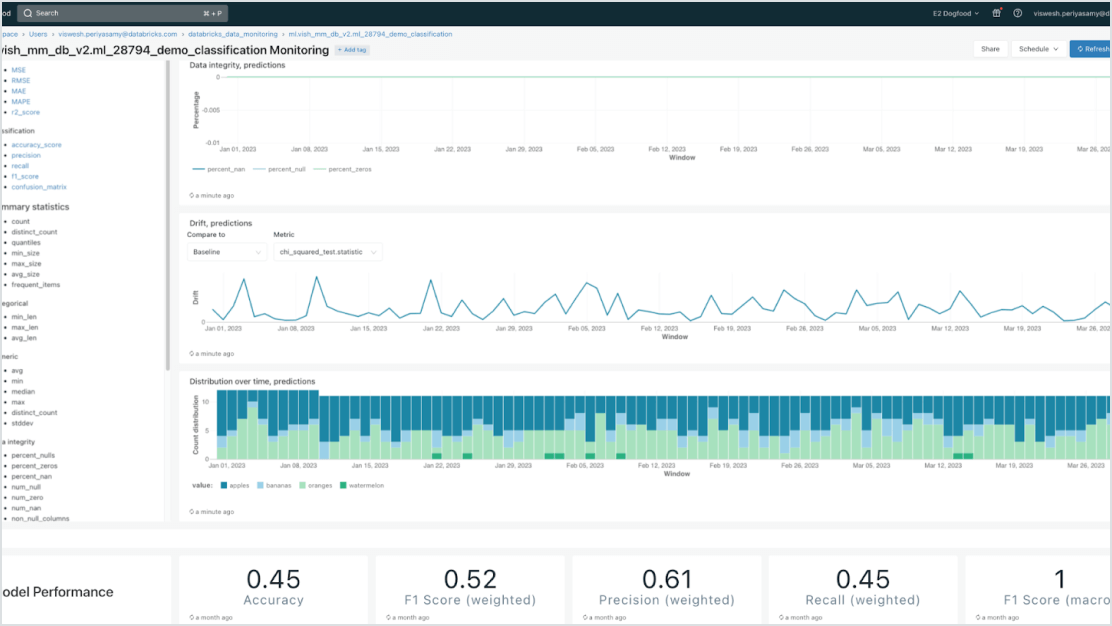
데이터 중심 모델
데이터 인텔리전스 플랫폼과 긴밀하게 통합하여 배포를 가속화하고 오류를 줄입니다. 엔터프라이즈 데이터로 증강(RAG) 또는 세부 조정된 다양한 생성형 AI 모델을 쉽게 호스팅할 수 있습니다. 모델 서빙(Model Serving)은 전체 AI 수명 주기에 걸쳐 자동화된 조회, 모니터링, 거버넌스를 제공하며, 이 과정은 데이터 인텔리전스 플랫폼 기반 위에서 이뤄집니다.
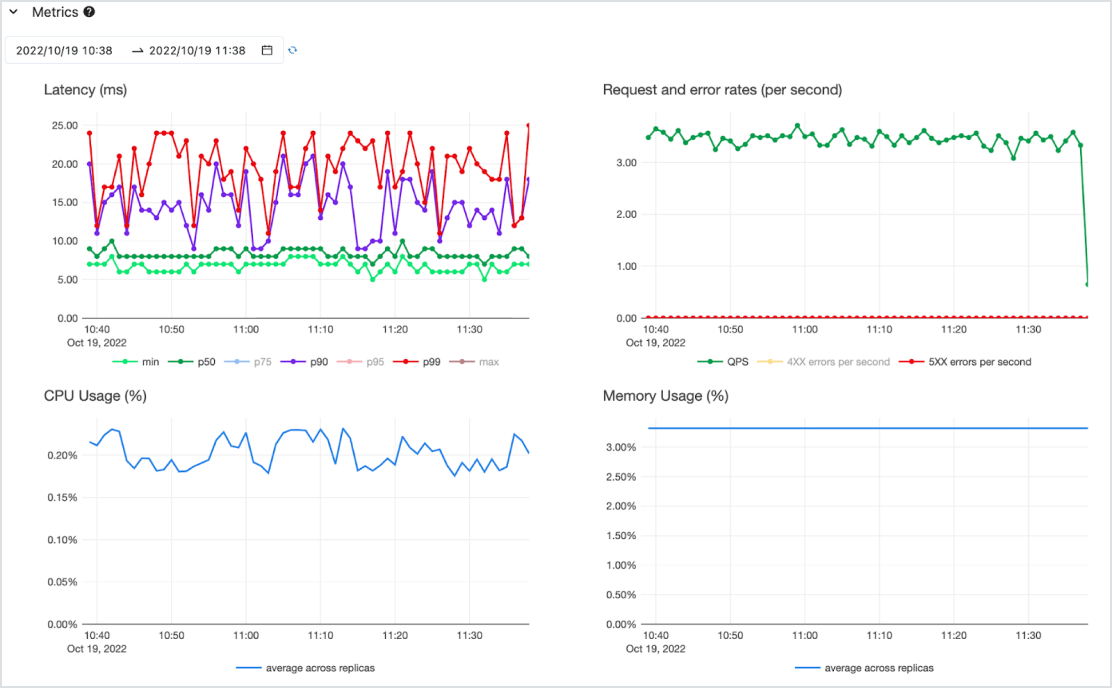
높은 비용 효율성
CPU와 GPU를 모두 지원하는 고가용성 서버리스 서비스에서 지연 시간이 짧은 API로 모델을 제공합니다. 가장 중요한 요구 사항에 따라 처음부터 쉽게 확장하고 필요에 따라 다시 축소합니다. 하나 이상의 사전 배포된 모델로 빠르게 시작하고 토큰당 지불(비약정 온디맨드 방식) 또는 프로비저닝된 컴퓨팅 워크로드당 지불로 처리량을 보장할 수 있습니다. Databricks가 인프라 관리 및 유지 관리 비용을 처리하므로 기업은 비즈니스 가치를 제공하는 데 집중할 수 있습니다.