Transformations
Que sont les transformations ?
Dans Spark, les structures de données principales sont immuables. En d’autres termes, elles ne peuvent pas être modifiées une fois créées. Ce concept peut sembler étrange à première vue. En effet, si vous ne pouvez pas la modifier, comment devez-vous l’utiliser ? Pour « modifier » un DataFrame, vous devrez indiquer à Spark comment vous souhaitez le transformer en un DataFrame de votre choix. Ces instructions sont appelées transformations. Les transformations sont au cœur de la façon dont vous exprimez votre logique métier avec Spark. Il existe deux types de transformations : celles qui spécifient des dépendances étroites et celles qui spécifient des dépendances larges.
Qu’est-ce qu’une dépendance étroite ?
Les transformations constituées de dépendances étroites (nous les appellerons « transformations étroites ») sont celles où chaque partition d’entrée ne contribue qu’à une seule partition de sortie. 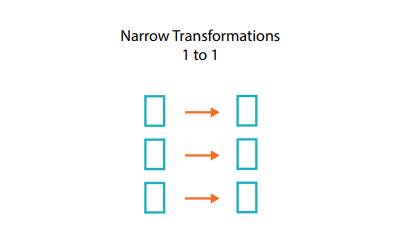
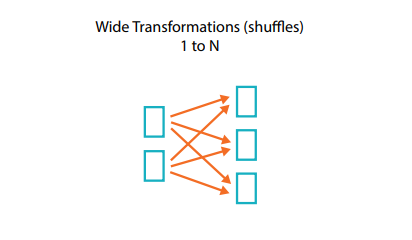
Qu’est-ce qu’une dépendance large ?
Une transformation à dépendance large (ou transformation large) est une transformation dans laquelle les partitions d’entrée contribuent à plusieurs partitions de sortie. Vous entendrez souvent parler d’un shuffle lorsque Spark échange des partitions sur le cluster. Avec les transformations étroites, Spark effectue automatiquement une opération de création de pipelines sur les dépendances étroites. Ainsi, si plusieurs filtres sont spécifiés sur les DataFrames, ils seront tous exécutés en mémoire. Il n’en va pas de même pour les shuffles. Lorsque nous effectuons un shuffle, Spark écrit les résultats sur le disque. Vous trouverez sur le Web de nombreux articles traitant de l’optimisation du shuffle, car c’est un sujet important. Cependant, tout ce que vous devez retenir pour le moment, c’est qu’il existe deux types de transformations.