Qu'est-ce que Spark Streaming ?
Comment Spark Streaming traite les micro-lots de données en temps réel avec DStreams et pourquoi Structured Streaming est désormais le moteur privilégié
- Découvrez ce qu'est Apache Spark Streaming, comment il étend l'API Spark et pourquoi il est désormais considéré comme un moteur de streaming hérité, supplanté par Structured Streaming.
- Voyez comment Spark Streaming ingère des données provenant de sources telles que Kafka, Flume et Amazon Kinesis, les traite par micro-lots et envoie les résultats vers des fichiers, des bases de données ou des tableaux de bord via DStreams.
- Explorez les principaux avantages de Spark Streaming, comme le traitement unifié par lots et en flux continu, la tolérance aux pannes et l'intégration avec MLlib et Spark SQL.
Apache Spark Streaming est la génération précédente du moteur de streaming d’Apache Spark. Spark Streaming ne bénéficie plus de mises à jour. Il s’agit d’un projet obsolète. Il existe un moteur de streaming plus récent et plus facile à utiliser dans Apache Spark, appelé Structured Streaming. Utilisez désormais Spark Structured Streaming pour vos applications de streaming et vos pipelines. Consultez l’article dédié à Structured Streaming.
Qu’est-ce que Spark Streaming ?
Apache Spark Streaming est un système de traitement en streaming évolutif et tolérant aux pannes. Il prend en charge en mode natif les charges de travail par batch et en streaming. Spark Streaming est une extension du noyau de l’API Spark qui permet aux data engineers et data scientists de traiter des données en temps réel à partir de diverses sources, y compris (mais sans s’y limiter) Kafka, Flume et Amazon Kinesis. Ces données traitées peuvent être transférées vers des systèmes de fichiers, des bases de données et des tableaux de bord dynamiques. Son abstraction clé est un flux discrétisé (en abrégé, un DStream), qui représente un flux de données divisé en petits batchs. Les DStreams sont construits sur les RDD, la principale abstraction de données de Spark. Cela permet à Spark Streaming de s’intégrer parfaitement à d’autres composants Spark tels que MLlib et Spark SQL. Spark Streaming se distingue des autres systèmes qui disposent d’un moteur de traitement conçu uniquement pour le streaming. Il se distingue aussi de ceux ayant des API de traitement batch et streaming similaires, mais qui compilent en interne des moteurs différents. Le moteur d’exécution unique de Spark et le modèle de programmation unifié pour le traitement batch et streaming offrent des avantages uniques par rapport à d’autres systèmes de streaming traditionnels.
Le guide pratique de l'IA agentique pour l'entreprise

Quatre avantages majeurs de Spark Streaming
- Récupération rapide des défaillances et des retards
- Meilleur équilibrage de charge et meilleure utilisation des ressources
- Combinaison de données de streaming avec des datasets statiques et des requêtes interactives
- Intégration native dans des bibliothèques de traitement avancées (SQL, machine learning, traitement graphique)
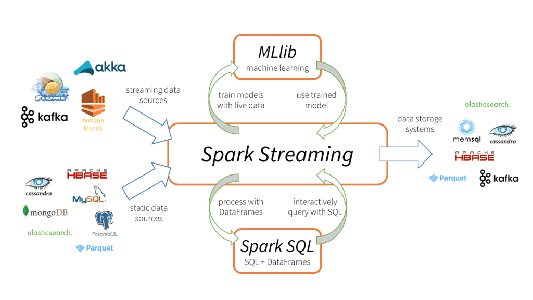
Cette unification des capacités de traitement de données disparates est la raison principale pour laquelle Spark Streaming a été rapidement adopté. Il permet aux développeurs d’utiliser très facilement un cadre unique répondant à tous leurs besoins en matière de traitement.
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.