La latence passe sous la seconde dans Apache Spark Structured Streaming
Amélioration de la gestion des décalages dans le projet Lightspeed

Apache Spark Structured Streaming est la principale plateforme open source de traitement de flux. C'est également la Technologie de base qui alimente le streaming sur la Databricks Lakehouse Platform et fournit une API unifiée pour le traitement par batch et stream. L'adoption du streaming connaissant une croissance rapide, diverses applications cherchent à en tirer parti pour la prise de décision en temps réel. Certaines de ces applications, en particulier celles de nature opérationnelle, exigent une latence plus faible. Bien que la conception de Spark permette un throughput élevé et une grande facilité d'utilisation à un coût inférieur, elle n'a pas été optimisée pour une latence inférieure à la seconde.
Dans cet article de blog, nous nous concentrerons sur les améliorations que nous avons apportées à la gestion des offsets pour réduire la latence de traitement inhérente de Structured Streaming. Ces améliorations ciblent principalement les cas d'utilisation opérationnels simples et sans état, tels que la surveillance et les alertes en temps réel.
Une évaluation approfondie de ces améliorations indique que la latence s'est améliorée de 68 à 75 % (soit jusqu'à 3 fois), passant de 700-900 ms à 150-250 ms pour des débits de 100K événements/s, 500K événements/s et 1M d'événements/s. Structured Streaming peut désormais atteindre des latences inférieures à 250 ms, satisfaisant ainsi les exigences de SLA pour un grand pourcentage des charges de travail opérationnelles.
Cet article suppose que le lecteur possède une connaissance de base de Spark Structured Streaming. Consultez la documentation suivante pour en savoir plus :
https://www.databricks.com/spark/getting-started-with-apache-spark/streaming
https://docs.databricks.com/structured-streaming/index.html
https://www.databricks.com/glossary/what-is-structured-streaming
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Motivation
Apache Spark Structured Streaming est un moteur de traitement de flux distribué basé sur le moteur Apache Spark SQL. Il fournit une API qui permet aux développeurs de traiter les flux de données en écrivant des requêtes de streaming de la même manière que des requêtes batch, ce qui facilite la compréhension et le test des applications de streaming. D'après les téléchargements Maven, Structured Streaming est aujourd'hui le moteur de streaming distribué open source le plus utilisé. L'une des principales raisons de sa popularité est la performance : un throughput élevé à un coût inférieur avec une latence de bout en bout inférieure à quelques secondes. Structured Streaming offre aux utilisateurs la flexibilité d'équilibrer le compromis entre le throughput, le coût et la latence.
Alors que l'adoption du streaming se développe rapidement en entreprise, il existe un désir de permettre à un ensemble diversifié d'applications d'utiliser une architecture de données en streaming. Lors de nos conversations avec de nombreux clients, nous avons rencontré des cas d'utilisation qui nécessitent une latence constante inférieure à la seconde. De tels cas d'utilisation à faible latence proviennent d'applications telles que les alertes opérationnelles et le monitoring en temps réel, également connues sous le nom de "charges de travail opérationnelles". Afin d'intégrer ces charges de travail dans Structured Streaming, nous avons lancé en 2022 une initiative d'amélioration des performances dans le cadre du Projet Lightspeed. Cette initiative a identifié des domaines et des techniques potentiels qui peuvent être utilisés pour améliorer la latence de traitement. Dans ce blog, nous détaillons l'un de ces domaines d'amélioration : la gestion des offsets pour le suivi de la progression et la manière dont elle permet d'atteindre une latence inférieure à la seconde pour les charges de travail opérationnelles.
Que sont les charges de travail opérationnelles ?
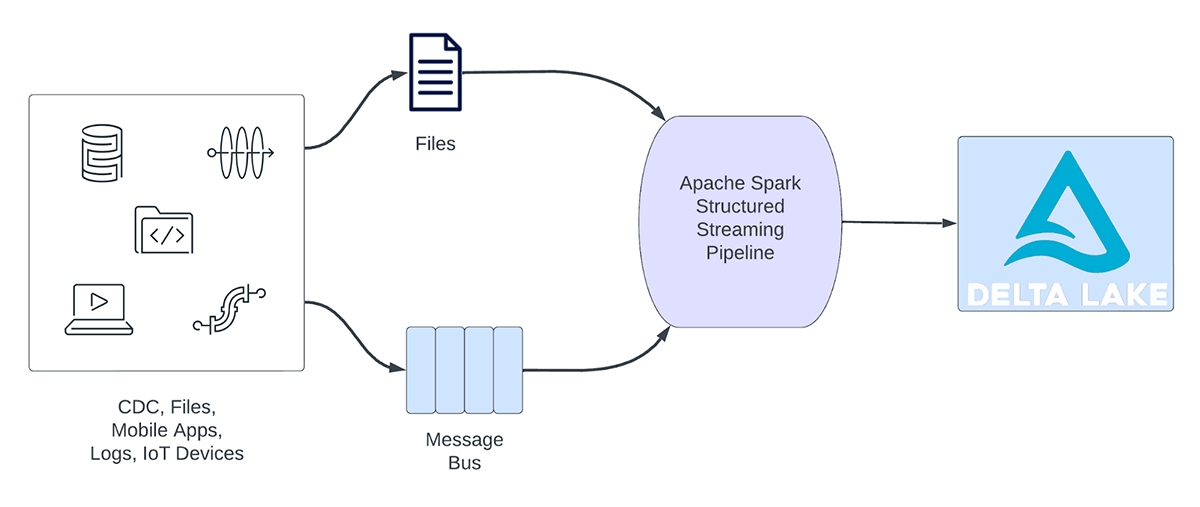
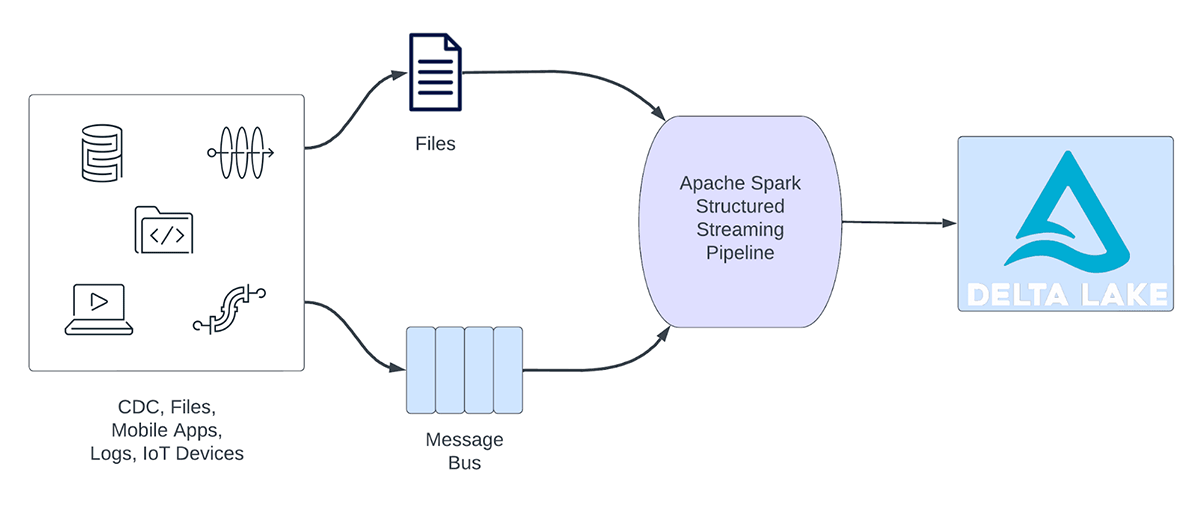
Les charges de travail de streaming peuvent être globalement classées en charges de travail analytiques et en charges de travail opérationnelles. La Figure 1 illustre les charges de travail analytiques et opérationnelles. Les charges de travail analytiques ingèrent, transforment, traitent et analysent généralement les données en temps réel et écrivent les résultats dans Delta Lake, qui s'appuie sur un stockage d'objets comme AWS S3, Azure Data Lake Gen2 et Google Cloud Storage. Ces résultats sont utilisés par des moteurs d'entreposage des données et des outils de visualisation en aval.
{kind=link}
{kind=link}
Figure 1. Charges de travail analytiques vs opérationnelles
Voici quelques exemples de charges de travail analytiques :
- analyse du comportement des clients: une société de Marketing peut utiliser l'analytique en streaming pour analyser le comportement des clients en temps réel. En traitant les données de parcours de navigation, les flux de réseaux sociaux et d'autres sources d'informations, le système peut détecter des modèles et des préférences qui peuvent être utilisés pour cibler plus efficacement les clients.
- Analyse des sentiments: une entreprise peut utiliser les données en streaming de ses comptes de réseaux sociaux pour analyser le sentiment des clients en temps réel. Par exemple, l'entreprise pourrait rechercher des clients qui expriment un sentiment positif ou négatif à l'égard de ses produits ou services.
- IoT Analytique: une ville intelligente peut utiliser l'analytique en streaming pour surveiller le flux du trafic, la qualité de l'air et d'autres mesures en temps réel. En traitant les données provenant de capteurs intégrés dans toute la ville, le système peut détecter des tendances et prendre des décisions concernant les schémas de circulation ou les politiques environnementales.
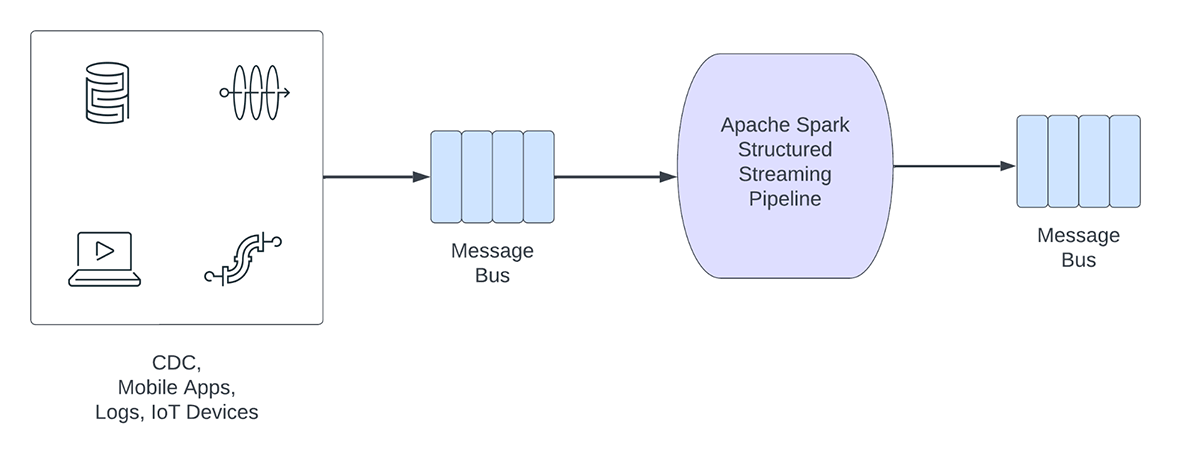
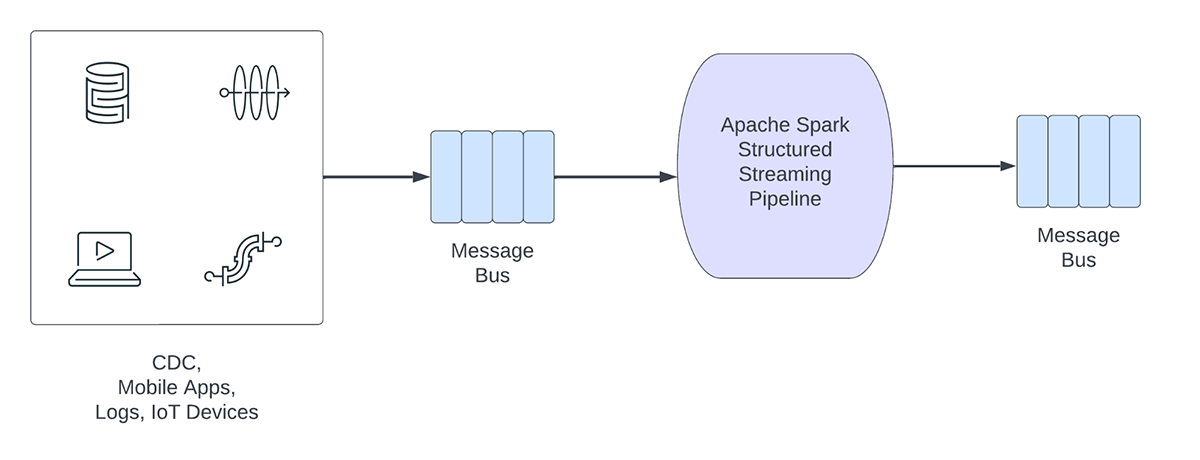
D'autre part, les charges de travail opérationnelles ingèrent et traitent les données en temps réel et déclenchent automatiquement un processus métier. Voici quelques exemples de ce type de charges de travail :
- Cybersécurité: une entreprise peut utiliser les données en streaming de son réseau pour surveiller les problèmes de sécurité ou de performances. Par exemple, l'entreprise peut rechercher des pics de trafic ou des accès non autorisés aux réseaux et envoyer une alerte au service de sécurité.
- Fuites d'informations personnelles identifiables: Une entreprise peut surveiller les logs de microservice, analyser et détecter si des informations personnelles identifiables (IPI) sont divulguées et, si c'est le cas, en informer par e-mail le propriétaire du microservice.
- Répartition des ascenseurs: une entreprise peut utiliser les données de streaming de l'ascenseur pour détecter quand le bouton d'alarme d'un ascenseur est activé. S'il est activé, il pourrait rechercher des informations supplémentaires sur l'ascenseur pour améliorer les données et envoyer une notification au personnel de sécurité.
- Maintenance proactive: à l'aide des données de streaming d'un générateur électrique, surveillez la température et, lorsqu'elle dépasse un certain threshold, informez le superviseur.
Les pipelines de streaming opérationnels partagent les caractéristiques suivantes :
- Les attentes en matière de latence sont généralement inférieures à la seconde
- Les pipelines lisent à partir d'un bus de messages
- Les pipelines effectuent généralement des calculs simples avec une transformation ou un enrichissement des données
- Les pipelines écrivent sur un bus de messages tel qu'Apache Kafka ou Apache Pulsar, ou sur des magasins clé-valeur rapides tels qu'Apache Cassandra ou Redis pour une intégration en aval avec les processus métier
Pour ces cas d'utilisation, lorsque nous avons profilé Structured Streaming, nous avons identifié que la gestion des offsets pour suivre la progression des micro-lots consomme un temps considérable. Dans la section suivante, nous examinerons la gestion des offsets existante et décrirons comment nous l'avons améliorée dans les sections suivantes.
Qu'est-ce que la gestion des offsets ?
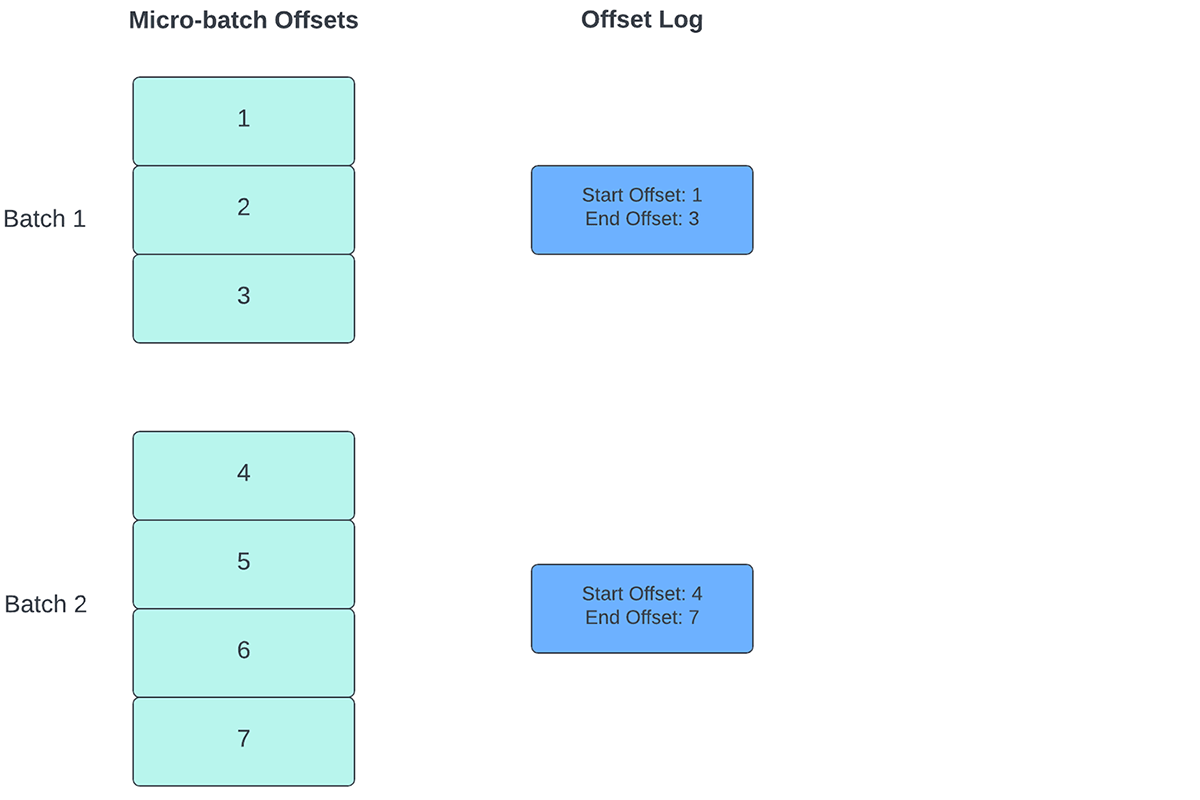
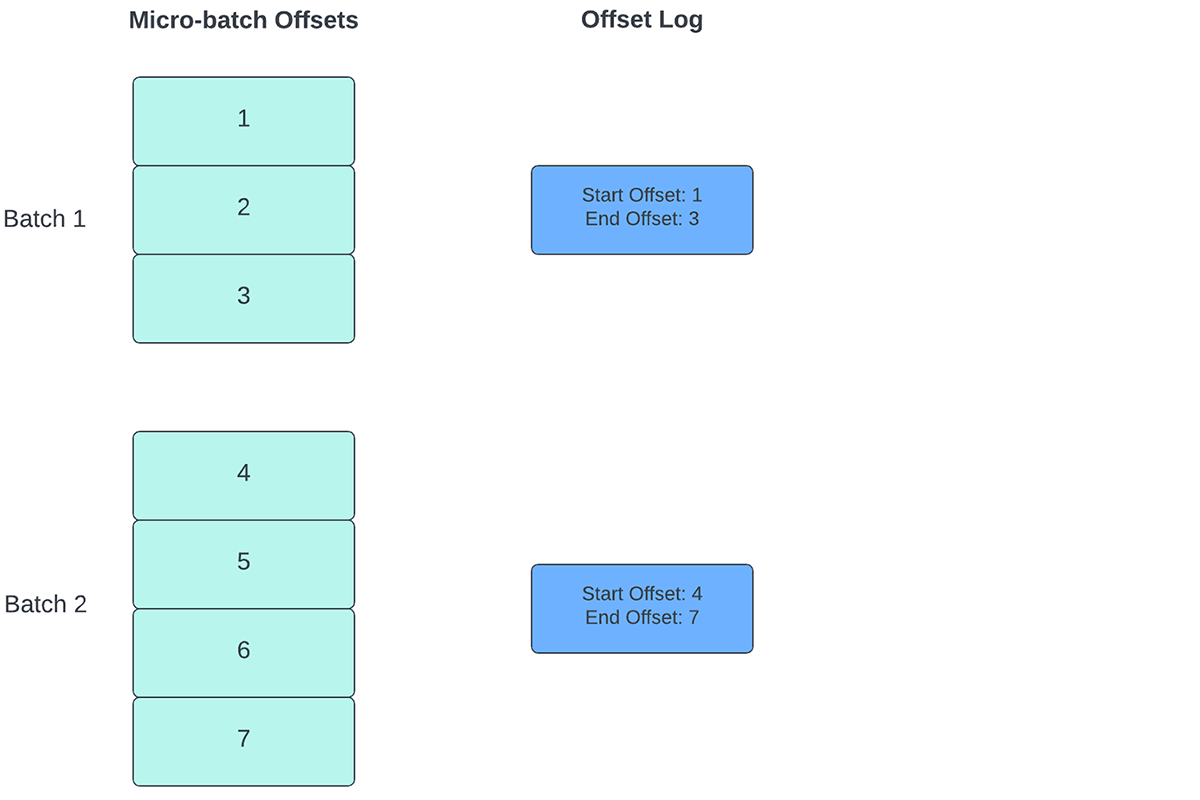
Pour suivre la progression du traitement des données, Spark Structured Streaming s'appuie sur la persistance et la gestion des décalages (offsets) qui sont utilisés comme indicateurs de progression. Généralement, un décalage est défini concrètement par le connecteur source, car les différents systèmes ont différentes manières de représenter la progression ou les emplacements dans les données. Par exemple, une implémentation concrète d'un offset peut être le numéro de ligne dans un fichier pour indiquer jusqu'où les données du fichier ont été traitées. Des logs durables (comme illustré dans la Figure 2) sont utilisés pour stocker ces offsets et marquer l'achèvement des micro-batchs.
{kind=link}
Dans Structured Streaming, les données sont traitées par unités de micro-lots. Deux Opérations de gestion des décalages sont effectuées pour chaque micro-batch. Une au début de chaque micro-batch et une à la fin.
- Au début de chaque micro-batch (avant le début effectif de tout traitement de données), un décalage est calculé en fonction des nouvelles données pouvant être lues depuis le système cible. Ce décalage est rendu persistant dans un Log durable appelé "offsetLog" dans le répertoire de point de contrôle. Ce décalage sert à calculer la plage de données qui sera traitée dans « ce » micro-batch.
- À la fin de chaque micro-batch, une entrée est persistée dans le journal durable appelé "commitLog" pour indiquer que "ce" micro-batch a été traité avec succès.
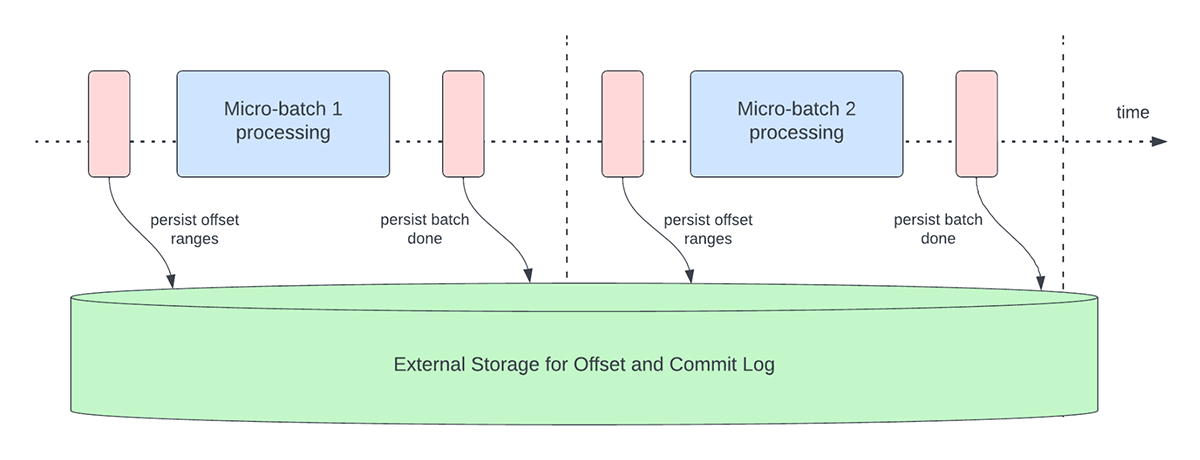
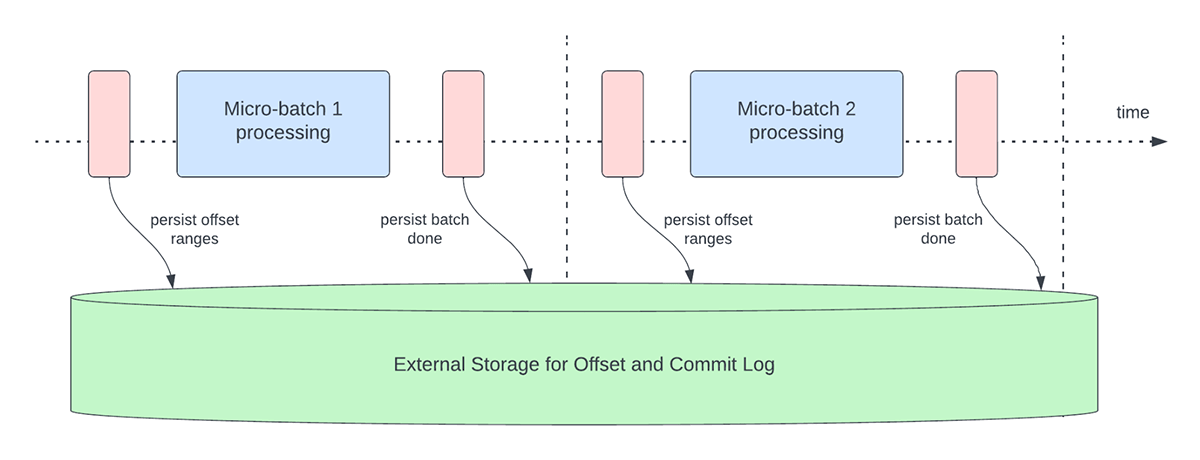
La Figure 3 ci-dessous illustre les opérations de gestion des offsets qui se produisent actuellement.
{kind=link}
Une autre opération de gestion des décalages est effectuée à la fin de chaque micro-batch. Cette opération est une opération de nettoyage visant à supprimer/tronquer les entrées anciennes et inutiles de l'offsetLog et du commitLog afin que ces logs ne s'étendent pas de manière illimitée.
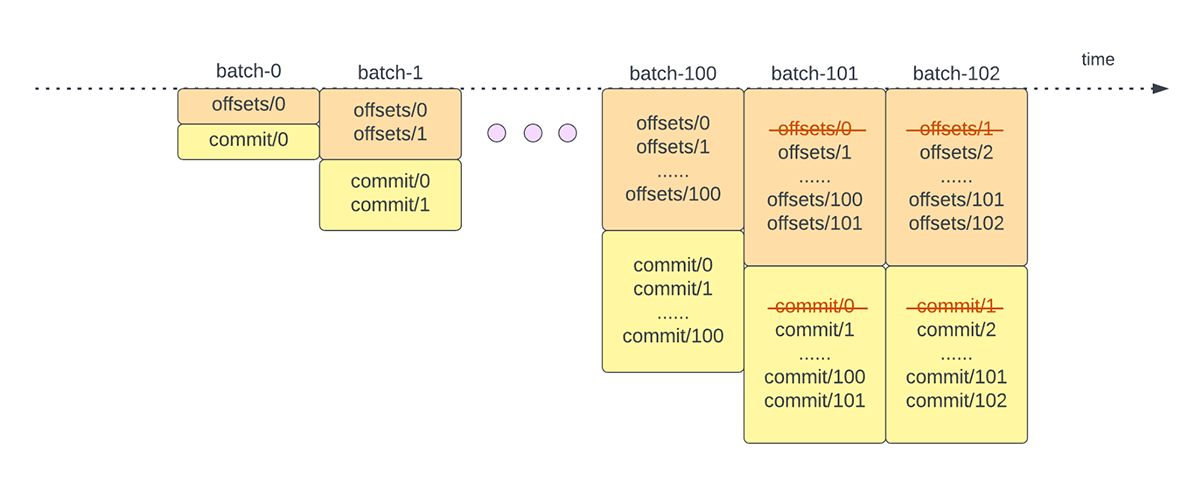
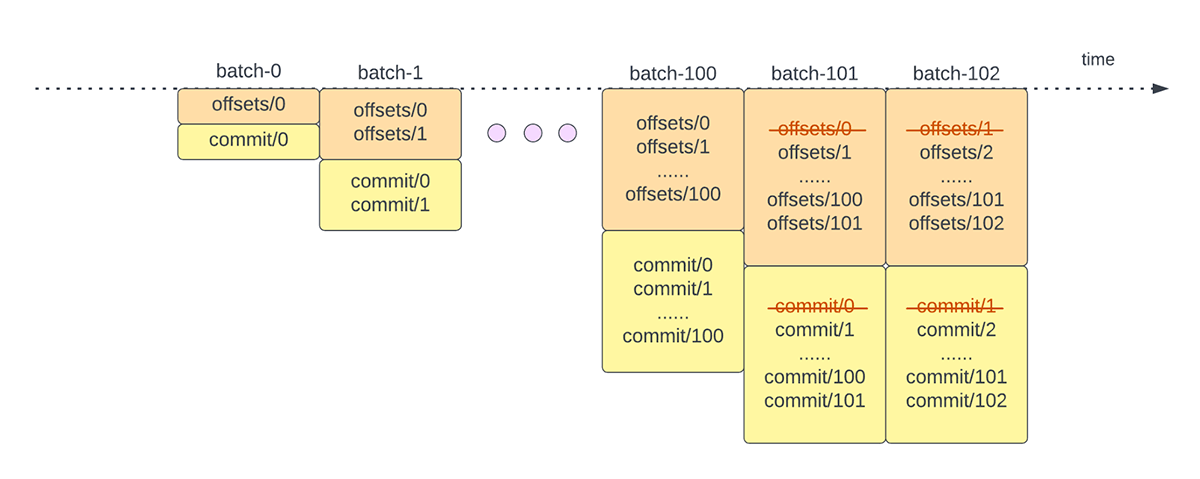{kind=link}
Ces opérations de gestion des décalages sont effectuées sur le chemin critique et en ligne avec le traitement réel des données. Cela signifie que la durée de ces opérations a un impact direct sur la latence de traitement et qu'aucun traitement de données ne peut avoir lieu tant que ces opérations ne sont pas terminées. Cela a également un impact direct sur l'utilisation du cluster.
Grâce à nos efforts d'évaluation comparative et de profilage des performances, nous avons identifié que ces opérations de gestion des décalages peuvent occuper la majorité du temps de traitement, en particulier pour les pipelines sans état à état unique qui sont souvent utilisés dans les cas d'utilisation d'alerte opérationnelle et de monitoring en temps réel.
Améliorations des performances dans Structured Streaming
Suivi de progression asynchrone
Cette fonctionnalité a été créée pour résoudre la surcharge de latence liée à la persistance des offsets à des fins de suivi de la progression. Cette fonctionnalité, lorsqu'elle est activée, permettra aux pipelines Structured Streaming de créer des points de contrôle de progression, c'est-à-dire de mettre à jour l'offsetLog et le commitLog, de manière asynchrone et en parallèle au traitement réel des données au sein d'un micro-lot. En d'autres termes, le traitement réel des données ne sera pas bloqué par ces opérations de gestion des offsets, ce qui améliorera considérablement la latence des applications. La Figure 5 ci-dessous illustre ce nouveau comportement pour la gestion des offsets.
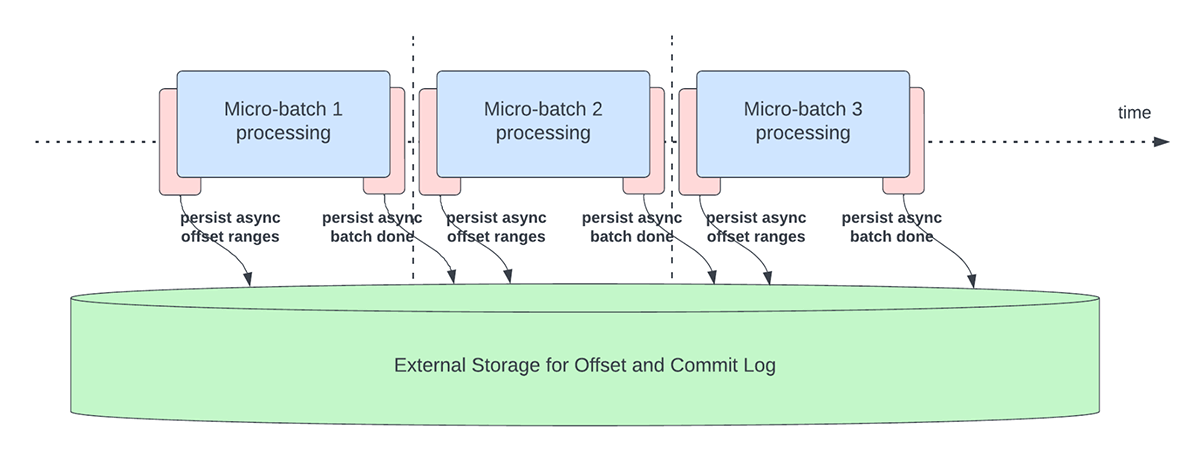
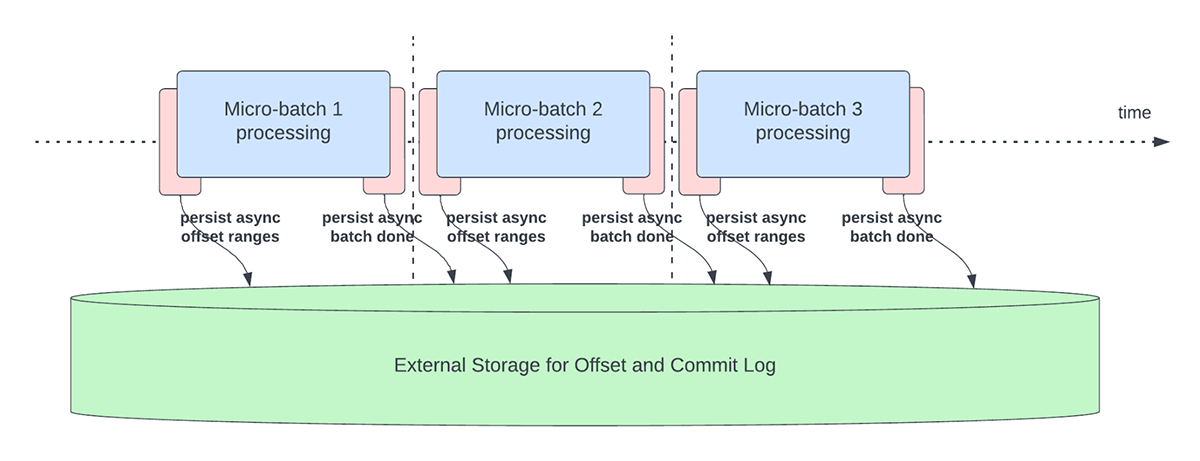{kind=link}
En plus d'effectuer des mises à jour de manière asynchrone, les utilisateurs peuvent configurer la fréquence à laquelle la progression est enregistrée par des points de contrôle. Cela sera utile pour les scénarios dans lesquels les opérations de gestion des décalages se produisent à une fréquence plus élevée que leur capacité de traitement. Cela se produit dans les pipelines lorsque le temps réellement consacré au traitement des données est nettement inférieur à celui de ces opérations de gestion des décalages. Dans de tels scénarios, un arriéré toujours croissant d'opérations de gestion des décalages se produira. Pour endiguer cet arriéré croissant, le traitement des données devra être bloqué ou ralenti, ce qui ramènera essentiellement le comportement de traitement à l'identique de celui où ces opérations de gestion des décalages sont exécutées en ligne avec le traitement des données. En règle générale, un utilisateur n'aura pas besoin de configurer ou de définir la fréquence des points de contrôle, car une valeur par défaut adéquate sera définie. Il est important de noter que le temps de récupération après une défaillance augmentera avec l'augmentation de l'intervalle de temps des points de contrôle. En cas d'échec, un pipeline doit retraiter toutes les données antérieures au dernier point de contrôle réussi. Les utilisateurs peuvent prendre en compte ce compromis entre une latence plus faible pendant le traitement normal et le temps de récupération en cas de défaillance.
Les configurations suivantes sont introduites pour activer et configurer cette fonctionnalité :
asyncProgressTrackingEnabled - activer ou désactiver le suivi asynchrone de la progressionDefault : false
asyncProgressCheckpointingInterval : l'intervalle auquel nous commitons les décalages et les commits d'achèvementDefault : 1 minute
L'exemple de code suivant illustre comment activer cette fonctionnalité :
Notez que cette fonctionnalité ne fonctionnera pas avec Trigger.once ou Trigger.availableNow, car ces déclencheurs exécutent les pipelines de manière manuelle ou planifiée. Par conséquent, le suivi de progression asynchrone ne sera pas pertinent. La query échouera si elle est soumise à l'aide de l'un des Triggers susmentionnés.
Applicabilité et limites
Il existe quelques limitations dans les versions actuelles qui pourraient changer à mesure que nous faisons évoluer la fonctionnalité :
- Actuellement, le suivi de progression asynchrone n'est pris en charge que dans les pipelines sans état utilisant Kafka Sink.
- Le traitement de bout en bout « exactly once » ne sera pas pris en charge avec ce suivi de progression asynchrone, car les plages d'offset pour un batch peuvent être modifiées en cas d'échec. Cependant, de nombreux récepteurs (sinks), tels que le récepteur Kafka, ne prennent en charge que les garanties « at-least once », ce qui fait que ce n'est peut-être pas une nouvelle limitation.
Purge asynchrone des Logs
Cette fonctionnalité a été créée pour résoudre la latence liée aux nettoyages des journaux effectués en ligne dans un micro-batch. En rendant asynchrone cette Opérations de nettoyage/purge des Logs et en l'exécutant en arrière-plan, nous pouvons éliminer la latence supplémentaire qu'elle cause lors du traitement des données. De plus, ces purges ne doivent pas nécessairement être effectuées à chaque micro-batch et peuvent se produire à une fréquence moins élevée.
Notez que cette fonctionnalité/amélioration n'a aucune limitation sur le type de pipelines ou de charges de travail qui peuvent l'utiliser. Par conséquent, cette fonctionnalité sera activée en arrière-plan par défaut pour tous les pipelines Structured Streaming.
Benchmarks
Afin de comprendre les performances du suivi de progression asynchrone et de la purge de Logs asynchrone, nous avons créé quelques benchmarks. Notre objectif avec les benchmarks est de comprendre la différence de performances que la gestion améliorée des offsets apporte dans un pipeline de streaming de bout en bout. Les benchmarks sont divisés en deux catégories :
- Source de débit vers puits de statistiques - Dans ce benchmark, nous avons utilisé une source et un puits de base, sans état et collectant des statistiques, ce qui est utile pour déterminer la différence de performance du moteur principal sans aucune dépendance externe.
- Source Kafka vers récepteur Kafka : pour ce benchmark, nous déplaçons des données d'une source Kafka vers un récepteur Kafka. Ceci s'apparente à un scénario du monde réel pour voir quelle serait la différence dans un scénario de production.
Pour ces deux tests de performance, nous avons mesuré la latence de bout en bout (50e centile, 99e centile) à différents débits de données d'entrée (100K événements/s, 500K événements/s, 1M d'événements/s).
Méthodologie du benchmark
La méthodologie principale consistait à générer des données à partir d'une source à un throughput constant donné. Les enregistrements générés contiennent des informations sur le moment où ils ont été créés. Côté récepteur, nous utilisons la bibliothèque Apache DataSketches pour recueillir la différence entre le moment où le récepteur traite l'enregistrement et le moment où il a été créé dans chaque batch. Ceci est utilisé pour calculer la latence. Nous avons utilisé le même cluster avec le même nombre de nœuds pour toutes les expérimentations.
Remarque : pour le benchmark Kafka, nous avons mis de côté certains nœuds d'un cluster pour exécuter Kafka et générer les données à fournir à Kafka. Nous calculons la latence d'un enregistrement uniquement après que l'enregistrement a été publié avec succès dans Kafka (sur le récepteur).
Benchmark de la source de débit vers le récepteur de statistiques
Pour ce benchmark, nous avons utilisé un cluster Spark de 7 nœuds de travail (i3.2xlarge - 4 cœurs, 61 Gio de mémoire) utilisant le Databricks runtime (11.3). Nous avons mesuré la latence de bout en bout pour les scénarios suivants afin de quantifier la contribution de chaque amélioration.
- Structured Streaming actuel - il s'agit de la latence de base sans aucune des améliorations susmentionnées
- Purge de Logs asynchrone : mesure la latence après l'application de la purge de Logs asynchrone uniquement
- Progression asynchrone : mesure la latence après l'application du suivi de la progression asynchrone
- Async Progress + Async Log Purge : mesure la latence après l'application des deux améliorations
Les résultats de ces expériences sont présentés dans les Figures 6, 7 et 8. Comme vous pouvez le voir, la purge asynchrone des Logs réduit de manière constante la latence d'environ 50 %. De même, le suivi de progression asynchrone seul améliore la latence d'environ 65 %. Combinées, la latence est réduite de 85 �à 86 % et passe en dessous de 100 ms.
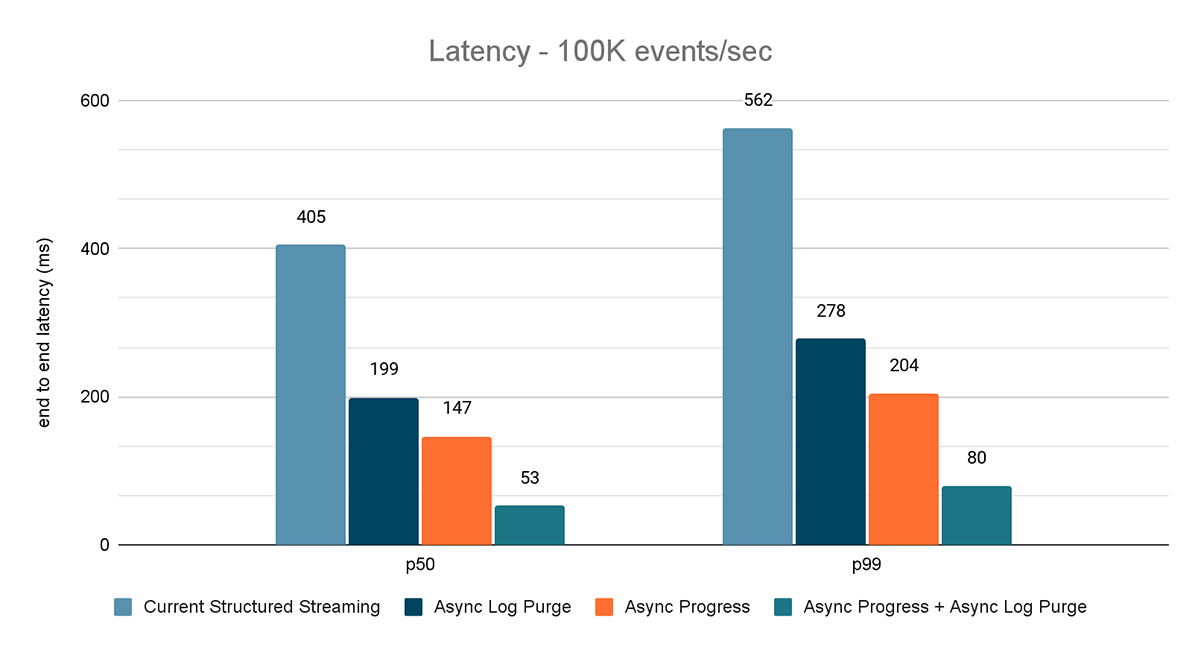
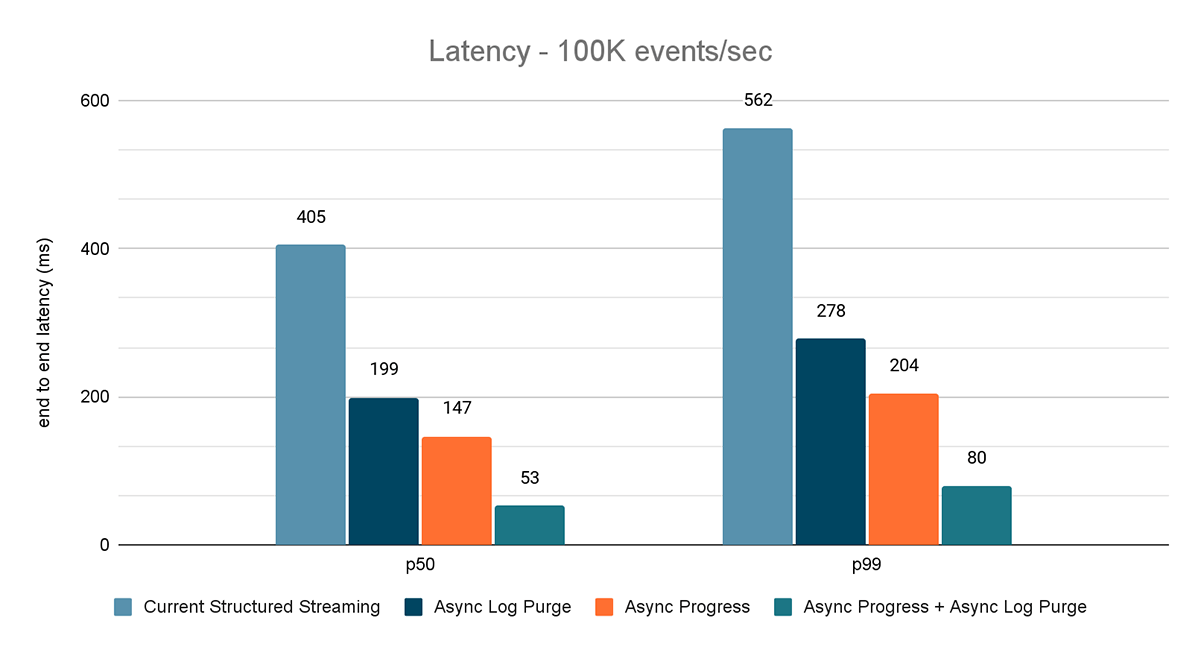{kind=link}
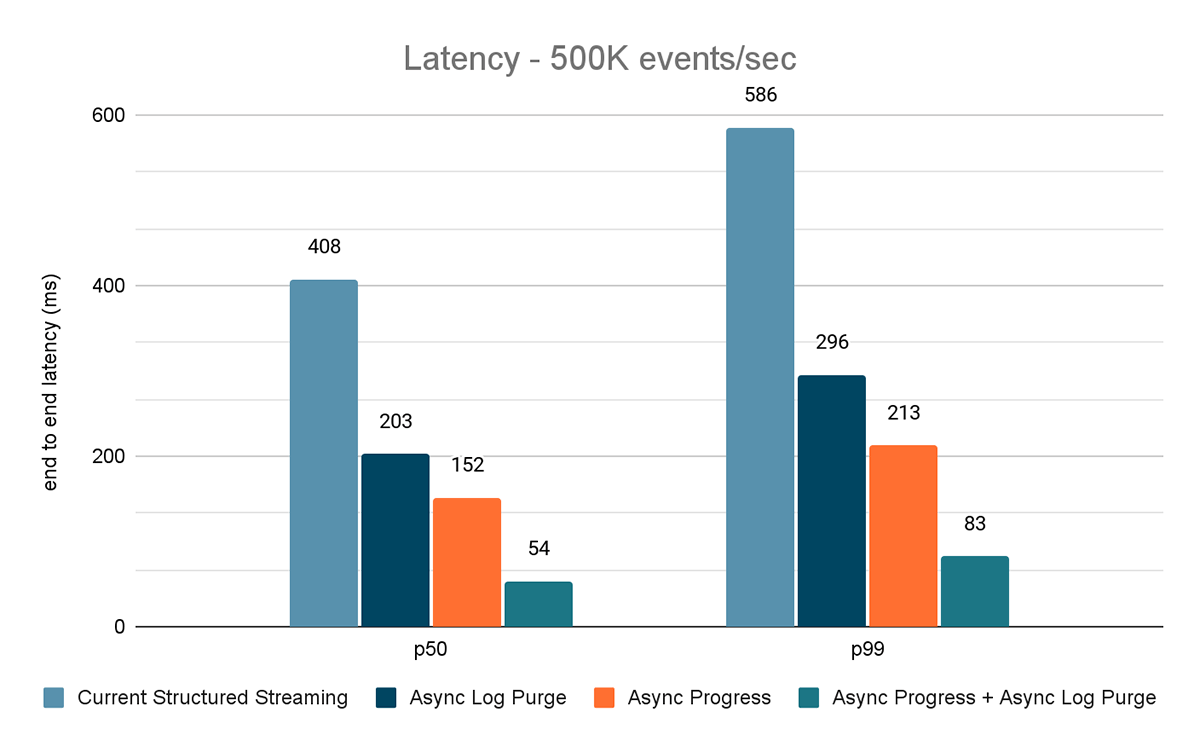
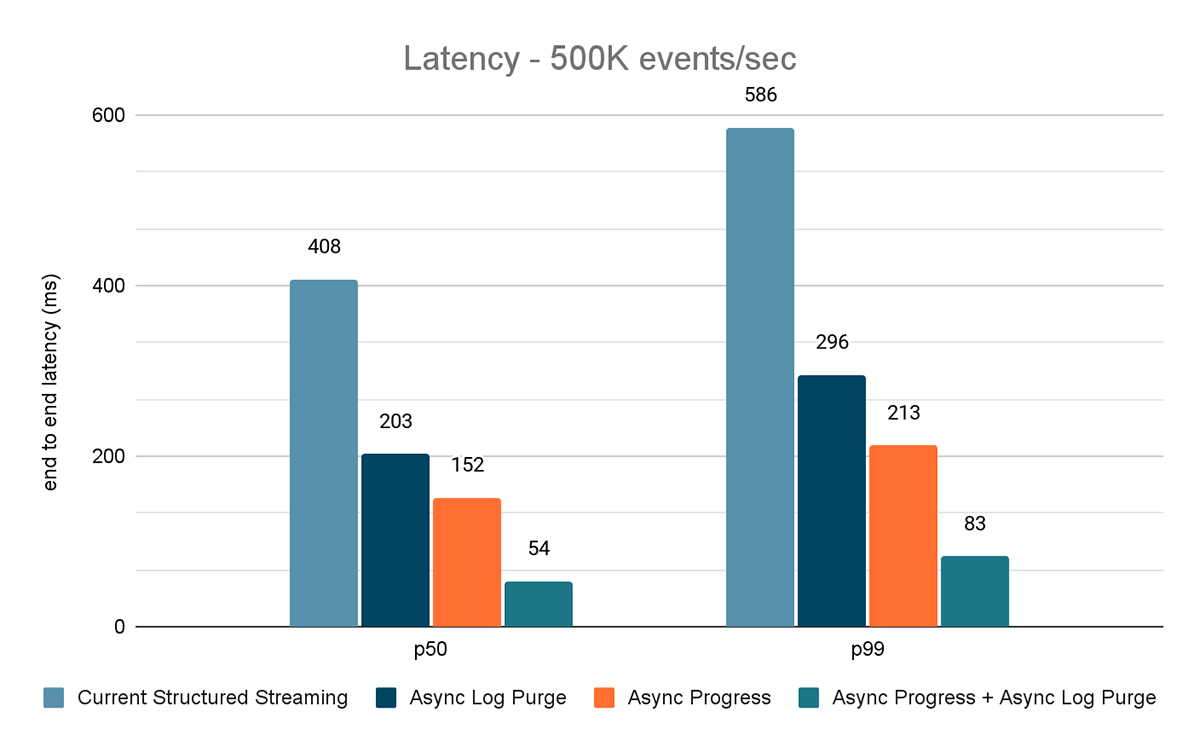{kind=link}
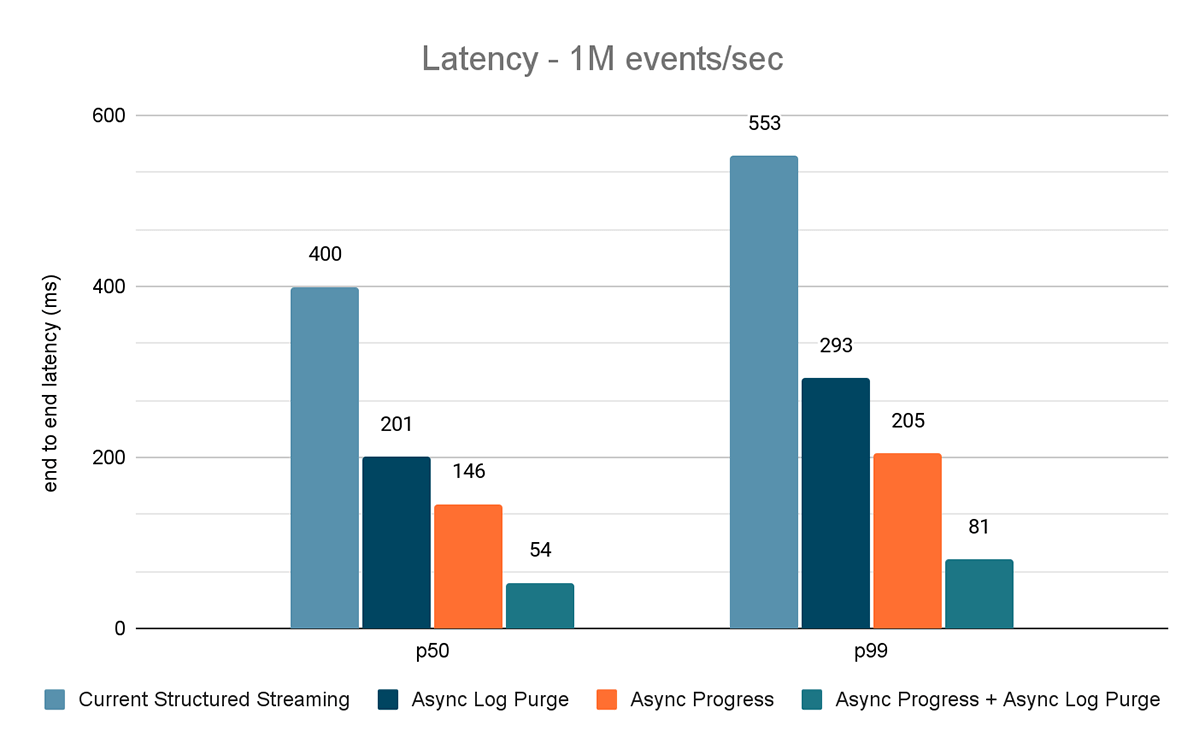
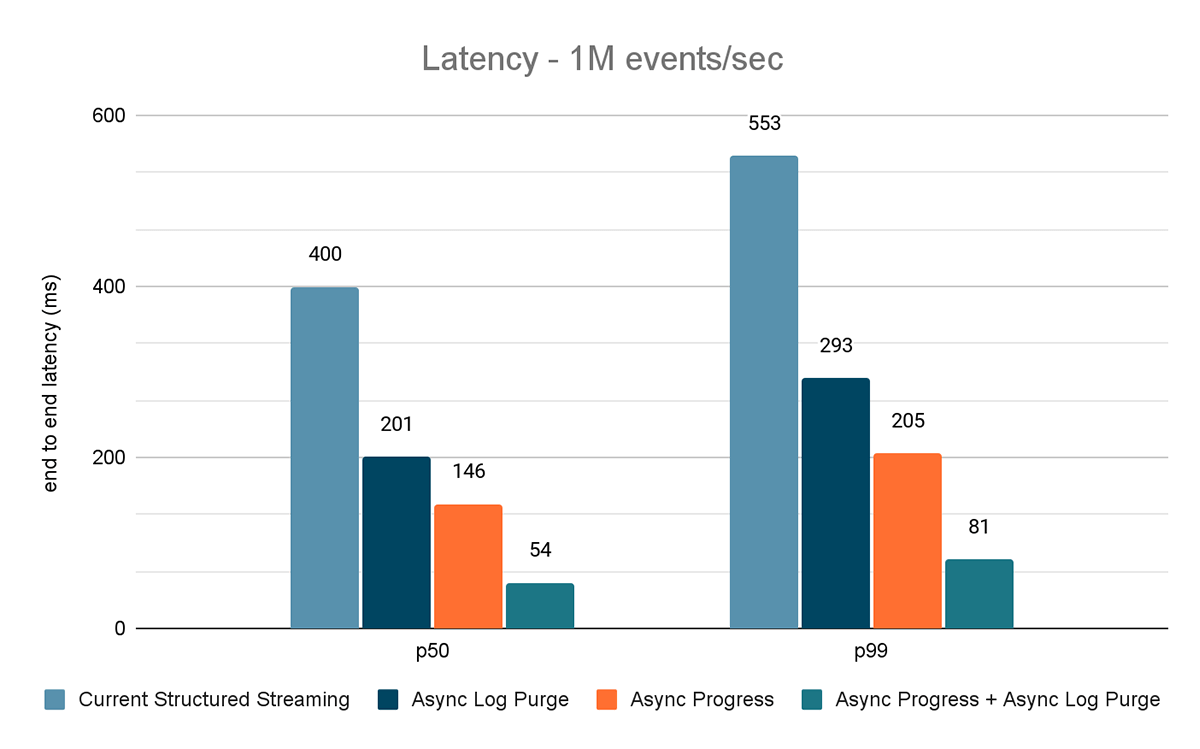{kind=link}
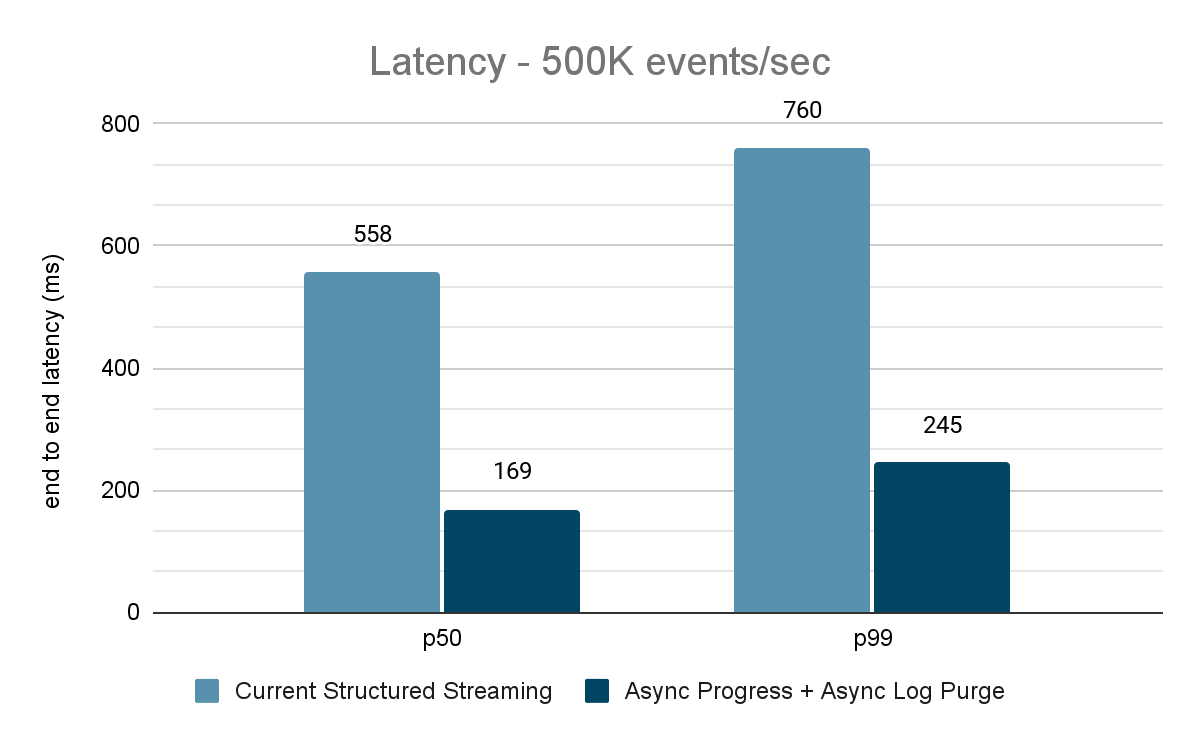
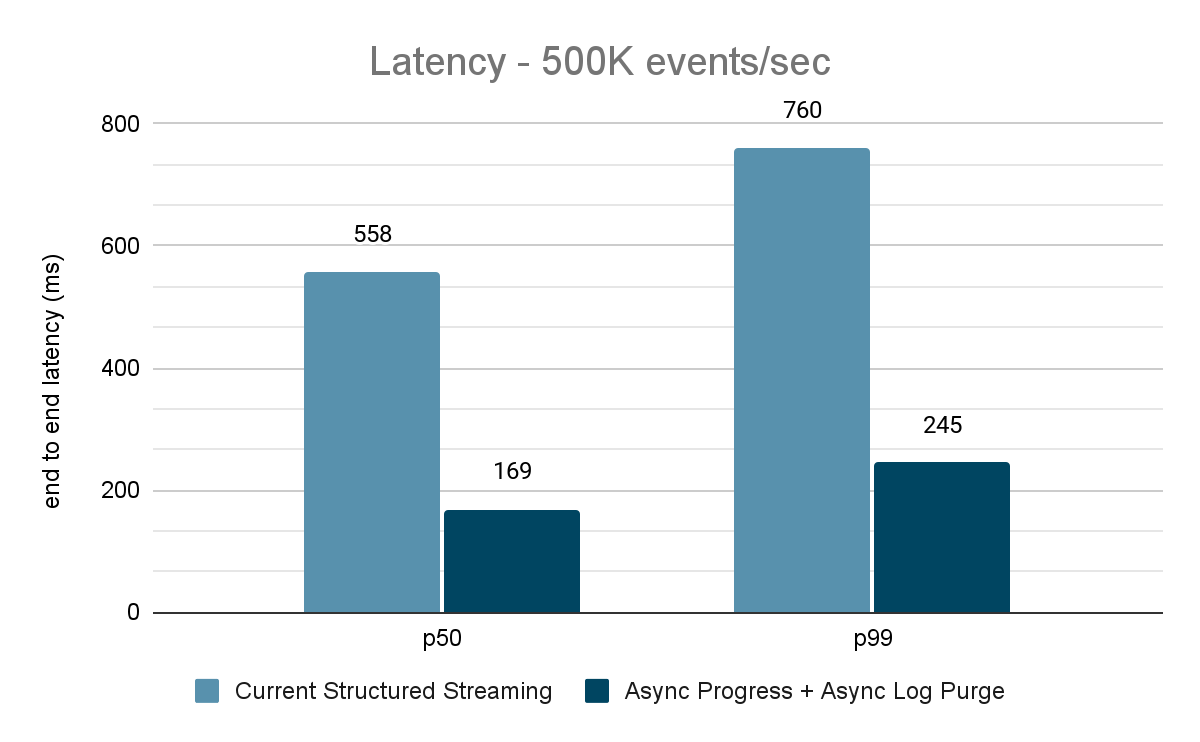
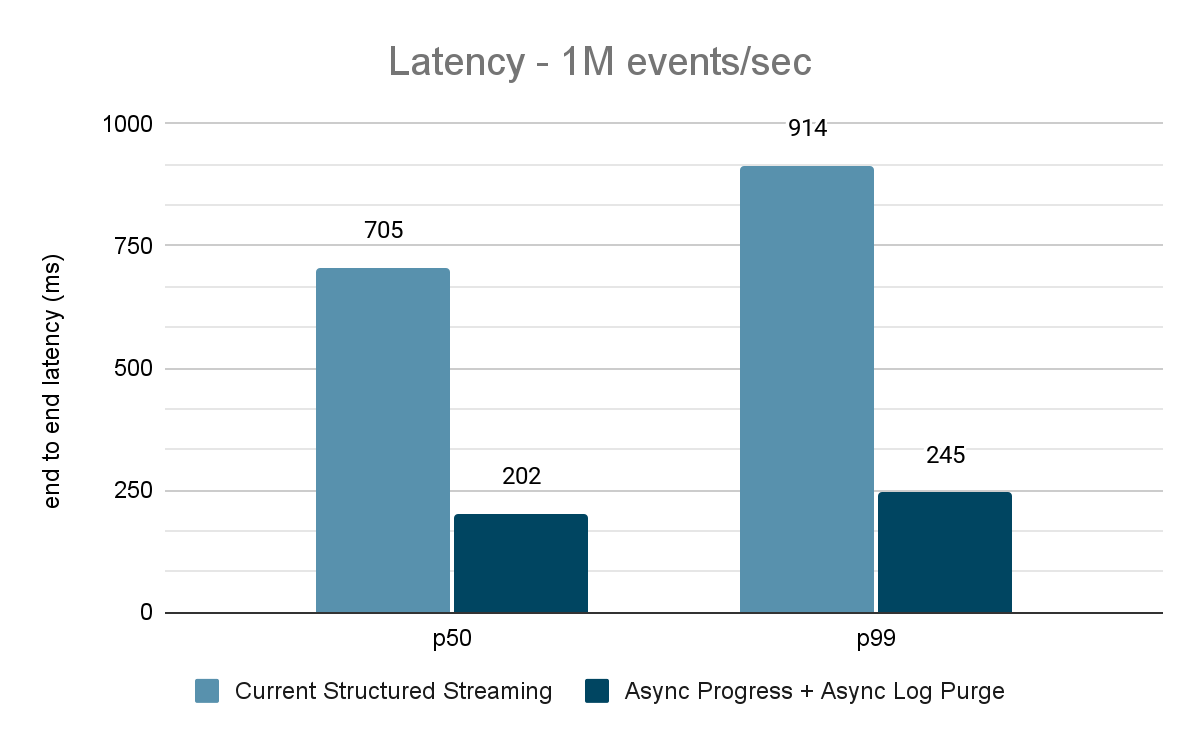
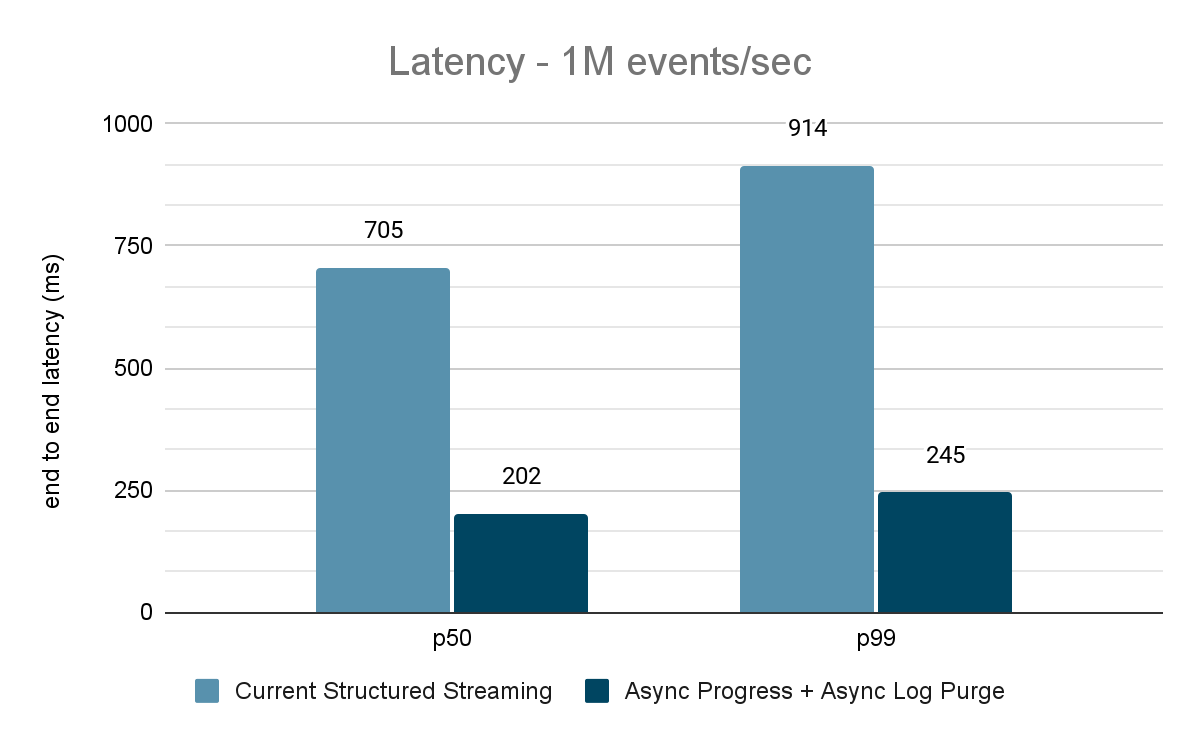
Benchmark source Kafka vers récepteur Kafka
Pour les benchmarks Kafka, nous avons utilisé un cluster Spark de 5 nœuds de travail (i3.2xlarge - 4 cœurs, 61 Gio de mémoire), un cluster séparé de 3 nœuds pour exécuter Kafka et 2 nœuds supplémentaires pour générer des données ajoutées à la source Kafka. Notre sujet Kafka a 40 partitions et un facteur de réplication de 3.
Le générateur de données publie les données dans un topic Kafka, et le pipeline de streaming structuré consomme les données et les republie dans un autre topic Kafka. Les résultats de l'évaluation des performances sont présentés dans les figures 9, 10 et 11. Comme on peut le constater, après application de la progression asynchrone et de la purge de journal asynchrone, la latence est réduite de 65 à 75 % (soit 3 à 3,5 fois) sur différents débits.
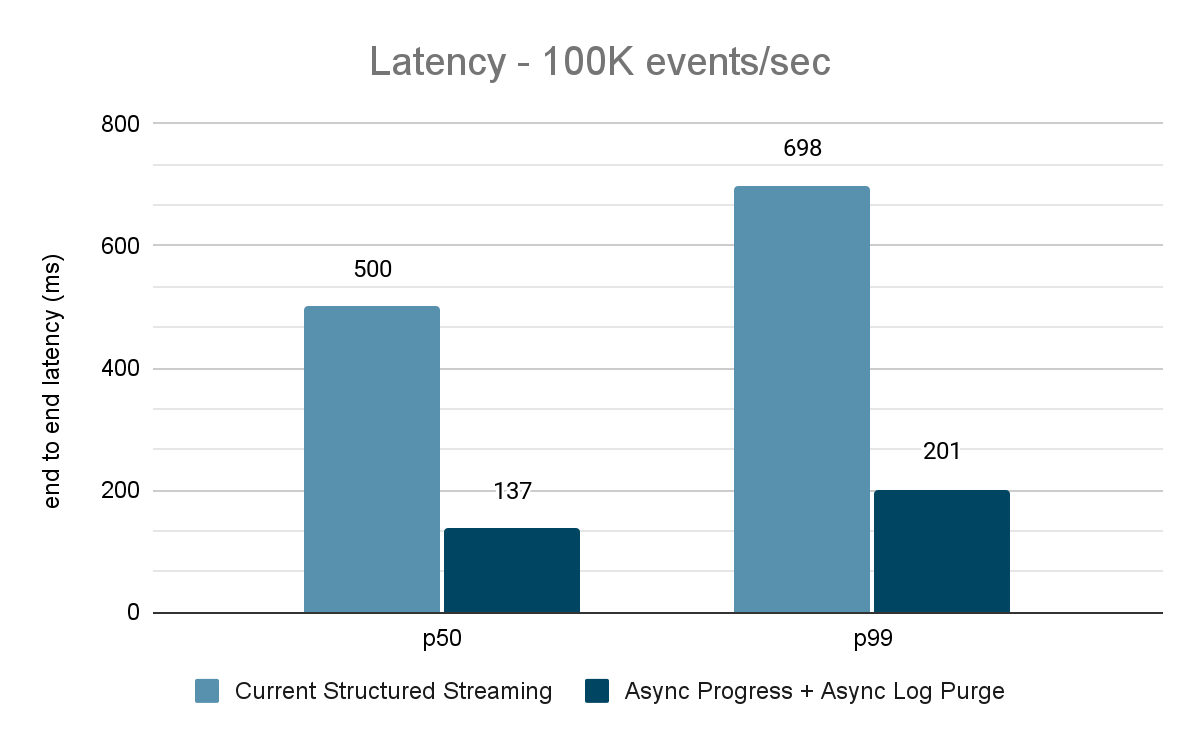
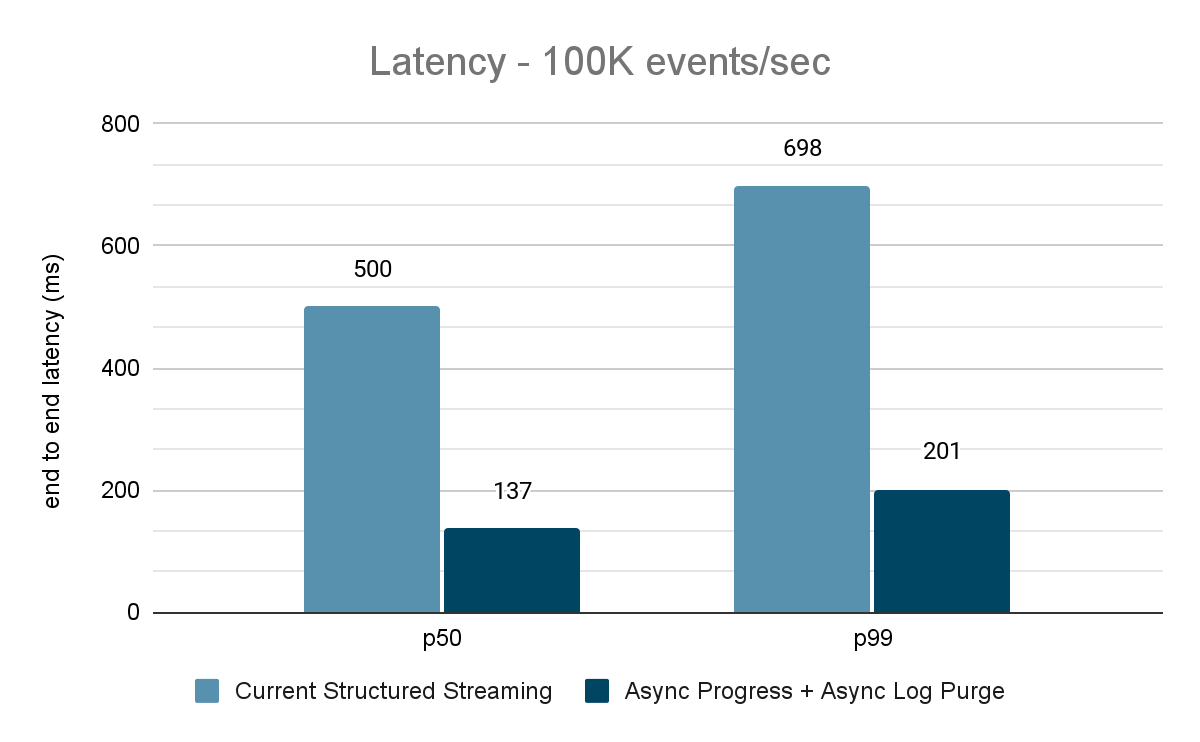{kind=link}
{kind=link}
{kind=link}
Résumé des résultats de performance
Avec le nouveau suivi de progression asynchrone et la nouvelle purge asynchrone des Logs, nous pouvons voir que les deux configurations réduisent la latence jusqu'à 3 fois. En travaillant ensemble, la latence est considérablement réduite pour tous les throughputs. Les graphiques montrent également que le temps gagné est généralement un temps constant (200 - 250 ms pour chaque configuration) et qu'ensemble, ils peuvent réduire le temps d'environ 500 ms sur toute la ligne (laissant suffisamment de temps pour la planification des batch et le traitement des queries).
Disponibilité
Ces améliorations de performance sont disponibles dans la Databricks Lakehouse Platform à partir de DBR 11.3. La purge asynchrone des Logs est activée par défaut dans DBR 11.3 et les versions ultérieures. En outre, ces améliorations ont été apportées à Open Source Spark et sont disponibles à partir d'Apache Spark 3.4.
Travaux futurs
Il existe actuellement certaines limitations quant aux types de charges de travail et de récepteurs pris en charge par la fonctionnalité de suivi de la progression asynchrone. À l'avenir, nous chercherons à prendre en charge davantage de types de charges de travail avec cette fonctionnalité.
Ce n'est que le début des fonctionnalités à faible latence prévisible que nous développons dans Structured Streaming dans le cadre du projet Lightspeed. En outre, nous continuerons à analyser et à profiler Structured Streaming pour trouver d'autres possibilités d'amélioration. Restez à l'écoute !
Rejoignez-nous au Data and AI Summit à San Francisco, du 26 au 29 juin, pour en savoir plus sur le projet Lightspeed et le streaming de données sur la Databricks Lakehouse Platform.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Ne manquez jamais un article Databricks
Et ensuite ?

Streaming de dados
September 24, 2025/12 min de leitura
De Lag para Agilidade: Reinventando a Arquitetura de Ingestão de Dados da Freshworks
Soluções
December 30, 2025/5 min de leitura