Extraire, transformer, charger (ETL)

Qu'est-ce que l'ETL ?
La quantité de données, de sources et de types de données ne cesse d'augmenter, tout comme l'importance de les exploiter dans le cadre d'initiatives d'analytique, de data science et de machine learning pour en tirer des insights stratégiques. Face à ces impératifs, les équipes de data engineering sont sous pression : la conversion de données brutes et désordonnées en données utilisables, fiables et à jour représente en effet une étape préalable cruciale. L'ETL, qui signifie « extract, transform and load », soit « extraire, transformer, charger », est justement le processus employé pour extraire les données de différentes sources, les transformer en ressource opérationnelle et fiable, et les charger dans des systèmes accessibles et utilisables en aval pour résoudre des problèmes métier.
Poursuivez votre exploration



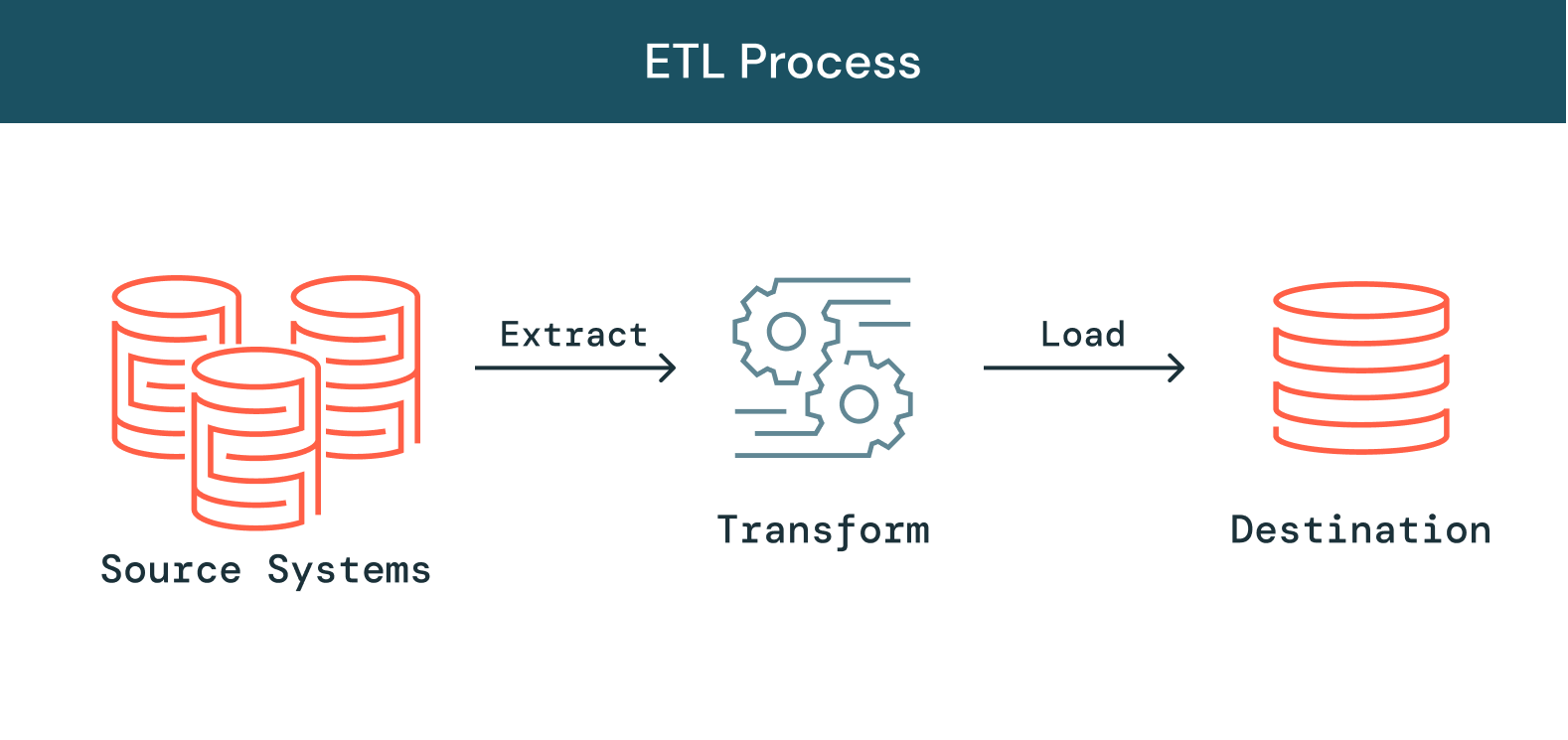
Comment fonctionne l'ETL ?
Extraire
La première étape du processus consiste à extraire les données des sources cibles, qui sont généralement hétérogènes : systèmes métier, API, données de capteur, outils marketing, bases de données de transactions, etc. Comme vous pouvez le voir, certains types de données peuvent être les sorties structurées de systèmes courants, tandis que d'autres sont des logs de serveur JSON semi-structurés. L'extraction peut se faire de différentes façons :
-
Extraction partielle : c'est quand le système source vous informe qu'un enregistrement a été modifié que l'obtention des données est la plus facile.
-
Extraction partielle (avec notification de mise à jour) : les systèmes ne peuvent pas tous envoyer une notification en cas de modification. En revanche, ils peuvent pointer vers les enregistrements en question et en fournir un extrait.
-
Extraction totale : certains systèmes sont totalement incapables d'identifier quelles données ont été modifiées. Dans ce cas, l'extraction complète est la seule possibilité pour sortir des données du système. Cette méthode impose de posséder un exemplaire de la dernière extraction au même format, afin de repérer les modifications apportées.
Transformer
La deuxième étape consiste à transformer les données brutes extraites des sources sous une forme utilisable par différentes applications. À ce stade, les données sont nettoyées, mappées et transformées, souvent selon un schéma spécifique pour répondre aux besoins opérationnels. Ce processus implique plusieurs types de transformation qui assurent la qualité et l'intégrité des données. Généralement, les données ne sont pas directement chargées dans la source de destination : il est courant de les charger dans une base de données de préparation. Cette étape permet d'effectuer une annulation rapide en cas de problème imprévu. Pendant cette phase, vous aurez la possibilité de générer des rapports d'audit à des fins de conformité réglementaire, ou de diagnostiquer et réparer les problèmes de données.
Charger
Enfin, la fonction de chargement consiste à écrire les données converties et stockées dans un emplacement préparatoire dans une base de données de destination, existante ou non. Selon les exigences de l'application, ce processus peut être très simple ou plus complexe. Chacune de ces étapes peut être réalisée à l'aide d'outils ETL ou de code personnalisé.
Qu'est-ce qu'un pipeline ETL ?
Un pipeline ETL (ou pipeline de données) est le mécanisme qui assure le déroulement du processus ETL. Les pipelines de données englobent des outils et des activités permettant de déplacer des données contenues dans un système ayant ses propres méthodes de stockage et de traitement, vers un autre système où elles seront stockées et gérées différemment. De plus, les pipelines permettent d'obtenir automatiquement les données de sources disparates, puis de les transformer et les consolider au sein d'un système de stockage hautement performant.
Les défis de l'ETL
Si l'ETL est un processus essentiel, l'augmentation exponentielle des sources et des types de données fait de l'élaboration et la maintenance de pipelines de données fiables l'un des grands défis du data engineering. Depuis l'origine, la création de pipelines capables d'assurer la fiabilité des données est aussi lente que difficile. Les pipelines de données sont écrits dans un code complexe et il est rarement possible de les réutiliser. Un pipeline écrit pour un environnement ne peut pas être utilisé dans un autre, même si le code sous-jacent est très similaire. Autrement dit, le goulet d'étranglement se situe souvent au niveau des data engineers qui doivent régulièrement réinventer la roue. Au-delà du développement, les architectures de pipelines de plus en plus complexes n'aident pas à gérer la qualité des données. Des données médiocres parviennent souvent à s'infiltrer dans les pipelines à l'insu des équipes et dégradent tout le dataset. Pour maintenir la qualité et garantir la fiabilité des insights, les data engineers doivent écrire du code personnalisé pour implémenter des contrôles de qualité à chaque étape du pipeline. Enfin, face à des pipelines toujours plus complexes et vastes, les entreprises parviennent plus difficilement à gérer la charge opérationnelle. Dans ce contexte, maintenir la fiabilité des données devient mission impossible.Il faut mettre en place une infrastructure de traitement des données, la faire évoluer, la redémarrer, la tenir à jour... Tout cela mobilise du temps et des ressources. En raison du manque de visibilité et d'outillage, les défaillances des pipelines sont difficiles à détecter, et plus encore à résoudre. Malgré tous ces défis, un processus ETL fiable reste absolument crucial pour toute entreprise qui veut s'appuyer sur des insights. Sans outils ETL capables de maintenir une norme de fiabilité des données, les équipes de toute l'organisation devront prendre des décisions à l'aveugle, sans pouvoir compter sur des métriques et des rapports. Pour prendre en charge les volumes croissants de données, les data engineers ont besoin d'outils pour rationaliser et démocratiser l'ETL, simplifier son cycle de vie et exploiter leurs propres pipelines pour obtenir plus rapidement des informations utiles.
Automatisez des processus ETL fiables sur Delta Lake
Delta Live Tables (DLT) facilite la création et la gestion de pipelines fiables fournissant des données de haute qualité sur Delta Lake. DLT aide les équipes de data engineering à simplifier le développement et la gestion ETL avec le développement de pipelines déclaratifs, des tests automatiques et une visibilité approfondie pour le monitoring et la restauration.
