Introducing Apache Spark 3.0
Now available in Databricks Runtime 7.0
by Matei Zaharia, Reynold Xin, Xiao Li, Wenchen Fan and Yin Huai
We’re excited to announce that the Apache SparkTM 3.0.0 release is available on Databricks as part of our new Databricks Runtime 7.0. The 3.0.0 release includes over 3,400 patches and is the culmination of tremendous contributions from the open-source community, bringing major advances in Python and SQL capabilities and a focus on ease of use for both exploration and production. These initiatives reflect how the project has evolved to meet more use cases and broader audiences, with this year marking its 10-year anniversary as an open-source project.
Here are the biggest new features in Spark 3.0:
- 2x performance improvement on TPC-DS over Spark 2.4, enabled by adaptive query execution, dynamic partition pruning and other optimizations
- ANSI SQL compliance
- Significant improvements in pandas APIs, including Python type hints and additional pandas UDFs
- Better Python error handling, simplifying PySpark exceptions
- New UI for structured streaming
- Up to 40x speedups for calling R user-defined functions
- Over 3,400 Jira tickets resolved
No major code changes are required to adopt this version of Apache Spark. For more information, please check the migration guide.
Celebrating 10 years of Spark development and evolution
Spark started out of UC Berkeley’s AMPlab, a research lab focused on data-intensive computing. AMPlab researchers were working with large internet-scale companies on their data and AI problems, but saw that these same problems would also be faced by all companies with large and growing volumes of data. The team developed a new engine to tackle these emerging workloads and simultaneously make the APIs for working with big data significantly more accessible to developers.
Community contributions quickly came in to expand Spark into different areas, with new capabilities around streaming, Python and SQL, and these patterns now make up some of the dominant use cases for Spark. That continued investment has brought Spark to where it is today, as the de facto engine for data processing, data science, machine learning and data analytics workloads. Apache Spark 3.0 continues this trend by significantly improving support for SQL and Python -- the two most widely used languages with Spark today -- as well as optimizations to performance and operability across the rest of Spark.
Improving the Spark SQL engine
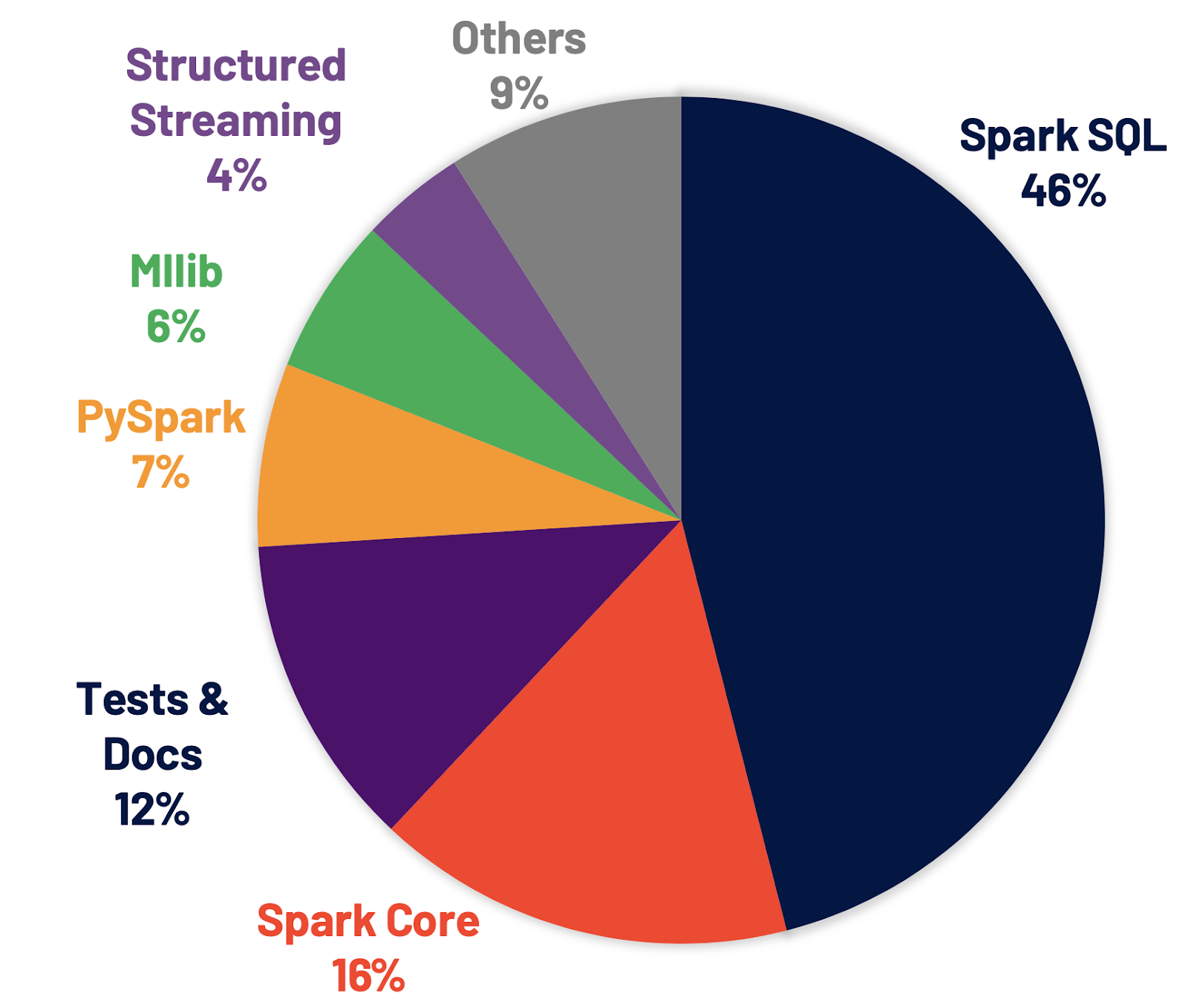
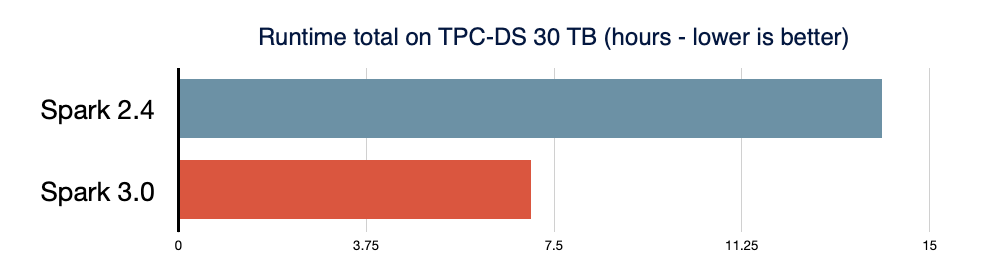
Spark SQL is the engine that backs most Spark applications. For example, on Databricks, we found that over 90% of Spark API calls use DataFrame, Dataset and SQL APIs along with other libraries optimized by the SQL optimizer. This means that even Python and Scala developers pass much of their work through the Spark SQL engine. In the Spark 3.0 release, 46% of all the patches contributed were for SQL, improving both performance and ANSI compatibility. As illustrated below, Spark 3.0 performed roughly 2x better than Spark 2.4 in total runtime. Next, we explain four new features in the Spark SQL engine.
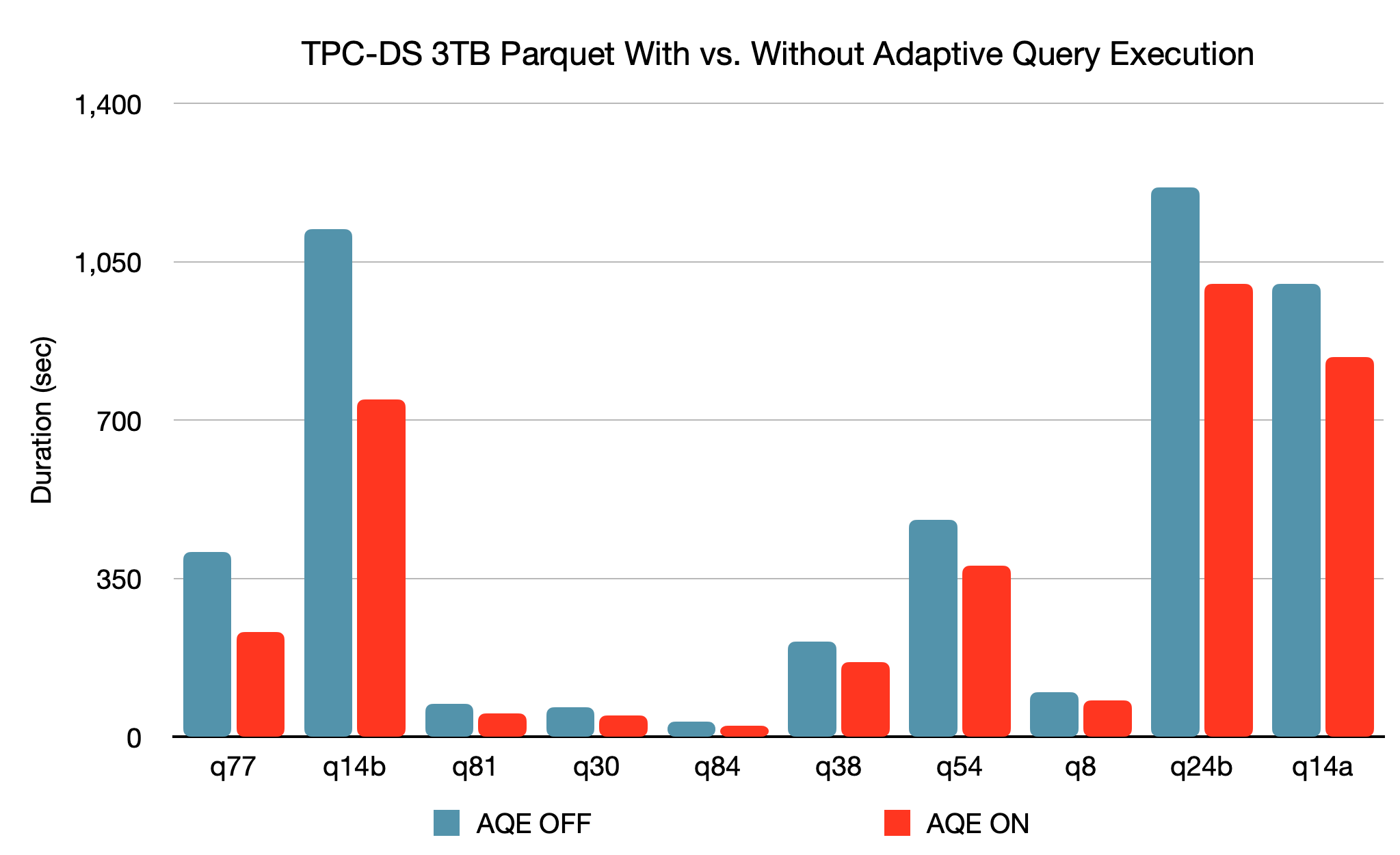
The new Adaptive Query Execution (AQE) framework improves performance and simplifies tuning by generating a better execution plan at runtime, even if the initial plan is suboptimal due to absent/inaccurate data statistics and misestimated costs. Because of the storage and compute separation in Spark, data arrival can be unpredictable. For all these reasons, runtime adaptivity becomes more critical for Spark than for traditional systems. This release introduces three major adaptive optimizations:
- Dynamically coalescing shuffle partitions simplifies or even avoids tuning the number of shuffle partitions. Users can set a relatively large number of shuffle partitions at the beginning, and AQE can then combine adjacent small partitions into larger ones at runtime.
- Dynamically switching join strategies partially avoids executing suboptimal plans due to missing statistics and/or size misestimation. This adaptive optimization can automatically convert sort-merge join to broadcast-hash join at runtime, further simplifying tuning and improving performance.
- Dynamically optimizing skew joins is another critical performance enhancement, since skew joins can lead to an extreme imbalance of work and severely downgrade performance. After AQE detects any skew from the shuffle file statistics, it can split the skew partitions into smaller ones and join them with the corresponding partitions from the other side. This optimization can parallelize skew processing and achieve better overall performance.
Based on a 3TB TPC-DS benchmark, compared without AQE, Spark with AQE can yield more than 1.5x performance speedups for two queries and more than 1.1x speedups for another 37 queries.
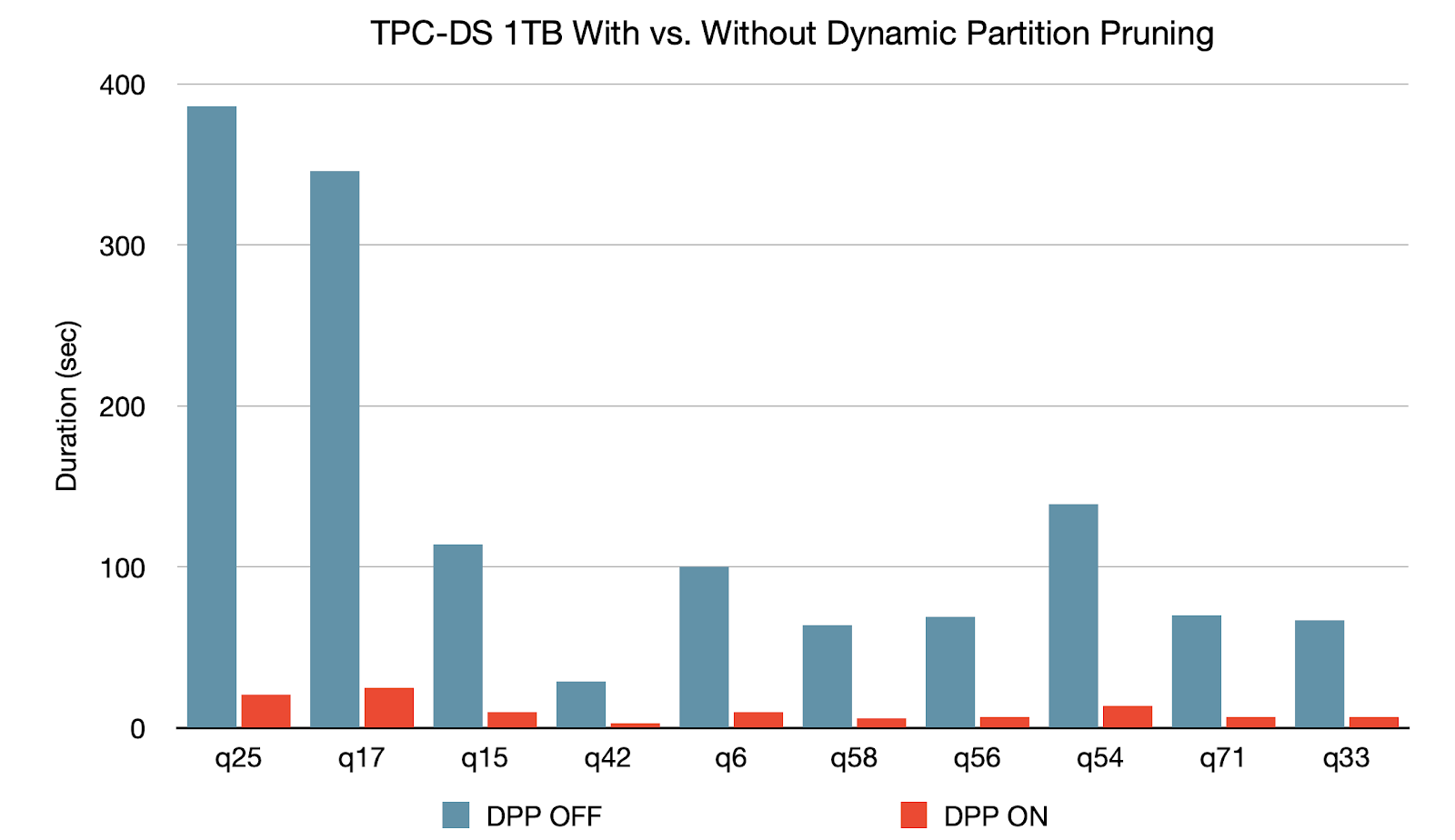
Dynamic Partition Pruning is applied when the optimizer is unable to identify at compile time the partitions it can skip. This is not uncommon in star schemas, which consist of one or multiple fact tables referencing any number of dimension tables. In such join operations, we can prune the partitions the join reads from a fact table, by identifying those partitions that result from filtering the dimension tables. In a TPC-DS benchmark, 60 out of 102 queries show a significant speedup between 2x and 18x.
ANSI SQL compliance is critical for workload migration from other SQL engines to Spark SQL. To improve compliance, this release switches to Proleptic Gregorian calendar and also enables users to forbid using the reserved keywords of ANSI SQL as identifiers. Additionally, we’ve introduced runtime overflow checking in numeric operations and compile-time type enforcement when inserting data into a table with a predefined schema. These new validations improve data quality.
Join hints: While we continue to improve the compiler, there’s no guarantee that the compiler can always make the optimal decision in every situation — join algorithm selection is based on statistics and heuristics. When the compiler is unable to make the best choice, users can use join hints to influence the optimizer to choose a better plan. This release extends the existing join hints by adding new hints: SHUFFLE_MERGE, SHUFFLE_HASH and SHUFFLE_REPLICATE_NL.
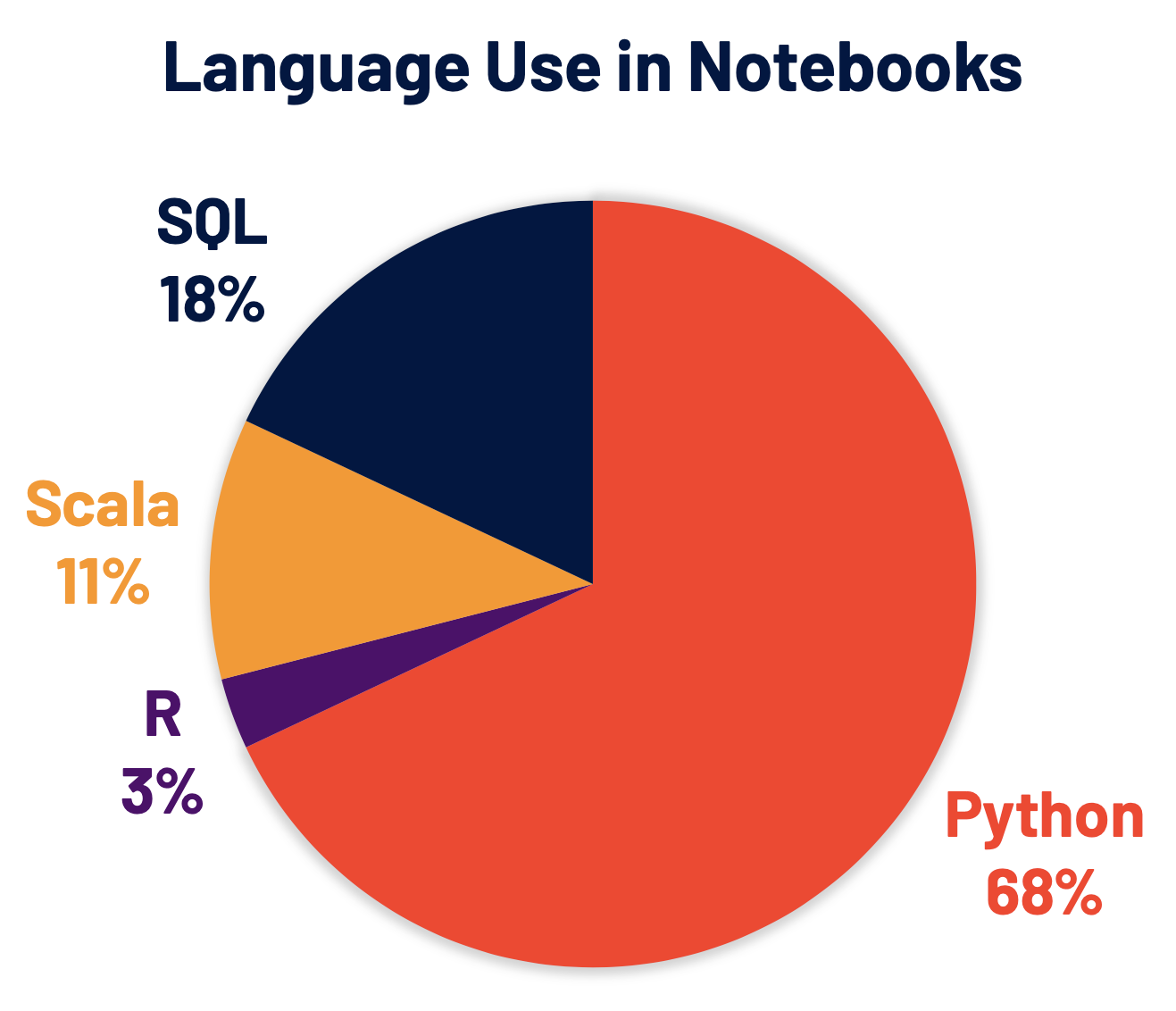
Python is now the most widely used language on Spark and, consequently, was a key focus area of Spark 3.0 development. 68% of notebook commands on Databricks are in Python. PySpark, the Apache Spark Python API, has more than 5 million monthly downloads on PyPI, the Python Package Index.
Many Python developers use the pandas API for data structures and data analysis, but it is limited to single-node processing. We have also continued to develop Koalas, an implementation of the pandas API on top of Apache Spark, to make data scientists more productive when working with big data in distributed environments. Koalas eliminates the need to build many functions (e.g., plotting support) in PySpark, to achieve efficient performance across a cluster.
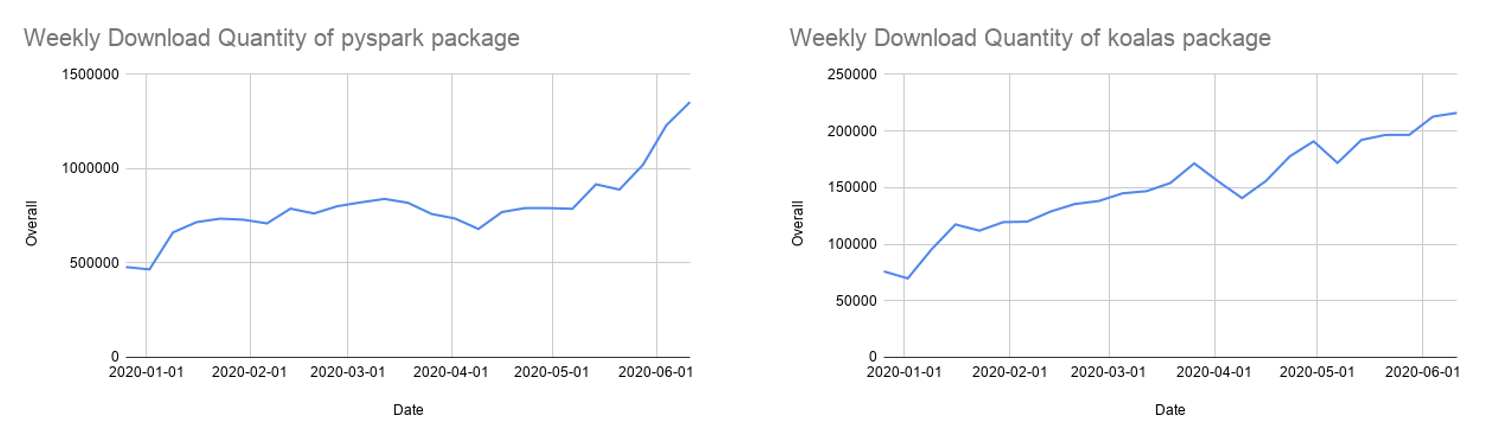
After more than a year of development, the Koalas API coverage for pandas is close to 80%. The monthly PyPI downloads of Koalas has rapidly grown to 850,000, and Koalas is rapidly evolving with a biweekly release cadence. While Koalas may be the easiest way to migrate from your single-node pandas code, many still use the PySpark APIs, which are also growing in popularity.
Spark 3.0 brings several enhancements to the PySpark APIs:
- New pandas APIs with type hints: pandas UDFs were initially introduced in Spark 2.3 for scaling user-defined functions in PySpark and integrating pandas APIs into PySpark applications. However, the existing interface is difficult to understand when more UDF types are added. This release introduces a new pandas UDF interface that leverages Python type hints to address the proliferation of pandas UDF types. The new interface becomes more Pythonic and self-descriptive.
- New types of pandas UDFs and pandas function APIs: This release adds two new pandas UDF types, iterator of series to iterator of series and iterator of multiple series to iterator of series. It’s useful for data prefetching and expensive initialization. Also, two new pandas-function APIs, map and co-grouped map are added. More details are available in this blog post.
- Better error handling: PySpark error handling is not always friendly to Python users. This release simplifies PySpark exceptions, hides the unnecessary JVM stack trace, and makes them more Pythonic.
Improving Python support and usability in Spark continues to be one of our highest priorities.
Hydrogen, streaming and extensibility
With Spark 3.0, we’ve finished key components for Project Hydrogen as well as introduced new capabilities to improve streaming and extensibility.
- Accelerator-aware scheduling: Project Hydrogen is a major Spark initiative to better unify deep learning and data processing on Spark. GPUs and other accelerators have been widely used for accelerating deep learning workloads. To make Spark take advantage of hardware accelerators on target platforms, this release enhances the existing scheduler to make the cluster manager accelerator-aware. Users can specify accelerators via configuration with the help of a discovery script. Users can then call the new RDD APIs to leverage these accelerators.
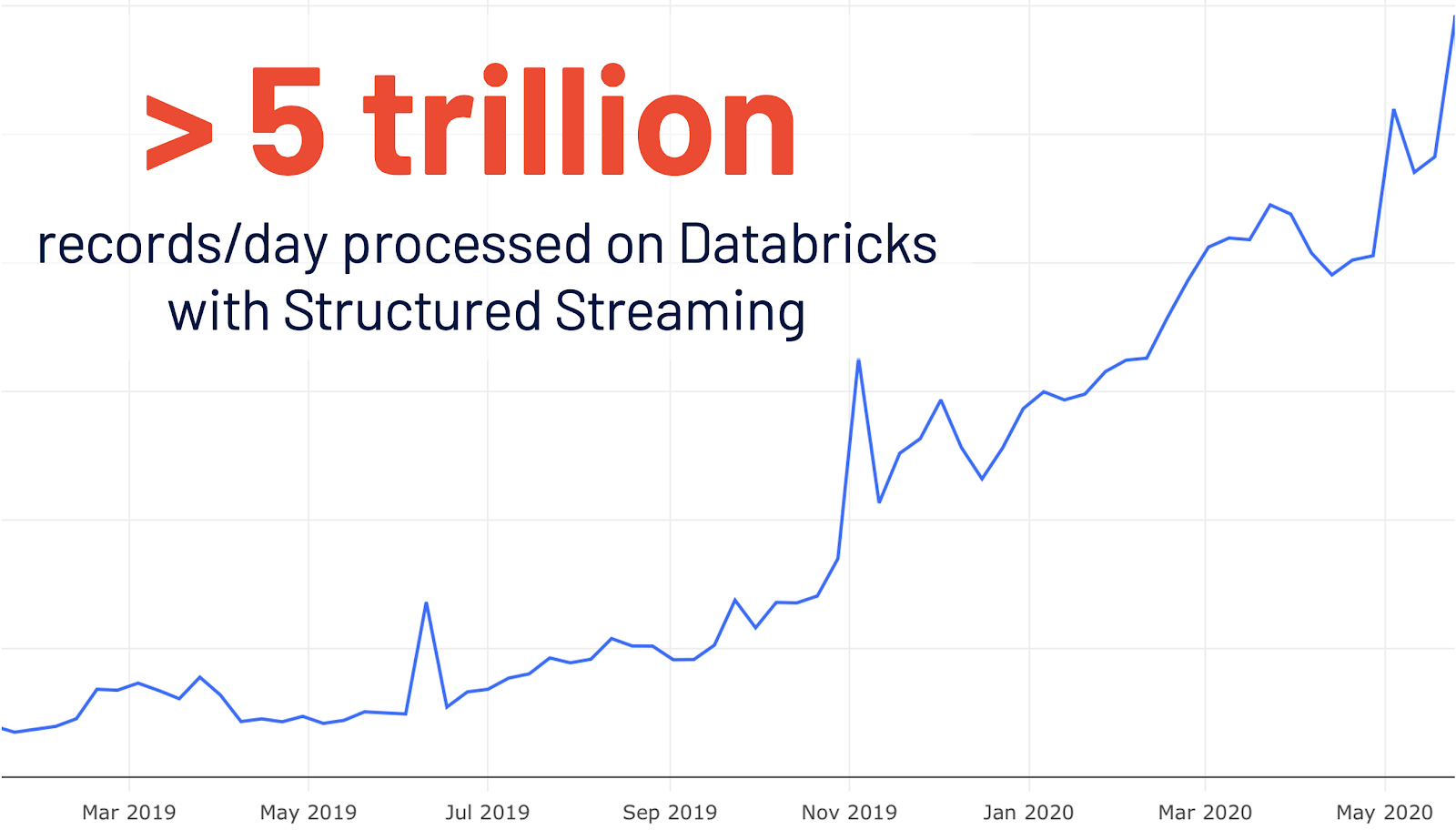
- New UI for structured streaming: Structured streaming was initially introduced in Spark 2.0. After 4x YoY growth in usage on Databricks, more than 5 trillion records per day are processed on Databricks with structured streaming. This release adds a dedicated new Spark UI for inspection of these streaming jobs. This new UI offers two sets of statistics: 1) aggregate information of streaming query jobs completed and 2) detailed statistics information about streaming queries.
- Observable metrics: Continuously monitoring changes to data quality is a highly desirable feature for managing data pipelines. This release introduces monitoring for both batch and streaming applications. Observable metrics are arbitrary aggregate functions that can be defined on a query (DataFrame). As soon as the execution of a DataFrame reaches a completion point (e.g., finishes batch query or reaches streaming epoch), a named event is emitted that contains the metrics for the data processed since the last completion point.
- New catalog plug-in API: The existing data source API lacks the ability to access and manipulate the metadata of external data sources. This release enriches the data source V2 API and introduces the new catalog plug-in API. For external data sources that implement both catalog plug-in API and data source V2 API, users can directly manipulate both data and metadata of external tables via multipart identifiers, after the corresponding external catalog is registered.
Other updates in Spark 3.0
Spark 3.0 is a major release for the community, with over 3,400 Jira tickets resolved. It’s the result of contributions from over 440 contributors, including individuals as well as companies like Databricks, Google, Microsoft, Intel, IBM, Alibaba, Facebook, Nvidia, Netflix, Adobe and many more. We’ve highlighted a number of the key SQL, Python and streaming advancements in Spark for this blog post, but there are many other capabilities in this 3.0 milestone not covered here. Learn more in the release notes and discover all the other improvements to Spark, including data sources, ecosystem, monitoring and more.
Get started with Spark 3.0 today
If you want to try out Apache Spark 3.0 in the Databricks Runtime 7.0, sign up for a free trial account and get started in minutes. Using Spark 3.0 is as simple as selecting version “7.0” when launching a cluster.
Learn more about feature and release details:
- O’Reilly's New Learning Spark, 2nd Edition free ebook download
- Adaptive Query Execution blog
- Pandas UDFs and Python Type Hints blog
- Spark 3.0 Preview on-demand webinar
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.