engineering des fonctionnalités
Ingénierie de fonctionnalité pour le machine learning
L'ingénierie de fonctionnalité, également appelée prétraitement des données, consiste à convertir les données brutes en fonctionnalités utilisables pour développer des modèles de machine learning. Cette rubrique décrit les principaux concepts de l'ingénierie de fonctionnalité et le rôle qu'elle joue dans la gestion du cycle de vie du ML.
Dans le contexte du machine learning, les fonctionnalités sont les données d'entrées utilisées pour entraîner un modèle. Elles représentent les attributs d'une entité qui fait l'objet de l'apprentissage du modèle. Les données brutes doivent généralement être prétraitées avant d'être utilisées dans un modèle de ML. Bien réalisée, l'ingénierie de fonctionnalité accroît l'efficacité du développement du modèle et produit des modèles plus simples, plus flexibles et plus précis.
Qu'est-ce que l'ingénierie de fonctionnalité ?
L'ingénierie de fonctionnalité consiste à transformer et enrichir les données pour améliorer les performances des algorithmes de machine learning employés pour entraîner les modèles sur ces données.
L'ingénierie de fonctionnalité comprend plusieurs étapes : mise à l'échelle ou normalisation des données, encodage des données non numériques (texte, images, etc.), agrégation des données en fonction du temps et de l'entité, regroupement des données de différentes sources, et même transfert des connaissances acquises par d'autres modèles. Ces transformations ont un objectif : accroître la capacité des algorithmes de machine learning à apprendre du dataset, et donc à faire des prédictions plus précises.
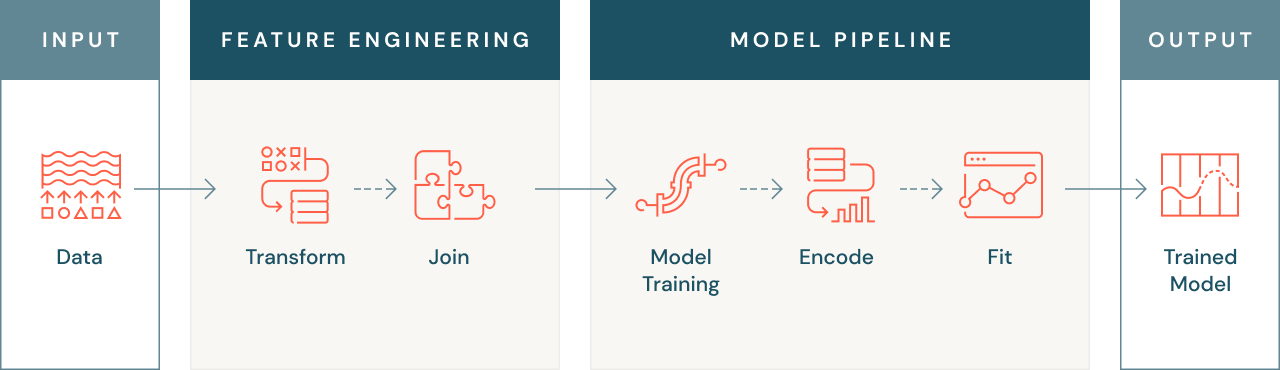
Pourquoi l'ingénierie de fonctionnalité a-t-elle une telle importance ?
L'ingénierie de fonctionnalité joue un rôle décisif à plusieurs titres. Tout d'abord, comme cela a été mentionné plus tôt, les modèles de machine learning ne peuvent pas toujours exploiter des données brutes. Les données doivent donc être converties dans une forme numérique compréhensible par le modèle. Il peut s'agir de convertir du texte ou des images sous forme numérique, ou bien de créer des fonctionnalités agrégées, comme la valeur moyenne des transactions d'un client.
Il peut arriver que les fonctionnalités d'un problème de machine learning soient présentes sur plusieurs sources de données. Dans ce cas, une ingénierie de fonctionnalité efficace va joindre ces sources pour créer un dataset unique. Cette opération vous permet d'utiliser toutes les données disponibles pour entraîner votre modèle, ce qui peut accroître sa précision et sa performance.
Autre scénario courant : les résultats et l'apprentissage d'autres modèles peuvent parfois être réutilisés sous la forme de fonctionnalités et mis au service d'un nouveau problème – c'est ce qu'on appelle l'apprentissage par transfert. Cette opération permet d'exploiter les connaissances acquises par les modèles précédents pour améliorer les performances d'un nouveau modèle. L'apprentissage par transfert s'avère particulièrement utile lorsqu'il s'agit de traiter des datasets à la fois vastes et complexes pour lesquels il n'est pas pratique d'entraîner un modèle à partir de zéro.
Une ingénierie de fonctionnalité efficace est également un gage de fiabilité des fonctionnalités au moment de l'inférence, quand le modèle est utilisé pour émettre des prédictions sur de nouvelles données. Cet aspect n'est pas à négliger, car les fonctionnalités employées au moment de l'inférence doivent être identiques à celles qui ont servi au moment de l'entraînement, afin d'éviter toute déformation « en ligne/hors ligne ». Ce type de déformation survient quand les fonctionnalités utilisées au moment de la prédiction ne sont pas celles ayant servi lors de l'entraînement.
En quoi l'ingénierie de fonctionnalité se distingue-t-elle des autres transformations ?
L'objectif de l'ingénierie de fonctionnalité est de créer un dataset pouvant servir à la création d'un modèle de machine learning. Nombre d'outils et de techniques employés pour transformer les données servent également en ingénierie de fonctionnalité.
Comme l'ingénierie de fonctionnalité est avant tout axée sur le développement d'un modèle, elle a certaines exigences qui ne sont pas présentes dans toutes les transformations. Par exemple, vous souhaiterez peut-être réutiliser les fonctionnalités dans différents modèles ou les partager avec d'autres équipes de votre organisation. Il vous faudra donc une méthode robuste pour découvrir les fonctionnalités.
De plus, en cas de réutilisation des fonctionnalités, vous aurez besoin d'un moyen de suivre la façon dont elles sont calculées, et à quels endroits. C'est ce qu'on appelle la généalogie, ou lineage, des fonctionnalités. Le machine learning a besoin de calculs de fonctionnalité reproductibles. En effet, la fonctionnalité ne doit pas seulement être calculée pour entraîner le modèle : elle doit aussi être recalculée de façon parfaitement identique au moment où le modèle est utilisé à des fins d'inférence.
Quels sont les avantages d'une ingénierie de fonctionnalité efficace ?
Un pipeline efficace d'ingénierie de fonctionnalité est synonyme de pipelines de modélisation plus robustes et, en fin de compte, de modèles plus performants et plus fiables. En améliorant les fonctionnalités utilisées pour l'entraînement et l'inférence, vous pouvez fortement influencer la qualité des modèles. Autrement dit, d'excellentes fonctionnalités font d'excellents modèles.
Pour prendre un autre point de vue, une ingénierie de fonctionnalité efficace encourage également la réutilisation. Cela permet non seulement aux professionnels de gagner du temps, mais aussi d'améliorer la qualité de leurs modèles.La réutilisation des fonctionnalités est importante pour deux raisons : elle permet de gagner du temps et elle évite les déformations « en ligne/hors ligne ». En effet, elle empêche vos modèles d'utiliser des données de fonctionnalité différentes entre l'entraînement et l'inférence, en mettant en avant des fonctionnalités robustes et bien définies.
Quels sont les outils de l'ingénierie de fonctionnalité ?
On utilise généralement les mêmes outils en data engineering et en ingénierie de fonctionnalité, car la plupart des transformations sont communes aux deux pratiques. Cela implique habituellement un système de stockage et de gestion des données, l'accès à un langage de transformation ouvert et standard (SQL, Python, Spark, etc.) et l'accès à une ressource de calcul pour exécuter les transformations.
Il existe toutefois des outils particulièrement utiles à l'ingénierie de fonctionnalité, notamment des bibliothèques Python spécialisées qui peuvent faciliter certaines transformations propres au machine learning (intégration de texte ou d'images, encodage one-hot de variables catégoriques, etc.). Vous trouverez également des projets open source qui facilitent le suivi des fonctionnalités utilisées par un modèle.
La gestion des versions des données est essentielle pour l'ingénierie de fonctionnalité, car il arrive souvent que les modèles soient entraînés sur un dataset qui a été modifié entre-temps. Un bon suivi des versions des données vous aide à reproduire un modèle particulier, en dépit de l'évolution naturelle de vos données au fil du temps.
Qu'est-ce qu'un magasin de fonctionnalités ?
Un magasin de fonctionnalités est un outil pensé pour relever les défis de l'ingénierie de fonctionnalité. C'est un dépôt centralisé qui rassemble toutes les fonctionnalités d'une organisation. Les data scientists peuvent utiliser un tel espace pour découvrir et partager des fonctionnalités, et suivre leur lineage. Un magasin de fonctionnalités garantit également l'utilisation des mêmes valeurs au moment de l'entraînement et de l'inférence. Le machine learning a besoin de calculs de fonctionnalité reproductibles. En effet, la fonctionnalité ne doit pas seulement être calculée pour entraîner le modèle : elle doit aussi être recalculée de façon parfaitement identique au moment où le modèle est utilisé à des fins d'inférence.
Pourquoi utiliser le magasin de fonctionnalités Databricks ?
Le magasin de fonctionnalités Databricks est entièrement intégré aux autres composants de Databricks. Vous pouvez utiliser les notebooks Databricks pour développer du code afin de créer des fonctionnalités, puis élaborer des modèles en vous appuyant sur ces fonctionnalités. Lorsque vous mettez des modèles à disposition avec Databricks, ils recherchent automatiquement les valeurs des fonctionnalités dans le magasin correspondant pour émettre des inférences. Le magasin de fonctionnalités Databricks offre également les avantages décrits dans cet article :
- Découvrabilité. L'interface du magasin de fonctionnalités, accessible depuis l'espace de travail Databricks, vous permet de parcourir et de rechercher des fonctionnalités.
- Lineage. Lorsque vous créez une table de fonctionnalité avec le magasin de fonctionnalités Databricks, les sources de données utilisées sont enregistrées et restent accessibles. Pour chaque fonctionnalité d'une table, vous pouvez également accéder aux modèles, notebooks, tâches et terminaisons qui l'exploitent.
Les autres atouts du magasin de fonctionnalités Databricks :
- Intégration à l'évaluation et la mise à disposition des modèles. Lorsque vous utilisez des fonctionnalités provenant du magasin de fonctionnalités Databricks pour entraîner un modèle, celui-ci embarque les métadonnées des fonctionnalités. Et quand vous utilisez le modèle pour évaluer un batch ou émettre des inférences en ligne, il récupère automatiquement les fonctionnalités dans le magasin de fonctionnalités Databricks. L'appelant n'a pas besoin de savoir de quoi il s'agit, ni d'inclure une logique pour rechercher et joindre les fonctionnalités afin d'évaluer les nouvelles données. Cette méthode simplifie considérablement le déploiement et la mise à jour des modèles.
- Recherches à des points spécifiques du temps. Le magasin de fonctionnalités prend en charge les séries chronologiques et les cas d'usage reposant sur des événements, qui nécessitent une correction ponctuelle.