자동 액체 클러스터링 발표
최대 10배 빠른 쿼리를 위한 최적화된 데이터 레이아웃
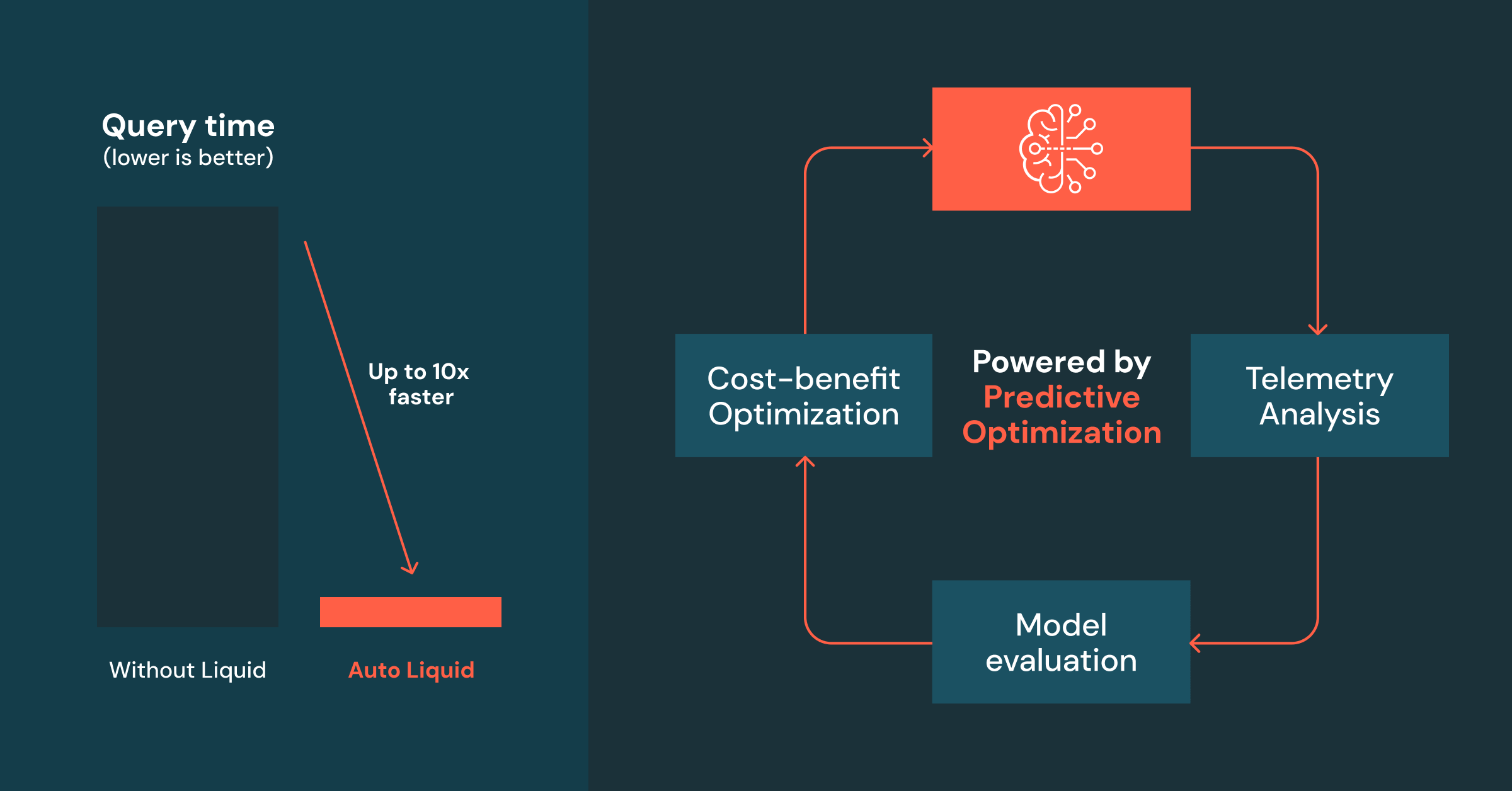
Summary
- 예측 최적화에 의해 구동되는 자동 액체 클러스터링은 클러스터링 키 선택을 자동화하여 쿼리 성능을 지속적으로 향상시키고 비용을 절감합니다.
- 견고한 선택 과정과 지속적인 모니터링으로 테이블을 최적화 상태로 유지합니다.
- TCO는 성능 향상이 비용을 상회하는지 자동으로 평가함으로써 최대화됩니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
우리는 예측 최적화를 통해 구동되는 자동 Liquid 클러스터링의 공개 미리보기를 발표하게 되어 기쁩니다. 이 기능은 Unity 카탈로그 에서 관리하는 테이블에 자동으로 Liquid 클러스터링 열을 적용하고 업데이트하여, 쿼리 성능을 향상시키고 비용을 줄입니다.
자동 Liquid Clustering은 수동 튜닝의 필요성을 제거함으로써 데이터 관리를 단순화합니다. 이전에는 데이터 팀이 각 테이블에 대한 특정 데이터 레이아웃을 수동으로 설계해야 했습니다. 이제 예측 최적화는 Unity 카탈로그의 힘을 이용하여 데이터와 쿼리 패턴을 모니터링하고 분석합니다.
자동 Liquid 클러스터링을 활성화하려면, 파라미터 CLUSTER BY AUTO를 설정하여 UC가 관리하는 비파티션 또는 Liquid 테이블을 구성합니다.
활성화되면, 예측 최적화는 테이블이 어떻게 쿼리되는지 분석하고 작업 부하에 따라 가장 효과적인 클러스터링 키를 지능적으로 선택 합니다. 그런 다음 테이블을 자동으로 클러스터링하여 데이터가 최적의 쿼리 성능을 위해 조직화되도록 합니다. Delta 테이블에서 읽는 모든 엔진은 이러한 개선 사항의 이점을 얻게 되어, 훨씬 빠른 쿼리 를 가능하게 합니다. 또한, 쿼리 패턴이 변경됨에 따라 예측 최적화는 클러스터링 스키마를 동적으로 조정하여, Delta 테이블을 설정할 때 수동 튜닝이나 데이터 레이아웃 결정의 필요성을 완전히 제거 합니다.
프라이빗 프리뷰 동안 수십 명의 고객들이 자동 액체 클러스터링을 테스트하고 강력한 결과를 보았습니다. 많은 사람들이 그 간단함과 성능 향상을 칭찬했으며, 일부는 이미 그들의 골드 테이블에 사용하고 있으며 모든 델타 테이블에 확장할 계획입니다.
Healthrise와 같은 프리뷰 고객들은 자동 액체 클러스터링을 통해 중요한 쿼리 성능 향상 을 보고하였습니다:
“우리는 모든 골드 테이블에 자동 액체 클러스터링을 배포했습니다. 그 이후로, 우리의 쿼리는 최대 10배 빠르게 실행되었습니다. 모든 작업 부하가 데이터 레이아웃 설계나 유지 관리 실행에 수동 작업이 전혀 필요 없이 훨씬 효율적 이게 되었습니다.” — 리 조우, 주요 데이터 엔지니어, 브라이언 알리, 데이터 서비스 | 기술 & 분석, Healthrise
최적의 데이터 레이아웃을 선택하는 것은 어려운 문제입니다
테이블에 최적의 데이터 레이아웃을 적용하면 쿼리 성능과 비용 효율성이 크게 향상됩니다. 전통적으로, 파티셔닝을 사용하면 고객들이 데이터 왜곡과 동시성 충돌을 피하기 위한 적절한 파티셔닝 전략을 설계하는 데 어려움을 겪었습니다. 성능을 더욱 향상시키기 위해, 고객들은 파티셔닝 위에 ZORDER를 사용할 수 있지만, ZORDERing은 비용이 많이 들고 관리하기가 더 복잡합니다.
Liquid Clustering 은 데이터 레이아웃 관련 결정을 크게 단순화하고 클러스터링 키를 데이터 재작성 없이 재정의할 수 있는 유연성을 제공합니다. 고객들은 카디널리티, 키 순서, 파일 크기, 잠재적 데이터 왜곡, 동시성, 그리고 미래의 접근 패턴 변경에 대해 걱정할 필요 없이 쿼리 접근 패턴에 순전히 기반한 클러스터링 키를 선택하기만 하면 됩니다. 우리는 수천 명의 고객들과 함께 작업하여 Liquid 클러스터링을 통해 더 나은 쿼리 성능을 누리는 이점을 얻었고, 이제 매월 3000+명의 활성 고객들 이 �매월 Liquid-클러스터링된 테이블에 200+ PB 데이터 를 작성하고 있습니다.
그러나 Liquid 클러스터링의 발전에도 불구하고, 여전히 테이블을 어떻게 쿼리하는지에 따라 클러스터링할 열을 선택해야 합니다. 데이터 팀은 다음을 파악해야 합니다:
- 어떤 테이블이 Liquid 클러스터링의 이점을 얻을 수 있을까요?
- 이 테이블에 가장 적합한 클러스터링 열은 무엇인가요?
- 비즈니스 요구사항이 변화함에 따라 쿼리 패턴이 변경되면 어떻게 될까요?
또한, 조직 내에서 데이터 엔지니어는 종종 여러 하위 소비자와 함께 작업하여 테이블이 어떻게 쿼리되는지 이해하면서도 변화하는 접근 패턴과 진화하는 스키마를 따라잡아야 합니다. 이 도전은 데이터 볼륨이 더 많은 분석 요구와 함께 확장됨에 따라 기하급수적으로 복잡해집니다.
자동 Liquid 클러스터링이 데이터 레이아웃을 어떻게 발전시키는가?
자동 액체 클러스터링을 통해 Databricks는 테이블 생성부터 데이터 클러스터링, 데이터 레이아웃의 변화에 이르기까지 모든 데이터 레이아웃 관련 결정을 대신해줍니다 - 이를 통해 데이터에서 인사이트를 추출하는데 집중할 수 있게 해줍니다.
예제 테이블을 통해 자동 액체 클러스터링이 어떻게 작동하는지 살펴봅시다.
example_tbl이라는 테이블을 고려해 보세요. 이 테이블은 date 와 customer ID로 자주 쿼리됩니다. 이것은 2월 5-6일 및 고객 ID A에서 F까지의 데이터를 포함합니다. 어떠한 데이터 레이아웃 구성도 없이, 데이터는 삽입 순서��대로 저장되어 다음과 같은 레이아웃을 결과로 합니다:
고객이 SELECT * FROM example_tbl WHERE date = '2025-02-05' AND customer_id = 'B'를 실행한다고 가정해봅시다. 쿼리 엔진은 델타 데이터 스킵 통계 (최소/최대 값, null 카운트, 파일당 총 레코드)를 활용하여 스캔할 관련 파일을 식별합니다. 불필요한 파일 읽기를 제거하는 것은 중요합니다. 이는 쿼리 실행 중에 스캔되는 파일 수를 줄이고, 직접적으로 쿼리 성능을 향상시키고 컴퓨팅 비용을 낮춥니다. 쿼리가 읽어야 할 파일이 적을수록, 그것은 더 빠르고 효율적이게 됩니다.
이 경우, 엔진은 2월 5일에 대해 최소/최대 값을 가진 파일의 절반이 날짜 열과 일치하기 때문에 5개의 파일을 식별합니다. 그러나, 데이터 스킵 통계는 최소/최대 값만 제공하기 때문에, 이 5개의 파일은 모두 고객 ID 의 최소/최대 값이 고객 B 가 중간 어딘가에 있다는 것을 제안합니다. 결과적으로, 쿼리는 고객 B의 항목을 추출하기 위해 모든 5개의 파일을 스캔해야 하며, 이는 50%의 파일 가지치기 비율(10개의 파일 중 5개를 읽음)을 초래합니다.
보시다시피, 핵심 문제는 고객 B의 데이터가 단일 파일에 공동으로 위치하지 않는 것입니다. 이는 고객 B 의 모든 항목을 추출하려면 다른 고객들의 상당한 양의 항목을 읽어야 함을 의미합니다.
여기서 파일 정리와 쿼리 성능을 향상시킬 방법이 있을까요? 자동 액체 클러스터링은 두 가지를 모두 향상시킬 수 있습니다. 그 방법을 확인해보세요.
자동 액체 클러스터링의 뒷면: 작동 원리
한번 활성화되면, 자동 Liquid 클러스터링은 계속해서 다음 세 단계를 수행합니다:
- 테이블이 Liquid Clustering 키의 도입이나 진화로 이익을 얻을지 결정하기 위해 텔레메트리 를 수집합니다.
- 작업 부하를 모델링 하여 적격한 열을 이해하고 식별합니다.
- 열 선택을 적용하고 비용-효익 분석에 기반한 클러스터링 체계를 발전시킵니다.

단계 1: 텔레메트리 분석
예측 최적화는 쿼리 스캔 통계를 수집하고 분석하여, 테이블이 Liquid 클러스터링에서 이점을 얻을 수 있는지 여부를 결정합니다.
우리의 예시로, 예측 최적화는 'date' 와 'customer_id' 열이 자주 쿼리되는 것을 감지합니다.
단계 2: 작업 부하 모델링
예측 최적화는 쿼리 작업 부하를 평가하고 데이터 스킵을 최대화하기 위한 최적의 클러스터링 키를 식별합니다.
이것은 과거 쿼리 패턴에서 학습하고 다른 클러스터링 체계의 잠재적인 성능 향상을 추정합니다. 과거 쿼리를 시뮬레이션함으로써, 각 옵션이 스캔된 데이터의 양을 얼마나 효과적으로 줄일 수 있는지예측합니다.
우리의 예시에서, ‘날짜’ 와 ‘고객_id’ 에 대한 등록된 스캔을 사용하고 일관된 쿼리를 가정하면, 예측 최적화는 다음을 계산합니다:
‘날짜’에 의한 클러스터링은 50%의 프루닝 비율로 5개의 파일을 읽습니다.‘customer_id’로 클러스터링하면, 약 2개의 파일을 읽어들이며(추정치), 80%의 프루닝 비율을 가집니다.‘date’와‘customer_id’둘 다로 클러스터링하면(아래의 데이터 레이아웃 참조), 단 1개의 파일만 읽어들이며 90%의 프루닝 비율을 가집니다.
단계 3: 비용-효익 최적화
Databricks 플랫폼은 클러스터링 키의 변경이 성능 향상에 명확한 이점을 제공함을 보장하며, 클러스터링은 추가적인 오버헤드를 초래할 수 있습니다. 새로운 클러스터링 키 후보가 식별되면, 예측 최적화는 성능 향상이 비용을 상회하는지 평가합니다. 만약 이점이 크다면, Unity 카탈로그 관리 테이블에서 클러스터링 키를 업데이트합니다.
우리의 예시에서, 'date' 와 'customer_id' 에 따른 클러스터링은 데이터의 90%를 정리하는 결과를 가져왔습니다. 이러한 열은 자주 쿼리되므로, 감소된 컴퓨팅 비용과 향상된 쿼리 성능은 클러스터링 오버헤드를 정당화합니다.
프리뷰 고객들은 예측 최적화의 비용 효율성을 강조했으며, 특히 수동으로 데이터 레이아웃을 설계하는 것에 비해 오버헤드가 낮습니다. CFC Underwriting과 같은 회사들은 소유 총 비용이 낮아졌다 고 보고하고 있으며, 효율성이 크게 향상되었습니다.
“우리는 Databricks의 자동 액체 클러스터링을 정말 좋아합니다. 왜냐하면 이를 통해 가장 최적화된 데이터 레이아웃을 바로 사용할 수 있다는 안심감을 줍니다. 또한 이는 엔지니어가 데이터 레이아웃을 유지할 필요를 제거함으로써 우리에게 많은 시간을 절약해 주었습니다. 이 기능 덕분에, 우리는 데이터 볼륨을 확장하면서도 컴퓨팅 비용이 줄어들었다는 것을 알게 되었습니다.” — Nikos Balanis, 데이터 플랫폼 헤드, CFC
이 기능을 간단히 설명하면: 예측 최적화는 당신을 대신하여 Liquid 클러스터링 키를 선택합니다, 그래서 데이터 스킵으로 인한 예상 비용 절감이 클러스터링의 예상 비용을 상회합니다.
지금 시작해 보세요!
아직 예측 최적화를 활성화하지 않았다면, 계정 콘솔에서 설정 > 기능 활성화 옆에 있는 예측 최적화를 선택하여 활성화할 수 있습니다.
Databricks가 처음이신가요? 2024년 11월 11일 이후, Databricks는 모든 새로운 Databricks 계정에서 기본적으로 예측 최적화를 활성화하였으며, Unity 카탈로��그 관리 테이블에 대한 모든 최적화를 실행하였습니다.
오늘 시작하세요 Unity 카탈로그 관리 테이블에 CLUSTER BY AUTO 를 설정함으로써. 새로운 AUTO 테이블을 생성하거나 기존의 Liquid / 비파티션 테이블을 변경하려면 Databricks 런타임 15.4+가 필요합니다. 가까운 미래에는 자동 액체 클러스터링이 새로 생성된 Unity 카탈로그 관리 테이블에 기본적으로 활성화될 예정입니다. 자세한 내용은 계속해서 알려드리겠습니다.

