data warehouse

Qu'est-ce qu'un data warehouse ?
Un data warehouse est un système de gestion des données qui conserve les données actuelles et historiques de multiples sources sous une forme orientée entreprise pour faciliter la création d'insights et de rapports. Les data warehouses sont généralement utilisés à des fins de business intelligence (BI), d'analytique et de rapport, pour prendre en charge des applications de données et préparer les données pour le machine learning (ML) et l'analyse.
Les data warehouses permettent d'analyser rapidement et simplement les données commerciales provenant de divers systèmes opérationnels : systèmes de point de vente, gestion d'inventaire, bases de données de marketing ou de vente. Les données peuvent traverser un data store opérationnel et nécessiter un nettoyage pour en garantir la qualité avant qu'elles soient utilisées dans le data warehouse pour produire des rapports.
Poursuivez votre exploration


Dans quel but utilise-t-on des data warehouses ?
Les data warehouses sont utilisés à des fins de BI, de rapport et d'analyse, pour prendre en charge des applications de données et préparer des données pour le machine learning. Ils facilitent l'extraction et la synthèse à partir de bases de données opérationnelles. Ils permettent notamment d'obtenir des informations difficiles à extraire directement de bases de données transactionnelles. Imaginons par exemple que la direction souhaite connaître chaque mois le total des revenus générés par chaque commercial, dans chaque catégorie de produit. Les bases de données transactionnelles ne capturent pas nécessairement ces données, alors que les data warehouses en sont capables.
Quels sont les types de data warehouses ?
- Data warehouse traditionnel : ce type de data warehouse stocke uniquement des données structurées. La structure du data warehouse permet aux utilisateurs d'accéder rapidement et facilement aux données à des fins de rapport et d'analytique.
- Data warehouse intelligent : ce type moderne de data warehouse repose sur une architecture de lakehouse et possède une plateforme intelligente qui est automatiquement optimisée. Un data warehouse intelligent ne donne pas seulement accès à des modèles d'IA et de ML : il utilise aussi l'IA pour faciliter la création de requêtes et de tableaux de bord, ainsi que pour optimiser les performances et les capacités.
Architecture du data warehouse
L'architecture d'entreposage des données suit le plus souvent un modèle à plusieurs niveaux. Cette architecture a été créée par Bill Inmon, l'informaticien souvent considéré comme le père du data warehouse.
Niveau inférieur
Le niveau inférieur d'une architecture de data warehouse comprend les sources de données et l'espace de stockage. Il inclut également des méthodes d'accès : API, passerelles, ODBC, JDBC et OLE-DB. C'est également au niveau inférieur qu'ont lieu l'importation des données ou ETL.
Niveau intermédiaire
Le niveau intermédiaire d'une architecture de data warehouse comprend un serveur OLAP qui peut être relationnel (ROLAP) ou multidimensionnel (MOLAP). Ces deux types peuvent être combinés pour former un serveur OLAP hybride (HOLAP).
Niveau supérieur
Le niveau supérieur d'une architecture de data warehouse accueille les clients front-end de requête, de BI, de création de tableaux de bord, de rapports et d'analyse.
Quelles sont les trois variantes du data warehouse ?
- Data warehouse d'entreprise (EDW) : ce data warehouse centralisé est utilisé par de nombreuses équipes différentes au sein de l'organisation. Il constitue souvent la source de référence pour la BI, l'analytique et la création de rapports.
- Dépôt de données opérationnelles (ODS) : ce type de data warehouse est dédié aux données opérationnelles ou transactionnelles les plus récentes.
- Data mart : cette version simplifiée du data warehouse dessert une seule ligne d'activité (LOB) ou un seul projet. Le data mart a des dimensions réduites par rapport à l'EDW, mais le nombre de data marts a tendance à augmenter avec la croissance de l'entreprise pour répondre aux besoins de libre accès des LOB.
Data lake, base de données et data warehouse
Quelle est la différence entre un data lake et un data warehouse ?
Le data lake et le data warehouse sont deux approches différentes de la gestion et du stockage des données.
Un data lake est un data repository de données non structurées ou semi-structurés qui permet de stocker de grandes quantités de données brutes dans leur format d'origine. Les data lakes sont conçus pour importer et conserver tous les types de données, qu'elles soient structurées, semi-structurées, non structurées, sans aucun schéma prédéfini. Les données sont souvent stockées dans leur format natif et ne sont pas nettoyées, transformées ni intégrées. Cela facilite le stockage et l'accès à de grands volumes de données.
Un data warehouse traditionnel, en revanche, est un repository structuré qui stocke les données de différentes sources sous une forme bien organisée, dans le but de fournir une source unique de vérité à des fins de business intelligence et d'analytique. Les données sont nettoyées, transformées et intégrées au sein d'un schéma optimisé pour les requêtes et l'analyse.
Un data warehouse intelligent reposant sur l'architecture du lakehouse fournit lui aussi une source de référence pour la business intelligence et l'analytique. Il va plus loin que le data warehouse traditionnel en accueillant aussi bien les données structurées, semi-structurées et non structurées. Il fournit également des fonctions de qualité des données et d'émission d'alertes basées sur des seuils.
Quelle est la différence entre un data warehouse et une base de données ?
Une base de données est une collection de données structurées diverses : textes et nombres, mais aussi images, vidéos et plus encore. Beaucoup désignent les systèmes de gestion de base de données par leur acronyme anglais, DMS. Le DBMS est le système de stockage des données qui alimentent les applications et l'analytique.
Un data warehouse traditionnel, en revanche, est un référentiel structuré qui fournit des données à des fins de business intelligence et d'analytique. Les données sont nettoyées, transformées et intégrées au sein d'un schéma optimisé pour les requêtes et l'analyse, et certaines agrégations courantes peuvent également être effectuées.
Quelle est la différence entre un data lake, un data warehouse et un data lakehouse ?
Le data lakehouse est une approche hybride qui réunit les avantages des deux mondes. C'est une architecture de données moderne qui intègre les capacités d'un data warehouse traditionnel et d'un data lake au sein d'une plateforme unifiée. Elle permet de conserver des données brutes dans leur format d'origine, comme avec un data lake, tout en fournissant les capacités de traitement et d'analytique typiques d'un data warehouse.
En résumé, la principale différence entre un data lake, un data warehouse traditionnel et un data lakehouse réside dans l'approche de la gestion et du stockage des données. Le data warehouse traditionnel stocke les données non structurées dans un schéma prédéfini, le data lake conserve les données brutes dans leur format d'origine, et un data lakehouse est une approche hybride combinant les capacités des deux.
Data lake | Data Lakehouse | Data warehouse traditionnel | |
|---|---|---|---|
Types de données | Tous les types : données structurées, semi-structurées et non structurées (brutes) | Tous les types : données structurées, semi-structurées et non structurées (brutes) | Données structurées uniquement |
Coût | $ | $ | $$$ |
Format | Format ouvert | Format ouvert | Format fermé, propriétaire |
Évolutivité | Peut accueillir n'importe quelle quantité de données à faible coût, quel que soit leur type | Peut accueillir n'importe quelle quantité de données à faible coût, quel que soit leur type | Le coût de l'évolutivité augmente de façon exponentielle en raison des coûts des fournisseurs |
Utilisateurs prévus | Limité : data scientists | Unifié : data analysts, data scientists, ingénieurs en machine learning | Limité : data analysts |
Fiabilité | Faible qualité, « marécages » de données | Données fiables de haute qualité | Données fiables de haute qualité |
Simplicité d'utilisation | Difficile : l'exploration de données brutes peut être difficile sans outils pour organiser et cataloguer les données | Simple : la simplicité et la structure du data warehouse sont mises au service des cas d'usage plus vastes du data lake | Simple : la structure du data warehouse permet aux utilisateurs d'accéder rapidement et facilement aux données à des fins de rapport et d'analytique |
Performance | Médiocre | Haute | Haute |
Un data lake peut-il remplacer un data warehouse ?
Pas vraiment. Le data lake et le data warehouse sont deux approches différentes de la gestion et du stockage des données, avec leurs forces et leurs faiblesses respectives. Si le data lake peut compléter le data warehouse en fournissant des données brutes à des fins d'analytique avancée, il ne peut pas remplacer entièrement un data warehouse au sens traditionnel du terme. En revanche, un data lake et un data warehouse peuvent se compléter : le data lake servira de source de données brutes à des fins d'analytique avancée, et le data warehouse fournira une source structurée, organisée et fiable de données commerciales à des fins de rapport et d'analyse.
Le data lake est le fondement du data lakehouse. Ce dernier peut remplacer le data warehouse traditionnel et s'appuie sur des formats de données ouverts tels que Delta Lake et Apache Iceberg™, garantissant fiabilité et performance.
Un data lakehouse peut-il remplacer un data warehouse traditionnel ?
Oui. Le data lakehouse est une architecture de données moderne qui combine les avantages d'un data warehouse et d'un data lake au sein d'une plateforme unifiée. Un data lakehouse repose sur un data lake ouvert et peut remplacer un data warehouse traditionnel parce qu'il réunit les capacités d'un data lake et d'un data warehouse au sein d'une même plateforme.
Le data lakehouse permet de conserver des données brutes dans leur format d'origine, comme avec un data lake, tout en fournissant les capacités de traitement et d'analytique typiques d'un data warehouse. Son approche d'application de schéma à la lecture offre de la flexibilité dans le traitement et l'interrogation des données. Une plateforme qui réunit les atouts d'un data lake et d'un data warehouse offre davantage de flexibilité, d'évolutivité et de rentabilité.
Qu'est-ce qu'un data warehouse moderne ?
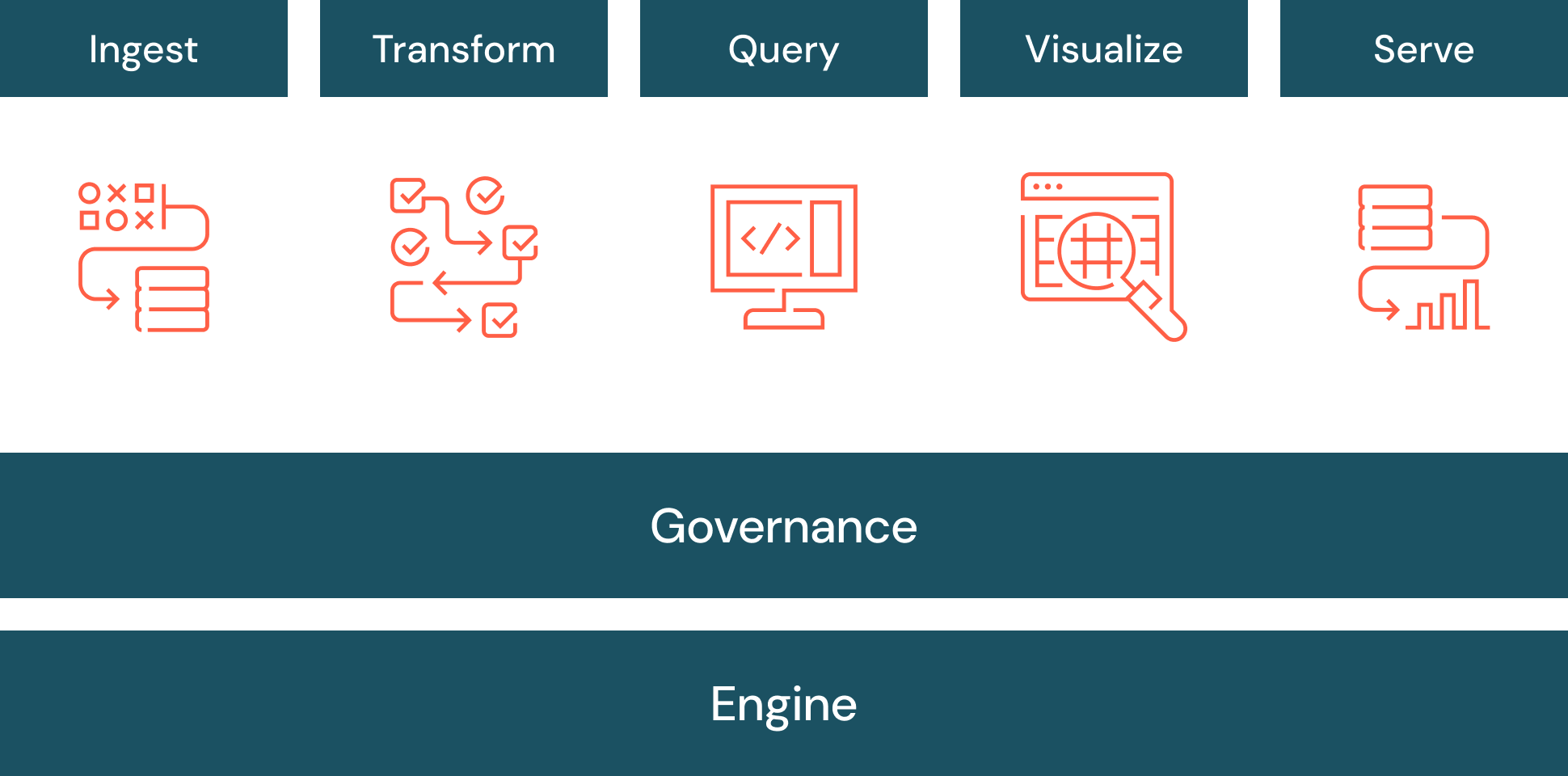
L'entreposage des données évolue sans cesse. On appelle également le data warehouse moderne « data warehouse intelligent » parce qu'il utilise des technologies récentes comme l'IA. Un data warehouse intelligent s'appuie sur une architecture de data lakehouse ouverte plutôt que sur celle du data warehouse traditionnel. Un data warehouse intelligent comprend les caractéristiques uniques de vos données et optimise automatiquement la plateforme dans une optique de faible latence et de concurrence élevée. Un data warehouse intelligent a également besoin d'un système de gouvernance unifiée pour encadrer la sécurité, les contrôles et les workflows. Il utilise l'IA pour générer des requêtes, corriger les erreurs, suggérer des visualisations et plus encore.
Qu'est-ce que l'ETL dans un data warehouse ?
Le data warehouse a besoin de données. Ces données doivent être chargées dans le data warehouse (ou référencées, selon le modèle de la fédération de lakehouses). Le processus consistant à extraire les données des systèmes sources, à les transformer puis à les charger dans le data warehouse est appelé ETL (extraction, transformation, chargement). L'ETL est généralement employé pour intégrer des données structurées provenant de différentes sources dans un schéma prédéfini.
La fédération de requêtes est un style d'ETL qui permet d'exécuter des requêtes sur de multiples sources de données réparties sur plusieurs clouds. Les données peuvent être visualisées et interrogées depuis un même endroit sans qu'il faille les déplacer vers un système unifié. Ce concept est aussi parfois appelé « virtualisation des données ».
Qu'est-ce qu'une dimension dans un data warehouse ?
Dans un data warehouse, une dimension décrit les données à l'aide d'informations d'étiquetage structurées. Ces informations permettent de filtrer, grouper et étiqueter les données. Par exemple, des entités commerciales telles qu'un client ou un produit peuvent constituer des dimensions.
Qu'est-ce qu'un fait dans un data warehouse ?
Dans un data warehouse, un fait est utilisé pour quantifier les données sous forme de nombres. Les commandes d'un client ou des données financières, par exemple, sont des faits.
Qu'est-ce que la modélisation dimensionnelle dans un data warehouse ?
La modélisation dimensionnelle est une technique d'entreposage des données qui organise les données en dimensions et en faits. Elle identifie les processus métier importants, puis modélise le data warehouse de façon à les soutenir.
Qu'est-ce qu'un schéma en étoile dans un data warehouse ?
Un schéma en étoile est un modèle de données multidimensionnel qui permet d'organiser une base de données afin de faciliter sa compréhension et son analyse. Les data warehouses, les bases de données, les data marts et d'autres outils peuvent bénéficier des schémas en étoile. Par leur conception, les schémas en étoile sont optimisés pour interroger de grands ensembles de données.
Introduits par Ralph Kimball dans les années 1990, ils sont particulièrement efficaces pour stocker et mettre à jour des données, tout en conservant un historique fiable. Ils réduisent en effet la duplication de définitions métier répétitives et accélèrent l'agrégation et le filtrage des données dans le data warehouse.
Quels avantages peut apporter un data warehouse à l'entreprise ?
- Consolidation des données provenant de nombreuses sources. Le data warehouse peut devenir le point d'accès unique pour toutes les données. Les utilisateurs n'ont ainsi plus besoin de se connecter à des dizaines, voire des centaines de dépôts.
- Renseignements historiques. Un data warehouse intègre les données de nombreuses sources et permet de mettre en évidence des tendances historiques.
- Séparation du traitement analytique des bases de données transactionnelles, ce qui améliore les performances des deux systèmes.
- Qualité, cohérence et précision des données. Un data warehouse bien conçu s'appuie sur une sémantique standard : cohérence des conventions de nommage, codes pour différents types de produits, langues, devises, etc.
- Tous les profils d'utilisateur, même sans maîtrise de SQL, peuvent obtenir des réponses à partir des données.
Défis des data warehouses
Quel que soit le type de data warehouse utilisé, il faut anticiper plusieurs points d'achoppement :
- Le manque de connexion entre les outils employés pour les données et les assets d'IA produit une approche fragmentée, néfaste pour la gouvernance des données.
- Les utilisateurs ont besoin d'une formation et de compétences spécifiques pour rédiger des requêtes, comprendre les structures de données, localiser les meilleures sources de données et s'y connecter, etc.
- Quand un data warehouse grandit, il ralentit. Dans le cloud, les coûts de calcul peuvent augmenter rapidement.
Évolutivité et performance
Avec la croissance des volumes de données, l'architecture du lakehouse distribue les fonctions de calcul indépendamment du stockage afin de maintenir des performances constantes pour un coût optimal. Il vous faut une plateforme conçue pour être élastique afin de permettre à votre organisation de développer ses opérations de données en fonction de ses besoins. L'évolutivité s'applique à différentes dimensions :
- Serverless : la plateforme doit permettre l'ajustement et le dimensionnement élastiques des charges de travail en fonction de la capacité de calcul requise. L'affectation dynamique des ressources garantit une grande rapidité de traitement des données et d'analyse, même pendant les pics de demande.
- Concurrence : la plateforme doit miser sur le calcul serverless et l'optimisation par IA pour permettre le traitement simultané des données et l'exécution de plusieurs requêtes en parallèle. Cela permettra à différents utilisateurs et équipes de réaliser des tâches d'analyse en même temps sans dégrader les performances.
- Stockage : la plateforme doit s'intégrer parfaitement aux data lakes de façon à stocker de grands volumes de données à moindre coût, tout en assurant la disponibilité et la fiabilité des données. Elle doit également optimiser le stockage dans un souci de performance pour réduire les dépenses associées.
L'évolutivité, aussi essentielle soit-elle, ne doit pas se faire au détriment de la performance. La plateforme doit employer différentes optimisations par l'IA pour optimiser les performances :
- Optimisation des requêtes : la plateforme doit appliquer des techniques d'optimisation par machine learning pour accélérer l'exécution des requêtes. Elle peut s'appuyer sur l'indexation automatique, la mise en cache et la poussée des prédicats pour garantir le traitement efficace des requêtes et produire rapidement des insights.
- Dimensionnement automatique : la plateforme doit faire évoluer les ressources serverless de façon intelligente en fonction de vos charges de travail. De cette manière, vous ne payez que pour le calcul que vous utilisez, tout en bénéficiant de performances optimales pour les requêtes.
- Performance des requêtes : la plateforme doit assurer, directement sur le data lake, des performances extrêmement élevées à faible coût, de l'ingestion des données aux requêtes interactives, en passant par l'ETL, le streaming et la data science.
- Delta Lake : la plateforme doit utiliser des modèles d'IA pour résoudre les difficultés typiques du stockage des données. Elle vous offrira ainsi des performances supérieures sans que vous n'ayez à gérer les tables manuellement, même si elles changent au fil du temps.
- Optimisation prédictive : organise automatiquement vos données pour parvenir au meilleur rapport prix-performance. Elle apprend vos habitudes d'utilisation, élabore un plan d'optimisation puis le met à exécution sur une infrastructure serverless hyperoptimisée.
Défis des data warehouses traditionnels
Les data warehouses traditionnels présentent des inconvénients supplémentaires :
- Prise en charge limitée, voire nulle des données non structurées telles que les images, le texte, les données IoT ou les frameworks de messagerie comme HL7, JSON et XML. Les data warehouses traditionnels ne peuvent accueillir que des données nettoyées et fortement structurées, alors que, selon Gartner, jusqu'à 80 % des données d'une organisation sont non structurées. Les organisations qui veulent exploiter leurs données non structurées pour profiter de la puissance de l'IA devront regarder ailleurs.
- Pas de prise en charge de l'IA et du machine learning : les data warehouses sont spécifiquement créés et optimisés pour les charges courantes d'entreposage – rapports historiques, BI et interrogation. Mais ils n'ont jamais été conçus ni pensés pour prendre en charge le machine learning.
- SQL seulement : les data warehouses ne prennent généralement pas en charge les langages Python et R, particulièrement appréciés des développeurs d'applications, des data scientists et des ingénieurs en machine learning.
- Duplication des données : de nombreuses entreprises exploitent des data warehouses et des data marts dédiés à des domaines ou des services spécifiques, en plus de leur data lake. Le résultat : de nombreuses duplications, des processus ETL redondants et aucune source unique de vérité.
- Synchronisation difficile : synchroniser deux exemplaires des données entre le data lake et le data warehouse ajoute une couche de complexité et de fragilité difficile à gérer. Cette dérive des données peut être source d'incohérences dans les rapports et d'erreurs dans les analyses.
- Des formats fermés et propriétaires qui rendent tributaire du fournisseur : la plupart des data warehouses d'entreprise utilisent leur propre format de données plutôt que des formats standards et ouverts. Les utilisateurs se retrouvent étroitement liés à leur fournisseur : il devient difficile, voire impossible, d'analyser les données avec d'autres outils et de les migrer vers d'autres plateformes.
- Coût : les data warehouses commerciaux facturent le stockage des données et l'analyse. Les coûts de stockage et de calcul sont donc étroitement liés. En séparant le calcul et le stockage avec un lakehouse, il devient possible de faire évoluer les deux indépendamment, selon les besoins.
- Solutions de rapport séparées : vous devez souvent poser des questions simples à vos données (« Quel est le chiffre des ventes au 3e trimestre ? », par exemple) sans pouvoir compter sur les fonctionnalités d'une véritable solution de rapport distincte.
- Dépendance vis-à-vis du format de table : vous avez besoin de flexibilité pour répondre aux besoins de vos domaines d'activité et de vos différents cas d'usage, mais certains data warehouses vous contraignent à utiliser un format spécifique (c'est le cas d'Apache Iceberg, par exemple).
Formats de table propriétaires
Le format de table est la principale technologie qui confère les avantages du data warehouse au data lake. Les formats de table organisent les données et les métadonnées de manière à représenter l'état d'une table au fil du temps.
On trouve souvent des formats de table propriétaires dans les environnements cloud où il est crucial d'assurer un accès efficace à de grands datasets pour des tâches comme l'analytique, la création de rapports et le machine learning. Certains fournisseurs créent des formats ou des structures de fichiers pour résoudre des problèmes spécifiques : réduire la taille du stockage, augmenter les vitesses de lecture et d'écriture ou ajouter du contrôle de versions.
Delta Lake, le format propriétaire de Databricks, est une couche de gestion et de gouvernance des données open source et en format ouvert qui réunit les avantages des data lakes et des data warehouses. Il se distingue par plusieurs caractéristiques :
- Transactions ACID : Delta Lake assure la cohérence des données, même pendant les opérations simultanées de mise à jour, de suppression et d'insertion. Grâce à cela, vos données sont toujours à jour et cohérentes.
- Métadonnées évolutives : quand le volume des datasets augmente, Delta Lake s'étend également et permet aux utilisateurs de stocker des métadonnées dans des tables. Cette approche facilite le suivi et le partage des modifications de données.
- Application des schémas : Delta Lake veille à ce que toutes vos données respectent un format spécifique de table.
- Compatibilité Apache Spark™ : comme Delta Lake est open source, il est compatible avec les API Apache Spark. Vous pouvez utiliser Delta Lake dans vos applications Spark sans modifier votre code.
Pour éviter de dépendre du format de table ouvert (OTF) ou de devoir choisir entre Delta Lake et Apache Iceberg, vous pouvez opter pour un format universel comme Delta Lake UniForm.
Multi-cloud
Il se peut que les données de votre organisation soient réparties sur plusieurs fournisseurs de cloud, dans un souci d'optimisation des coûts ou pour répondre aux besoins spécifiques de votre dataset. Cela peut devenir un problème si les données sont gérées sur des réseaux distincts et stockées selon des schémas différents.
Une architecture de lakehouse moderne peut gérer les données sur plusieurs fournisseurs de services cloud, sans dépendre d'un système cloud unique. Pour votre organisation, les avantages sont multiples :
- Distribution des données : en répartissant les données sur plusieurs plateformes cloud, votre entreprise peut trouver la collection de services la mieux adaptée à son budget et ses obligations de conformité.
- Résilience renforcée : les environnements multi-cloud améliorent la disponibilité des données en répartissant les charges et les sauvegardes sur plusieurs fournisseurs. Cela peut même devenir crucial en cas de panne ou d'interruption d'un service cloud.
- Intégration des données : un data warehouse qui prend en charge le multi-cloud peut également intégrer les données de ces différentes sources en temps réel, pour vous donner accès à des données de qualité et améliorer vos décisions.
- Conformité : l'architecture multi-cloud peut vous aider à satisfaire des exigences légales et réglementaires particulières concernant la localisation géographique de vos données et leur répartition sur plusieurs services cloud.
Les défis des data warehouses intelligents
Les data warehouses intelligents présentent leur propre lot de défis :
- Cette approche moderne n'a pas atteint sa forme définitive, et l'organisation doit être prête à faire évoluer sa stratégie.
- Politiques relatives à l'IA : votre organisation doit établir des politiques pour déterminer quelles personnes et quels systèmes peuvent utiliser les fonctions d'IA d'un data warehouse intelligent.
Quelles sont les solutions de Databricks pour l'entreposage des données ?
Databricks propose un data warehouse intelligent, Databricks SQL, qui repose sur l'architecture ouverte du data lakehouse. Databricks SQL fait partie d'une plateforme intégrée, la Data Intelligence Platform, qui englobe le ML, des workflows, la gouvernance des données et bien d'autres fonctions. En utilisant un socle ouvert et unifié pour toutes vos données, vous bénéficiez de capacités d'IA/ML, de streaming, d'orchestration, d'ETL et d'analytique en temps réels. Cela est adossé à un entreposage des données qui rassemble la sécurité, la gouvernance et le catalogage. Un système de stockage unifié assure la fiabilité et le partage des données. Et tout ceci, sur la même plateforme. D'autre part, comme la Databricks Data Intelligence Platform repose sur une architecture ouverte de data lakehouse, vous pouvez y stocker toutes vos données brutes : journaux, textes, fichiers audio, vidéos et images.
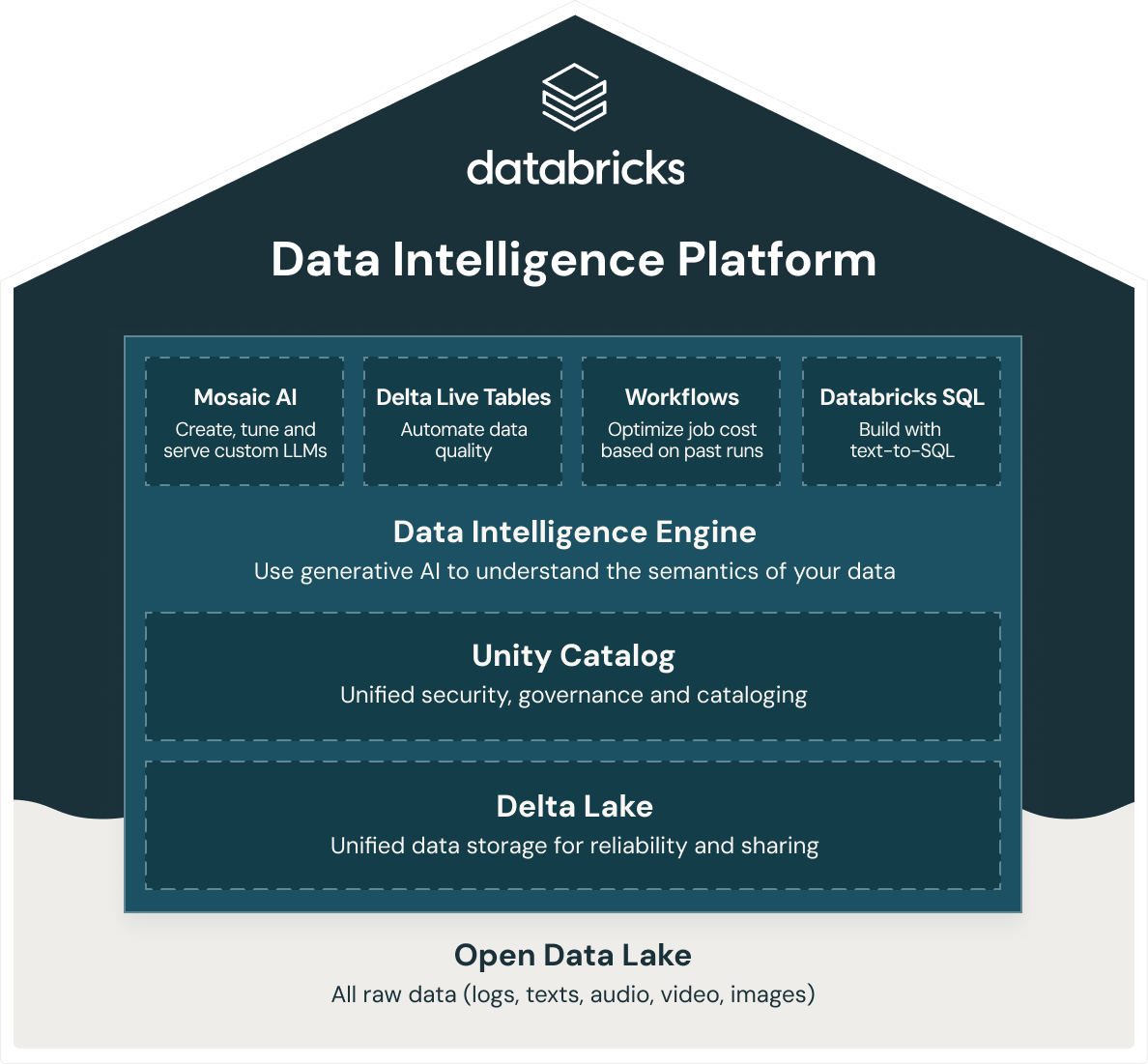
Pour créer un lakehouse performant, les organisations misent sur Delta Lake, une couche de gestion et de gouvernance des données open source et en format ouvert qui cumule les avantages des data lakes et des data warehouses. La Databricks Data Intelligence Platform utilise Delta Lake pour offrir :
- Des performances record de data warehouse pour le prix d'un data lake
- Du calcul SQL serverless qui élimine toute gestion d'infrastructure
- Une intégration transparente avec la pile de données moderne, telle que dbt, Tableau, PowerBI, Fivetran, pour importer, interroger et transformer les données in situ
- Une expérience de développement SQL de premier ordre pour tous les professionnels des données de votre organisation, avec prise en charge de l'ANSI-SQL
- Une gouvernance détaillée avec data lineage, balisage au niveau des tables et des lignes, contrôle d'accès basé sur les rôles et plus encore
- Un moteur d'intelligence des données basé sur l'IA pour comprendre la sémantique de vos données