État des données et de l'IA
Data intelligence et course à la personnalisation des LLM

Stratégie de données et d'IA
La course à la démocratisation des données et de l'IA
Toutes les entreprises veulent profiter du potentiel de transformation des initiatives d'IA générative. Et elles tiennent à mettre la puissance de l'intelligence des données entre les mains de tous leurs collaborateurs. Mais quand les informations sont enfermées dans des silos et que leur gestion est fragmentée sur plusieurs outils, les équipes ont souvent des difficultés à mener à bien ces projets.
Aujourd'hui, une question brûlante taraude les décideurs métier : quel est le moyen le plus rapide et le plus efficace de démocratiser l'IA ?
Le rapport sur L'État des données et de l'IA offre une vue d'ensemble des initiatives de données et d'IA actuellement privilégiées par les entreprises. Nous avons analysé les données d'utilisation anonymisées des 10 000 clients qui utilisent aujourd'hui la Databricks Data Intelligence Platform, et parmi lesquels figurent 300 entreprises du Fortune 500. Nous avons ainsi pu établir une vue extrêmement détaillée de leurs progrès dans les efforts pour accélérer l'adoption de l'IA générative au sein de leurs activités, et identifier les outils qui les aident dans cette démarche.
Découvrez comment les acteurs les plus innovants réussissent avec le machine learning, adoptent l'IA g�énérative et répondent à l'évolution des exigences de gouvernance. Vous apprendrez aussi comment votre propre entreprise peut élaborer une stratégie de données adaptée à l'ère de l'IA d'entreprise.
Voici un résumé de nos découvertes :
L'IA est passée en production
Le nombre de modèles d'IA passés en production a été multiplié par 11
Pendant des années, les entreprises ont expérimenté le machine learning (ML), un composant essentiel de l'IA. Beaucoup ont rencontré des difficultés (données cloisonnées, workflows de déploiement complexes, gouvernance, etc.) dans leurs efforts pour traduire leurs expérimentations ML contrôlées en applications concrètes, prêtes pour la production. Aujourd'hui, nous voyons les fruits de ces efforts. Sur l'ensemble des entreprises, le nombre de modèles enregistré en production a augmenté de 1 018 % par rapport à l'année dernière. D'ailleurs, pour la toute première fois dans nos recherches, la croissance des modèles enregistrés a été plus rapide que celle des expérimentations consignées, qui atteint tout de même 134 %.
Mais en matière de ML, les besoins et les objectifs varient d'une industrie à l'autre. Nous avons étudié six secteurs clés pour mieux comprendre ces tendances, en examinant le rapport entre expérimentation et enregistrement de modèles. Nos conclusions ? Les trois secteurs les plus efficaces mettent 25 % de leurs modèles en production.
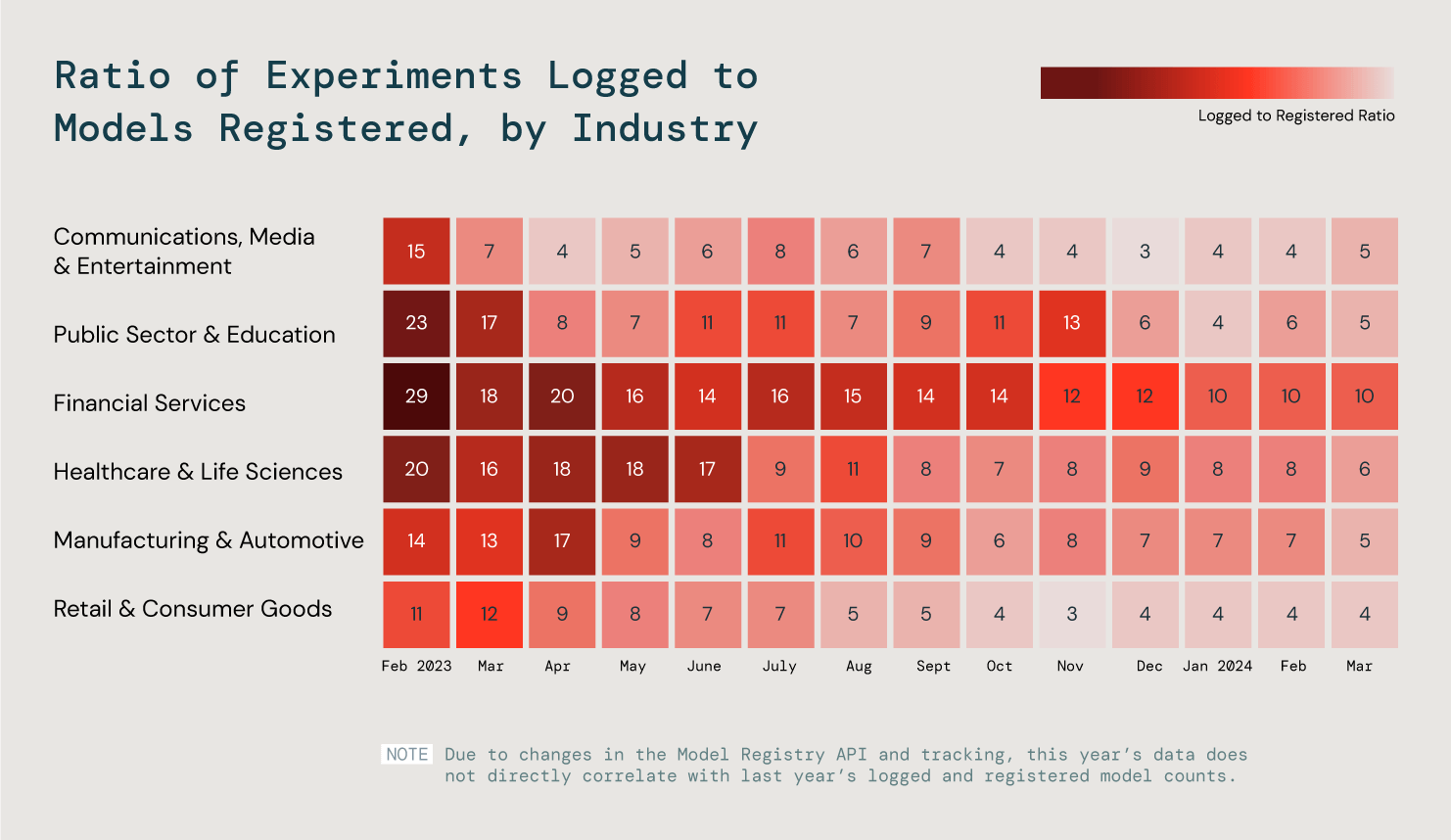
Nous avons analysé le rapport entre expérimentation et enregistrement de modèles chez tous nos clients afin d'évaluer les progrès du ML en production.
C'est en production que l'IA révèle toute sa valeur, que le produit s'adresse à des équipes internes ou à des clients. Nous pensons que le succès croissant du ML va ouvrir la voie à de brillantes réussites dans la création d'applications d'IA générative prêtes pour la production.
Personnalisation des LLM
L'utilisation des bases de données vectorielles a augmenté de 377 %
Les entreprises progressent sur leur parcours d'IA générative, et elles tendent de plus en plus à personnaliser les LLM existants en fonction de leurs besoins propres, généralement en exploitant leurs données privées.
La génération augmentée par récupération (RAG) est un mécanisme essentiel pour les entreprises qui veulent accroître les performances des LLM open source et propriétaires. Pour la RAG, une base de données vectorielle sert à entraîner les modèles sous-jacents sur des données privées afin de produire des résultats plus précis, en phase avec les opérations d'une organisation.
Et cette personnalisation est une priorité pour les entreprises. L’utilisation des bases de données vectorielles a augmenté de 377 % au cours de l'année écoulée.
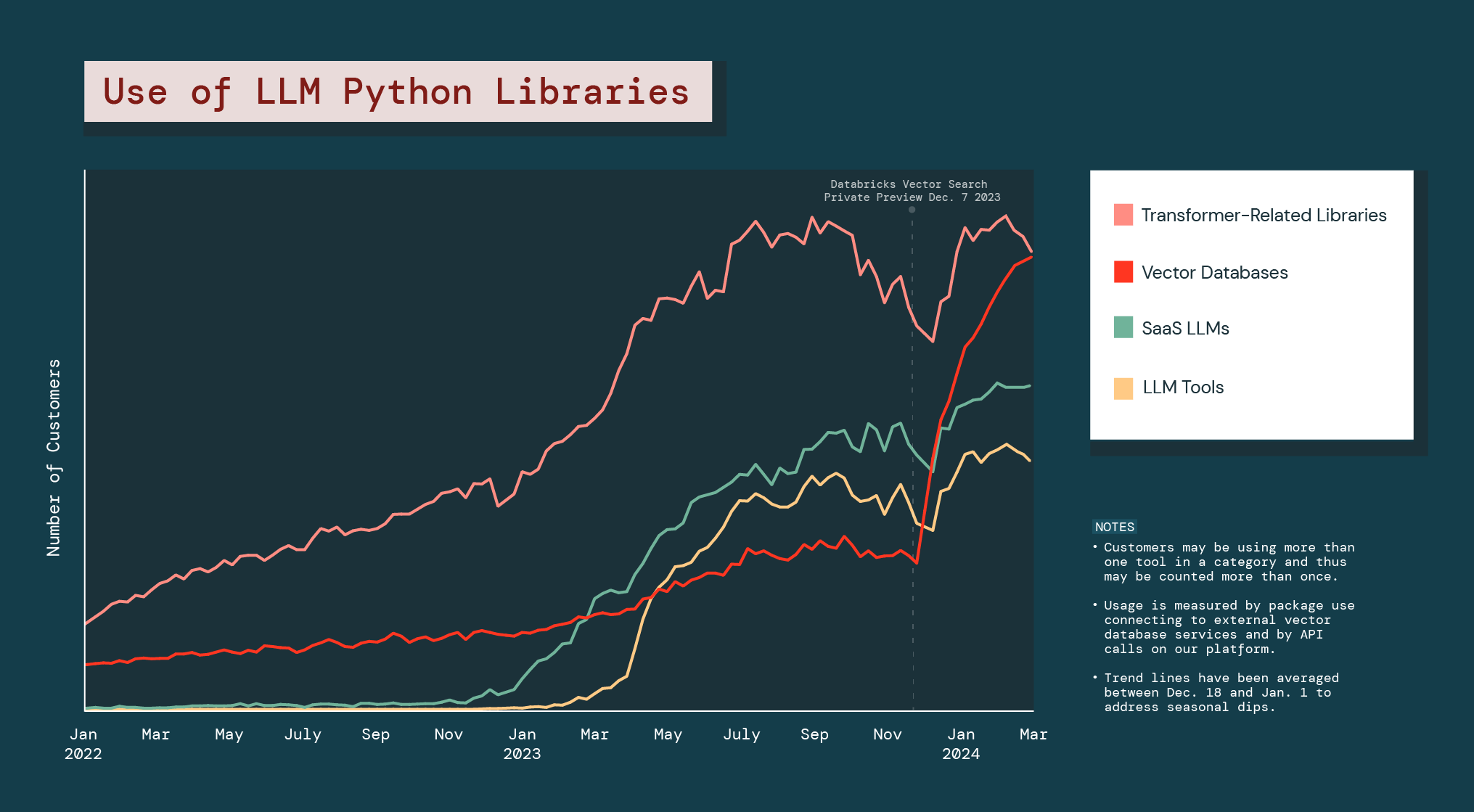
Depuis le lancement en accès anticipé de Databricks Vector Search, l'ensemble de la catégorie des bases de données vectorielles a affiché une croissance de 186 %, bien supérieure à celle de toute autre bibliothèque Python pour LLM.
L'explosion des bases de données vectorielles confirme que les entreprises cherchent des alternatives à l'IA générative afin de résoudre des problèmes ou de poursuivre des opportunités propres à leur activité. Elle laisse également penser qu'elles vont utiliser différents types de modèles d'IA générative dans leurs opérations.
LLM open source
Les entreprises privilégient les petits modèles
L'un des grands avantages des LLM open source, en particulier pour les entreprises, est qu'ils peuvent être personnalisés et adaptés à des cas d'usage spécifiques. Dans la pratique, les clients étudient souvent un grand nombre de modèles et de familles de modèles. Nous avons analysé l'utilisation des modèles open source de Meta Llama et de Mistral, les deux plus grands acteurs dans le domaine.
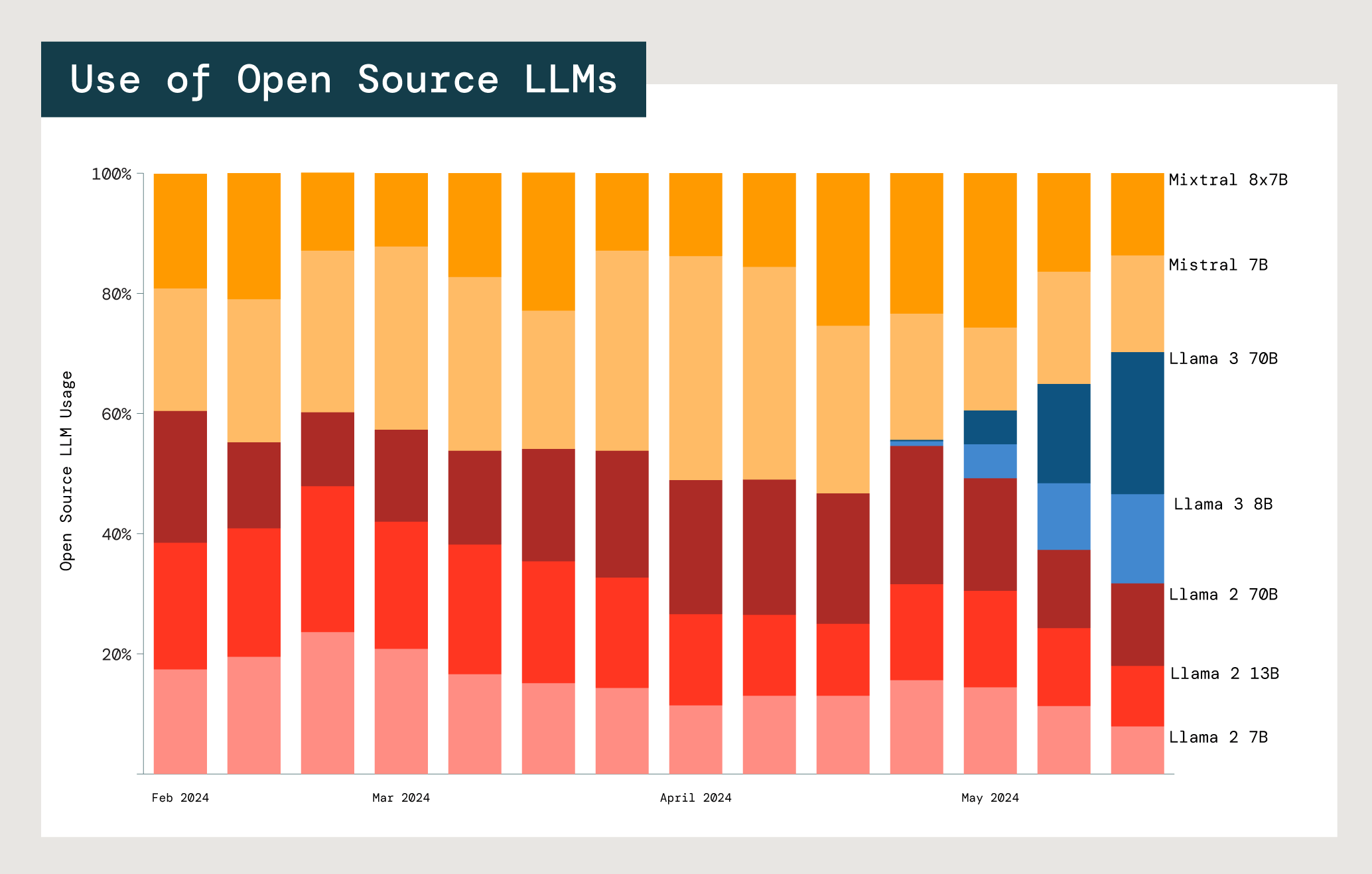
Adoption relative des modèles open source Mistral et Meta Llama dans les API des modèles de fondation Databricks.
Chaque modèle est un compromis entre coût, latence et performance. L'utilisation des deux plus petits modèles Meta Llama 2 (7B et 13B) est très largement supérieure à celle du plus grand modèle, Meta Llama 2 70B. Chez les utilisateurs de Llama comme ceux de Mistral, les modèles qui comptent 13 milliards ou moins de paramètres sont privilégiés à 77 %. Cela suggère que les entreprises mettent le coût et les avantages de la taille d'un modèle dans la balance pour choisir celui qui sera le plus adapté à leur cas d'usage.
