Les modèles de machine learning
Qu’est-ce qu’un modèle de machine learning ?
Un modèle de machine learning est un programme capable de trouver des modèles ou de prendre des décisions à partir d’un tout nouveau dataset. Par exemple, dans le traitement du langage naturel, les modèles de machine learning peuvent analyser et reconnaître correctement l’intention derrière des phrases ou des combinaisons de mots jamais entendues auparavant. Dans la reconnaissance d’images, on peut apprendre à un modèle de machine learning à reconnaître des objets, tels que des voitures ou des chiens. Un modèle de machine learning peut accomplir ce type de tâches en étant « entraîné » à l’aide d’un vaste dataset. Pendant l’entraînement, l’algorithme de machine learning est optimisé pour trouver certains modèles ou sorties de dataset, en fonction de la tâche. C’est le résultat de ce processus qui s’appelle un modèle de machine learning. Il s’agit généralement d’un programme informatique doté de règles et de structures de données spécifiques.
Poursuivez votre exploration


Qu’est-ce qu’un algorithme de machine learning ?
Un algorithme de machine learning est une méthode mathématique permettant de trouver des modèles dans un ensemble de données. Les algorithmes de machine learning sont souvent issus des statistiques, du calcul et de l’algèbre linéaire. La régression linéaire, les arbres de décision, la forêt aléatoire et XGBoost sont des exemples populaires d’algorithmes de machine learning.
Qu’est-ce que l’entraînement d’un modèle dans le domaine du machine learning ?
L’entraînement de modèle désigne le processus consistant à exécuter un algorithme de machine learning sur un dataset (appelé dataset d’entraînement) et à optimiser l’algorithme afin de trouver certains modèles ou certaines données de sortie. La fonction qui en résulte, dotée de règles et de structures de données est appelée modèle entraîné de machine learning.
Quels sont les différents types de machine learning ?
En général, la plupart des techniques de machine learning appartiennent à trois catégories : le machine learning supervisé, le machine learning non supervisé et le machine learning par renforcement.
Qu’est-ce que le machine learning supervisé ?
En machine learning supervisé, l’algorithme reçoit un dataset en entrée et est guidé pour répondre à un ensemble de sorties spécifiques. Cette méthode est couramment utilisée dans le domaine de la reconnaissance d’images grâce à une technique appelée classification. Elle est également utilisée pour prédire des données démographiques telles que la croissance de la population ou les métriques de santé, à l’aide d’une technique appelée régression.
Qu’est-ce que le machine learning non supervisé ?
En machine learning non supervisé, l’algorithme utilise un dataset en entrée mais n’est pas guidé pour obtenir des résultats particuliers. Il est en revanche entraîné à identifier des similitudes entre les objets pour regrouper ceux qui partagent des caractéristiques communes. Un exemple est celui des moteurs de recommandation utilisés par les sites de vente en ligne qui reposent sur le machine learning non supervisé, principalement sur une méthode appelée clustering.
Qu’est-ce que le machine learning par renforcement ?
En machine learning par renforcement, l’algorithme procède à un apprentissage autonome grâce à une multitude d’expériences d’essais et d’erreurs. Ce type de machine learning se produit lorsque l’algorithme interagit en permanence avec son environnement, plutôt que d’utiliser des données d’entraînement. La conduite autonome est l’un des exemples les plus populaires de machine learning par renforcement.
Quels sont les différents modèles de machine learning ?
Il existe de nombreux modèles de machine learning. Presque tous sont basés sur certains algorithmes de machine learning. Les algorithmes les plus couramment utilisés pour la classification et la régression appartiennent au machine learning supervisé, tandis que les algorithmes de clustering sont principalement utilisés pour des scénarios de machine learning non supervisé.
Machine learning supervisé
- Régression logistique : la régression logistique est utilisée pour déterminer si une entrée appartient ou non à un certain groupe.
- SVM : les SVM (Support Vector Machines) créent des coordonnées pour chaque objet dans un espace à n dimensions et utilisent un hyperplan pour regrouper les objets en fonction de caractéristiques communes.
- Naive Bayes : Naive Bayes est un algorithme qui suppose l’indépendance des variables et utilise la probabilité pour classer les objets en fonction de leurs caractéristiques.
- Arbres de décision : les arbres de décision sont également des classificateurs utilisés pour déterminer la catégorie d’une entrée en parcourant les feuilles et les nœuds de l’arbre.
- Régression linéaire : la régression linéaire est utilisée pour identifier les relations entre la variable d’intérêt et les entrées. Elle prédit également ses valeurs en fonction des valeurs des variables d’entrée.
- kNN : la technique des k plus proches voisins (k Nearest Neighbors) consiste à rassembler les éléments les plus proches dans un dataset et à déterminer les caractéristiques les plus fréquentes ou les plus moyennes entre ces éléments.
- Forêt aléatoire : une forêt aléatoire est un ensemble de plusieurs arbres de décision qui proviennent de sous-ensembles aléatoires de données. Cette méthode combinatoire peut offrir une meilleure précision de prédiction qu’un arbre de décision unique.
- Algorithmes de boosting : les algorithmes de boosting, tels que Gradient Boosting Machine, XGBoost et LightGBM, utilisent l’apprentissage ensembliste. Ils combinent les prédictions de plusieurs algorithmes (tels que les arbres de décision) tout en tenant compte de l’erreur de l’algorithme précédent.
Machine learning non supervisé
- K-Means : l’algorithme K-Means trouve des similitudes entre les objets et les regroupe en K clusters distincts.
- Clustering hiérarchique : ce modèle construit un arbre de clusters imbriqués sans avoir à spécifier leur nombre.
Qu’est-ce qu’un arbre de décision en machine learning (ML) ?
Un arbre de décision est une approche prédictive en machine learning permettant de déterminer la classe à laquelle un objet appartient. Comme son nom l’indique, un arbre de décision est un organigramme en forme d’arbre où chaque étape consiste à évaluer une condition particulière pour déterminer la classe d’un objet. 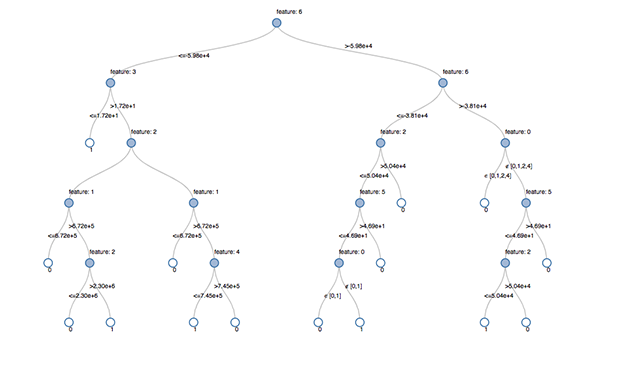 Un arbre de décision visualisé dans Databricks Lakehouse. Source : https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Un arbre de décision visualisé dans Databricks Lakehouse. Source : https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Qu’est-ce que la régression en machine learning ?
La régression en data science et en machine learning est une méthode statistique qui permet de prédire des résultats en fonction d’un ensemble de variables d’entrée. Le résultat est souvent une variable qui dépend d’une combinaison des variables d’entrée. 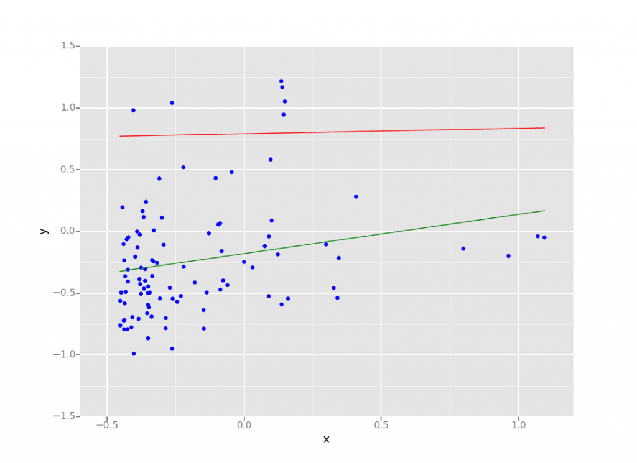 Modèle de régression linéaire réalisé sur Databricks Lakehouse. Source : https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Modèle de régression linéaire réalisé sur Databricks Lakehouse. Source : https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Qu’est-ce qu’un classificateur en machine learning ?
Un classificateur en machine learning est un algorithme qui permet d’attribuer un objet à une catégorie ou à un groupe. Par exemple, il peut être utilisé pour déterminer si un e-mail est un spam ou si une transaction est frauduleuse.
Combien de modèles existe-t-il en machine learning ?
Une pléthore ! Le machine learning est un domaine en constante évolution et il y a toujours plus de modèles de machine learning en cours de développement.
Quel est le modèle de machine learning le plus performant ?
Le choix du modèle de machine learning le plus performant dépend entièrement du résultat souhaité. Par exemple, pour prédire le nombre d’achats de véhicules dans une ville en s’appuyant sur des données historiques, une technique de machine learning supervisée comme la régression linéaire s'avère la plus adaptée. En revanche, pour évaluer si un client dans cette ville est susceptible d’acheter un véhicule en fonction de ses revenus et de ses habitudes de déplacement, utiliser un arbre de décision serait plus judicieux.
Qu’est-ce que le déploiement de modèles en machine learning (ML) ?
Le déploiement de modèle en machine learning consiste à rendre un modèle disponible pour une utilisation dans un environnement cible, que ce soit à des fins de test ou de production. Généralement, l’intégration du modèle à d’autres applications de l’environnement (comme les bases de données et l’interface utilisateur) se fait par le biais d’API. Le déploiement représente la phase finale permettant à une organisation de tirer profit de l’investissement significatif engagé dans le développement du modèle. 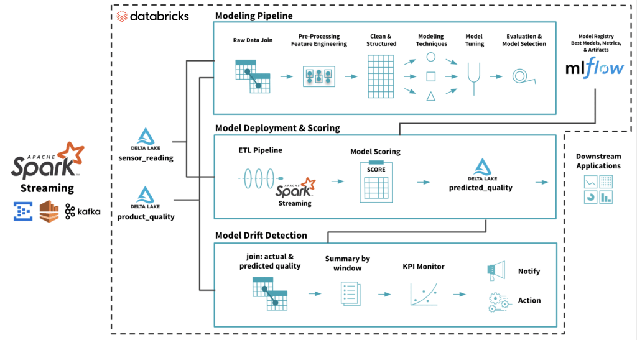 Le cycle de vie complet d’un modèle de machine learning sur Databricks Lakehouse. Source : https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Le cycle de vie complet d’un modèle de machine learning sur Databricks Lakehouse. Source : https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
Qu’est-ce qu’un modèle de deep learning ?
Un modèle de deep learning est une classe de modèles de ML imitant la manière dont les humains traitent l’information. Il se compose de plusieurs couches de traitement, d’où le terme « deep », qui extraient les caractéristiques les plus significatives des données fournies. Chaque couche de traitement transmet une représentation plus abstraite des données à la couche suivante, la dernière couche fournissant un insight plus humain. Contrairement aux modèles de ML traditionnels qui nécessitent que les données soient libellées, les modèles de deep learning peuvent ingérer de grandes quantités de données non structurées. Ils sont utilisés pour réaliser des fonctions plus proches de l’humain, telles que la reconnaissance faciale et le traitement du langage naturel.  Représentation simplifiée du deep learning. Source : https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Représentation simplifiée du deep learning. Source : https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Qu’est-ce qu’une série temporelle en machine learning ?
En machine learning, un modèle de série temporelle désigne un modèle dont l’une des variables indépendantes est une mesure de temps successive (par exemple, des minutes, jours ou années) qui influence la variable dépendante ou prédite. Les modèles de séries temporelles en machine learning sont utilisés pour prédire des événements limités dans le temps, par exemple la météo de la semaine prochaine, le nombre de clients attendus dans un mois ou encore les projections de chiffre d’affaires pour l’année à venir, et ainsi de suite.
Où trouver des informations supplémentaires sur le machine learning ?
- Découvrez dans cet eBook gratuit une multitude de cas passionnants où les entreprises à travers le monde ont mis en pratique l’apprentissage automatique.
- Pour approfondir la connaissance des experts en machine learning, consultez le blog Databricks Machine Learning.