Personnaliser l'expérience client grâce aux recommandations

Accédez directement aux Notebooks de recommandation référencés tout au long de cet article.
Le commerce de détail a fait un bond de géant dans l'adoption du e-commerce en 2020. En pourcentage du total des ventes au détail, le e-commerce a connu une progression de plusieurs années en une seule année. Pendant ce temps, la COVID, les confinements et l'incertitude économique ont complètement bouleversé la façon dont nous interagissons avec les clients et les fidélisons. Les entreprises doivent repenser la personnalisation pour être compétitives en cette période de changement rapide.
En 2020, nous avons observé un changement rapide dans le comportement des consommateurs, et pas seulement dans l'adoption du e-commerce. Les marques de distributeur ont connu une adoption accrue de la part des consommateurs. La demande pour les produits de première nécessité a connu une résurgence. Les clients ont non seulement repensé leurs relations avec des produits spécifiques, mais aussi avec les détaillants, répartissant leurs dépenses entre plusieurs partenaires commerciaux. La pertinence des présentoirs en magasin, des articles phares et des promotions a été remise en question par les principaux détaillants capables de générer 35 % de leur chiffre d'affaires grâce à des recommandations personnalisées.
Offrir une expérience où les clients se sentent compris aide les détaillants à se démarquer de la masse des grands distributeurs et à fidéliser leur clientèle. C'était déjà le cas avant la COVID, mais l'évolution des préférences des consommateurs rend cela d'autant plus essentiel pour les entreprises du commerce de détail. Des études montrant que le coût d'acquisition de clients peut être jusqu'à cinq fois plus élevé que celui de la fidélisation, les organisations qui cherchent à réussir dans la nouvelle normalité doivent continuer à tisser des liens plus profonds avec leurs clients existants afin de conserver une base de consommateurs solide. Les consommateurs d'aujourd'hui ne manquent pas d'options et d'incitations pour repenser leurs habitudes de consommation bien ancrées.
La personnalisation est indispensable pour être compétitif
Face à un choix pléthorique, les consommateurs attendent des marques qu'ils achètent et des entreprises auprès desquelles ils effectuent leurs achats qu'elles offrent une expérience adaptée à leurs besoins et préférences. La personnalisation, autrefois présentée comme une vision exotique de ce qui pourrait être, devient de plus en plus l'attente de base des consommateurs constamment connectés, pressés par le temps et qui recherchent de la valeur à travers un ensemble de considérations de plus en plus complexes.
Les marques qui proposent des expériences personnalisées peuvent rivaliser avec ces géants de la distribution. Dans une analyse pré-COVID des attitudes et des habitudes de consommation, 80 % des participants ont indiqué qu'ils étaient plus susceptibles de faire affaire avec une entreprise proposant des expériences personnalisées. Il s'est avéré que ces personnes étaient 10 fois plus susceptibles d'effectuer 15 achats ou plus par an auprès d'organisations qui, selon elles, comprenaient et répondaient à leurs besoins et préférences personnels. Dans une autre enquête, 50 % des participants ont déclaré considérer les marques qu'ils achètent comme des extensions d'eux-mêmes, ce qui favorise une fidélité client plus profonde et plus durable pour les marques qui y parviennent.
Alors que la COVID a provoqué un changement d'orientation des consommateurs vers la valeur, la disponibilité, la qualité, la sécurité et la communauté, les marques les plus à l'écoute de l'évolution des besoins et des sentiments ont vu des clients abandonner leurs concurrents à leur profit. Alors que certains secteurs ont prospéré et que beaucoup d'autres ont périclité, les organisations qui avaient déjà entamé leur transition vers une meilleure expérience client ont obtenu de meilleurs résultats, reflétant fidèlement les tendances observées lors de la récession de 2007-2008 (Figure 1).
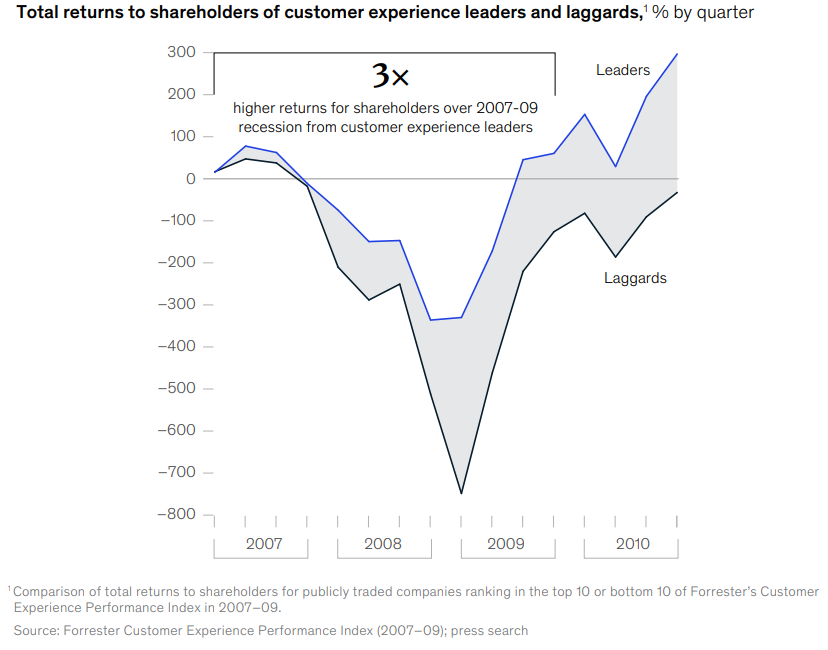
Figure 1. Les leaders de la CX surperforment les retardataires, même sur un marché en baisse, une visualisation de l'indice de performance de l'expérience client de Forrester fournie par McKinsey & Company (link
Alors que nous nous tournons vers ce qui sera la nouvelle normalité, il est clair que la personnalisation de l'expérience client restera un axe majeur pour de nombreuses organisations B2C et même des organisations B2B. De plus en plus, les analystes de marché reconnaissent l'expérience client comme une force de rupture permettant aux nouvelles organisations de renverser les acteurs établis de longue date. Les organisations qui se concentrent uniquement sur la concurrence par le produit, la distribution, les Tarifs et la promotion se trouveront sous la pression de concurrents capables d'offrir plus de valeur aux consommateurs pour chaque dollar reçu.
Concentrez-vous sur le parcours client
La personnalisation commence par une exploration minutieuse du parcours client. Cela commence lorsque les clients prennent conscience d'un besoin et cherchent à identifier un produit pour y répondre. Celui-ci s'oriente ensuite vers la sélection d'un Canal de distribution pour son achat et se conclut par la consommation, la mise au rebut et l'éventuel réachat. Le parcours est varié et pas simplement linéaire, mais à chaque étape, il existe une opportunité de créer de la valeur pour le client.
La numérisation de chaque étape offre au client de la flexibilité quant à la manière dont il va interagir et permet à l'organisation d'évaluer la santé de son modèle. Bien qu'elle fasse partie intégrante de l'expérience en ligne et mobile, la numérisation peut être étendue aux étapes en magasin, en transit et même à domicile du parcours client, en tenant dûment compte de la transparence, de la confidentialité et de la valeur ajoutée pour le client.

Ces données générées par les clients ainsi que les entrées tierces fournissent à l'organisation les informations dont elle a besoin pour affiner sa compréhension du client et de son parcours unique. Les motivations, les objectifs et les préférences individuels peuvent désormais être mieux compris et des expériences plus personnalisées peuvent être proposées au client.
L'examen du parcours client, sa numérisation et l'analyse des données qu'il génère permettent de créer une boucle de rétroaction grâce à laquelle l'expérience client s'améliore. Pour lancer cette boucle et la maintenir dans le temps, une vision claire pour être compétitif en matière d'expérience client doit être exprimée. Cette vision doit fédérer l'ensemble de l'organisation, et pas seulement le service marketing et ses équipes techniques, autour d'objectifs communs. Ces objectifs doivent ensuite être traduits en structures incitatives qui encouragent la collaboration interdépartementale et l'innovation. Le parcours d'une organisation visant à offrir des expériences client différenciatrices est fondamentalement un parcours pour devenir une organisation apprenante, qui met en pratique les insights, célèbre les leçons tirées de l'échec et monte rapidement en charge ses succès pour générer de la valeur pour le client.
Tirer parti des préférences des clients
La personnalisation est multiforme, mais à différents moments du parcours client, les organisations auront l'occasion de sélectionner du contenu, des produits et des promotions à présenter au client. À ces moments-là, nous pouvons prendre en considération les retours passés des clients pour sélectionner les bons articles à présenter. Les retours clients ne nous parviennent pas toujours sous la forme de notes de 1 à 5 étoiles ou d'avis écrits. Les retours peuvent s'exprimer par le biais d'interactions, de temps de consultation, de recherches de produits et d'événements d'achat. Un examen attentif de la manière dont les clients interagissent avec divers assets et de la façon dont ces interactions peuvent être interprétées comme des expressions de préférence peut révéler un large éventail de données avec lesquelles vous pouvez permettre la personnalisation.
Une fois les commentaires reçus, nous examinons quels articles présenter. Imaginons un client qui parcourt un assortiment de produits recommandés, clique sur l'un d'entre eux, explore des alternatives à cet article, l'ajoute à son panier, puis explore les articles fréquemment achetés avec ce dernier. À chaque étape de ce segment très limité du parcours client, le client interagit avec notre contenu avec des objectifs très différents en tête. Les préférences du client restent inchangées tout au long de ce parcours, mais son intention nous amène à utiliser cette information pour faire des choix très différents quant à ce que nous pourrions lui présenter.
Comprendre que c'est autant un art qu'une science
Les moteurs que nous utilisons pour proposer du contenu en fonction des préférences des clients sont appelés des systèmes de recommandation. Dire que leur construction relève autant de l'art que de la science serait un euphémisme. Avec certains moteurs de recommandation, nous nous concentrons principalement sur les préférences communes de clients similaires pour élargir la gamme de contenus que nous pourrions proposer aux clients. Avec d'autres, nous nous concentrons sur les propriétés du contenu lui-même (p. ex., les descriptions de produits) et nous nous appuyons sur les interactions spécifiques de l'utilisateur avec un contenu connexe pour quantifier la probabilité qu'un article intéresse le client. Chaque classe de moteur de recommandation s'articule autour d'un objectif général, mais au sein de chacune, il existe une myriade de décisions que l'entreprise doit prendre pour orienter ses recommandations vers des objectifs spécifiques.
La complexité de ces moteurs et la raison même de leur création sont telles que toute évaluation préalable de leur prétendue exactitude est sujette à caution. Bien que des méthodes d'évaluation hors ligne aient été proposées et devraient être employées pour s'assurer que les systèmes de recommandation que nous construisons ne déraillent pas, la réalité est que nous ne pouvons évaluer efficacement leur capacité à nous aider à atteindre un objectif particulier qu'en les déployant dans le cadre de projets pilotes limités et en évaluant la réaction des clients. Et dans ces évaluations, il est important de garder à l'esprit qu'il n'y a pas d'attente de perfection, seulement une amélioration progressive par rapport à la solution précédente.
Considérez les compromis entre les performances & l'exhaustivité
Le principal défi à surmonter dans la conception de tout système de recommandation est la scalabilité. Considérons un système de recommandation qui s'appuie sur les similarités entre utilisateurs. Un petit pool de 100 000 utilisateurs nécessite l'évaluation d'environ 5 000 000 000 de paires d'utilisateurs, et chacune de ces évaluations peut impliquer une comparaison des préférences pour chaque article que nous pourrions recommander. D'un point de vue purement technique, effectuer ce nombre de calculs ne pose pas de problème, mais le coût de cette opération effectuée régulièrement et dans les contraintes de temps imposées à ces systèmes rend une évaluation par force brute intenable.
C'est pour cette raison que la littérature technique sur le développement des systèmes de recommandation met fortement l'accent sur les techniques de similarité approximative. Ces techniques offrent des raccourcis qui nous permettent de cibler les utilisateurs ou les articles les plus susceptibles d'être similaires aux objets que nous comparons. Avec ces techniques, il existe un compromis entre les gains de performance et l'exhaustivité des recommandations. Ainsi, bien que ces techniques soient d'une nature assez technique, une conversation importante doit avoir lieu entre les architectes de solutions et les parties prenantes de l'entreprise sur le juste équilibre entre ces deux considérations.
Accélérez vos efforts avec des accélérateurs de solution.
Il va sans dire qu'une gestion rigoureuse des ressources peut grandement contribuer à maîtriser les coûts de développement, d'entraînement et de déploiement continus des systèmes de recommandation. Databricks est spécialement conçu pour le développement évolutif sur des infrastructures cloud qui permettent aux organisations de provisionner puis déprovisionner rapidement des ressources précisément pour cette raison.
Pour aider nos clients à comprendre comment ils peuvent utiliser Databricks pour développer divers systèmes de recommandation, nous avons mis à disposition une série de notebooks détaillés dans le cadre de notre programme Solution Accelerators. Chaque Notebook exploite un dataset réel pour montrer comment les données brutes peuvent être transformées en une ou plusieurs Solutions de recommandation.
L'objectif de ces Notebooks est éducatif. Personne ne doit considérer les techniques présentées ici comme la seule ou même la meilleure façon de résoudre un problème de recommandation spécifique. Néanmoins, en nous confrontant aux problèmes décrits ci-dessus, nous espérons que certaines parties du code présenté aideront nos clients à répondre à leurs propres besoins en matière de systèmes de recommandation.
Recommandeurs à filtrage collaboratif
- CF 01 : Préparation des données
- CF 02 : Identifier les utilisateurs similaires
- CF 03 : Création de recommandations basées sur l'utilisateur
- CF 04 : Créer des recommandations basées sur les articles
- CF 05 : Déployer des filtres collaboratifs
Des systèmes de recommandation basés sur le contenu
Vous pouvez également visionner notre webinar à la demande sur la personnalisation et les recommandations.
- CN 01 : Préparation des données
- CN 02a : Déterminer les similarités de titres
- CN 02b : Déterminer les similarités de description
- CN 02c : Déterminer les similitudes entre les catégories
- CN 03 : Construction de systèmes de recommandation basés sur les profils utilisateur
- CN 04 : Déploiement de systèmes de recommandation basés sur le contenu
Data Science et ML
December 18, 2020/10 min de leitura
Personnaliser l'expérience client grâce aux recommandations
Ne manquez jamais un article Databricks
Et ensuite ?

Data Science e ML
October 31, 2023/9 min de leitura
