LakeFlowジョブを使用する顧客

データ、分析、またはAIワークフローを組織化します
あなたのデータプラットフォームに完全に統合された管理されたオーケストレーションサービスでパイプラインを効率化します。簡単にETL、分析、MLワークフローを定義し、監視し、自動化することができ、信頼性と深い観察性を持っています。シンプルなオーサリング
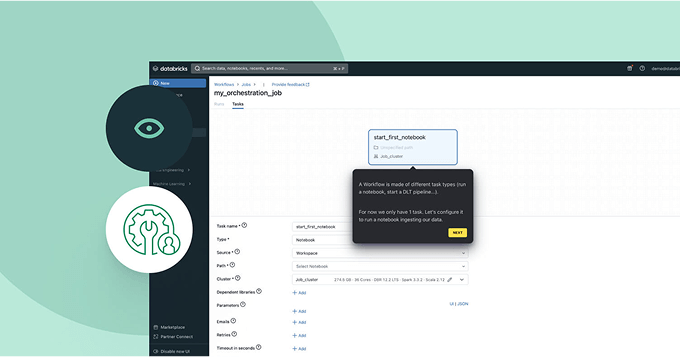
どのレ�ベルのデータ専門家でも使用できるシンプルで直感的なツールを使用してワークフローを設計します。お気に入りのIDEで、または数回のクリックだけでタスクを定義し、ジョブ作成を簡単にします。
実用的なインサイト
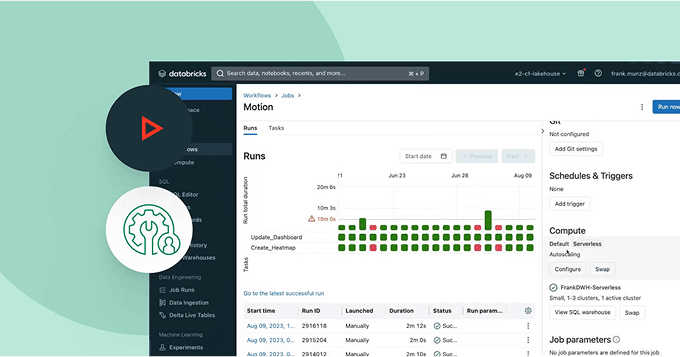
リアルタイムモニタリングで全てのタスクを完全に把握します。詳細なメトリクスと分析を使用して、生産の健康状態を積極的に評価し、迅速にボトルネックを特定し、問題をトラブルシューティングし、データパイプライン全体でのシームレスな操作を確保します。
高い信頼性
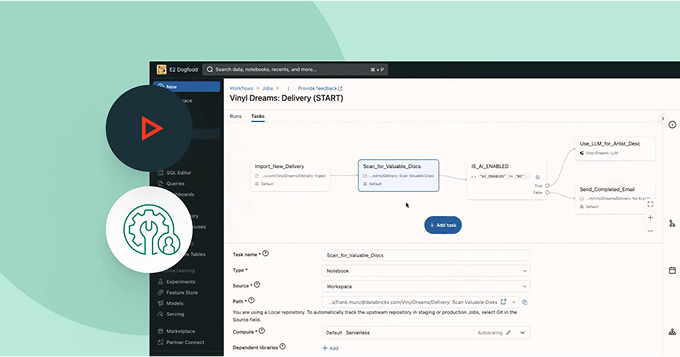
あなたのプロダクションワークフローをスムーズかつ信頼性高く運用するために、完全に管理されたオーケストレーションサービスを信頼してください。実績あるパフォーマンスとスケーラビリティを持つLakeflow Jobsは、数千の組織から最も重要なデータパイプラインの処理を任されています。
あなたのデータパイプラインを効率化し、調整してください
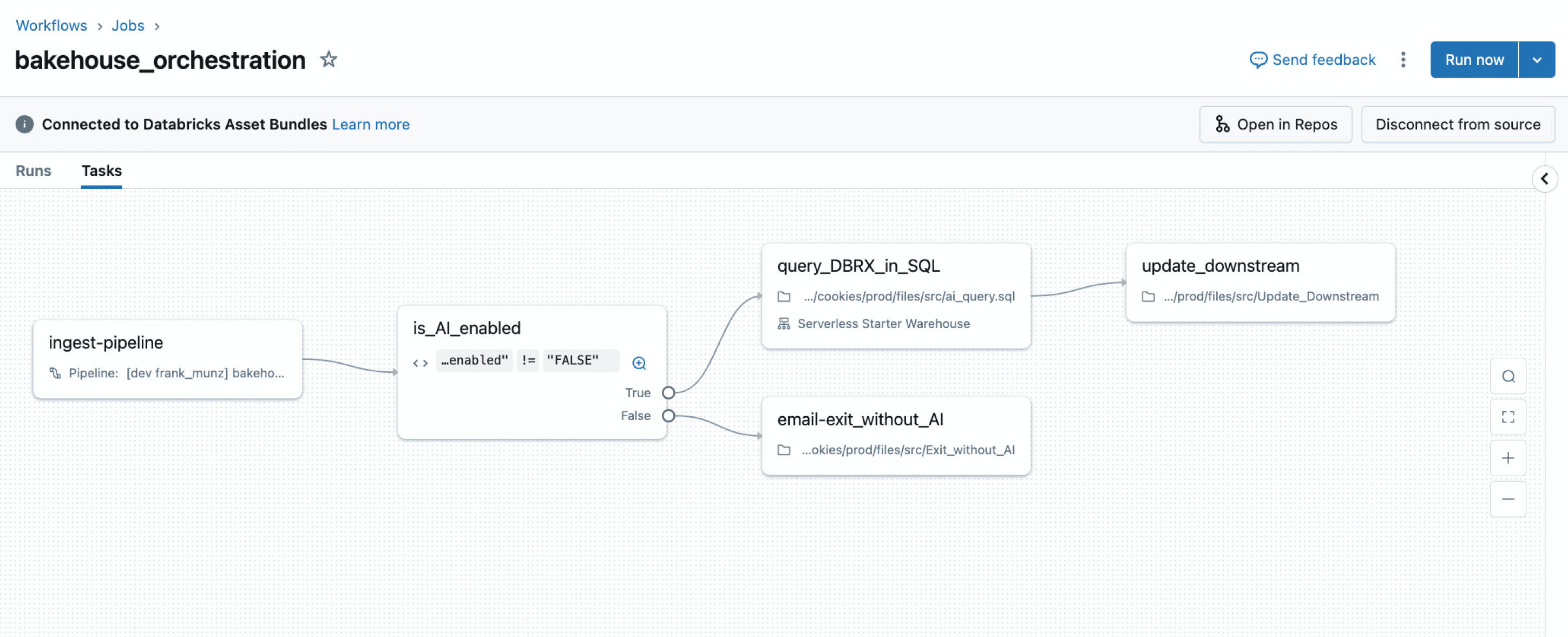
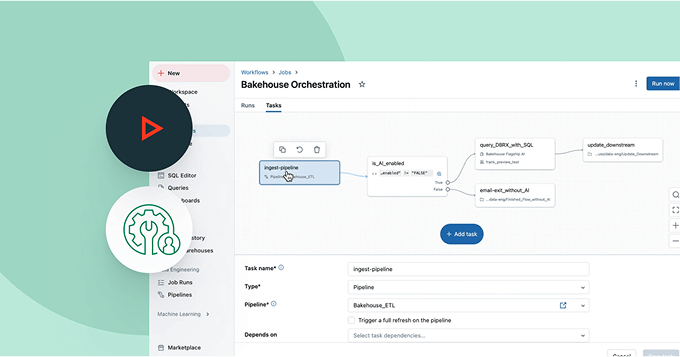
ETL、分析、AIパイプライン全体でジョブを簡単に定義、管理、監視できます。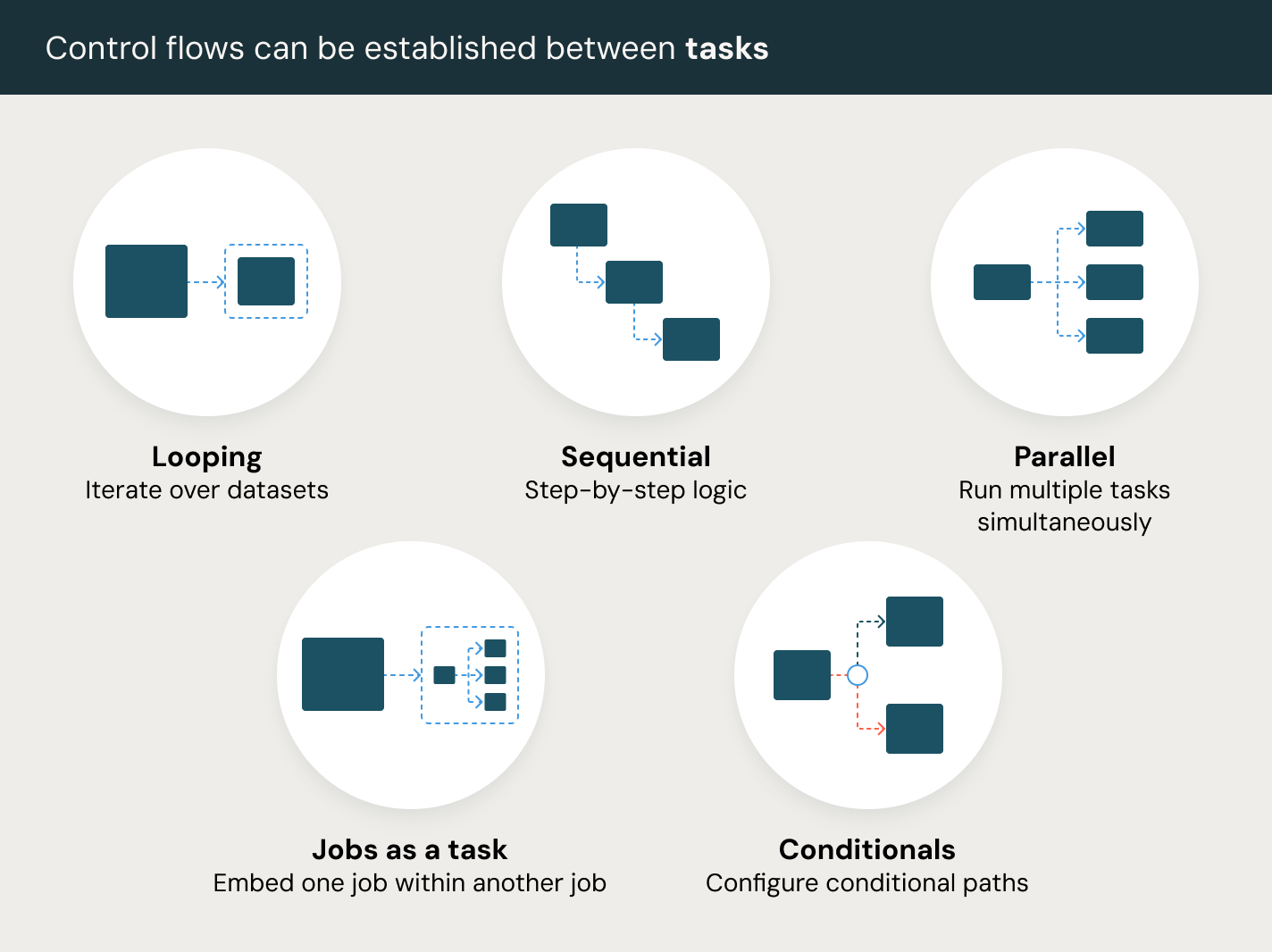
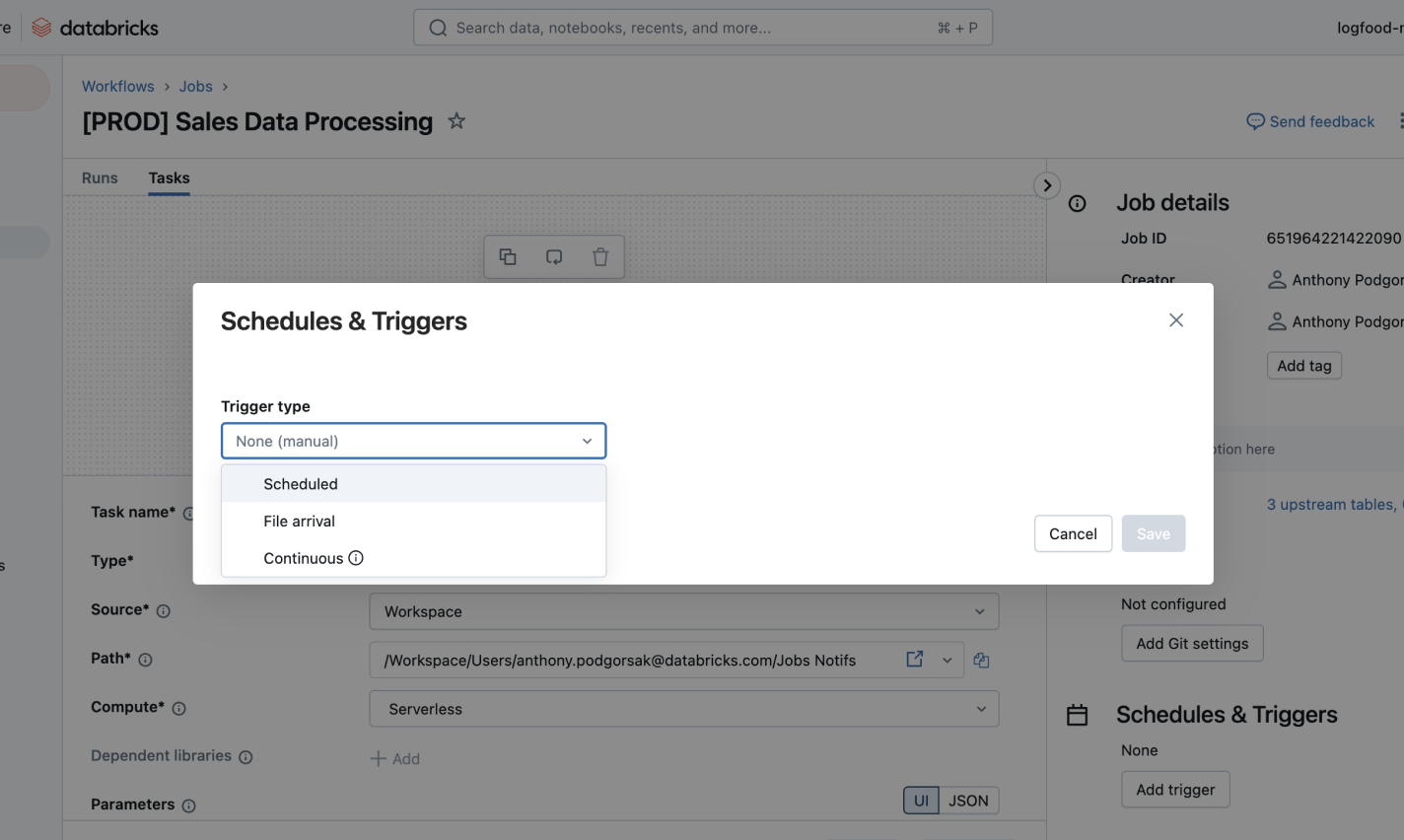
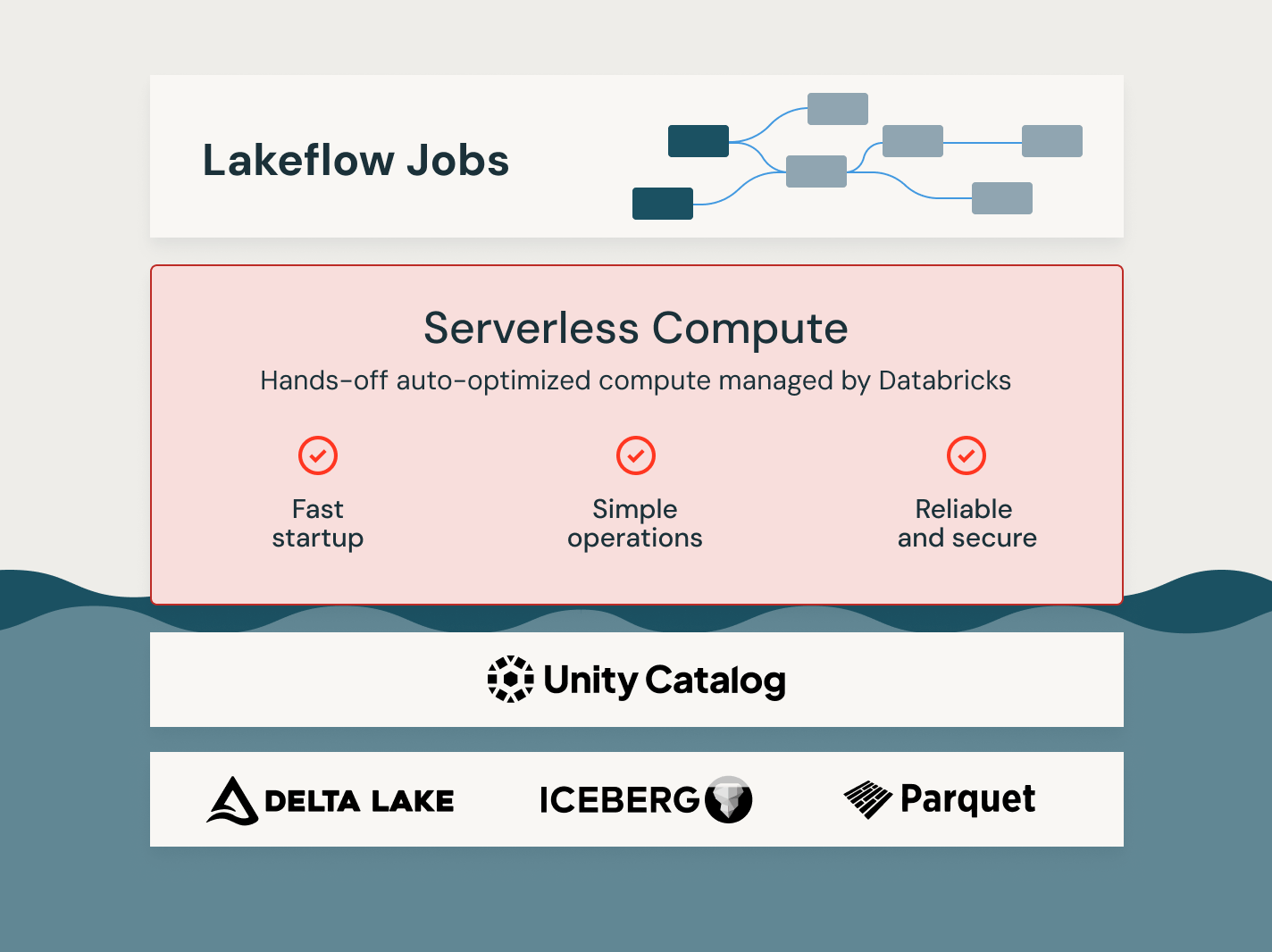
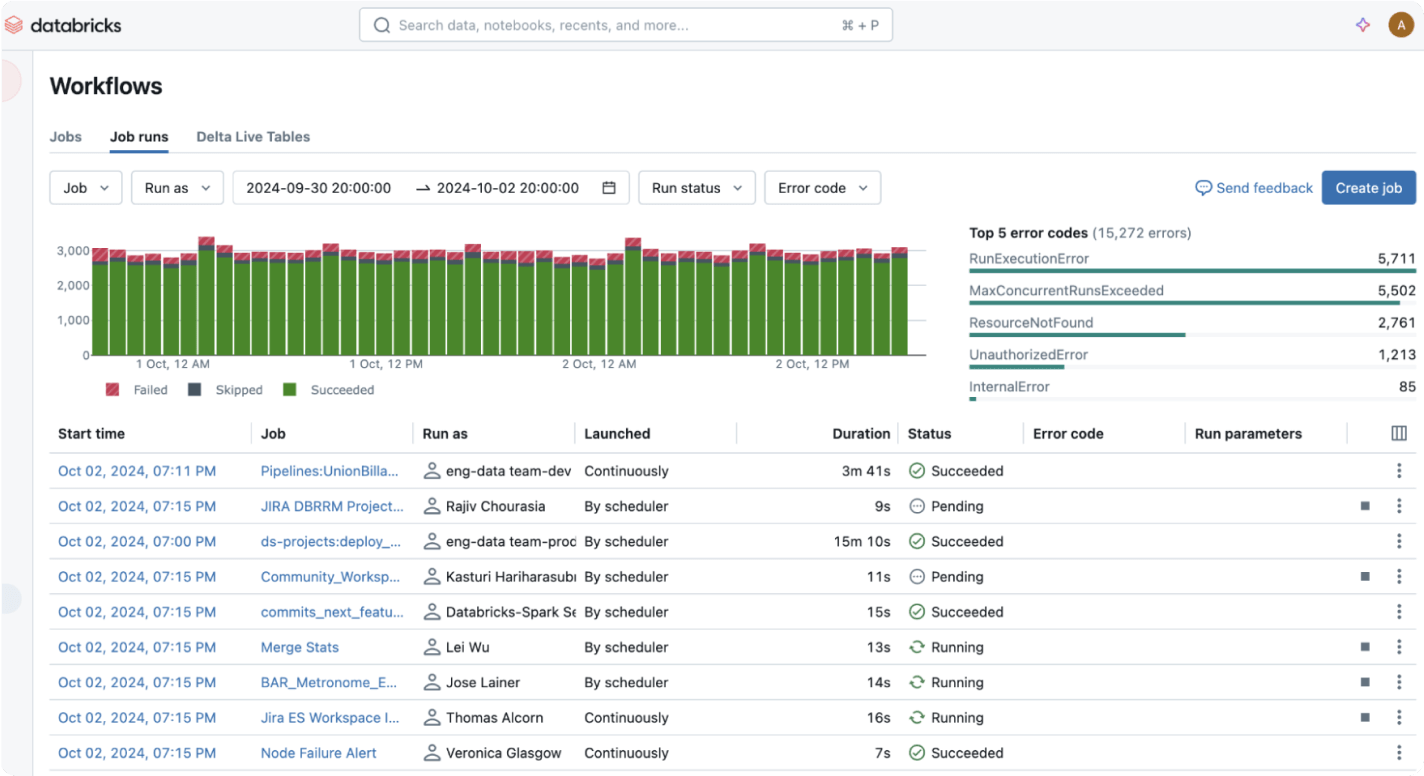

その他の機能
Lakeflow Jobsの力を解放しましょう

データオーケストレーションを自動化し、抽出、変換、ロード(ETL)プロセスを行います
さまざまなソースからDatabricksへのデータ取り込みと変換を自動化し、任意のワークロードに対して正確で一貫したデータ準備を確保します。
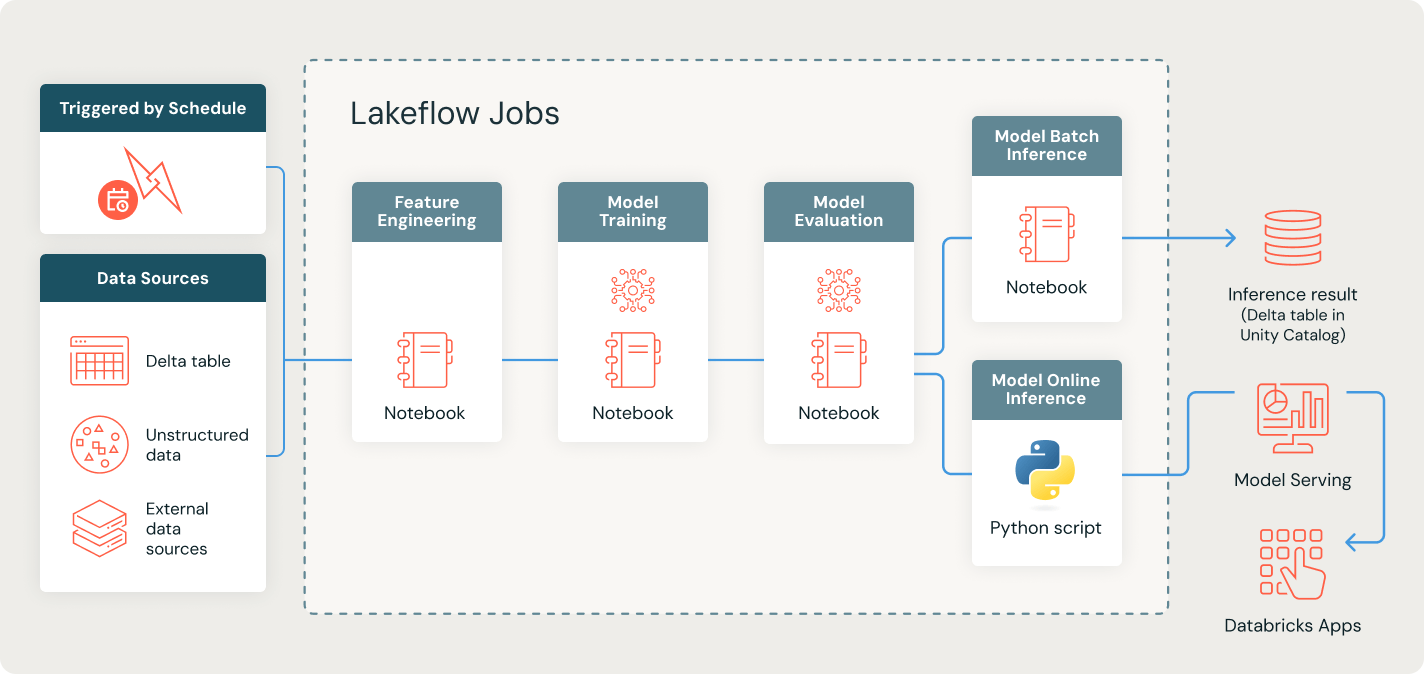
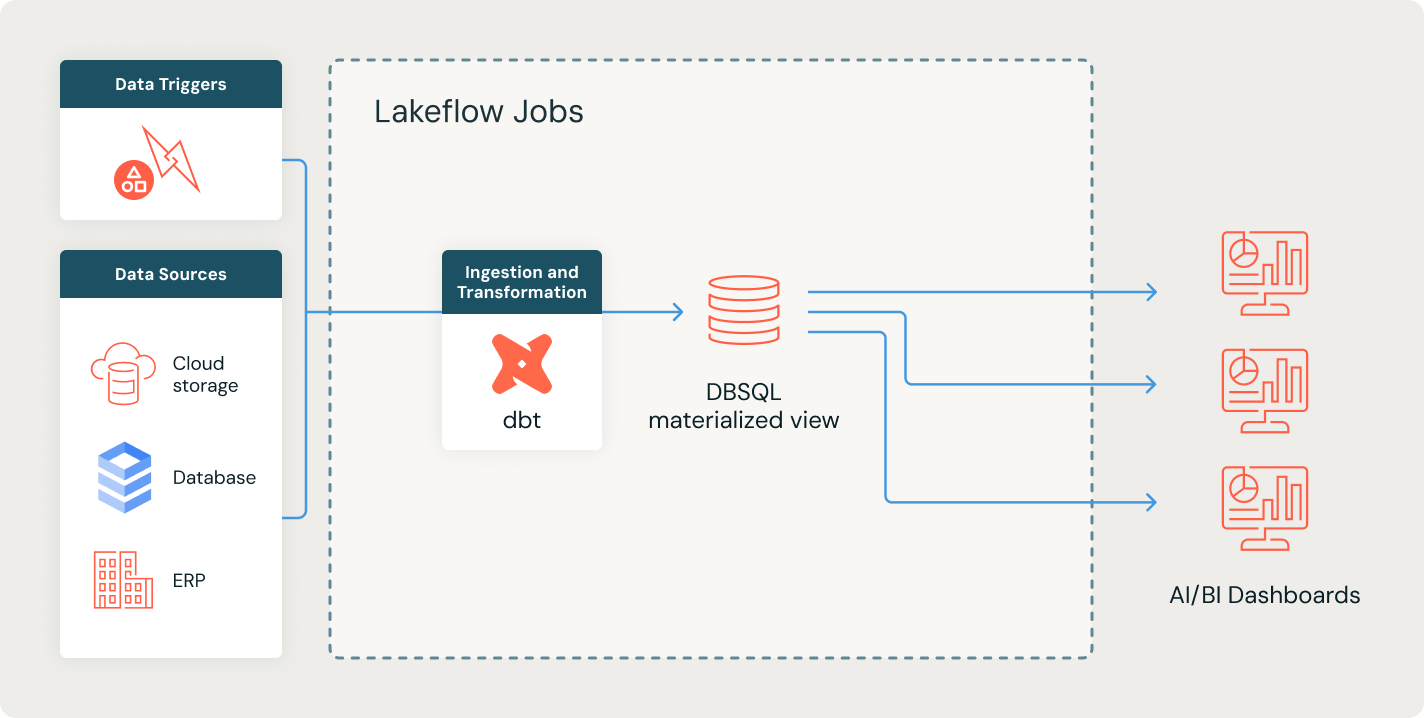
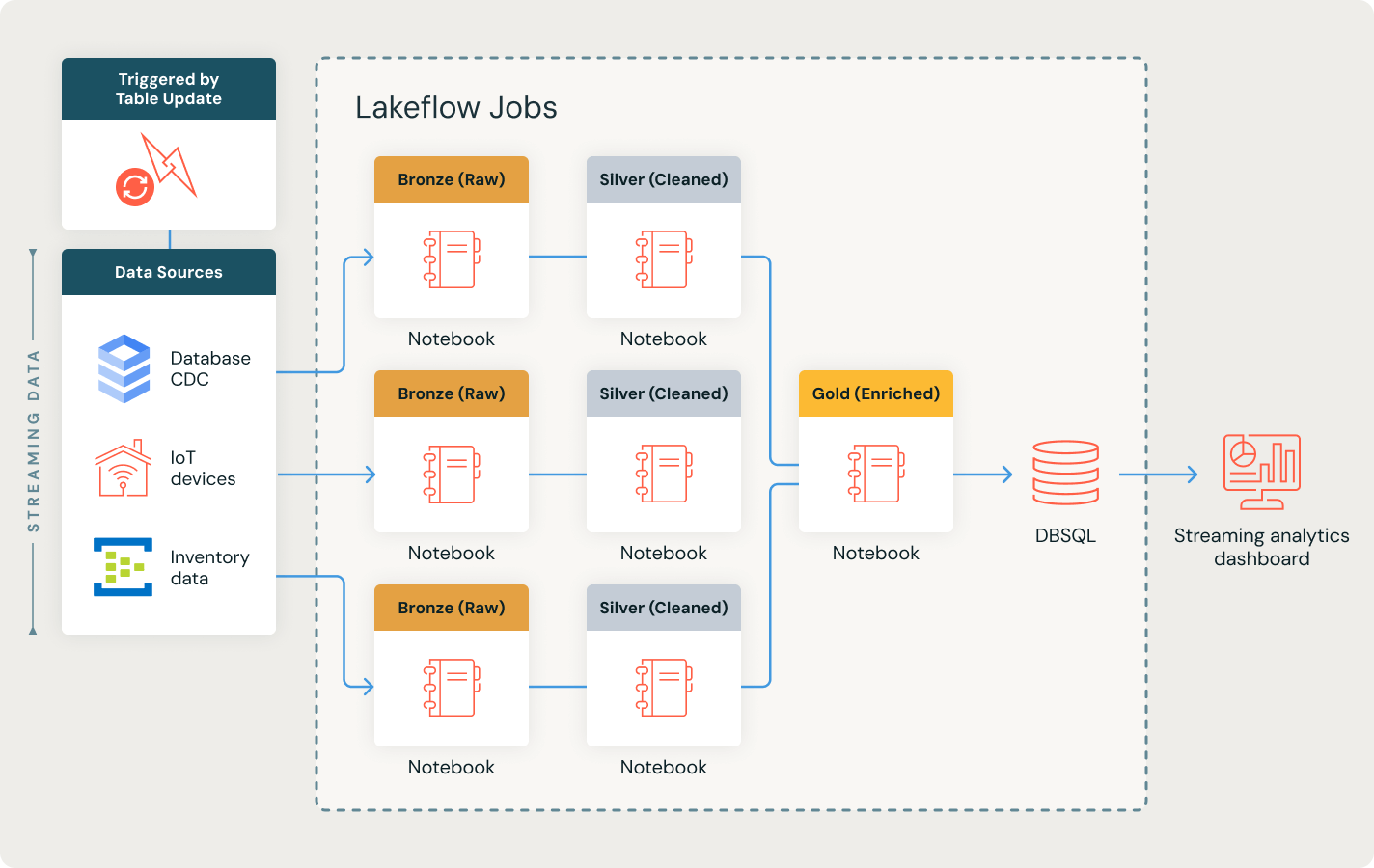
さらに詳しく
Databricksデータインテリジェンスプラットフォームが、あなたのデータとAIのワークロード全体にわたるデータチームをどのように強化するかについて詳しく学びましょう。
LakeFlow Connect
あらゆるソースからの効率的なデータ取り込みコネクタと、Data Intelligence Platformとのネイティブな統合により、統一されたガバナンスの下で、分析とAIへの簡単なアクセスが可能になります。

Spark宣言的パイプライン
バッチおよびストリーミングデータ処理のための簡素化された宣言的なパイプラインを提供し、分析とAI/MLタスクのための自動化された信頼性の高い変換を保証します。

Databricks Assistant
AIによる支援を活用してコーディングを簡素化し、ワークフローのデバッグとクエリの最適化を自然言語を使用してより迅速かつ効率的にデータエンジニアリングと分析を行います。

レイクハウスストレージ
あなたのレイクハウス内のデータを統一し、すべての形式とタイプを通じて、すべての分析とAIワークロードのために利用します。

Unity Catalog
Databricks Data Intelligence Platformに組み込まれた、データとAIのための業界唯一の統一されたオープンなガバナンスソリューションで、すべてのデータ資産をシームレスに管理します。
データインテリジェンスプラットフォーム
Databricks データ・インテリジェンス・プラットフォームは、さまざまなデー��タ・AI のワークロードを支援しています。詳しい内容は、下記のページをご覧ください。



