Zu Databricks migrieren
Modernisieren Sie Ihre Datenplattform durch einen Umstieg auf die Databricks Data Intelligence Platform.

Risikoarme Migration zu einem schnellen und offenen Data Lakehouse
Herkömmliche Data Warehouses sind teuer. Und deswegen wird es Zeit für etwas Neues.Kosten reduzieren
Entscheiden Sie sich für Kosteneinsparungen und eine schnelle Amortisierung: Nutzen Sie ein elastisches, cloudnatives Serverless Data Lakehouse, das passend für Benutzer und Daten skaliert und ein erstklassiges Verhältnis von Preis und Performance bietet.
Schnelle und planbare Migration
Führen Sie Ihre Migration mithilfe von Tools, Vorlagen und Accelerators in einfachen Phasen durch. Lakebridge wird seit seiner Einführung 2025 von mehr als 1.000 Kunden und Partnern genutzt. Es verringert Risiken und Komplexität bei Migrationen und Modernisierungen und verbessert gleichzeitig die Datenqualität.
Für eine offene Zukunft gestalten
Unterstützen Sie eine Vielzahl von Geschäftsanwendern: Entscheiden Sie sich für eine Plattform, die nicht an bestimmte Anbieter gebunden und zudem KI-fähig ist. Ihre Geschäftsanwender haben neue Anforderungen? Darauf sind Sie vorbereitet. Oder benötigen Sie Governance für Ihren gesamten Datenbestand? Auch das ist kein Problem.

Tools und Accelerators von Databricks und unseren Partnern
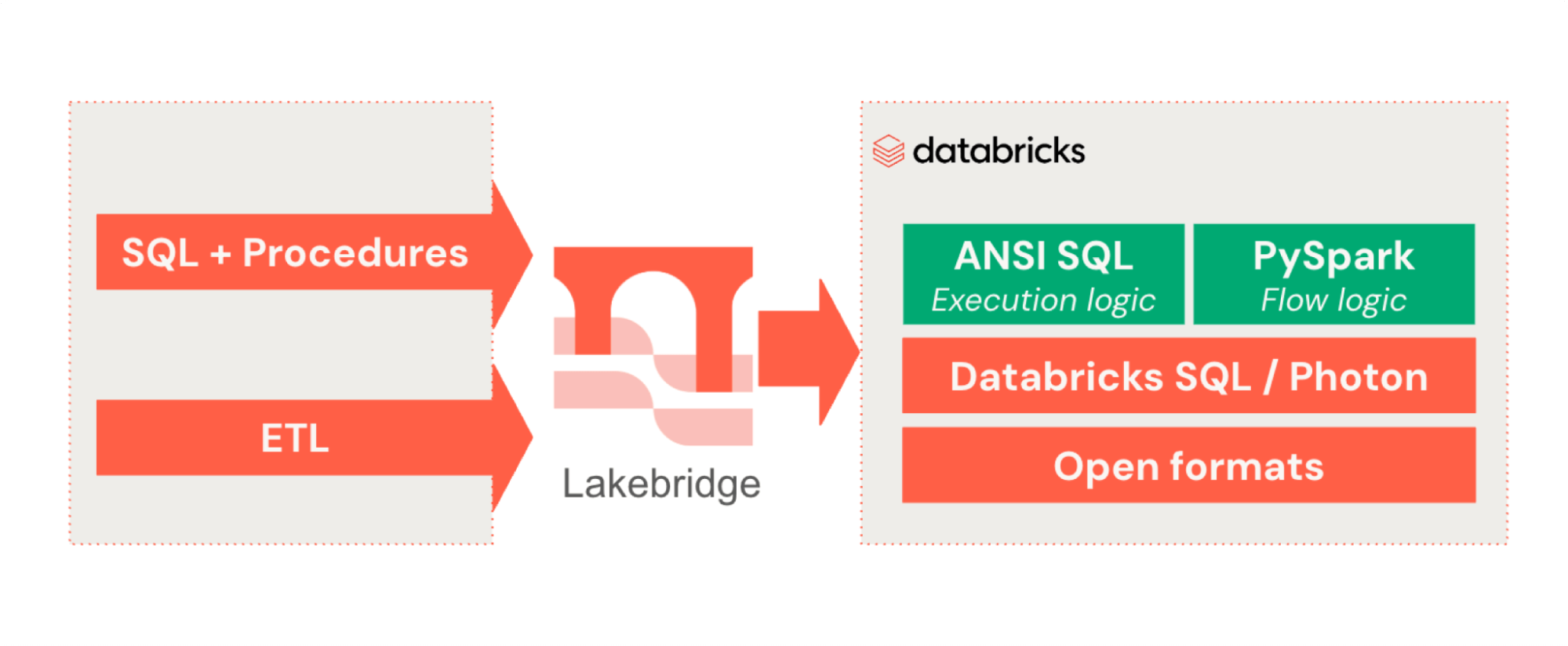
Schnelle, planbare Migrationen
Join mehr als 1.000 Kunden und Partnern und beschleunigen Sie mit Lakebridge die Migration zu Databricks – automatisieren Sie die Code-Konvertierung, validieren Sie Daten und wechseln Sie schnell und sicher von Legacy-Data-Warehouses.



Bewährte Strategien für Skalierbarkeit, Kosteneffizienz und AI-Innovation
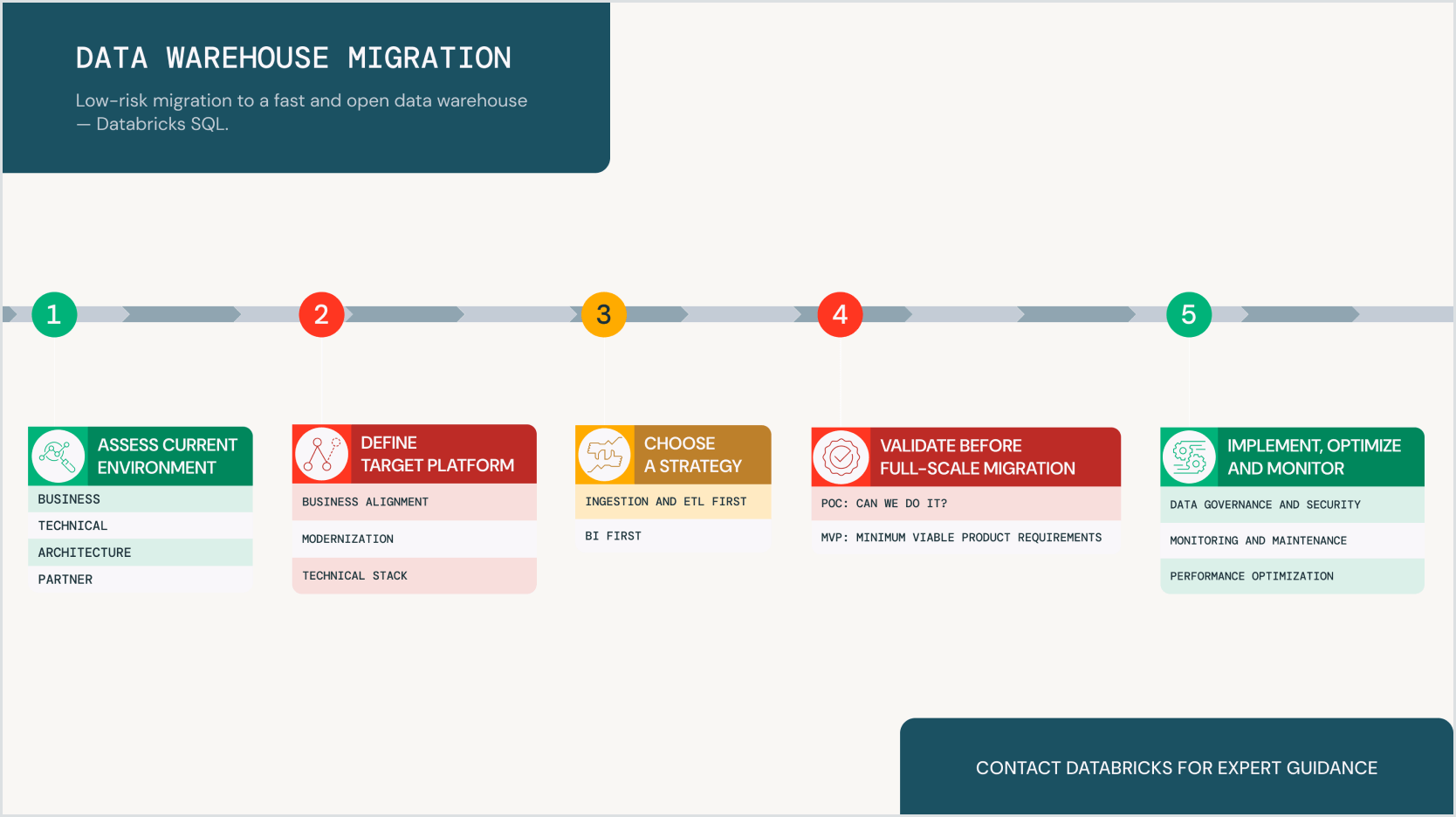
Die Migration zu einer modernen Plattform wie Databricks Lakehouse bietet Ihnen elastische Skalierbarkeit, reduzierte Kosten, integrierte Sicherheit und die Möglichkeit, Open-Source-Technologien nahtlos zu integrieren – ganz ohne Vendor-Lock-in. Befolgen Sie diese bewährte Migrationsstrategie und erfahren Sie:
- Warum die Modernisierung Ihres Data Warehouses entscheidend für Skalierbarkeit, Kosteneinsparungen und fortgeschrittene Analysen ist
- Welche strukturierte Migrationsstrategie Databricks für einen nahtlosen Übergang bietet
- Wie Sie Risiken dank Proof of Concepts (POCs), MVPs und Databricks-nativen Tools minimieren
Migration beschleunigen, um Daten und KI-gestützte Ergebnisse schneller liefern zu können

Gesamtbetriebskosten senken und Betriebseffizienz steigern
Der Aufbau von ETL-Pipelines oder die Implementierung von maschinellem Lernen auf Snowflake erfordert die Nutzung und den Betrieb zusätzlicher Tools. Mit der Zeit wird Ihre Architektur so immer kostspieliger und komplexer. Mit der Databricks-Plattform erhalten Sie leistungsstarkes, kostengünstiges ETL und native Unterstützung für KI.






Daten- und KI-Journey planen und umsetzen
Projekte schneller erfolgreich abschließen – dank erstklassigem Fachwissen in den Bereichen Data Engineering, Data Science und Projektmanagement.
Die Experten für die Databricks Data Intelligence Platform vom Databricks Professional Services Migration Team liefern Ihnen dank eines präskriptiven Ansatzes handfeste Ergebnisse. Die Vorgehensweise maximiert den Wert Ihrer bestehenden Daten- und Pipeline-Investitionen und stellt eine reibungslose Migration sicher. Das Migrationsteam gibt Ihnen zudem Best Practices an die Hand, damit Sie Risiken und Kosten senken können. Ob als Teil Ihres Teams oder in Zusammenarbeit mit Ihren SI-Partnern – die Databricks-Experten sorgen für eine erfolgreiche und reibungslose Umsetzung von Architektur, Planung, Design und Migration.
Bei Daten und KI aufs Tempo drücken
Unsere Angebote und Fachservices unterstützen Sie bei Ihrer Journey im Daten- und KI-Bereich und beschleunigen ihre Abläufe individuell und optimal – vom ersten Workspace-Onboarding bis zur Ausbildung von DataOps- und Center-of-Excellence-Praktiken im Unternehmensmaßstab.
Weniger Risiken für Ihr Projekt dank Migrationsabsicherung
Ganz gleich, ob Sie von älteren EDW-, Hadoop- oder Cloud-Data-Warehouse-Workloads zu Databricks migrieren: Das Databricks Professional Services Migration Team kann Ihnen als Partner und vertrauenswürdiger Berater zur Seite stehen, um Risiken zu minimieren und den Nutzen in jeder Phase Ihres Vorhabens zu maximieren. Wir können Ihnen oder Ihren SI-Partnern helfen – sei es durch umfassende Migrationsservices oder Leistungen zur Qualitätssicherung.
Operationalisierung in großem Umfang
Das Entwickeln eines Proof-of-Concept für eine Datenpipeline oder eines Einzelknotenmodells ist noch einigermaßen überschaubar. Schwieriger wird es, wenn es darum geht, Daten- und KI-Verfahren im gesamten Unternehmen erfolgreich einzuführen und zu skalieren. Mit unseren präskriptiven Angeboten und unserem Fachwissen möchten wir Sie bei der Bewältigung dieser anspruchsvollen Aufgabe unterstützen.
Kundenberichte
Lakebridge
Schnelle, planbare Data-Warehouse-Migrationen zu Databricks
Vereinfachen und beschleunigen Sie Data-Warehouse-Migrationen von mehr als 10 Legacy-Plattformen wie Oracle, Teradata, Snowflake, Amazon Redshift und Microsoft SQL Server zum Databricks Lakehouse. Sie können auch Legacy-ETL-Code zuverlässig konvertieren.
Die Nutzung von Lakebridge wächst jeden Monat um 20 % – und das aus gutem Grund. Schließen Sie sich unseren mehr als 1.000 Kunden und Partnern an, die für schnellere und besser planbare Migrationen darauf vertrauen.



