Implémentation d'un réseau neuronal convolutif pour la classification des voitures
par Dr Evan Eames et Henning Kropp
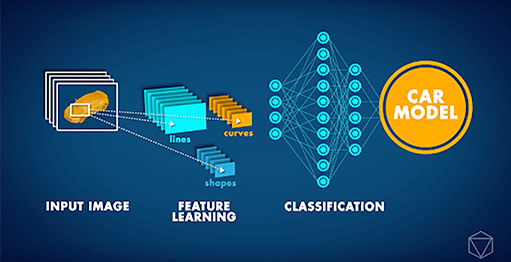
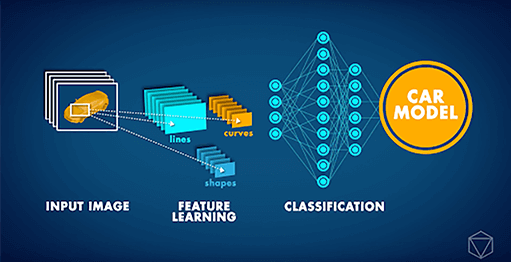
Les réseaux neuronaux convolutifs (ou CNN, pour Convolutional Neural Networks) sont des architectures de réseaux neuronaux particulièrement avancées utilisées principalement dans les tâches de vision par ordinateur. Les CNN peuvent être exploités pour diverses tâches, de la reconnaissance d'image à la détection de changement, en passant par la localisation d'objets. Récemment, notre partenaire Data Insights a reçu une demande ambitieuse de la part d'un grand constructeur automobile : développer une application de vision informatique capable d'identifier le modèle de voiture sur une image donnée. Étant donné que différents modèles de voitures peuvent paraître assez similaires et qu'une même voiture peut avoir l'air très différente en fonction de son environnement et de l'angle sous lequel elle est photographiée, une telle tâche était, jusqu'à très récemment, tout simplement impossible.

Cependant, à partir de 2012 environ, la ‘Révolution du Deep Learning’ a permis de traiter un tel problème. Au lieu qu'on leur explique le concept de voiture, les ordinateurs pourraient étudier des images à plusieurs reprises et apprendre ces concepts par eux-mêmes. Ces dernières années, de nouvelles innovations en matière de réseaux de neurones artificiels ont donné naissance à une IA capable d'effectuer des tâches de classification d'images avec une précision de niveau humain. En nous appuyant sur de tels développements, nous avons pu entraîner un CNN profond pour classifier les voitures par leur modèle. Le réseau de neurones a été entraîné sur le dataset Stanford Cars, qui contient plus de 16 000 images de voitures, comprenant 196 modèles différents. Au fil du temps, nous avons pu constater que la précision des prédictions a commencé à s'améliorer, à mesure que le réseau de neurones apprenait le concept d'une voiture et à distinguer les différents modèles.
{kind=link}
En collaboration avec notre partenaire, nous construisons un pipeline de machine learning de bout en bout en utilisant Apache Spark™ et Koalas pour le prétraitement des données, Keras avec Tensorflow pour l'entraînement du modèle, MLflow pour le suivi des modèles et des résultats, et Azure ML pour le déploiement d'un service REST. Cette configuration dans Azure Databricks est optimisée pour entraîner les réseaux rapidement et efficacement, et aide également à essayer beaucoup plus rapidement de nombreuses configurations de CNN différentes. Même après seulement quelques tentatives d'entraînement, la précision du CNN a atteint environ 85 %.
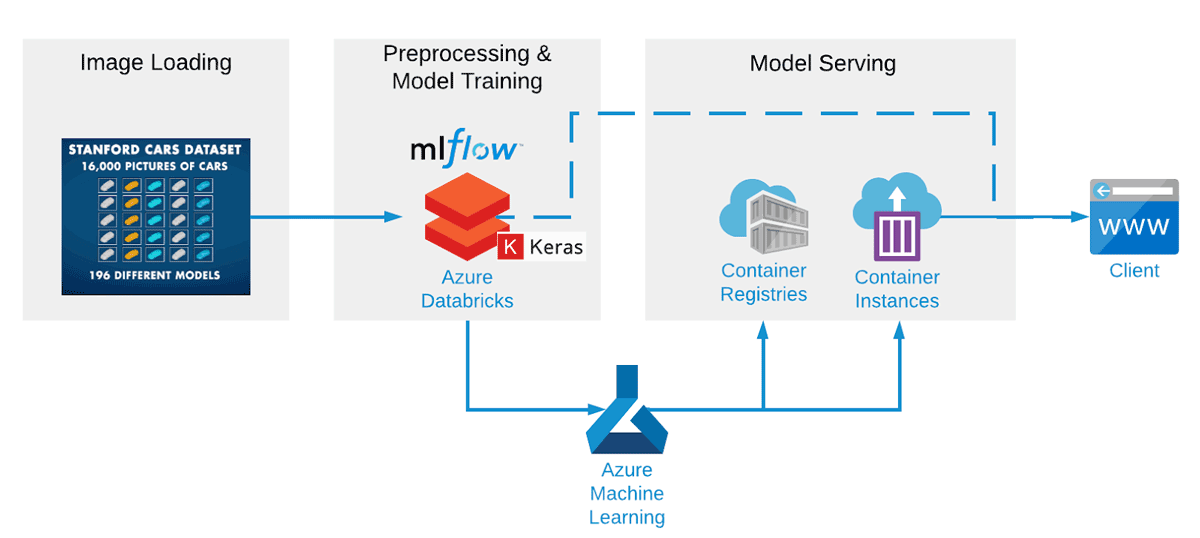
Mise en place d'un réseau de neurones artificiels pour classifier des images
Dans cet article, nous décrivons quelques-unes des principales techniques utilisées pour mettre un réseau de neurones en production. Si vous souhaitez essayer d'exécuter le réseau de neurones par vous-même, les Notebooks complets incluant un guide méticuleux étape par étape sont disponibles ci-dessous.
Cette démonstration utilise le dataset Stanford Cars, disponible publiquement, qui est l'un des datasets publics les plus complets. Bien qu'un peu daté, vous ne trouverez donc pas de modèles de voitures postérieurs à 2012 (toutefois, une fois l'entraînement effectué, l'apprentissage par transfert pourrait facilement permettre de lui substituer un nouveau dataset). Les données sont fournies par l'intermédiaire d'un compte de stockage ADLS Gen2 que vous pouvez monter sur votre workspace.

Pour la première étape du prétraitement des données, les images sont compressées en fichiers hdf5 (un pour l'entraînement et un pour le test). Ceci peut ensuite être lu par le réseau de neurones. Cette étape peut être entièrement omise, si vous le souhaitez, car les fichiers hdf5 font partie du stockage ADLS Gen2 fourni avec les Notebooks proposés ici.
- Charger le dataset Stanford Cars dans des fichiers HDF5
- Utilisez Koalas pour l'augmentation d'images
- Entraînez le CNN avec Keras
- Déployer le modèle en tant que service REST sur Azure ML
Augmentation d'images avec Koalas
La quantité et la diversité des données recueillies ont un impact important sur les résultats que l'on peut obtenir avec les modèles de deep learning. L'augmentation de données est une stratégie qui peut améliorer de manière significative les résultats d'apprentissage sans qu'il soit nécessaire de collecter de nouvelles données. Avec différentes techniques comme le recadrage, le remplissage et le retournement horizontal, qui sont couramment utilisées pour entraîner de grands réseaux de neurones, les ensembles de données peuvent être artificiellement gonflés en augmentant le nombre d'images pour l'entraînement et le test.
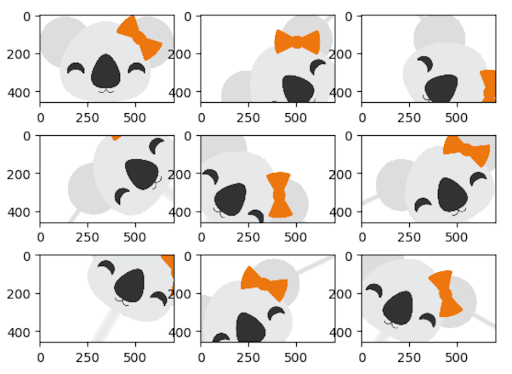
Appliquer l'augmentation de données à un grand corpus de données d'entraînement peut être très coûteux, en particulier lors de la comparaison des résultats de différentes approches. Avec Koalas, il est facile d'essayer les frameworks existants pour l'augmentation d'images en Python et de mettre le processus à l'échelle sur un cluster à nœuds multiples en utilisant l'API Pandas, bien connue dans le domaine de la Data Science.
Coder un ResNet dans Keras
Quand on décompose un CNN, il se compose de différents 'blocs', chaque bloc représentant simplement un groupe d'opérations à appliquer à des données d'entrée. Ces blocs peuvent être classés dans les grandes catégories suivantes :
- Bloc d'identité : une série d'opérations qui conserve la forme des données.
- Bloc de convolution : une série d'opérations qui réduisent la forme des données d'entrée à une forme plus petite.
Un CNN est une série de blocs d'identité et de blocs de convolution (ou ConvBlocks) qui réduisent une image d'entrée en un groupe compact de nombres. Chacun de ces nombres résultants (s'il est entraîné correctement) devrait à terme vous fournir une information utile pour classifier l'image. Un CNN résiduel ajoute une étape supplémentaire pour chaque bloc. Les données sont enregistrées en tant que variable temporaire avant que les opérations qui constituent le bloc ne soient appliquées, puis ces données temporaires sont ajoutées aux données de sortie. Généralement, cette étape supplémentaire est appliquée à chaque bloc. Par exemple, la figure ci-dessous illustre un CNN simplifié pour la détection de nombres manuscrits :
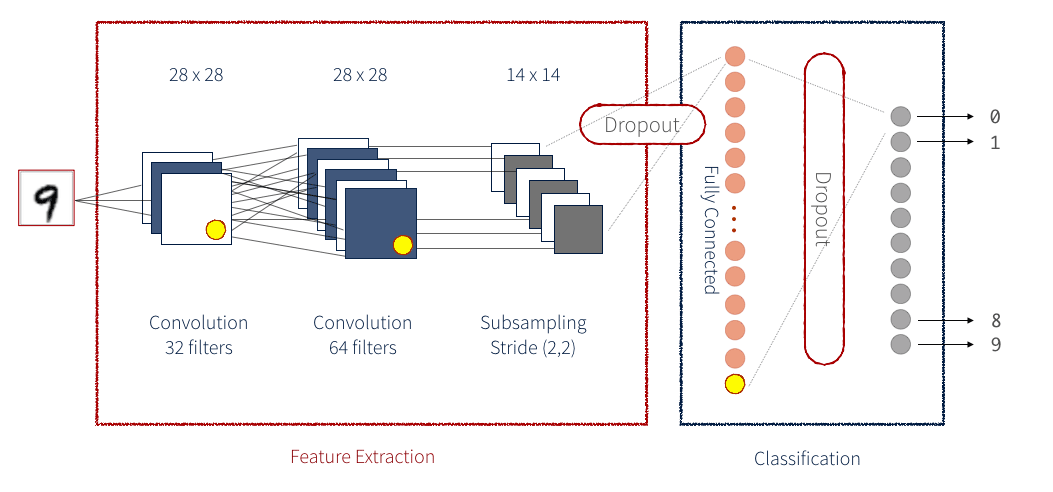
Il existe de nombreuses méthodes différentes pour implémenter un réseau de neurones. L'une des manières les plus intuitives est via Keras. Keras fournit une bibliothèque front-end simple pour exécuter les étapes individuelles qui composent un réseau de neurones. Keras peut être configuré pour fonctionner avec un back-end Tensorflow ou un back-end Theano. Ici, nous utiliserons un back-end Tensorflow. Un réseau Keras est décomposé en plusieurs couches, comme illustré ci-dessous. Pour notre réseau, nous définissons également notre implémentation client d'une couche.
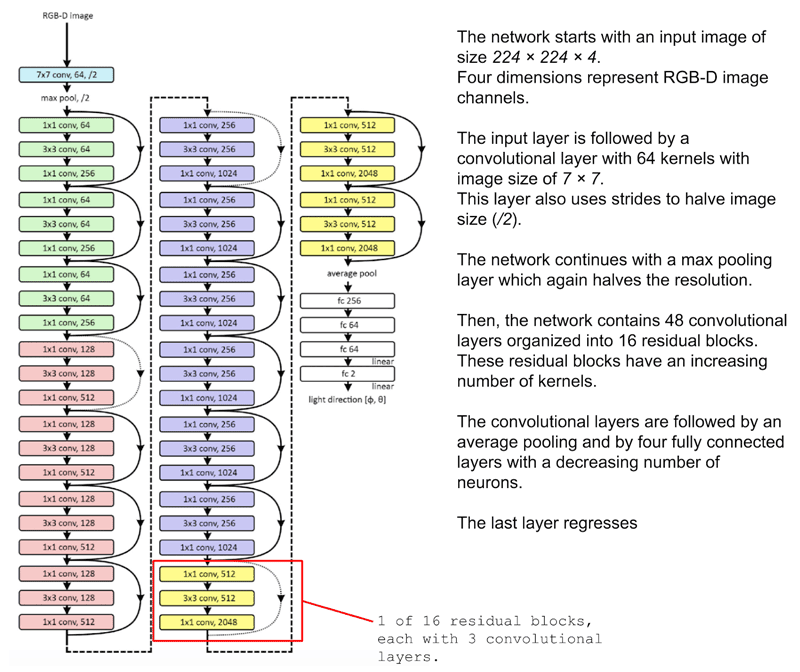
La couche de mise à l'échelle
Pour toute opération personnalisée qui a des poids entraînables, Keras vous permet d'implémenter votre propre couche. Lors du traitement d'énormes quantités de données d'images, des problèmes de mémoire peuvent survenir. Initialement, les images RVB contiennent des données entières (0-255). Lors de l'exécution de la descente de gradient dans le cadre de l'optimisation pendant la rétropropagation, on constatera que les gradients entiers ne permettent pas une précision suffisante pour ajuster correctement les poids du réseau. Par conséquent, il est nécessaire de passer à la précision en virgule flottante. C'est là que des problèmes peuvent survenir. Même lorsque les images sont réduites à 224x224x3, si nous utilisons dix mille images d'entraînement, cela représente plus d'un milliard d'entrées en virgule flottante. Au lieu de convertir un ensemble de données entier en précision à virgule flottante, il est préférable d'utiliser une 'couche de mise à l'échelle' (Scale Layer), qui met à l'échelle les données d'entrée une image à la fois, et uniquement lorsque cela est nécessaire. Cela doit être appliqué après la normalisation batch dans le modèle. Les paramètres de cette couche de Monter en charge (Scale Layer) sont également des paramètres qui peuvent être appris par l'entraînement.
Pour utiliser cette couche personnalisée également lors du scoring, nous devons packager la classe avec notre modèle. Avec MLflow, nous pouvons y parvenir à l'aide d'un dictionnaire Keras custom_objects qui mappe des noms (chaînes de caractères) à des classes ou fonctions personnalisées associées au modèle Keras. MLflow enregistre ces couches personnalisées à l'aide de CloudPickle et les restaure automatiquement lorsque le modèle est chargé avec mlflow.keras.load_model(). et mlflow.pyfunc.load_model().
Suivi des résultats avec MLflow et Azure Machine Learning
Le développement du machine learning implique des complexités supplémentaires par rapport au développement logiciel. La multitude d'outils et de frameworks rend difficile le suivi des expériences, la reproduction des résultats et le déploiement des modèles de machine learning. Avec Azure Machine Learning, il est possible d'accélérer et de gérer le cycle de vie du machine learning de bout en bout à l'aide de MLflow pour créer, partager et déployer des applications de machine learning de manière fiable avec Azure Databricks.
Afin de suivre automatiquement les résultats, un workspace Azure ML existant ou nouveau peut être lié à votre workspace Azure Databricks. De plus, MLflow prend en charge l'enregistrement automatique pour les modèles Keras (mlflow.keras.autolog()), rendant l'expérience presque sans effort.
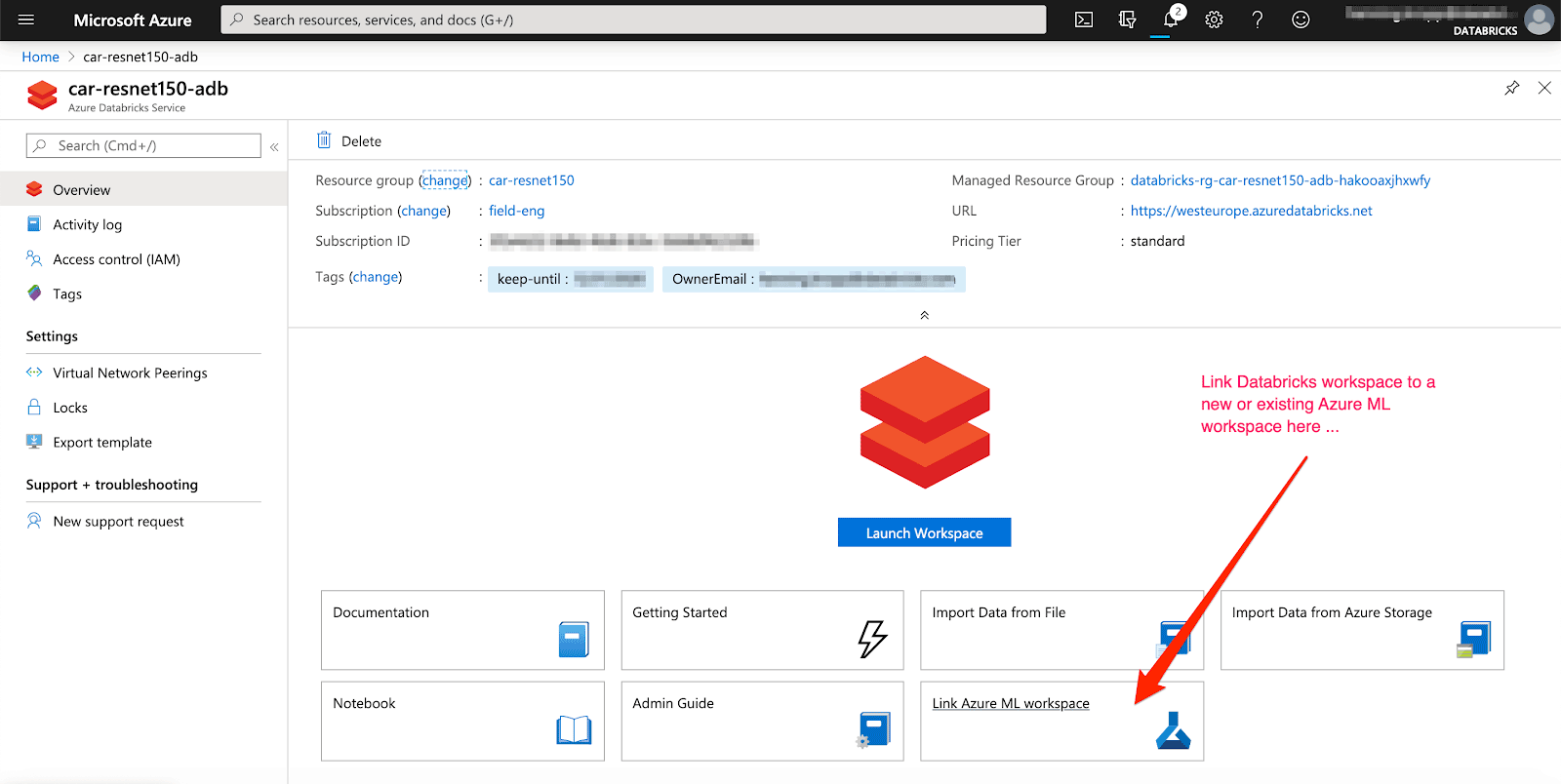
Bien que les utilitaires de persistance des modèles intégrés de MLflow soient pratiques pour l'empaquetage de modèles provenant de diverses bibliothèques de ML populaires telles que Keras, ils ne couvrent pas tous les cas d'utilisation. Par exemple, vous voudrez peut-être utiliser un modèle d'une bibliothèque ML qui n'est pas explicitement pris en charge par les saveurs intégrées de MLflow. Sinon, vous pouvez vouloir empaqueter du code d'inférence personnalisé et des données pour créer un modèle MLflow. Heureusement, MLflow fournit deux solutions qui peuvent être utilisées pour accomplir ces tâches : Modèles Python personnalisés et Saveurs personnalisées.
Dans ce scénario, nous voulons nous assurer que nous pouvons utiliser un moteur d'inférence de modèle qui prend en charge le traitement des requêtes d'un client d'API REST. Pour ce faire, nous utilisons un modèle personnalisé basé sur le modèle Keras précédemment construit pour accepter un objet Dataframe JSON contenant une image encodée en Base64.
À l'étape suivante, nous pouvons utiliser ce py_model et le déployer sur un serveur Azure Container Instances, ce qui peut être réalisé grâce à l'intégration Azure ML de MLflow.
Déployer un modèle de classification d'images dans Azure Container Instances
À ce stade, nous avons un Modèle de machine learning entraîné et en avons enregistré un dans notre workspace avec MLflow dans le cloud. Pour finir, nous aimerions déployer le modèle en tant que service web sur Azure Container Instances.
Un service web est une image, dans ce cas une image Docker. Il encapsule la logique de scoring et le modèle lui-même. Dans ce cas, nous utilisons notre représentation de modèle MLflow personnalisée qui nous donne le contrôle sur la façon dont la logique de scoring prend en charge les images d'un client REST et sur la façon dont la réponse est mise en forme.
Container Instances est une excellente solution pour tester et comprendre le workflow. Pour les déploiements en production évolutifs, envisagez d'utiliser Azure Kubernetes Service. Pour plus d'informations, consultez comment et où déployer.
Démarrer avec la classification d'images par CNN
Cet article et ces notebooks présentent les principales techniques utilisées pour mettre en place un workflow de bout en bout pour l'entraînement et le déploiement d'un réseau de neurones en production sur Azure. Les exercices du notebook associé vous guideront à travers les étapes requises pour créer cela dans votre propre environnement Azure Databricks à l'aide d'outils comme Keras, Databricks Koalas, MLflow et Azure ML.
Ressources pour développeurs
- Notebooks
- Vidéo : https://www.youtube.com/watch?v=mxEqcIbPqPs
- GitHub: https://github.com/EvanEames/Cars
- Diapositives : https://www.slideshare.net/jonbros/deep-learning-with-databricks
- PDF : https://github.com/EvanEames/Cars/blob/master/CNN_howto.pdf
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.