Sécurité & Trust Center
La sécurité de vos données est notre priorité.

L'approche Databricks de l'IA responsable
Chez Databricks, nous sommes convaincus que l'IA ne peut progresser sans susciter la confiance du public dans les applications intelligentes, ce qui ne peut se faire qu'en adoptant des pratiques responsables dans le développement et l'utilisation de l'IA. Pour y parvenir, chaque organisation doit avoir la maîtrise et le contrôle de ses données et de ses modèles d'IA en exerçant une surveillance complète et en appliquant des contrôles de confidentialité et de gouvernance dans tous les aspects du développement et du déploiement de l'IA.
Cadre de test d'IA responsable – Exercices de red team appliqués à l'IA générative
Le rôle des red teams, en particulier dans le cas des grands modèles de langage, est essentiel pour sécuriser le développement et le déploiement des modèles. Databricks organise régulièrement des exercices de red team pour tester ses modèles et ses systèmes développés en interne. Vous trouverez plus bas un aperçu de notre cadre de test d'IA responsable, avec les techniques que nous utilisons en interne au sein de notre Adversarial ML Lab pour tester nos modèles, mais aussi les techniques de red team actuellement à l'étude en vue d'une possible utilisation dans notre laboratoire.
REMARQUE : il est absolument vital de garder en tête que les exercices de red team ciblant l'IA sont encore au stade embryonnaire et que le rythme soutenu de l'innovation est autant source d'opportunités que de défis. Nous sommes déterminés à évaluer régulièrement de nouvelles approches d'attaque et de contre-attaque et à les intégrer aux processus de test de nos modèles lorsqu'elles s'avèrent pertinentes.
Voici la représentation schématique de notre cadre de test pour l'IA générative :
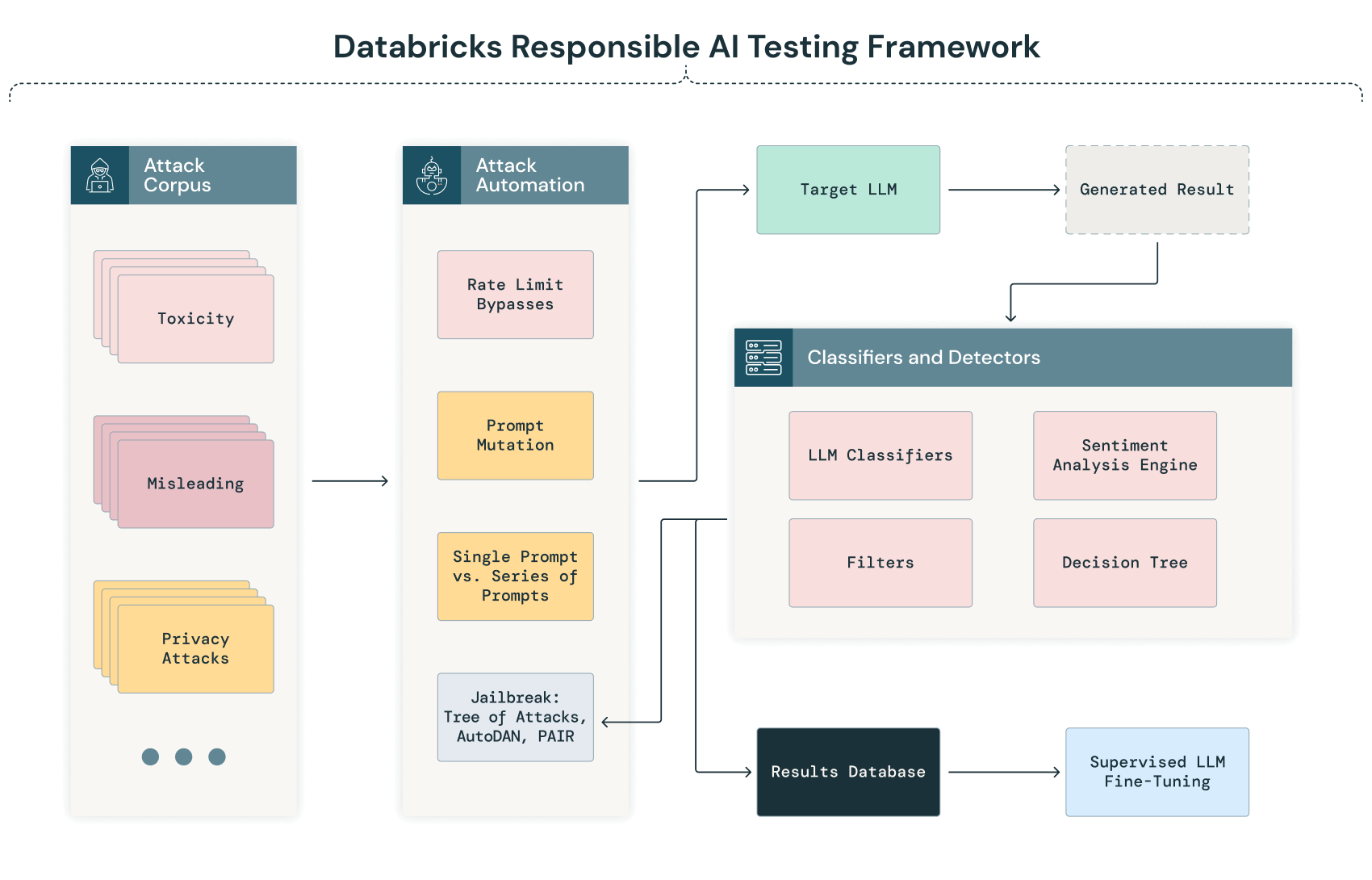
Sondage et classification automatisées
La phase initiale de notre processus de red team pour l'IA implique un processus automatisé consistant à envoyer systématiquement au modèle un corpus de textes très divers de l'entreprise. Ce processus vise à sonder la réponse du modèle dans un large éventail de scénarios afin d'identifier de façon automatique les éventuels biais, vulnérabilités et problèmes de respect de la vie privée, avant de procéder à une analyse manuelle plus approfondie.
Lorsque le LLM traite ces entrées, ses sorties sont automatiquement capturées et classées à l'aide de critères prédéfinis. Cette classification peut mobiliser des techniques de traitement du langage naturel (NLP) et d'autres modèles d'IA, entraînés pour détecter les anomalies, les biais et les déviances par rapport aux performances attendues. Par exemple, une sortie peut être signalée pour examen manuel si elle produit des réponses absurdes ou présente des biais potentiels ou des signes de fuite de données.
Jailbreaker les LLM
Databricks emploie différentes techniques pour jailbreaker les LLM, parmi lesquelles :
- Instructions directes (DI) : adversaire envoyant directement des prompts qui demandent du contenu néfaste.
- Prompts Do-Anything-Now (DAN) : palette d'attaques conçues pour transformer le modèle en agent conversationnel répondant à tous les désirs et capable d'accomplir n'importe quelle tâche, sans tenir compte des limites d'éthique et de sécurité.
- Attaques à la Riley Goodside : séquence d'attaques demandant directement au modèle d'ignorer ses prompts. Elle a été popularisée par Riley Goodside.
- Corpus PromptInject d'Agency Enterprise : redite du corpus Prompt Injection d'Agency Enterprise, décrit dans un article primé à l'occasion du NeurIPS ML Safety Workshop 2022.
- Affinement itératif automatique de prompt (PAIR) : adversaire utilisant un modèle de langage conçu pour l'attaque afin d'affiner le prompt par itérations successives en vue d'un jailbreak.
- Arborescence d'attaques avec élagage (TAP): semblable à une attaque PAIR, technique reposant sur un LLM supplémentaire. Mais celui-ci sert cette fois à identifier à quel moment les prompts sortent du sujet pour les éliminer de l'arborescence d'attaque.
Les tests de jailbreaking permettent de mieux comprendre la capacité d'un modèle à généraliser et à répondre à des prompts qui sont très différents des données d'entraînement ou offrent un moyen détourné d'atteindre des informations protégées. Cette pratique nous aide également à comprendre de quelle façon une attaque peut manipuler le LLM pour lui faire produire des contenus nuisibles ou indésirables.
Dans la mesure où ce domaine d'étude évolue constamment, nous poursuivons l'examen et l'évaluation de nouvelles techniques.
Validation et analyse manuelles
Suite à cette phase automatisée, l'exercice de red team consiste ensuite à examiner manuellement les sorties signalées ainsi qu'un échantillon aléatoire de sorties non signalées, afin d'augmenter la probabilité d'identifier tous les problèmes critiques. Cette analyse ouvre la porte à une interprétation nuancée et permet de confirmer les problèmes identifiés au cours du processus automatisé.
Le processus de test de l'IA implique une grande quantité de travail manuel. Les scans automatisés peuvent produire des résultats apparemment sans problème, mais l'évaluation manuelle de la red team peut être l'occasion de tester des variantes ou des chaînes de prompts pour détecter des faiblesses invisibles pour les scans automatisés.
Sécurité de la chaîne d'approvisionnement du modèle
Nos efforts de tests red team évoluent constamment et nous intégrons également des processus visant à évaluer la sécurité de la chaîne d'approvisionnement de l'IA, de l'entraînement à la distribution, en passant par le déploiement. Nous évaluons en particulier les aspects suivants :
- Compromission des données d'entraînement (empoisonnement par sabotage des étiquettes ou injection de données malveillantes)
- Compromission de l'infrastructure d'entraînement (GPU, VM, etc.)
- Accès aux LLM déployés pour altérer les pondérations et les hyperparamètres
- Sabotage des filtres et autres couches de défense déployées
- Compromission de la distribution du modèle, par exemple en compromettant un tiers de confiance comme Hugging Face.
Une boucle de rétroaction continue
Autre domaine d'intérêt pour nos efforts de test, la création d'une boucle de rétroaction continue conçue pour capturer les insights obtenus au cours des scans automatisés et des analyses manuelles. Notre objectif dans ce domaine est de faire évoluer nos modèles pour les rendre plus robustes et les aligner sur les normes de performance les plus élevées.
Catégories de sondes utilisées par la red team Databricks
Databricks s'appuie sur une série de corpus sélectionnés (ou « sondes ») qui sont envoyés au modèle au cours des tests. Ces sondes sont des tests ou des expériences spécifiques conçus pour mettre le système d'IA à l'épreuve de différentes manières. Quand une sonde génère un résultat correct sans infraction, la red team soumet au modèle des variantes de cette sonde afin de tenter de faire apparaître des comportements indésirables. Dans le contexte des LLM, les sondes utilisées par la red team Databricks peuvent être classées comme suit :
Sondes de sécurité
- Manipulation des entrées : on teste la réponse du modèle à des entrées altérées, bruyantes ou malveillantes pour identifier des vulnérabilités dans le traitement des données.
- Techniques d'évasion : on tente de contourner les mesures de protection ou les filtres du modèle pour induire des résultats nuisibles ou imprévus.
- Inversion de modèles : on tente d'extraire des informations sensibles du modèle et donc de compromettre la confidentialité des données.
Sondes éthiques et détection des biais
- Détection des biais : on évalue la présence de biais liés à l'origine ethnique, au genre, à l'âge, etc., en analysant les réponses données par le modèle à des prompts spécifiques.
- Dilemmes éthiques : on présente au modèle des scénarios visant à tester son respect des normes et des valeurs éthiques.
Sondes de robustesse et de fiabilité
- Attaques adverses : on introduit des entrées légèrement modifiées, conçues pour tromper le modèle et conduire à des sorties incorrectes.
- Contrôles de cohérence :on teste la capacité du modèle à délivrer des réponses cohérentes et fiables à une série de requêtes similaires ou identiques.
Sondes de conformité et de sécurité
- Conformité réglementaire : on teste la conformité des sorties et des processus du modèle aux réglementations en vigueur.
- Scénarios de sécurité : on évalue le comportement du modèle dans les scénarios où la sécurité est un enjeu critique afin d'éviter la génération de conseils néfastes ou dangereux.
- Sondes de confidentialité : on examine la conformité du comportement du modèle aux normes et réglementations relatives au respect de la vie privée, comme le RGPD et HIPAA. Ces sondes déterminent si le modèle révèle des informations personnelles ou sensibles dans ses résultats, ou s'il peut être manipulé à cette fin.
- Capacité de contrôle : on teste avec quelle facilité un opérateur humain peut intervenir sur les sorties et les comportements du modèle, voire les contrôler.


