AdaGrad
La descente de gradient est la méthode d'optimisation la plus couramment employée par les algorithmes de machine learning et de deep learning. Elle est utilisée pour entraîner les modèles de machine learning.
Types de descente de gradient
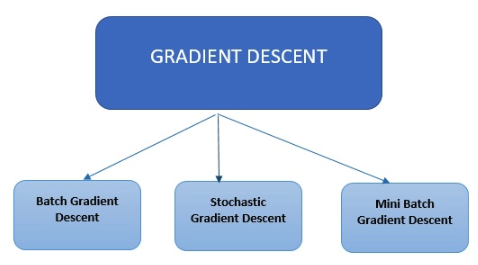 Les algorithmes modernes de machine learning et de deep learning utilisent trois principaux types de descente de gradient.
Les algorithmes modernes de machine learning et de deep learning utilisent trois principaux types de descente de gradient.
Descente de gradient par lots
La descente de gradients par lot est le type le plus simple. Elle calcule l'erreur de chaque exemple du dataset d'entraînement, mais ne met à jour le modèle qu'une fois tous les exemples d'entraînement évalués.
Descente de gradient stochastique
La descente de gradient stochastique calcule l'erreur et met à jour le modèle à chaque exemple du dataset d'entraînement.
Descente de gradient par mini-lots
La descente de gradient par mini-lots ne parcourt pas tous les exemples : elle fait un résumé sur un échantillon en fonction de la taille des lots et procède à une mise à jour pour chacun d'entre eux. La descente de gradient stochastique est une méthode courante d'optimisation. Son concept est simple et elle peut généralement être mise en œuvre avec une grande efficacité. Il faut toutefois ajuster un paramètre, la taille du pas. Plusieurs options ont été proposées pour automatiser cet ajustement. L'une d'entre elles, AdaGrad, offre de bons résultats. Les méthodes classiques de sous-gradient stochastique suivent principalement un schéma procédural prédéterminé qui ne tient pas compte des données observées. À l'inverse, les algorithmes AdaGrad incorporent dynamiquement la connaissance de la géométrie des données observées lors des précédentes itérations pour effectuer un apprentissage plus informatif, basé sur le gradient. Deux versions d'AdaGrad ont été publiées. L'AdaGrad diagonal (la version la plus utilisée en pratique) a pour principal atout de maintenir et d'adapter un taux d'apprentissage par dimension. L'autre version, l'AdaGrad complet, maintient un taux d'apprentissage par direction (par exemple, une matrice PSD complète). L'algorithme de gradient adaptatif (AdaGrad) est un algorithme d'optimisation basée sur le gradient. Le taux d'apprentissage est adapté aux paramètres par composant en incorporant les connaissances acquises lors des précédentes observations. Les mises à jour sont plus volumineuses (par exemple, pour des taux d'apprentissage élevés) pour les paramètres liés à des fonctionnalités peu fréquentes. Elles sont plus réduites (par exemple, pour des taux d'apprentissage faibles) quand il s'agit de fonctionnalités fréquentes. Les mises à jour sont réduites. Par conséquent, cet algorithme convient idéalement aux données éparses (traitement du langage naturel ou reconnaissance d'image). Chaque paramètre a son propre taux d'apprentissage, ce qui améliore les performances sur les problèmes liés aux gradients épars.
Les avantages d'AdaGrad
- AdaGrad élimine l'ajustement manuel du taux d'apprentissage
- La convergence est plus rapide et plus fiable qu'avec la descente de gradient stochastique lorsque la mise à l'échelle des pondérations est inégale
- Il est peu sensible à la taille du pas principal