Partner Connect
Entdecken und integrieren Sie Daten, Analysen und KI-Lösungen ganz unkompliziert in Ihr Lakehouse
Partner Connect macht es Ihnen leicht, Daten-, Analyse- und KI-Tools direkt auf der Databricks-Plattform zu entdecken – und Lösungen, die Sie bereits nutzen, im Handumdrehen zu integrieren. Mit Partner Connect ist die Tool-Integration mit nur wenigen Klicks erledigt, und Sie haben die Funktionalität Ihres Lakehouse im Handumdrehen erweitert.
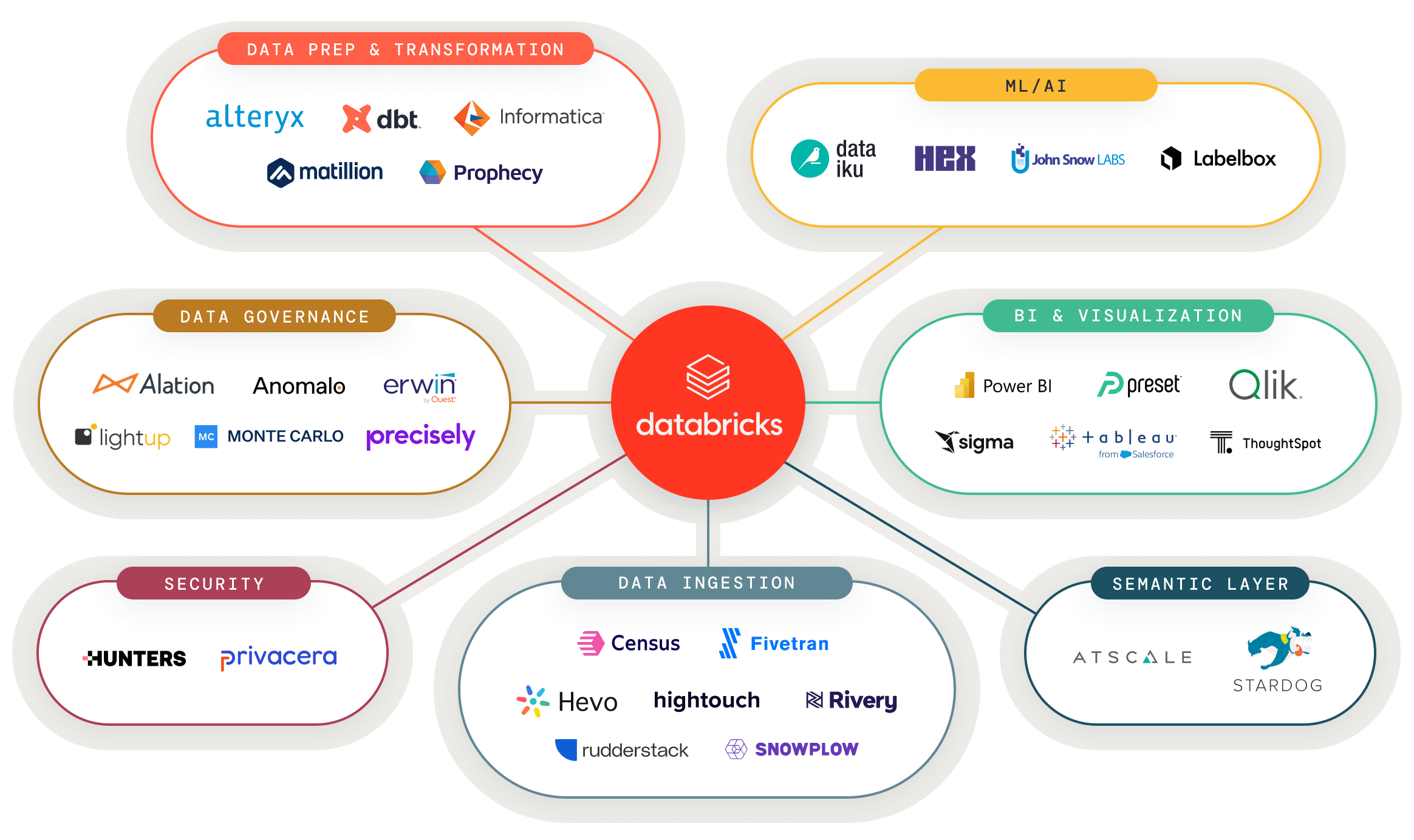
Daten- und KI-Tools mit dem Lakehouse vernetzen
Verbinden Sie Ihre bevorzugten Daten- und KI-Tools kinderleicht mit dem Lakehouse und nutzen Sie Analyseanwendungen aller Art

Entdecken Sie validierte Daten und KI-Lösungen für neue Anwendungsfälle
Ein zentraler Anlaufpunkt für geprüfte Partnerlösungen, damit Sie Ihre nächste Datenanwendung schneller erstellen können
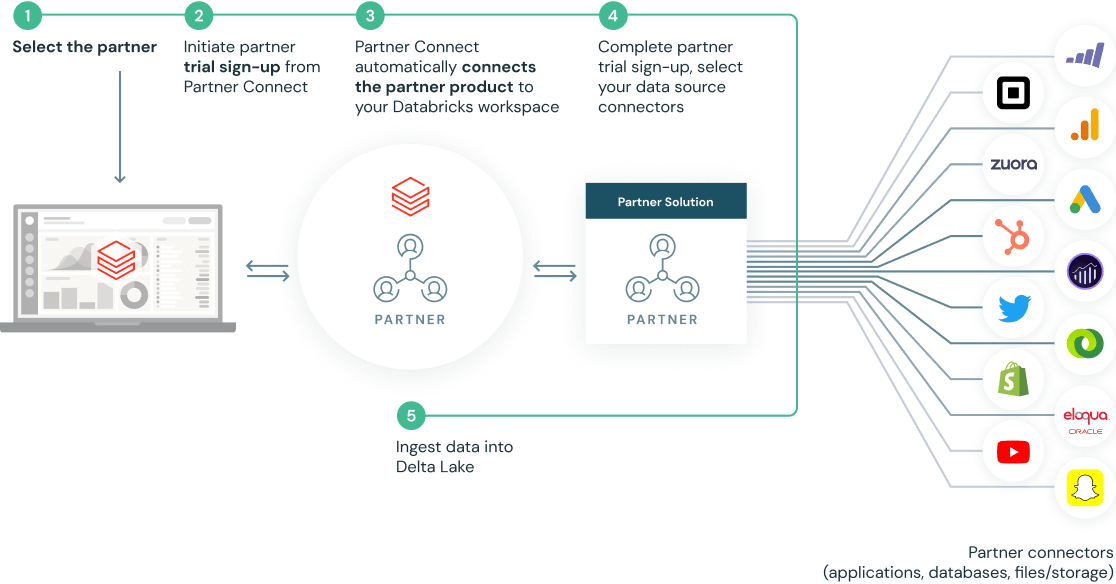
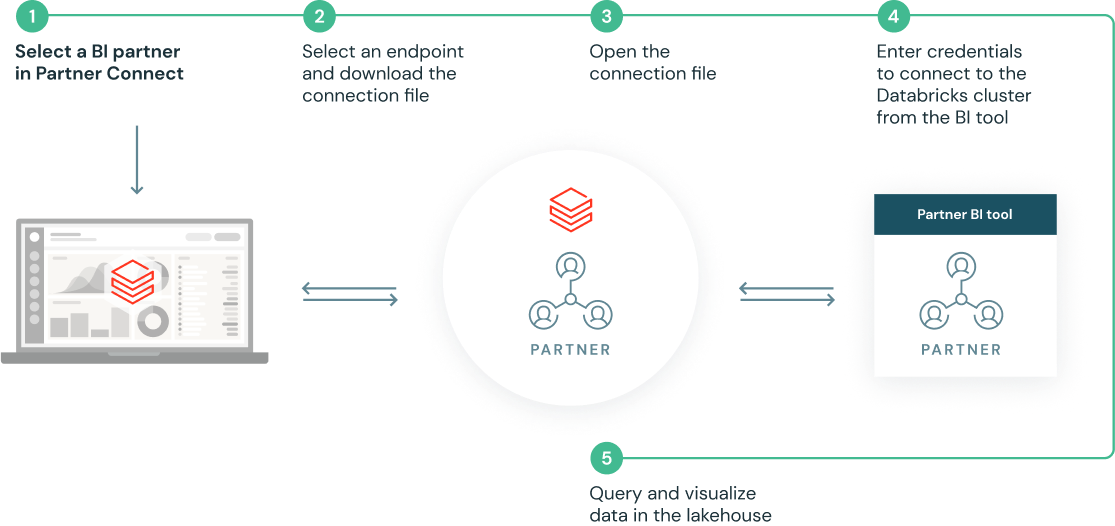
Mit ein paar Klicks eingerichtet dank vorgefertigter Integrationen
Partner Connect vereinfacht Ihre Integrationen durch die automatische Konfiguration von Ressourcen wie Clustern, Token und Verbindungsdateien für eine Verbindung mit Partnerlösungen
Ihr Einstieg als Partner
Databricks-Partner sind ideal positioniert, um Kunden schneller Analyseerkenntnisse zu liefern. Nutzen Sie die Entwicklungs- und Partnerressourcen von Databricks, um gemeinsam mit unserer offenen, Cloud-basierten Plattform zu wachsen.
Demos
Ressourcen
Blog
Dokumentation
Möchten Sie mehr wissen?
Nutzen Sie die Entwicklungs- und Partnerressourcen von Databricks, um gemeinsam mit unserer offenen cloudbasierten Plattform zu wachsen.