L'API Pandas dans le prochain Apache Spark™ 3.2
par Hyukjin Kwon et Xinrong Meng
L'édition Free a remplacé l'édition Community, offrant des fonctionnalités améliorées sans frais. Commencez à utiliser l'édition Free dès aujourd'hui.
Nous sommes ravis d'annoncer que l'API pandas fera partie de la prochaine version d'Apache Spark™ 3.2. pandas est une bibliothèque puissante et flexible qui s'est rapidement développée pour devenir l'une des bibliothèques de référence en Data Science. Désormais, les utilisateurs de pandas pourront tirer parti de l'API pandas sur leurs clusters Spark existants.
Il y a quelques années, nous avons lancé Koalas, un projet open source qui implémente l'API DataFrame de pandas sur Spark, et qui a été largement adopté par les data scientists. Récemment, Koalas a été officiellement fusionné dans PySpark par SPIP : Support pandas API layer on PySpark dans le cadre du Project Zen (voir aussi Project Zen: Making Data Science Easier in PySpark du Data + AI Summit 2021).
Les utilisateurs de pandas pourront monter en charge leurs charges de travail en modifiant une seule ligne dans la prochaine version de Spark 3.2 :
Cet billet de blog résume la prise en charge de l'API pandas sur Spark 3.2 et met en évidence les fonctionnalités, les changements et la Feuille de route notables.
Scalabilité au-delà d'une seule machine
L'une des limites connues de pandas est qu'elle ne monte pas en charge linéairement avec votre volume de données en raison du traitement sur une seule machine. Par exemple, pandas échoue avec une erreur de mémoire insuffisante s'il tente de lire un dataset plus volumineux que la mémoire disponible sur une seule machine :
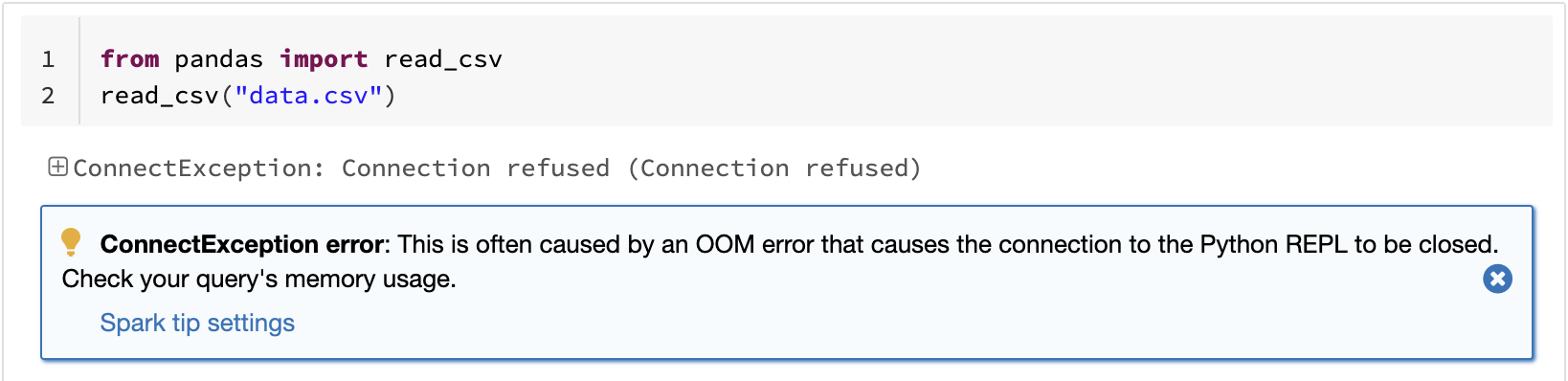
L'API pandas sur Spark surmonte cette limitation, permettant aux utilisateurs de travailler avec de grands datasets en tirant parti de Spark :

L'API pandas sur Spark s'adapte également bien aux grands clusters de nœuds. Le graphique ci-dessous montre ses performances lors de l'analyse d'un dataset Parquet de 15 To avec des clusters de différentes tailles. Chaque machine du cluster dispose de 8 vCPU et de 61 GiB de mémoire.
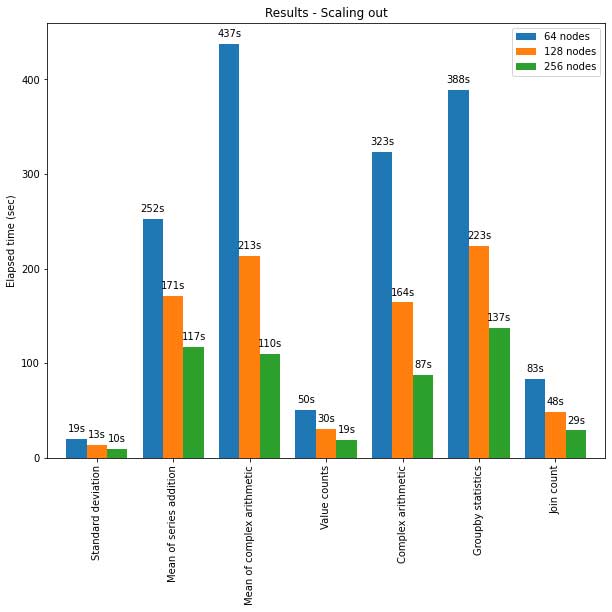
L'exécution distribuée de l'API pandas sur Spark monte en charge de manière presque linéaire dans ce test. Le temps écoulé diminue de moitié lorsque le nombre de machines au sein d'un cluster double. L'accélération par rapport à une seule machine est également significative. Par exemple, sur le benchmark de l'écart type, un cluster de 256 machines peut traiter ~250 fois plus de données qu'une seule machine en à peu près le même temps (chaque machine dispose de 8 vCPU et de 61 GiB de mémoire) :
| Machine unique | Cluster de 256 machines | |
| Jeu de données Parquet | 60 Go | 60 Go x 250 (15 To) |
| Temps écoulé (s) de l'écart type | 12s | 10 s |
Performance optimisée sur une seule machine
L'API pandas sur Spark est souvent plus performante que pandas, même sur une seule machine, grâce aux optimisations du moteur Spark. Le graphique ci-dessous compare l'API Pandas sur Spark à pandas sur une machine (avec 96 vCPU et 384 Gio de mémoire) sur un dataset CSV de 130 Go :
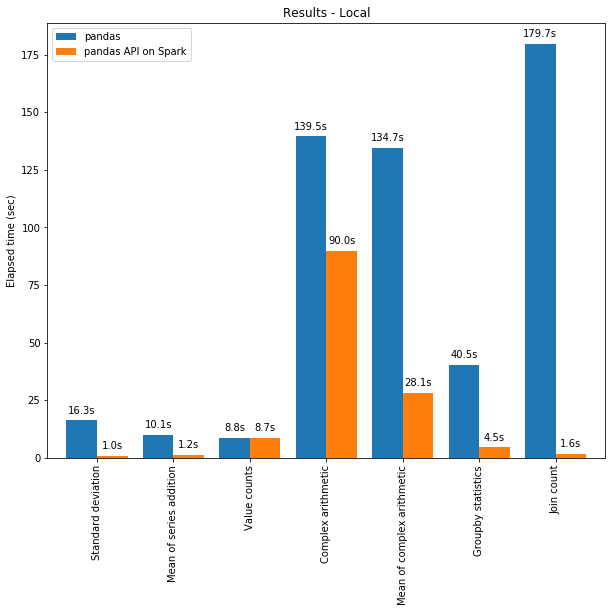
Le multithreading et l'Optimiseur Catalyst de Spark SQL contribuent à l'optimisation des performances. Par exemple, l'opération Join count est environ 4 fois plus rapide avec la génération de code whole-stage : 5,9 s sans génération de code, 1,6 s avec génération de code.
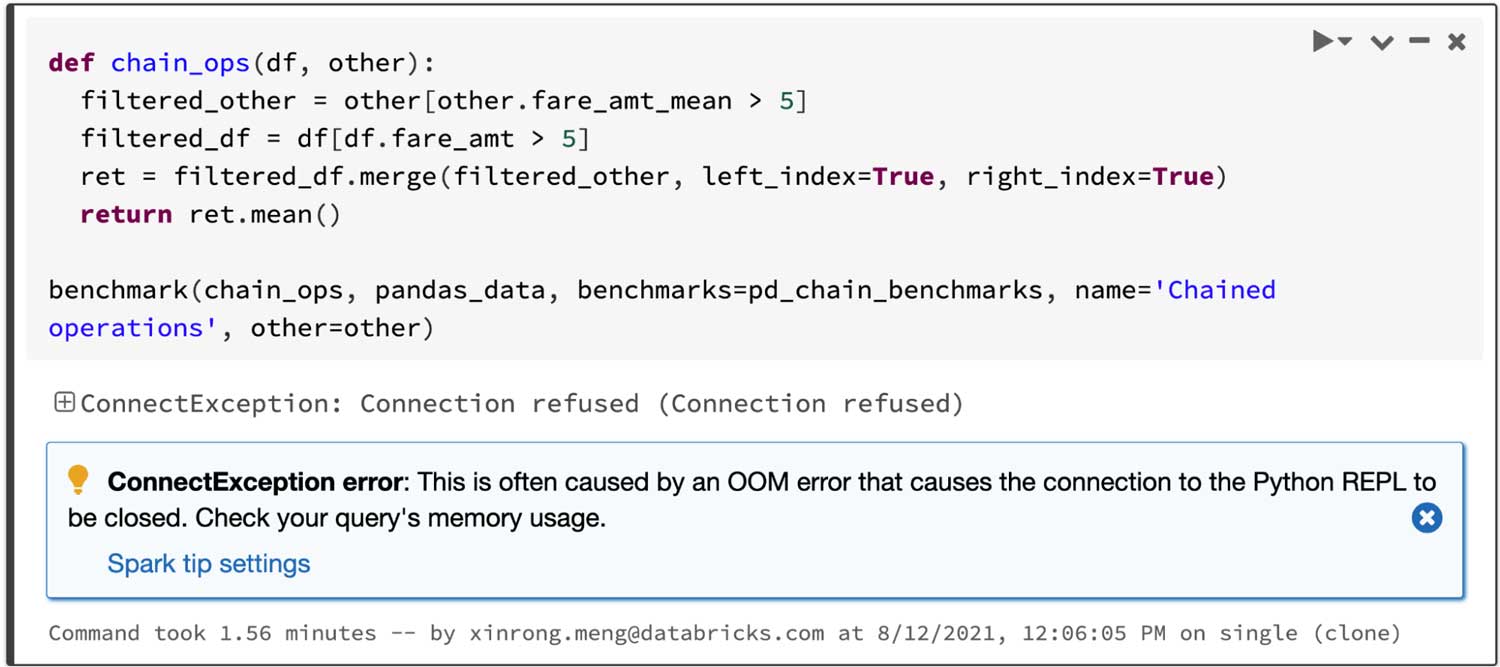
Spark présente un avantage particulièrement significatif dans le chaînage d'opérations. L'optimiseur de requêtes Catalyst peut reconnaître les filtres pour ignorer intelligemment des données et peut appliquer des jointures sur disque, tandis que pandas a tendance à charger toutes les données en mémoire à chaque étape.
Pour une query qui joint deux trames filtrées puis calcule la moyenne de la trame jointe, l'API pandas sur Spark réussit en 4,5 s, tandis que pandas échoue en raison de l'erreur OOM (Out of memory) comme ci-dessous :
Visualisation interactive des données
pandas utilise matplotlib par défaut, qui fournit des graphiques statiques. Par exemple, le code ci-dessous génère un graphique statique :
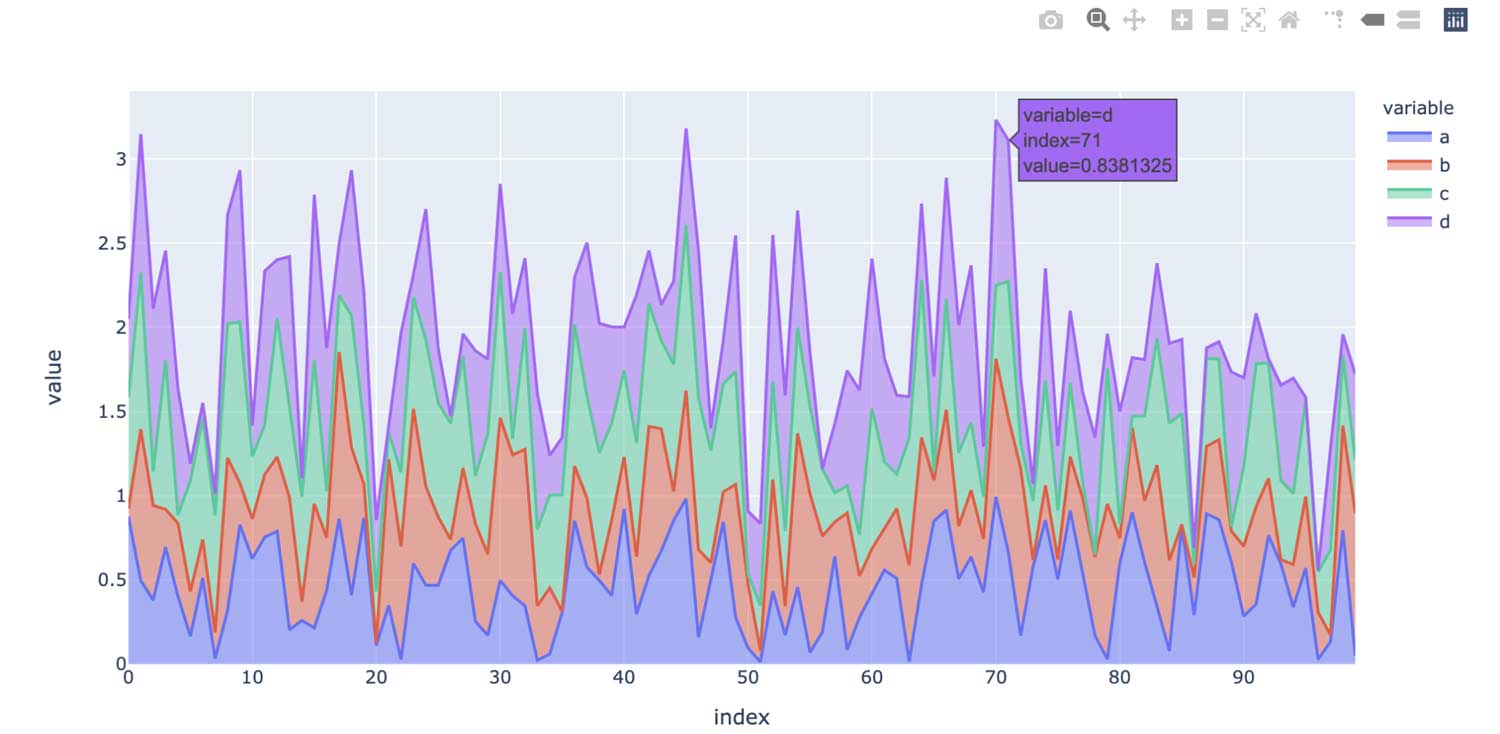
En revanche, l'API pandas sur Spark utilise par défaut un backend plotly, qui fournit des graphiques interactifs. Par exemple, il permet aux utilisateurs d'effectuer un zoom avant et arrière de manière interactive. En fonction du type de graphique, l'API pandas sur Spark détermine automatiquement la meilleure façon d'exécuter le calcul en interne lors de la génération de graphiques interactifs :
Exploiter la fonctionnalité unified analytics dans Spark
pandas est conçu pour la Data Science Python avec un traitement batch, tandis que Spark est conçu pour l'unified analytics, y compris le SQL, le streaming et le machine learning. Pour combler l'écart entre eux, l'API pandas sur Spark fournit de nombreuses façons différentes aux utilisateurs avancés de tirer parti du moteur Spark, par exemple :
- Les utilisateurs peuvent interroger directement les données via SQL avec le moteur SQL optimisé de Spark, comme illustré ci-dessous :
- Elle prend également en charge la syntaxe d'interpolation de chaîne pour interagir naturellement avec les objets Python :
- L'API pandas sur Spark prend également en charge le traitement en streaming :
- Les utilisateurs peuvent facilement appeler les bibliothèques de machine learning évolutives dans Spark :
Voir aussi le billet de blog sur l'interopérabilité entre PySpark et l'API pandas sur Spark.
Prochaines étapes
Pour les prochaines versions de Spark, la feuille de route se concentre sur :
• Plus d'indications de type
Le code de l'API pandas sur Spark est actuellement partiellement typé, ce qui permet toujours l'analyse statique et la saisie semi-automatique. À l'avenir, tout le code sera entièrement typé.
• Améliorations des performances
Il existe plusieurs endroits dans l'API pandas sur Spark où nous pouvons encore améliorer les performances en interagissant plus étroitement avec le moteur et l'optimiseur SQL.
• Stabilisation
Plusieurs points sont à corriger, notamment en ce qui concerne les valeurs manquantes telles que NaN et NA, qui présentent des différences de comportement dans les cas limites.
De plus, l'API pandas sur Spark suivra et adaptera son comportement à la dernière version de pandas dans ces cas.
• Plus grande couverture de l'API
L'API pandas sur Spark a atteint une couverture de 83 % de l'API pandas et ce chiffre ne cesse d'augmenter. L'objectif est maintenant d'atteindre 90 %.
Veuillez signaler un problème s'il y a des bogues ou si des fonctionnalités dont vous avez besoin sont manquantes et, bien sûr, nous apprécions toujours les contributions de la communauté.
Démarrer
Si vous souhaitez essayer l'API pandas sur Spark dans Databricks Runtime 10.0 Beta (prochain Apache Spark 3.2), inscrivez-vous gratuitement à Databricks Community Edition ou à l'essai Databricks et lancez-vous en quelques minutes.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.