Apache Kylin
Qu'est-ce qu'Apache Kylin ?
Apache Kylin est un moteur de traitement analytique en ligne (OLAP) distribué et open source pour l'analyse interactive des grands volumes de données. Apache Kylin a été conçu pour fournir une interface SQL et des possibilités d'analyse multidimensionnelle (OLAP) sur Hadoop/Spark. Il a également l'avantage de s'intégrer facilement avec les outils de BI via les pilotes ODBC et JDBC, ainsi que l'API REST. Créé par eBay en 2014, il est devenu un projet de haut niveau de l'Apache Software Foundation un an plus tard, en 2015. Il a remporté le prix du meilleur outil bog data open source en 2015 et 2016. Aujourd'hui, il est utilisé par des milliers d'entreprises dans le monde comme application analytique stratégique pour les big data. Quand d'autres moteurs OLAP peinent face à d'importants volumes de données, Kylin répond aux requêtes en quelques millisecondes. Il atteint une latence inférieure à la seconde pour les requêtes portant sur des pétaoctets de données. Pour atteindre cette vitesse exceptionnelle, le moteur précalcule les différentes combinaisons dimensionnelles et les agrégats de mesures via des requêtes Hive, puis injecte les résultats dans la HBase. 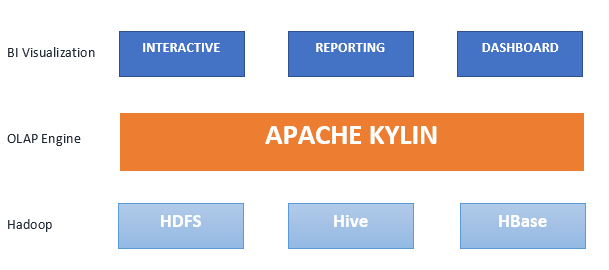
Comment fonctionne Apache Kylin ?
Le moteur de requête Kylin, accessible via l'interface utilisateur conviviale de Kylin, une API ou JDBC, exploite le processeur de requête Apache Calcite et les fonctionnalités HBase pour accélérer les recherches. Kylin s'appuie sur l'écosystème Hadoop :
- Hive : source d'entrée ; jointure préliminaire du schéma en étoile pendant la construction du cube
- MapReduce : agrégation des métriques pendant la construction du cube
- HDFS : stockage des fichiers intermédiaires pendant la construction du cube
- HBase : stockage et interrogation des cubes de données
- Calcite : analyse SQL, génération de code, optimisation Quel est l'intérêt d'Apache Kylin pour votre organisation ?
- Un moteur OLAP très rapide à grande échelle : Kylin est conçu pour réduire à quelques secondes la latence des requêtes sur Hadoop avec plus de 10 milliards de lignes de données
- Interface SQL ANSI sur Hadoop : Kylin intègre ANSI SQL à Hadoop et prend en charge la plupart des fonctions de requête ANSI SQL. Aucune programmation n'est nécessaire : il est directement utilisable par les analystes et les ingénieurs.
- Intégration transparente avec les outils de BI : Kylin offre actuellement des possibilités d'intégration avec des outils de BI comme Tableau, JDBC/ODBC et les API REST
- Requêtes interactives : les utilisateurs interagissent avec les données Hadoop via Kylin avec une latence inférieure à la seconde
- Service de requêtes de cube MOLAP portant sur plusieurs milliards de lignes : les utilisateurs peuvent définir un modèle de données et le prédéfinir dans Kylin même s'il compte plus de 10 milliards d'enregistrements de données brutes.
Pilote ODBC open source : le pilote ODBC de Kylin a été développé à partir de zéro et s'accorde très bien avec Tableau.