Grands modèles de langage (LLM)
Que sont les grands modèles de langage (LLM) ?
Les modèles de langage sont un type d'IA générative (GenAI) qui utilisent le traitement du langage naturel (NLP) pour comprendre et générer le langage humain. Les grands modèles de langage (LLM) en sont les plus puissants. Les LLM sont entraînés à partir de dataset massifs à l'aide d'algorithmes de machine learning (ML) avancés pour apprendre les motifs et les structures du langage humain et générer des réponses textuelles à des invites écrites. Parmi les exemples de LLM, on peut citer BERT, Claude, Gemini, Llama et la famille de LLM Generative Pretrained Transformer (GPT).
Les LLM ont largement dépassé leurs prédécesseurs en termes de performances et de capacités dans diverses tâches liées au langage. Leur capacité à générer du contenu complexe et nuancé et à automatiser des tâches pour obtenir des résultats comparables à ceux d'un humain est à l'origine de progrès dans divers domaines. Les LLM sont largement intégrés dans le monde de l'entreprise pour avoir un impact dans divers environnements et cas d'utilisation métier, notamment l'automatisation du support, la découverte d'insights et la génération de contenu personnalisé.
Les principales capacités des LLM en matière d'IA et de langage sont les suivantes :
- Compréhension du langage naturel : les LLM peuvent comprendre les nuances du langage humain, y compris le contexte, la sémantique et l'intention.
- Génération de contenu multimodal : Les LLM peuvent produire un texte de type humain à des fins diverses, allant du codage à la rédaction créative, ainsi que des images, de la parole et bien plus encore.
- Réponse aux questions : les LLM peuvent répondre intelligemment à des questions ouvertes.
- Monter en charge : Les LLM peuvent tirer parti des capacités des processeurs graphiques (GPU) pour prendre en charge efficacement des tâches linguistiques à grande échelle et s'adapter aux besoins croissants de l'entreprise.
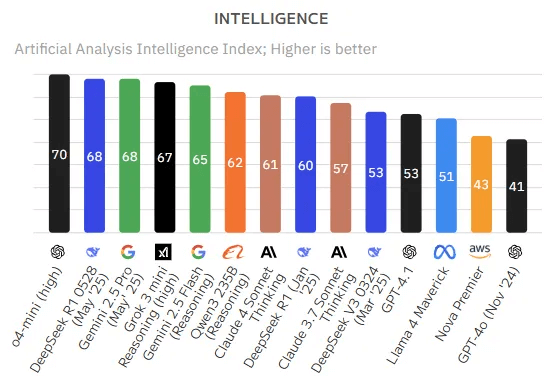
Comment fonctionnent les LLM ?
La plupart des LLM sont construits à l'aide d'une architecture de type transformeur. Ils fonctionnent en divisant le texte d'entrée en jetons (unités de sous-mots), en intégrant ces jetons dans des vecteurs numériques et en utilisant des mécanismes d'attention pour comprendre les relations dans l'ensemble de l'entrée. Ils prédisent ensuite le jeton suivant dans une séquence afin de générer des sorties cohérentes.
Que signifie pré-entraîner les LLM ?
Le pré-entraînement d'un modèle LLM fait référence au processus qui consiste à l'entraîner sur un grand corpus de données, telles que du texte ou du code, sans utiliser de connaissances préalables ou de pondérations d'un modèle existant. Le résultat d'un pré-entraînement complet est un modèle de base qui peut être utilisé directement ou affiné pour des tâches en aval.
Le pré-entraînement garantit que les connaissances fondamentales du modèle sont adaptées à votre domaine spécifique. Le résultat est un modèle personnalisé qui se distingue par les données uniques de votre organisation. Cependant, le pré-entraînement est généralement le type d'entraînement le plus vaste et le plus coûteux, et n'est pas courant pour la plupart des organisations.
Que signifie ajuster finement les LLM ?
Le réglage fin est un processus visant à adapter un LLM pré-entraîné à l'aide d'un dataset relativement plus petit et propre à un domaine ou une tâche en particulier. Au cours du processus de réglage fin, l'entraînement se poursuit sur une courte durée, par exemple en ajustant un nombre de pondérations plus faible que dans le cas du modèle entier.
Les deux formes d'affinement les plus courantes sont :
Réglage fin par instructions supervisées : cette approche consiste à poursuivre l'entraînement d'un LLM pré-entraîné sur un dataset d'exemples d'entrées-sorties, généralement plusieurs milliers.
Pré-entraînement continu : cette méthode d'affinement ne s'appuie pas sur des exemples d'entrées et de sorties, mais utilise plutôt du texte non structuré spécifique à un domaine pour poursuivre le même processus de pré-entraînement (comme la prédiction du jeton suivant et la modélisation du langage masqué).
L'affinement est important, car il permet à une organisation de prendre un LLM de base et de l'entraîner avec ses propres données pour une plus grande précision et une meilleure personnalisation pour le domaine et les charges de travail de l'entreprise. Cette approche vous donne également un contrôle accru sur les données d'entraînement, ce qui est un atout pour l'utilisation responsable de l'IA.
Réseaux de neurones et architecture de transformer
Les LLM reposent sur l'apprentissage profond, une forme d'AI dans laquelle un programme est entraîné à l'aide de grandes quantités de données, sur la base de probabilités. Grâce à leur exposition à des datasets massifs, les LLM peuvent s'entraîner à reconnaître des modèles et des relations linguistiques sans programmation explicite, avec des mécanismes d'auto-apprentissage pour améliorer continuellement leur précision.
Les LLMs reposent sur des réseaux de neurones artificiels, inspirés de la structure du cerveau humain. Ces réseaux se composent de nœuds interconnectés organisés en couches, comprenant une couche d'entrée, une couche de sortie et une ou plusieurs couches intermédiaires. Chaque nœud traite et transmet les informations à la couche suivante en fonction des motifs appris.
Les LLM utilisent un type de réseau de neurones appelé modèle Transformer. Ces modèles révolutionnaires peuvent analyser une phrase entière en une seule fois, contrairement aux anciens modèles qui traitent les mots de manière séquentielle. Cela leur permet de comprendre le langage plus rapidement et plus efficacement. Les modèles Transformer utilisent une technique mathématique appelée auto-attention, qui attribue une importance variable aux différents mots d'une phrase, ce qui permet au modèle de saisir les nuances de sens et de comprendre le contexte. L'encodage positionnel aide le modèle à comprendre l'importance de l'ordre des mots au sein d'une phrase, ce qui est essentiel à la compréhension du langage. Le modèle Transformer permet aux LLM de traiter de grandes quantités de données, d'apprendre des informations contextuellement pertinentes et de générer du contenu cohérent.
Une version simplifiée du processus d'entraînement des LLM
Découvrez ce que sont les transformateurs, le fondement de tous les LLM
Poursuivez votre exploration

Le Grand livre de l’IA générative
Bonnes pratiques de développement pour des applications d'IA de qualité production/

Puisez dans le potentiel des LLM
Comment gagner en efficacité et r�éduire les coûts avec l'IA.
Databricks se classe n° 1 dans les catégories Exécution et Vision
Magic Quadrant™ Gartner® 2025 pour les plateformes de data science et de machine learning
Quelles sont les applications des LLM ?
Les LLM peuvent avoir un impact dans de nombreux domaines, tous secteurs confondus. Voici quelques cas d'usage typiques :
- Robots conversationnels et assistants virtuels : les LLM sont utilisés pour alimenter des chatbots destinés aux clients et aux collaborateurs d'une entreprise. Ces robots peuvent fournir une assistance, assurer le suivi des prises de contact via le site web ou servir d'assistant personnel.
- Création de contenu : les LLM peuvent générer différents types de contenu, tels que des articles, des billets de blog et des publications pour les réseaux sociaux.
- Génération de code et débogage : les LLM peuvent produire des extraits de code utiles, identifier et corriger des erreurs dans le code, et compléter des programmes sur la base d'instructions d'entrée.
- Analyse des sentiments : les LLM peuvent comprendre automatiquement le sentiment d'un texte pour évaluer la satisfaction des clients.
- Classification et regroupement de textes : les LLM peuvent organiser, catégoriser et trier de grands volumes de données pour identifier des thèmes et des tendances afin d'enrichir la prise de décision.
- Traduction : les LLM peuvent traduire des documents et des pages Web dans différentes langues pour atteindre différents marchés.
- Synthèse et paraphrase : les LLM peuvent résumer des articles, des publications, des appels de clients ou des réunions, en mettant en relief les points les plus importants.
- Sécurité : les LLM peuvent être utilisés en cybersécurité pour identifier les schémas de menace et automatiser les réponses.
Quelques clients ayant déployé des LLM avec d'excellents résultats
JetBlue
JetBlue a déployé « BlueBot », un robot conversationnel qui s'appuie sur des modèles open source d'IA générative enrichis de données d'entreprise, exécuté avec Databricks. Ce chatbot est à la disposition de toutes les équipes de JetBlue qui peuvent accéder à des données en fonction de leur rôle. L'équipe « finance », par exemple, peut consulter les données SAP et les déclarations réglementaires, mais les équipes d'exploitation ne verront que les informations de maintenance.
Chevron Phillips
Chevron Phillips exploite les solutions d'IA générative basées sur des modèles open source comme Dolly de Databricks pour rationaliser l'automatisation du traitement des documents. Ces outils transforment les données non structurées issues de PDF et de manuels en insight structurés, ce qui permet une extraction de données plus rapide et plus précise pour les Opérations et la veille stratégique. Les politiques de gouvernance garantissent la productivité et la gestion des risques tout en maintenant la traçabilité.
Thrivent Financial
Thrivent Financial tire parti de l'IA générative et de Databricks pour accélérer les recherches, fournir des insights plus clairs et plus accessibles et augmenter la productivité de Data Engineering. En regroupant les données sur une plateforme unique avec une gouvernance basée sur les rôles, l'entreprise crée un espace sécurisé où les équipes peuvent innover, explorer et travailler plus efficacement.
Pourquoi les LLM connaissent-ils un soudain succès ?
Plusieurs percées technologiques récentes ont propulsé les LLM sur le devant de la scène :
- Progrès des technologies de machine learning : les LLM exploitent de nombreuses avancées dans les techniques de ML. La plus notable est certainement l'architecture des transformateurs, qui est à la base de la plupart des LLM.
- Accessibilité accrue : La sortie de ChatGPT a ouvert la voie à toute personne ayant accès à Internet pour interagir avec l'un des LLM les plus avancés via une interface Web simple, permettant au monde de comprendre la puissance des LLM.
- Puissance de calcul accrue : La disponibilité de ressources de calcul plus puissantes, comme les processeurs graphiques (GPU) et de meilleures techniques de traitement des données, a permis aux chercheurs d'entraîner des modèles beaucoup plus grands.
- Quantité et qualité des données d'entraînement : La disponibilité de grands datasets et la capacité à les traiter ont considérablement amélioré les performances des modèles. GPT-3, par exemple, a été entraîné sur des big data (environ 500 milliards de jetons) qui comprenaient des sous-ensembles de grande qualité. Le dataset WebText2 (17 millions de documents), notamment, rassemble le contenu de pages web publiques choisies pour leur qualité.
Puis-je utiliser les données de mon organisation pour personnaliser un LLM ?
Lorsque vous cherchez à personnaliser une application de LLM avec les données de votre organisation, vous devez examiner quatre modèles d'architecture. Ces différentes techniques, décrites plus bas, ne s'excluent pas les unes les autres. Au contraire, elles peuvent (et doivent) être combinées pour tirer parti de leurs forces respectives.
| Méthode | Définition | Cas d'usage principal | Exigences en matière de données | Avantages | Facteurs |
|---|---|---|---|---|---|
| Élaboration de prompts spécialisés visant à orienter le comportement du LLM | Guidage rapide, à la volée | Aucun | Rapide, économique, sans entraînement | Moins de contrôle que le réglage fin | |
| Le LLM est combiné à de la récupération de connaissances extérieures | Datasets dynamiques et connaissances externes | Base de connaissances ou de données externes (base de données vectorielle, par exemple) | Contexte actualisé dynamiquement, précision accrue | Augmente la longueur des prompts et le calcul d'inférences | |
| Adaptation d'un LLM préentraîné à des datasets ou des domaines spécifiques | Spécialisation pour un domaine ou une tâche | Des milliers d'exemples spécifiques ou d'instructions | Contrôle granulaire, spécialisation élevée | Nécessite des données étiquetées, coût de calcul important | |
| Entraînement d'un LLM à partir de zéro | Tâches uniques ou corpus propre à un domaine | Grands datasets (milliards, voire milliers de milliards de jetons) | Contrôle maximum, spécialement adapté à des besoins spécifiques | Consomme une grande quantité de ressources |

Quelle que soit la technique choisie, l'organisation devra créer sa solution en adoptant une approche modulaire et rigoureusement structurée pour se préparer à l'itérer et à l'adapter. Découvrez cette approche et bien plus encore dans The Big Book of Generative AI.
Que signifie le Data Engineering dans le contexte des LLM ?
L'ingénierie de prompt consiste à adapter les prompts textuels fournis à un LLM afin d'obtenir des réponses plus précises ou pertinentes. Les LLM ne produisent pas tous des résultats de la même qualité, car l'ingénierie de prompt est spécifique à chaque modèle. Voici quelques conseils généraux qui fonctionnent pour divers modèles :
- Utilisez des prompts clairs et concis comprenant éventuellement une instruction, du contexte (si nécessaire), une requête ou une entrée utilisateur, ainsi qu'une description du type ou du format souhaité pour le résultat.
- Donnez des exemples dans votre prompt (« few-shot learning », ou généralisation à partir d'une poignée d'exemples), pour aider le LLM à comprendre ce que vous voulez.
- Dites au modèle comment se comporter – demandez-lui, par exemple, d'admettre qu'il ne connaît pas la réponse à une question le cas échéant.
- Demandez au modèle de raisonner étape par étape, ou d'expliquer sa démarche.
- Si votre prompt inclut une entrée utilisateur, utilisez des techniques pour empêcher tout piratage. Précisez clairement quelles portions du prompt décrivent l'instruction et lesquelles décrivent l'entrée utilisateur.
Que signifie la génération augmentée par récupération (RAG) en ce qui concerne les LLM ?
La génération augmentée par récupération, ou RAG, est une approche architecturale qui peut améliorer l'efficacité des applications LLM en s'appuyant sur des données personnalisées. Elle consiste à récupérer des données et des documents utiles pour répondre à une question ou accomplir une tâche, puis à les fournir au LLM à titre de contexte. La RAG a donné la preuve de son efficacité avec les chatbots d'assistance et les systèmes de Q&R devant s'appuyer sur des informations à jour ou accéder à des connaissances propres à un domaine particulier.
Vous trouverez ici davantage d'informations sur la RAG.
Quels sont les LLM les plus courants et quelles sont leurs spécificités ?
Le domaine des LLM regorge de nombreuses options. De façon générale, on peut grouper les LLM en deux catégories : les services propriétaires et les modèles open source.
Modèles propriétaires
Les modèles LLM propriétaires sont développés et détenus par des entreprises privées et nécessitent généralement des licences pour y accéder. Le LLM propriétaire le plus médiatisé est peut-être GPT-4o, qui alimente ChatGPT, lancé en grande pompe en 2022. ChatGPT présente aux utilisateurs une interface de recherche conviviale permettant de saisir un prompt et d'obtenir généralement une réponse rapide et pertinente. Les développeurs peuvent utiliser l'API ChatGPT pour intégrer ce LLM à leurs propres applications, produits et services. D'autres modèles propriétaires incluent Gemini de Google et Claude d'Anthropic.
Modèles open source
L'autre option consiste à héberger soi-même un LLM, généralement en partant d'un modèle open source et compatible avec un usage commercial. La communauté open source a rapidement su rattraper les performances des modèles propriétaires. Parmi les modèles LLM open source populaires, on trouve Llama 4 de Meta et Mixtral 8x22B.
Quels critères pour faire le bon choix
Pour faire le bon choix et évaluer les différences d'approche entre l'API d'un fournisseur tiers et l'hébergement d'un LLM open source (ou affiné par réglage fin), il faut tenir compte de la pérennité du modèle, de la gestion des coûts et de l'avantage compétitif que vous pouvez tirer de vos données. Le retrait d'un modèle propriétaire devenu obsolète, par exemple, va interrompre vos pipelines et vos index vectoriels ; les modèles open source resteront toujours accessibles. Les modèles open source et affinés par réglage fin peuvent offrir davantage de choix et de possibilités de personnalisation, ce qui aura un effet positif sur le rapport performance-prix. En anticipant le réglage fin de vos propres modèles, vous pourrez exploiter les données de votre organisation et en faire un avantage compétitif, en développant des modèles plus performants que ceux disponibles dans le public. Dernier point, les modèles propriétaires peuvent créer des problèmes de gouvernance : ces « boîtes noires » ne permettent pas de superviser les processus, ni les pondérations de leur entraînement.
L'hébergement de vos propres LLM open source exige plus de travail que l'utilisation de LLM propriétaires. MLflow de Databricks permet à une personne qui maîtrise Python d'utiliser n'importe quel modèle de transformateur comme objet Python.
Comment choisir quel LLM utiliser ?
L'évaluation des LLM est un domaine délicat qui évolue constamment, principalement parce que leurs performances sont inégales d'une tâche à l'autre. Un LLM peut exceller selon un indicateur donné, mais une variation, même minime, dans le prompt ou le problème peut suffire à altérer considérablement sa performance.
Voici toutefois quelques outils et critères pour évaluer les performances des LLM :
- MLflow
- Ensemble d'outils LLMOps pour l'évaluation des modèles.
- Mosaic Model Gauntlet
- Approche d'évaluation agrégée, qui catégorise la compétence des modèles en six grands domaines (décrits ci-dessous) plutôt qu'une seule métrique monolithique.
- Hugging Face collecte des centaines de milliers de modèles provenant de contributeurs LLM
- BIG-bench (critère Beyond the Imitation Game)
- Cadre de référence dynamique qui héberge actuellement plus de 200 tâches et s'intéresse principalement à l'adaptation aux futures capacit�és des LLM.
- Faisceau d'évaluation de LM EleutherAI
- Cadre holistique qui évalue les modèles sur plus de 200 tâches, intègre les évaluations telles que BIG-bench et MMLU, et privilégie les capacités de reproduction et de comparaison.
À lire également : Bonnes pratiques pour l'évaluation des applications RAG à destination des LLM
Comment opérationnaliser la gestion des LLM via les opérations sur les grands modèles de langage ?
Un LLMOps (Large Language Model Ops) est un ensemble de pratiques, de techniques et d’outils utilisés pour la gestion opérationnelle des grands modèles de langage (LLM, Large Language Model) dans des environnements de production.
Le LLMOps permet le déploiement, le monitoring et la maintenance efficaces des LLM. Tout comme le MLOps (Machine Learning Ops) traditionnel, les solutions LLMOps nécessitent une collaboration entre les data scientists, les ingénieurs DevOps et les professionnels IT. Vous trouverez ici davantage d'informations sur le LLMOps.
Où puis-je trouver davantage d'informations sur les grands modèles de langage (LLM) ?
Vous trouverez de nombreuses ressources sur les LLM, mais voici quelques suggestions :
Formation
- LLM : modèles de fondation initiaux (EDX et Formation Databricks) – une formation gratuite de Databricks qui explore les rouages des modèles de fondation en lien avec les LLM.
- LLM : de l'application à la production (EDX et Formation Databricks) – une formation gratuite de Databricks qui s'intéresse au développement des applications de LLM à l'aide des frameworks les plus modernes et les plus répandus.
Ebooks
- Le Grand livre de l’IA générative
- Guide rapide pour affiner et créer des LLM personnalisés
- Un guide pratique pour les grands modèles de langage
Blogs techniques
- Présentation de Llama 4 de Meta sur la Databricks Data Intelligence Platform | Blog Databricks
- Mise en service des modèles Qwen sur Databricks | Blog Databricks
- Bonnes pratiques pour l'évaluation des applications RAG à destination des LLM
- Créer des applications d'IA générative avec la MLflow AI Gateway et Llama 2
- Créez des applications RAG de haute qualité avec Mosaic AI, l'évaluation d'agents, Model Serving et la recherche vectorielle
- LLMOPs : tout ce que vous devez savoir pour bien gérer des LLM
Étapes suivantes
- Contactez Databricks pour planifier une démonstration et discuter de vos projets de grands modèles de langage (LLM)
- Explorez l'offre de Databricks pour les LLM
- Découvrez les applications de la génération augmentée de récupération (RAG), l'architecture LLM la plus courante.