Feingranulare Zeitreihenvorhersage im großen Maßstab mit Facebook Prophet und Apache Spark
von Bilal Obeidat, Bryan Smith und Brenner Heintz
Probieren Sie dieses Notebook zur Zeitreihenprognose in unserem Solution Accelerator für Nachfrageprognosen aus.
Fortschritte bei der Zeitreihenprognose ermöglichen es Einzelhändlern, zuverlässigere Nachfrageprognosen zu erstellen. Die Herausforderung besteht nun darin, diese Prognosen rechtzeitig und mit einer Granularität zu erstellen, die es dem Unternehmen ermöglicht, präzise Anpassungen der Produktbestände vorzunehmen. Durch die Nutzung von Apache Spark™ und Facebook Prophet stellen immer mehr Unternehmen, die vor diesen Herausforderungen stehen, fest, dass sie die Skalierbarkeits- und Genauigkeitsgrenzen früherer Lösungen überwinden können.
In diesem Beitrag besprechen wir die Bedeutung der Zeitreihenprognose, visualisieren einige Beispiel-Zeitreihendaten und erstellen dann ein einfaches Modell, um die Verwendung von Facebook Prophet zu demonstrieren. Sobald Sie mit der Erstellung eines einzelnen Modells vertraut sind, kombinieren wir Prophet mit der Magie von Apache Spark™, um Ihnen zu zeigen, wie Sie Hunderte von Modellen gleichzeitig trainieren können, was uns ermöglicht, präzise Prognosen für jede einzelne Produkt-Store-Kombination auf einer bisher selten erreichten Granularitätsebene zu erstellen.
Genaue und zeitnahe Prognosen sind jetzt wichtiger denn je
Die Verbesserung der Geschwindigkeit und Genauigkeit von Zeitreihenanalysen zur besseren Vorhersage der Nachfrage nach Produkten und Dienstleistungen ist entscheidend für den Erfolg von Einzelhändlern. Wenn zu viel Produkt in ein Geschäft geliefert wird, können Regal- und Lagerflächen überlastet, Produkte verderben und Einzelhändler stellen fest, dass ihre finanziellen Mittel in Lagerbeständen gebunden sind, wodurch sie keine neuen Chancen nutzen können, die von Herstellern oder veränderten Verbrauchermustern geschaffen werden. Wenn zu wenig Produkt in ein Geschäft geliefert wird, können Kunden die benötigten Produkte möglicherweise nicht kaufen. Diese Prognosefehler führen nicht nur zu einem sofortigen Umsatzverlust für den Einzelhändler, sondern auf Dauer können Kundenfrustrationen die Kunden zu Wettbewerbern treiben.
Neue Erwartungen erfordern präzisere Zeitreihenprognosemethoden und -modelle
Seit einiger Zeit bieten Enterprise-Resource-Planning (ERP)-Systeme und Drittanbieterlösungen Einzelhändlern Funktionen zur Nachfrageprognose, die auf einfachen Zeitreihenmodellen basieren. Aber mit technologischen Fortschritten und erhöhtem Druck in der Branche suchen viele Einzelhändler nach Möglichkeiten, über die linearen Modelle und traditionelleren Algorithmen hinauszugehen, die ihnen historisch zur Verfügung standen.
Neue Funktionen, wie die von Facebook Prophet, entstehen aus der Data-Science-Community, und Unternehmen suchen nach der Flexibilität, diese Machine-Learning-Modelle für ihre Zeitreihenprognoseanforderungen anzuwenden.
![]()
Diese Abkehr von traditionellen Prognoselösungen erfordert von Einzelhändlern und ähnlichen Unternehmen, dass sie internes Fachwissen nicht nur in den Komplexitäten der Nachfrageprognose entwickeln, sondern auch in der effizienten Verteilung der Arbeit, die erforderlich ist, um Hunderttausende oder sogar Millionen von Machine-Learning-Modellen rechtzeitig zu erstellen. Glücklicherweise können wir Spark verwenden, um das Training dieser Modelle zu verteilen, was es ermöglicht, nicht nur die Gesamtnachfrage nach Produkten und Dienstleistungen vorherzusagen, sondern die einzigartige Nachfrage für jedes Produkt an jedem Standort.
Visualisierung der Nachfragesaisonalität in Zeitreihendaten
Um die Verwendung von Prophet zur Erstellung feingranularer Nachfrageprognosen für einzelne Geschäfte und Produkte zu demonstrieren, verwenden wir einen öffentlich verfügbaren Datensatz von Kaggle. Er besteht aus 5 Jahren täglicher Verkaufsdaten für 50 einzelne Artikel in 10 verschiedenen Geschäften.
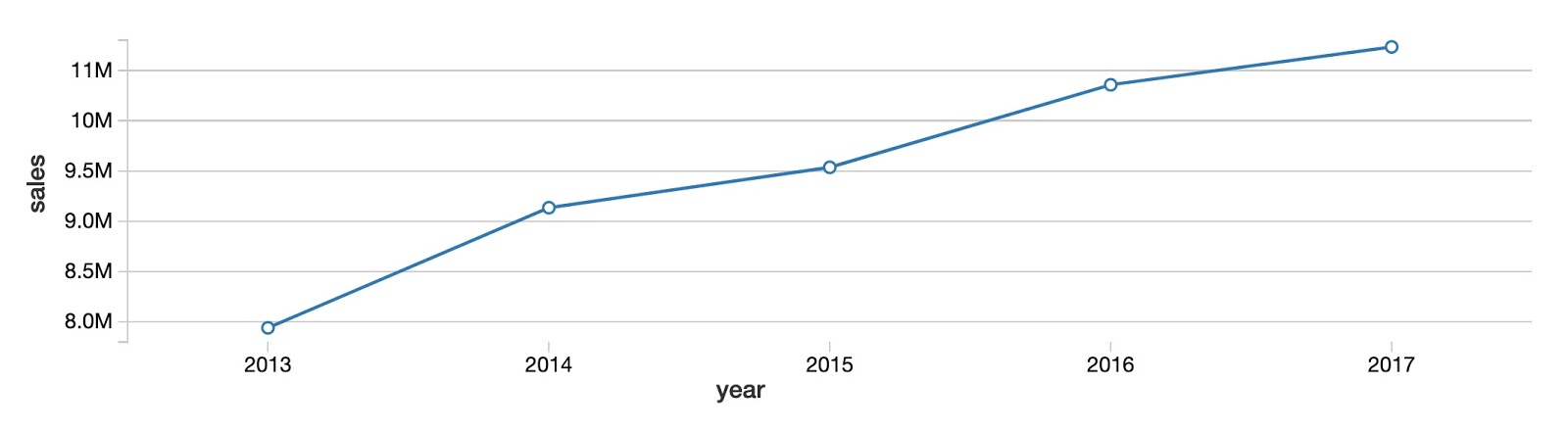
Um zu beginnen, betrachten wir den jährlichen Gesamtverkaufstrend für alle Produkte und Geschäfte. Wie Sie sehen können, steigen die Gesamtproduktverkäufe von Jahr zu Jahr ohne klares Anzeichen einer Annäherung an ein Plateau.
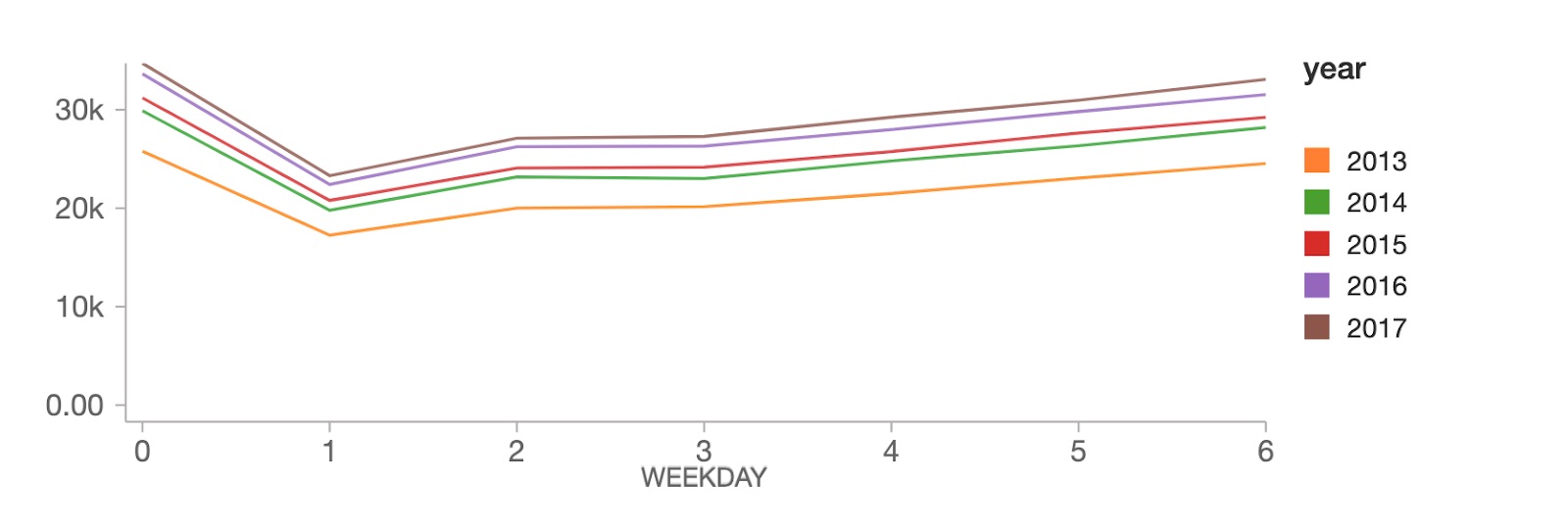
Auf Wochentagsebene erreichen die Verkäufe am Sonntag (Wochentag 0) ihren Höhepunkt, gefolgt von einem starken Rückgang am Montag (Wochentag 1), und erholen sich dann stetig im Rest der Woche.
Erste Schritte mit einem einfachen Zeitreihenprognosemodell auf Facebook Prophet
Wie in den obigen Diagrammen gezeigt, zeigen unsere Daten einen klaren jährlichen Aufwärtstrend bei den Verkäufen sowie sowohl jährliche als auch wöchentliche saisonale Muster. Es sind diese überlappenden Muster in den Daten, für die Prophet entwickelt wurde.
Facebook Prophet folgt der scikit-learn API, sodass es für jeden mit Erfahrung mit sklearn leicht zu erlernen sein sollte. Wir müssen einen pandas DataFrame mit 2 Spalten als Eingabe übergeben: Die erste Spalte ist das Datum und die zweite ist der Wert, der vorhergesagt werden soll (in unserem Fall Verkäufe). Sobald unsere Daten im richtigen Format vorliegen, ist die Erstellung eines Modells einfach:
Nachdem wir unser Modell an die Daten angepasst haben, verwenden wir es nun, um eine 90-tägige Prognose zu erstellen. Im folgenden Code definieren wir einen Datensatz, der sowohl historische Daten als auch 90 Tage darüber hinaus enthält, mithilfe der make_future_dataframe-Methode von Prophet:
Das ist alles! Wir können nun visualisieren, wie unsere tatsächlichen und vorhergesagten Daten übereinstimmen, sowie eine Prognose für die Zukunft mithilfe der integrierten .plot-Methode von Prophet. Wie Sie sehen können, spiegeln sich die wöchentlichen und saisonalen Nachfragemuster, die wir zuvor veranschaulicht haben, tatsächlich in den prognostizierten Ergebnissen wider.
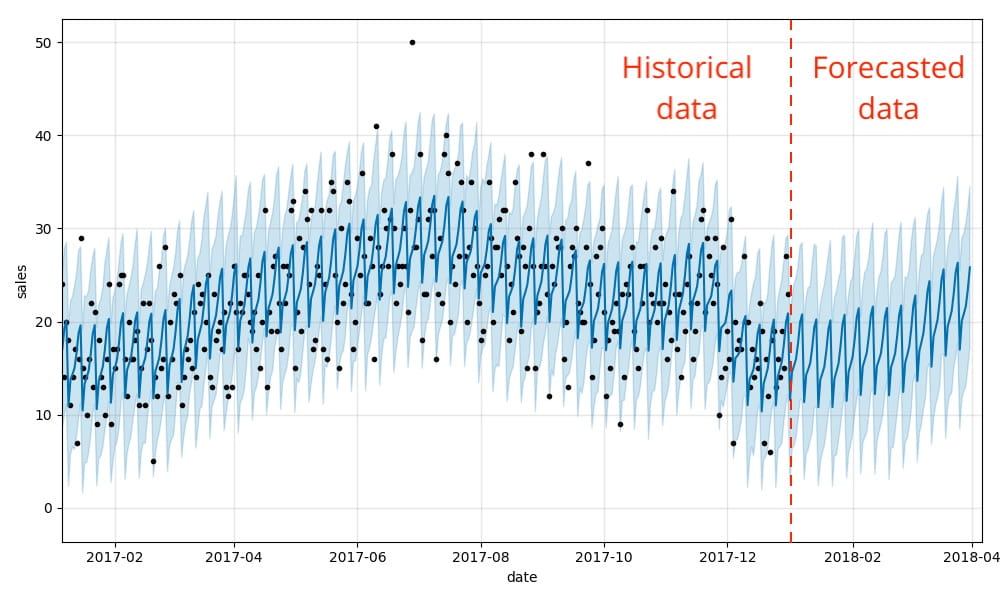
Diese Visualisierung ist etwas unübersichtlich. Bartosz Mikulski bietet eine ausgezeichnete Aufschlüsselung davon, die es wert ist, angesehen zu werden. Kurz gesagt, die schwarzen Punkte stellen unsere tatsächlichen Werte dar, die dunkelblaue Linie unsere Vorhersagen und das hellblaue Band unser (95%) Unsicherheitsintervall.
Hunderte von Zeitreihenprognosemodellen parallel mit Prophet und Spark trainieren
Nachdem wir gezeigt haben, wie man ein einzelnes Zeitreihenprognosemodell erstellt, können wir die Leistung von Apache Spark nutzen, um unsere Bemühungen zu vervielfachen. Unser Ziel ist es, nicht eine Prognose für den gesamten Datensatz zu erstellen, sondern Hunderte von Modellen und Prognosen für jede Produkt-Store-Kombination, was als sequentieller Vorgang unglaublich zeitaufwendig wäre.
Die Erstellung von Modellen auf diese Weise könnte es beispielsweise einer Lebensmittelhandelskette ermöglichen, eine präzise Prognose für die Milchmenge zu erstellen, die sie für ihr Geschäft in Sandusky bestellen sollte, die sich von der Menge unterscheidet, die für ihr Geschäft in Cleveland benötigt wird, basierend auf der unterschiedlichen Nachfrage an diesen Standorten.
Verwendung von Spark DataFrames zur Verteilung der Verarbeitung von Zeitreihendaten
Data scientists stehen häufig vor der Herausforderung, eine große Anzahl von Modellen mithilfe einer verteilten Datenverarbeitungs-Engine wie Apache Spark zu trainieren. Durch die Nutzung eines Spark-Clusters können einzelne Worker-Knoten im Cluster eine Teilmenge von Modellen parallel zu anderen Worker-Knoten trainieren, was die für das Training der gesamten Sammlung von Zeitreihenmodellen erforderliche Gesamtzeit erheblich verkürzt.
Das Training von Modellen auf einem Cluster von Worker-Knoten (Computern) erfordert natürlich mehr Cloud-Infrastruktur, und das hat seinen Preis. Aber durch die einfache Verfügbarkeit von On-Demand-Cloud-Ressourcen können Unternehmen die benötigten Ressourcen schnell bereitstellen, ihre Modelle trainieren und diese Ressourcen ebenso schnell wieder freigeben. So können sie massive Skalierbarkeit ohne langfristige Verpflichtungen gegenüber physischen Vermögenswerten erreichen.
Der Schlüsselmechanismus für die verteilte Datenverarbeitung in Spark ist das DataFrame. Durch das Laden der Daten in ein Spark DataFrame werden die Daten auf die Worker im Cluster verteilt. Dies ermöglicht es diesen Workern, Teilmengen der Daten parallel zu verarbeiten, wodurch die für unsere Arbeit erforderliche Gesamtzeit reduziert wird.
Natürlich muss jeder Worker Zugriff auf die Teilmenge der Daten haben, die er für seine Arbeit benötigt. Indem wir die Daten nach Schlüsselwerten gruppieren, in diesem Fall nach Kombinationen von Geschäft und Artikel, bringen wir alle Zeitreihendaten für diese Schlüsselwerte auf einen bestimmten Worker-Knoten.
Wir teilen den groupBy-Code hier mit, um zu unterstreichen, wie er uns ermöglicht, viele Modelle effizient parallel zu trainieren, obwohl er erst dann zum Einsatz kommt, wenn wir im nächsten Abschnitt eine UDF einrichten und auf unsere Daten anwenden.
Die Leistung von Pandas User-Defined Functions (UDFs) nutzen
Nachdem unsere Zeitreihendaten ordnungsgemäß nach Geschäft und Artikel gruppiert sind, müssen wir nun ein einzelnes Modell für jede Gruppe trainieren. Um dies zu erreichen, können wir eine Pandas User-Defined Function (UDF) verwenden, die es uns ermöglicht, eine benutzerdefinierte Funktion auf jede Datengruppe in unserem DataFrame anzuwenden.
Diese UDF trainiert nicht nur ein Modell für jede Gruppe, sondern generiert auch ein Ergebnis-Set, das die Vorhersagen dieses Modells darstellt. Aber während die Funktion jede Gruppe im DataFrame unabhängig von den anderen trainiert und Vorhersagen trifft, werden die von jeder Gruppe zurückgegebenen Ergebnisse bequem in einem einzigen Ergebnis-DataFrame gesammelt. Dies ermöglicht es uns, Vorhersagen auf Geschäfts-Artikel-Ebene zu generieren, aber unsere Ergebnisse Analysten und Managern als ein einziges Ausgabedatenset zu präsentieren.
Wie Sie im unten stehenden, gekürzten Python-Code sehen können, ist die Erstellung unserer UDF relativ einfach. Die UDF wird mit der Methode pandas_udf instanziiert, die das Schema der Daten identifiziert, die sie zurückgeben wird, und den Typ der Daten, die sie zu empfangen erwartet. Unmittelbar danach definieren wir die Funktion, die die Arbeit der UDF ausführt.
Innerhalb der Funktionsdefinition instanziieren wir unser Modell, konfigurieren es und passen es an die empfangenen Daten an. Das Modell trifft eine Vorhersage, und diese Daten werden als Ausgabe der Funktion zurückgegeben.
Um nun alles zusammenzuführen, verwenden wir den zuvor besprochenen groupBy-Befehl, um sicherzustellen, dass unser Datensatz ordnungsgemäß in Gruppen aufgeteilt wird, die bestimmte Geschäfts-Artikel-Kombinationen darstellen. Dann wenden wir einfach die UDF auf unser DataFrame an, wodurch die UDF ein Modell anpasst und Vorhersagen für jede Datengruppe trifft.
Das von der Anwendung der Funktion auf jede Gruppe zurückgegebene Dataset wird aktualisiert, um das Datum widerzuspiegeln, an dem wir unsere Vorhersagen generiert haben. Dies wird uns helfen, die Daten zu verfolgen, die während verschiedener Modellläufe generiert wurden, wenn wir unsere Funktionalität schließlich in die Produktion überführen.
Nächste Schritte
Wir haben nun ein Zeitreihen-Prognosemodell für jede Geschäfts-Artikel-Kombination erstellt. Mithilfe einer SQL-Abfrage können Analysten die maßgeschneiderten Prognosen für jedes Produkt einsehen. In der folgenden Abbildung haben wir die prognostizierte Nachfrage für Produkt Nr. 1 über 10 Geschäfte hinweg dargestellt. Wie Sie sehen können, variieren die Nachfrageprognosen von Geschäft zu Geschäft, aber das allgemeine Muster ist über alle Geschäfte hinweg konsistent, wie wir es erwarten würden.
Wenn neue Verkaufsdaten eintreffen, können wir effizient neue Prognosen generieren und diese an unsere bestehenden Tabellenstrukturen anhängen. So können Analysten die Erwartungen des Unternehmens im Zuge der sich entwickelnden Bedingungen aktualisieren.
Um mehr zu erfahren, sehen Sie sich das On-Demand-Webinar mit dem Titel How Starbucks Forecasts Demand at Scale with Facebook Prophet and Azure Databricks an und schauen Sie sich unseren Solution Accelerator for Demand Forecasting an.

(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.