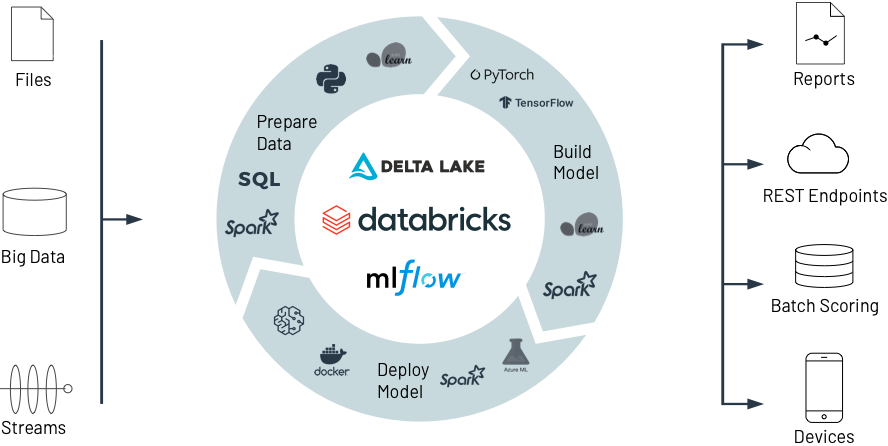
머신 러닝 수명 주기 단순화
조직 및 기술 사일로에서 전체 데이터 및 ML 수명 주기를 위한 개방형 통합 플랫폼으로 전환

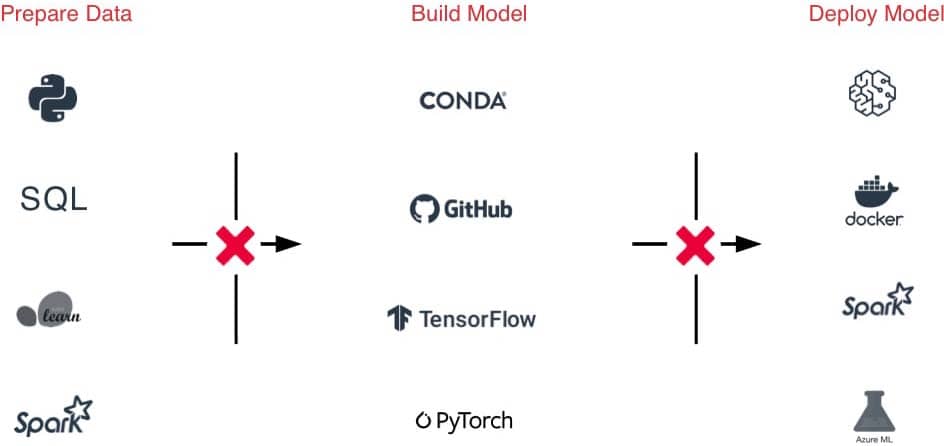
ML 모델을 구축하는 일은 어렵지만, 이를 프로덕션으로 옮기는 것이 더 어렵습니다. 시간 경과에 따라 데이터 품질과 모델 정확도를 유지하는 것은 당면한 과제 중 일부일 뿐입니다. Databricks는 데이터 준비부터 모델 훈련, 배포에 이르기까지 ML 개발을 규모에 맞게 간소화합니다.
문제점
ML 프레임워크의 다양성 수준이 매우 높기 때문에 ML 환경을 관리하기가 어렵습니다.
데이터 준비부터 Experiment, 프로덕션에 이르기까지 다양한 도구와 프로세스로 인해 팀 간 핸드오프가 어렵습니다.
모델, 종속성, 아티팩트, Experiment를 추적하기 어려워 결과를 재현하기가 어렵습니다.
보안 및 규정 준수 위험
솔루션
클릭 한 번으로 수명 주기 전반에 걸쳐 확장 가능하며 즉시 사용 가능하도록 최적화된 ML 환경에 액세스합니다.
하나의 플랫폼으로 데이터 수집, 기능화, 모델 구축, 조정 및 프로덕션화를 위한 핸드오프가 간소화됩니다.
하나의 중앙 허브에서 코드, 결과, 아티팩트 및 Experiment를 자동으로 추적하고 모델을 관리합니다.
세분화된 액세스 제어, 데이터 리니지, 버전 관리를 통해 규정 준수 요구를 충족 합니다.
Databricks 머신 러닝
Databricks가 Experiment부터 프로덕션까지 전례 없는 규모로 데이터를 공동으로 준비하고 최첨단 ML 모델을 구축, 배포, 관리하는 데 어떻게 도움이 되는지 알아보세요.
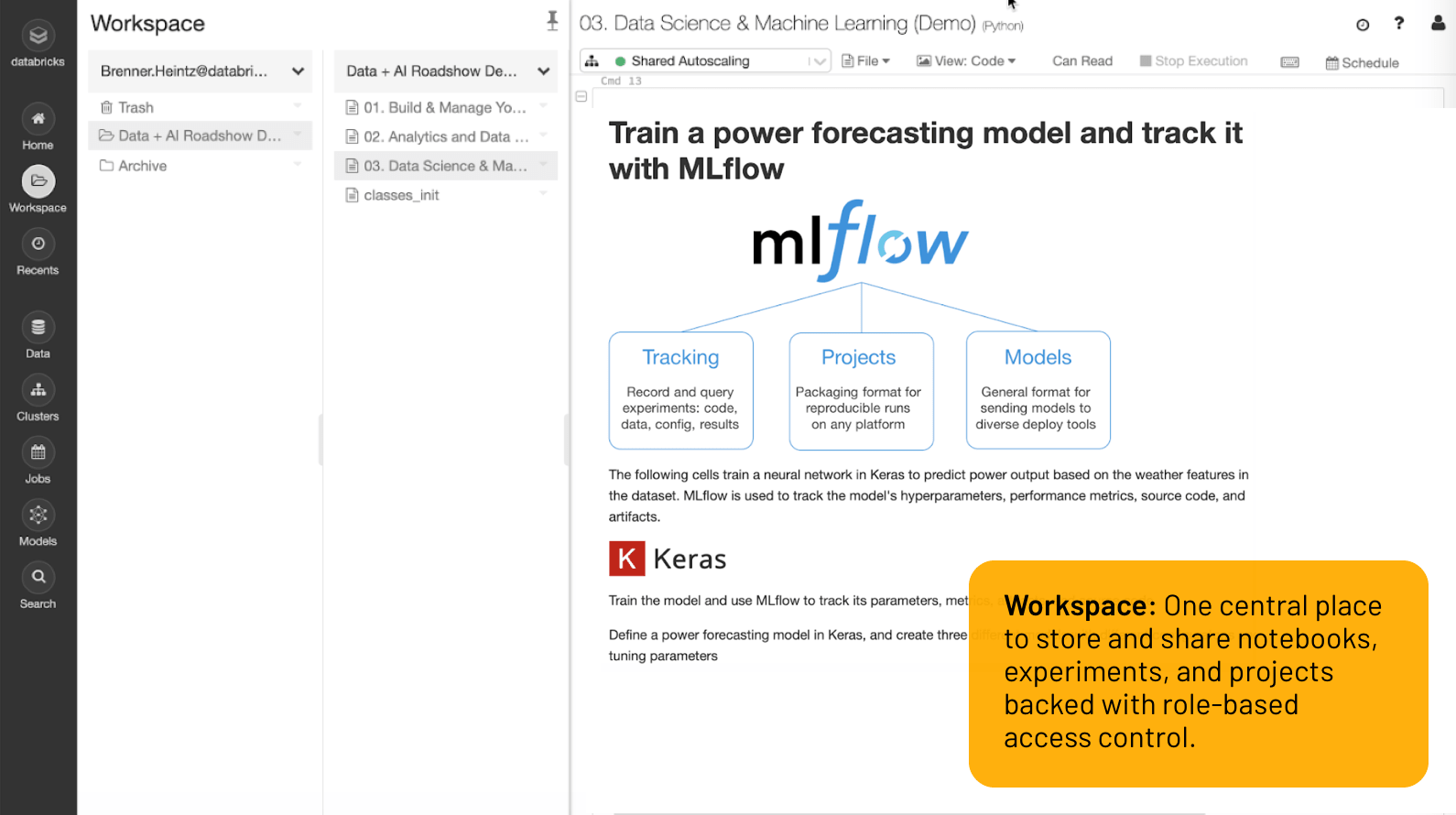
워크스페이스
하나의 중앙 위치에서 역할 기반 액세스 제어로 지원되는 노트북, Experiment, 프로젝트를 저장하고 공유할 수 있습�니다.
전례 없는 규모로 Experiment에서 프로덕션 ML까지
동급 최고 수준의 개발자 환경
워크스페이스에서 클릭 한 번이면 작업을 완료하는 데 필요한 모든 것이 가능합니다. 데이터 세트, ML 환경, 노트북, 파일, Experiment, 모델을 모두 한 곳에서 안전하게 사용할 수 있습니다.
다양한 언어(Python, R, Scala, SQL)를 지원하는 협업 노트북을 사용하면 공동 작성, Git 통합, 버전 관리, 역할 기반 액세스 제어 등을 통해 빈틈없이 관리할 수 있을 뿐만 아니라 팀으로 작업하기가 더 쉬워집니다. 또는 Databricks에서 Jupyter Lab, PyCharm, IntelliJ, RStudio 등과 같은 친숙한 도구를 사용하여 무제한 데이터 저장 및 컴퓨팅의 이점을 활용할 수 있습니다.
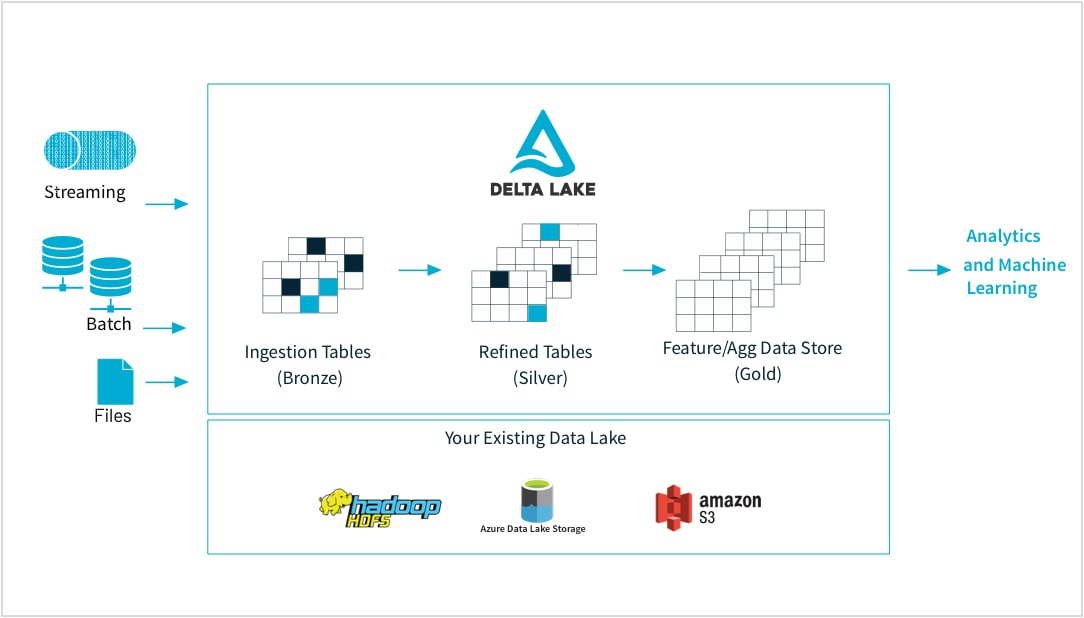
가공되지 않은 데이터에서 고품질 특성 저장소까지
머신 러닝 실무자는 작거나 큰 데이터 세트, DataFrames, 텍스트, 이미지, 배치 또는 스트리밍 등 다양한 형식에서 모델을 훈련시킵니다. 모두 특정 파이프라인과 변환이 필요합니다.
Databricks를 사용하면 거의 모든 소스에서 가공되지 않은 데이터를 수집하고, 배치 및 스트리밍 데이터를 병합하고, 변환을 예약하고, 테이블 버전을 지정하고, 품질 검사를 수행하여 데이터가 원본이고 나머지 조직에서 분석할 준비가 되어 있는지 확인할 수 있습니다. 이제 언제든지 모든 데이터, CSV 파일 또는 대규모 데이터 레이크 수집을 원활하고 신뢰할 수 있는 방식으로 작업할 수 있습니다.

scikit-learn, TensorFlow, PyTorch 등의 운영을 위한 최고의 플랫폼
ML 프레임워크는 엄청난 속도로 발전하고 있으며, 이는 ML 환경을 유지하기 어렵게 만들고 있습니다. Databricks ML 런타임은 가장 많이 사용되는 ML 프레임워크(scikit-learn, TensorFlow 등)와 Conda 지원을 포함하여 즉시 사용 가능하고 최적화된 ML 환경을 제공합니다.
하이퍼매개변수 조정과 같이 기본 제공되는 AutoML은 더 빠르게 결과를 얻는 데 도움이 되며, 단순화된 확장을 통해 소규모 데이터에서 �대규모 데이터로 쉽게 이동할 수 있으므로 더 이상 사용 가능한 컴퓨팅 양에 제한을 받지 않습니다. 예를 들어 HorovodRunner를 사용하여 클러스터 전체에 컴퓨팅을 분산하여 딥러닝 모델을 더 빠르게 훈련하고, TensorFlow의 CUDA 최적화 버전을 실행하여 클러스터의 각 GPU에서 더 많은 성능을 끌어냅니다.
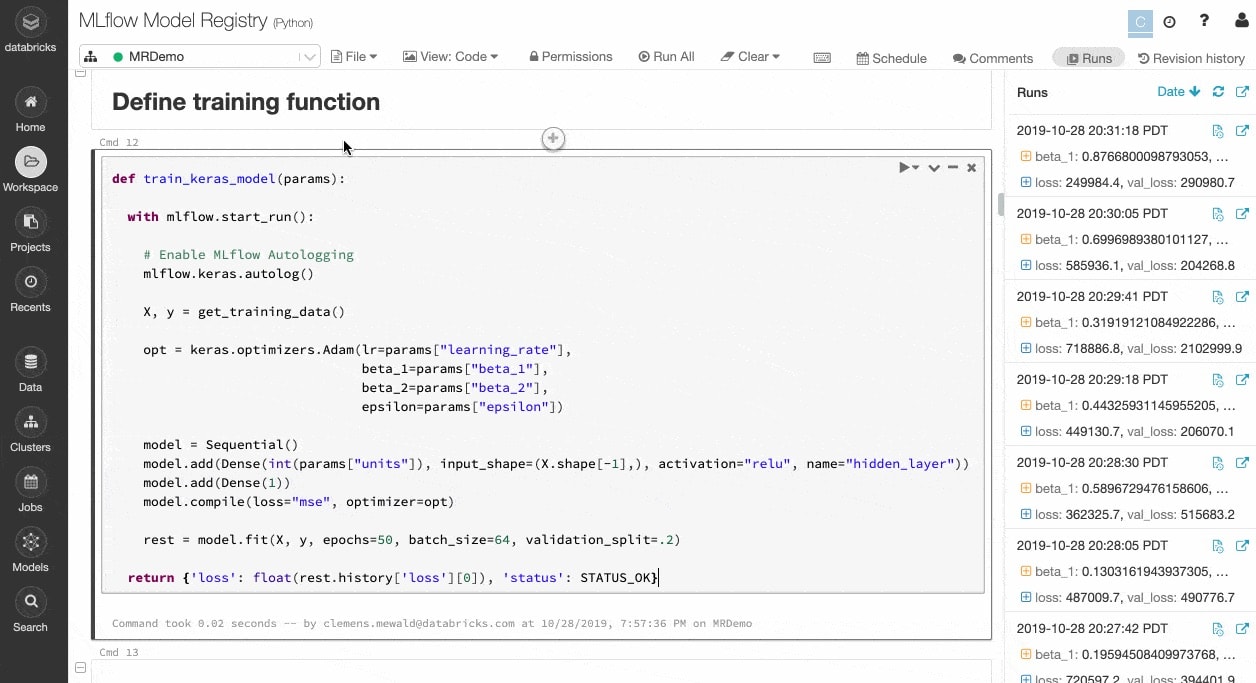
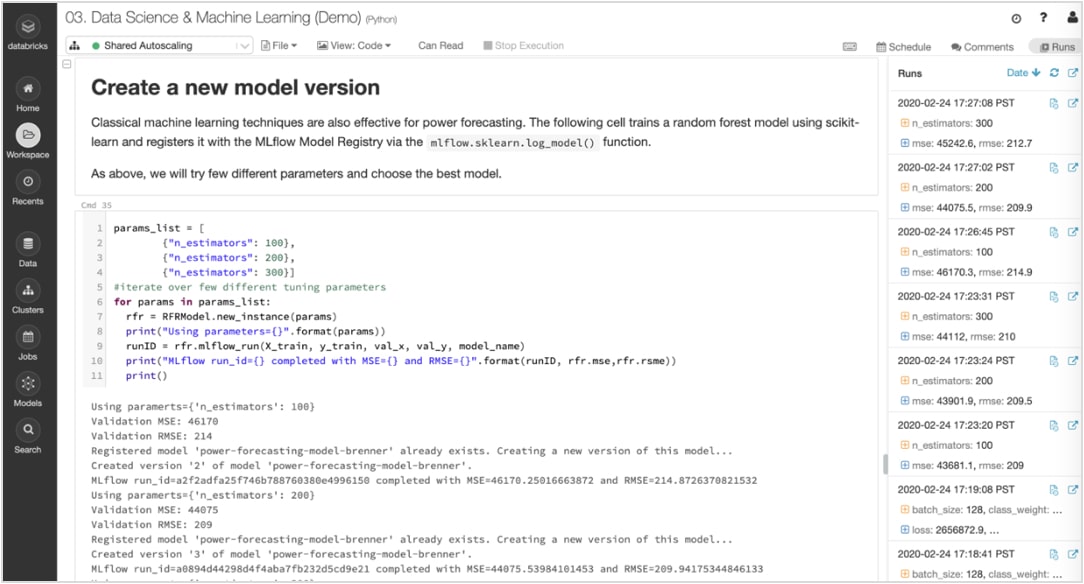
Experiment 및 아티팩트를 추적하여 나중에 실행 재현
ML 알고리즘에는 구성 가능한 매개변수가 수십 개 있으며, 단독으로 작업하든 팀으로 작업하든 모델을 생성하기 위해 각 Experiment에 어떤 매개변수, 코드, 데이터가 사용되었는지 추적하기가 어렵습니다.
MLflow는 노트북 내에서 실행되는 각 훈련에 대한 데이터, 코드, 매개변수, 결과와 같은 아티팩트와 함께 Experiment를 자동으로 추적합니다. 따라서 이전 실행을 한 눈에 신속하게 확인하고 결과를 비교하며 필요한 경우 이전 버전의 코드로 되돌릴 수 있습니다. 프로덕션에 가장 적합한 모델 버전을 확인했다면 이를 중앙 리포지토리에 등록하여 배포를 위해 제출하고 핸드오프를 단순화할 수 있습니다.
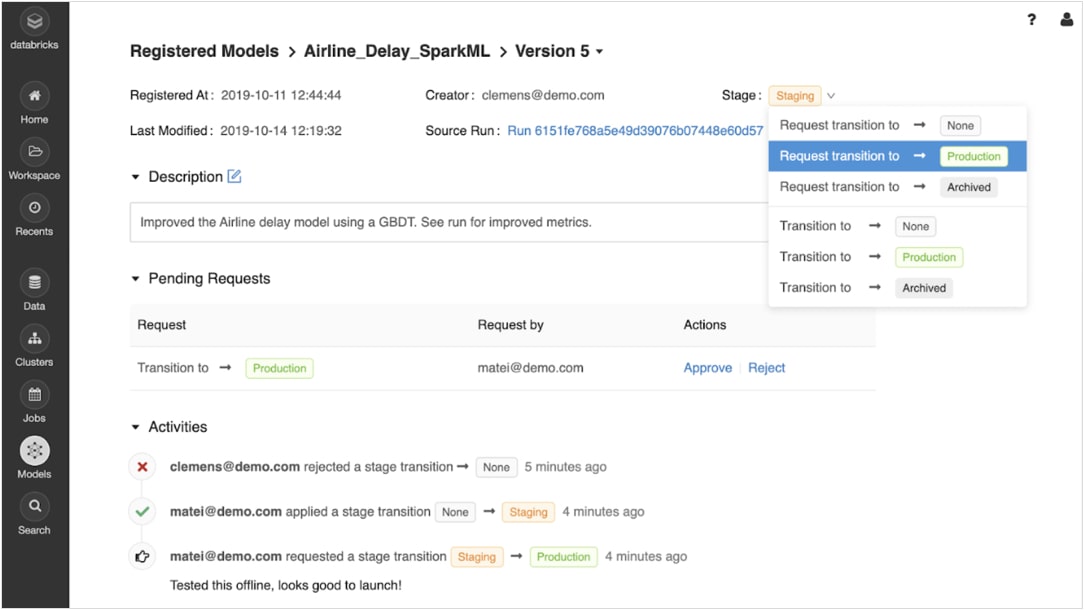
프로토타입 제작에서 프로덕션으로 자신 있게 전환
학습된 모델을 등록하면 MLflow 모델 레지스트리를 사용해 모델의 수명 주기 전반에 걸쳐 협업 방식으로 모델을 관리할 수 있습니다.
모델은 Experiment, 스테이징, 프로덕션, 보관 등 다양한 단계를 거치면서 버전을 관리하고 이동할 수 있습니다. 이해 관계자들은 단계 변경 요청을 제출하거나 의견을 제시할 수 있습니다. 모든 수명 주기 관리는 승인 및 거버넌스 워크플로, 역할 기반 액세스 관리와 통합됩니다.
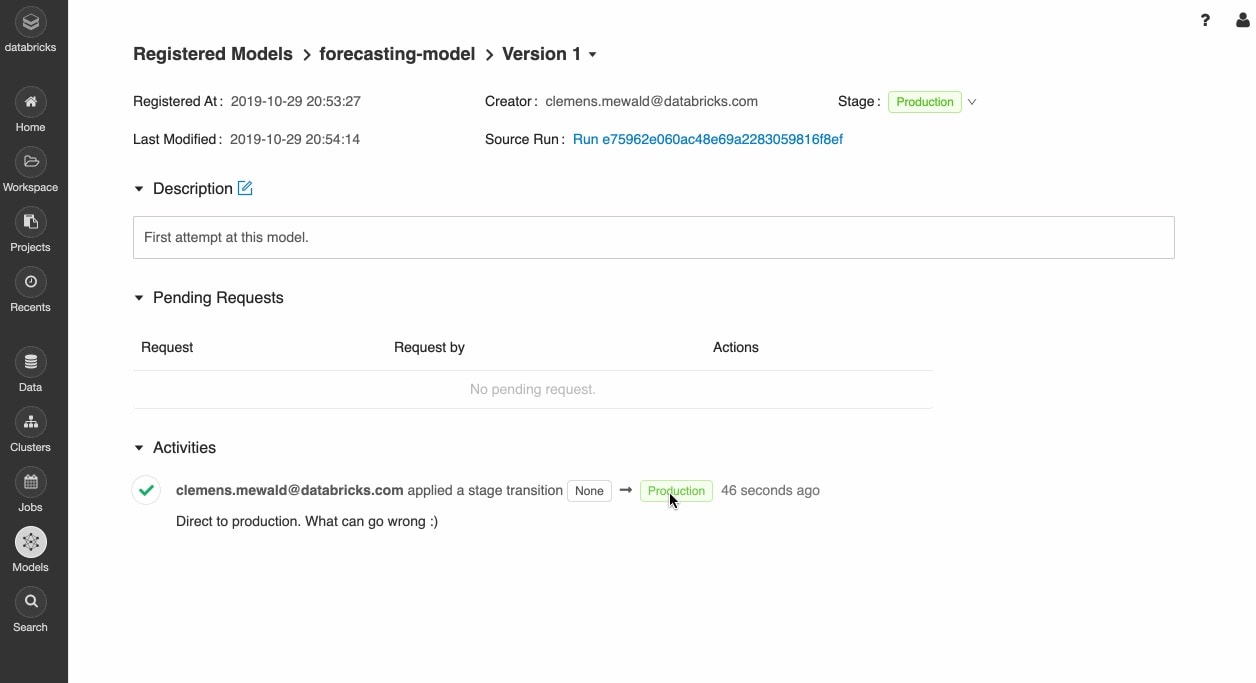
어디에나 모델 배포
Docker 컨테이너, Azure ML 또는 Amazon SageMaker와의 기본 통합을 사용하여 Apache Spark™ 또는 REST API로의 배치 추론을 위한 프로덕션 모델을 빠르게 배포합니다.
작업 스케줄러 및 자동 관리형 클러스터를 사용하여 프로덕션 모델을 운용하여 비즈니스 요구에 따라 확장할 수 있습니다.
Delta Lake 및 MLflow를 사용하여 최신 버전의 모델을 프로덕션에 신속하게 푸시하고 모델 드리프트를 모니터링합니다.
리소스
보고서

eBook

eBook

Ready to get started?