Databricks Query Profiles에 대한 업데이트 발표
당신의 성능 튜닝을 위한 현대화된 경험

Summary
- 향상된 쿼리 인사이트: 재설계된 쿼리 프로필은 쿼리 성능에 대한 더 명확한 시각을 제공합니다.
- 개선된 최적화 도구: 새로운 Top Operators 패널과 같은 기능을 통해 성능 병목 현상을 쉽게 찾을 수 있습니다.
- 간소화된 분석: 어떤 노드든 쉽게 확대하여 필터링하고, 매우 상호 작용적인 그래프에서 탐색할 수 있습니다.
Databricks에서는 항상 여러분의 쿼리가 더 빠르게 실행되도록 노력하고 있습니다. 그럼에도 불구하고, 쿼리가 어떻게 실행 계획으로 변환되고 병렬 실행을 위해 분배되는지 좀 더 자세히 살펴보는 것이 도움이 되는 경우가 있습니다.
그래서 쿼리 프로필 이 등장합니다. 우리는 이를 Databricks SQL의 첫 번째 릴리즈에서부터 소개했습니다. 그 이후로, 노트북과 워크플로우를 위한 서버리스 컴퓨트에서 실행되는 SQL과 파이썬 코드에 뿐만 아니라 DLT 파이프라인에도적용했습니다.
여러분의 피드백 덕분에 Query Profiles를 더욱 개선하였습니다. 이제 모든 클라우드에서 사용할 수 있는 새로운 경험은 성능을 미세 조정하고 병목 현상을 해결하는 것을 더욱 쉽고 즐겁게 만듭니다.
쿼리 프로필: 성능 튜닝의 동반자
Query Profiles는 SQL, Python DataFrames, 또는 DLT 파이프라인을 사용하든지 간에 쿼리가 어떻게 실행되는지 이해하는 데 도움을 줍니다. 각 쿼리의 느린 부분을 찾아내고, 실행 중에 어떤 일이 발생하는지 이해하고, 성능 튜닝 결정을 안내하는 데 도움을 줍니다. 아래의 비디오를 확인하여 Query Profiles가 어떻게 작동하는지 확인하고 시도해 보세요.
업그레이드된 인터페이스는 매우 상호 작용적이고 직관적입니다. 시각적으로 실행 계획을 탐색하고, 어떤 작업이 포함되었는지(예: 스캔 또는 조인) 확인하고, 시간과 자원이 어디에 소비되었는지, 쿼리가 아직 실행 중인지 이미 완료되었는지를 빠르게 파악하는 메트릭을 확인할 수 있습니다.
Databricks 전반에 걸쳐 쿼리 프로필을 찾을 수 있습니다: 쿼리 히스토리 페이지, 노트북, SQL 에디터, Jobs UI, 그리고 DLT 파이프라인에서도 찾아볼 수 있습니다. 또한 Databricks Assistant 와 함께 /optimize 명령을 사용할 때 통합되어 있습니다.
개발 중에 쿼리를 미세 조정하거나 느린 작업이나 파이프라인을 조사하거나 쿼리 히스토리 시스템 테이블을 사용하여 이상치를 발견한 후 세부 사항을 파악하는 데, 쿼리 프로필은 성능을 이해하고 향상시키는 데 가장 좋은 도구입니다.
더 깊게 들어가기 전에 더 똑똑한 개요를 제공합니다
쿼리 요��약 패널을 재구성하여 쿼리를 완전히 열기 전에 쿼리에 대한 더 명확한 그림을 제공합니다. 쿼리 히스토리에서 문장을 검토하든, 에디터에서 활발하게 개발하든, 한눈에 개요를 볼 수 있습니다.
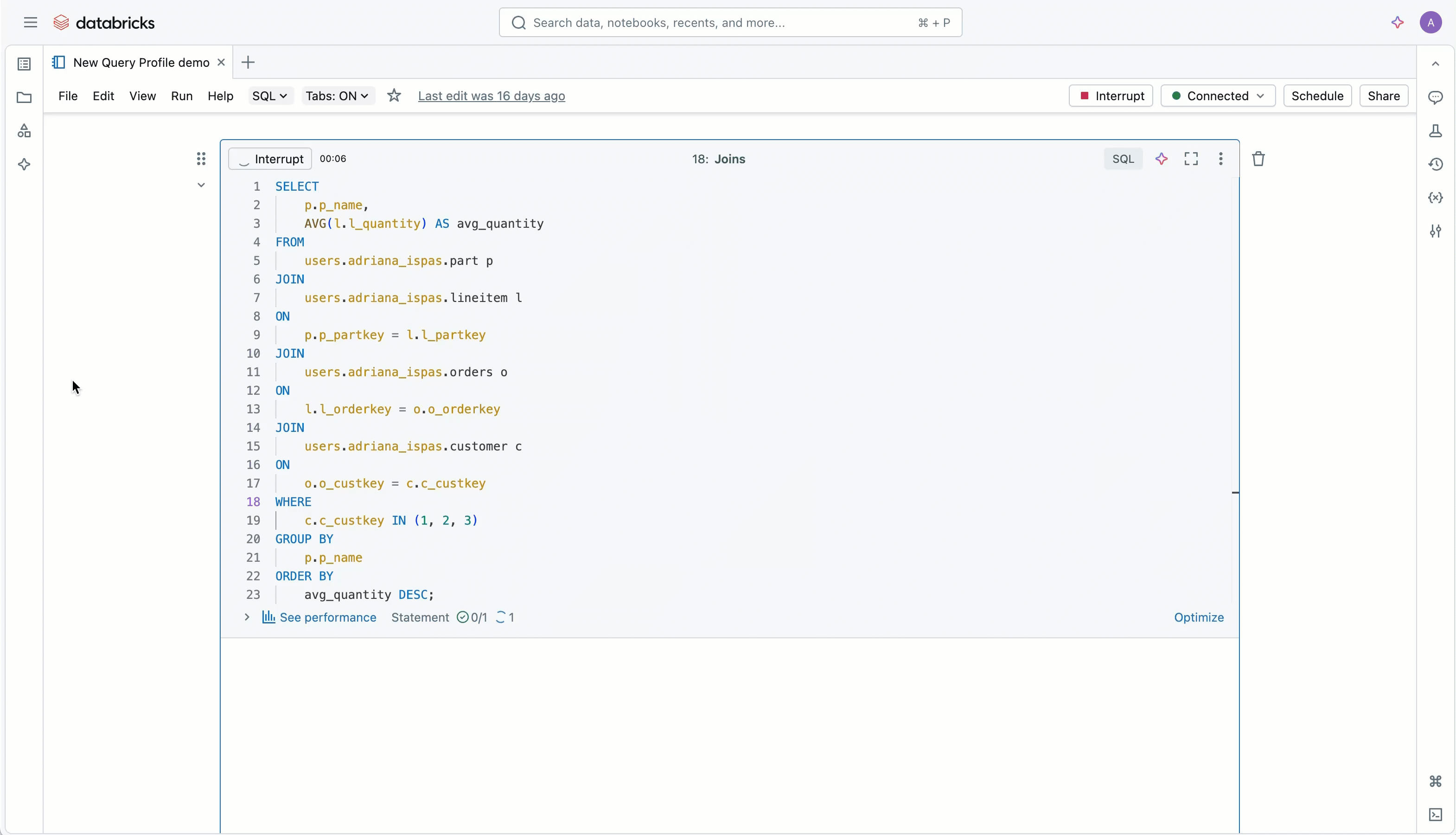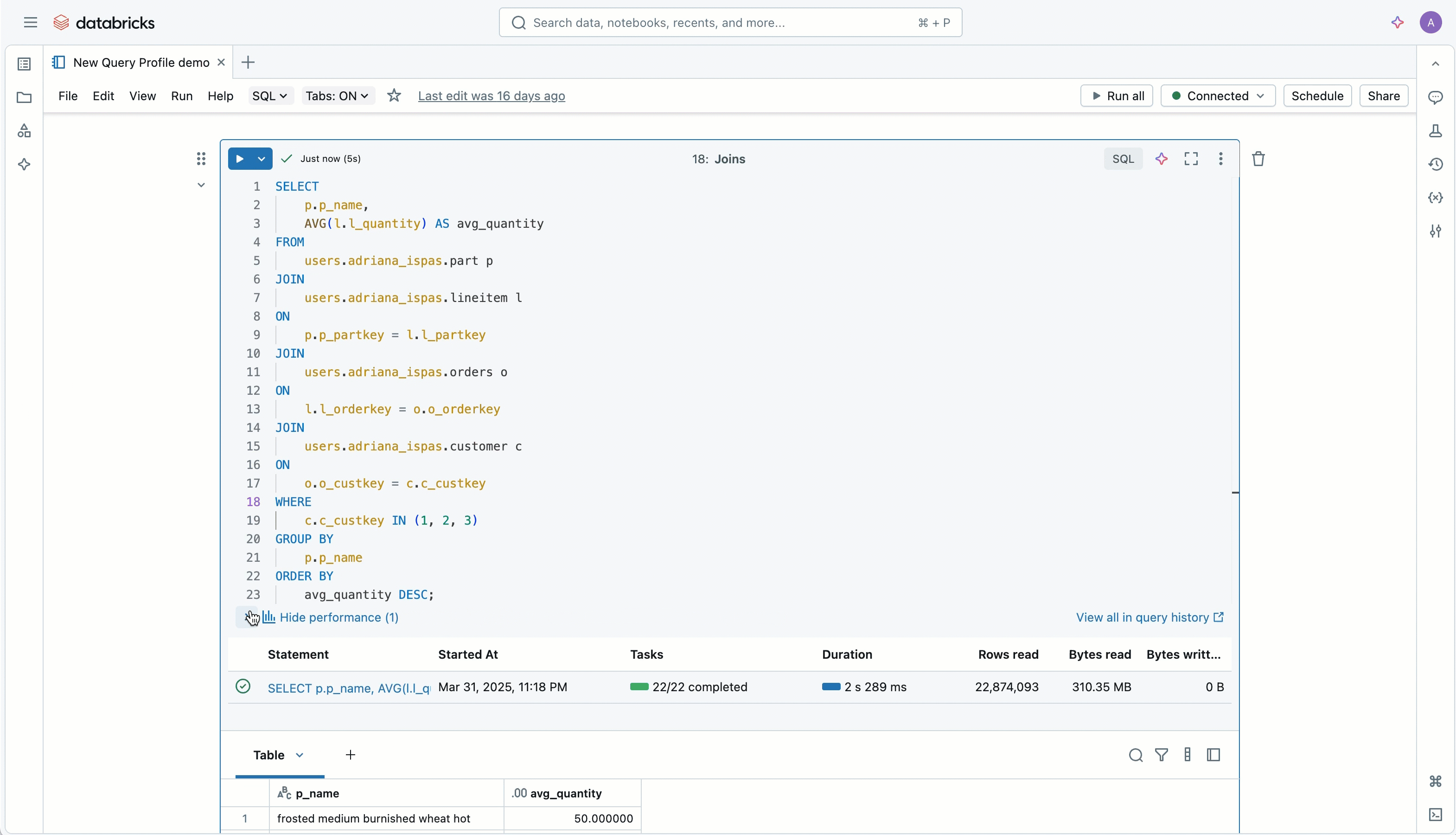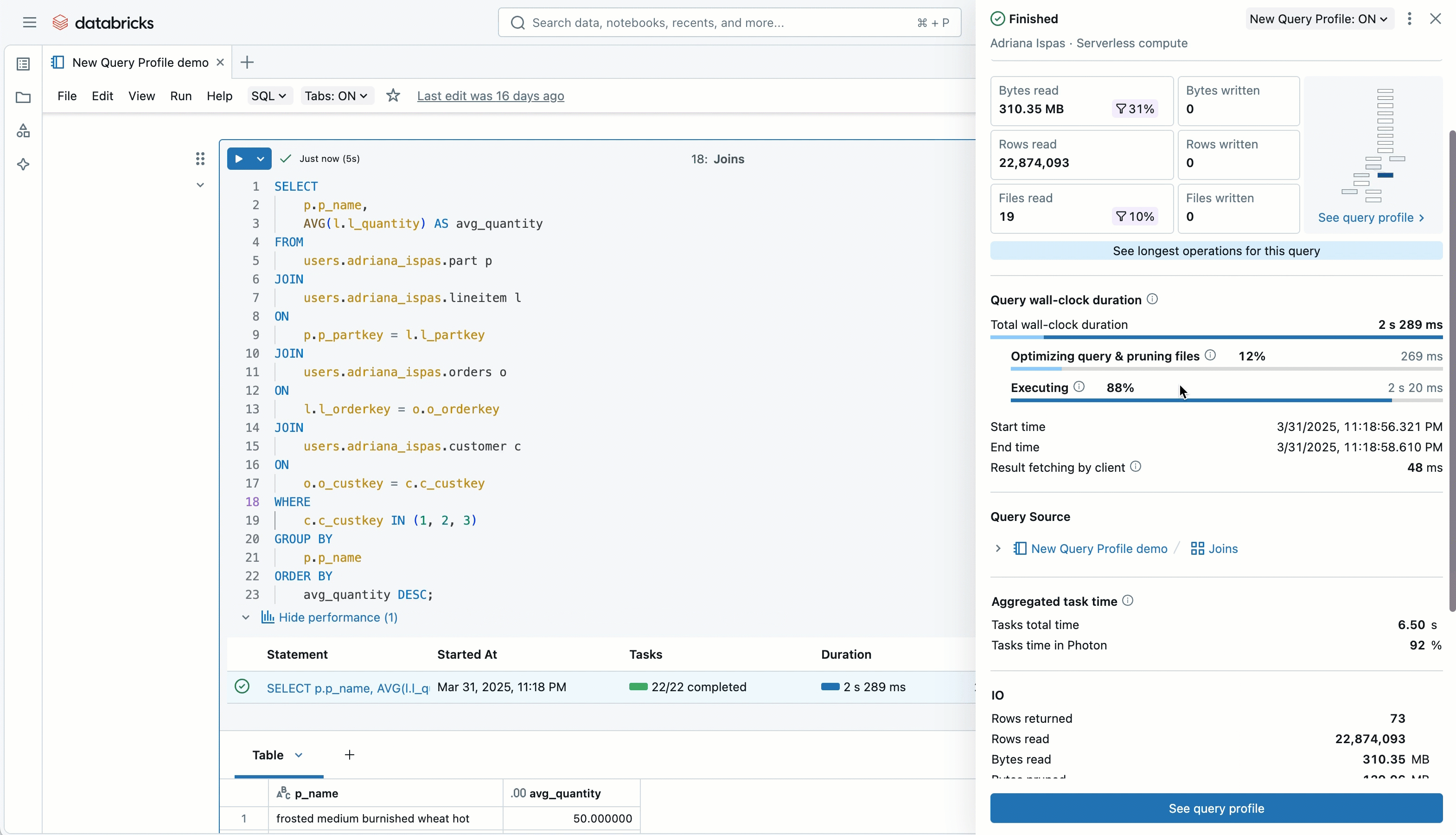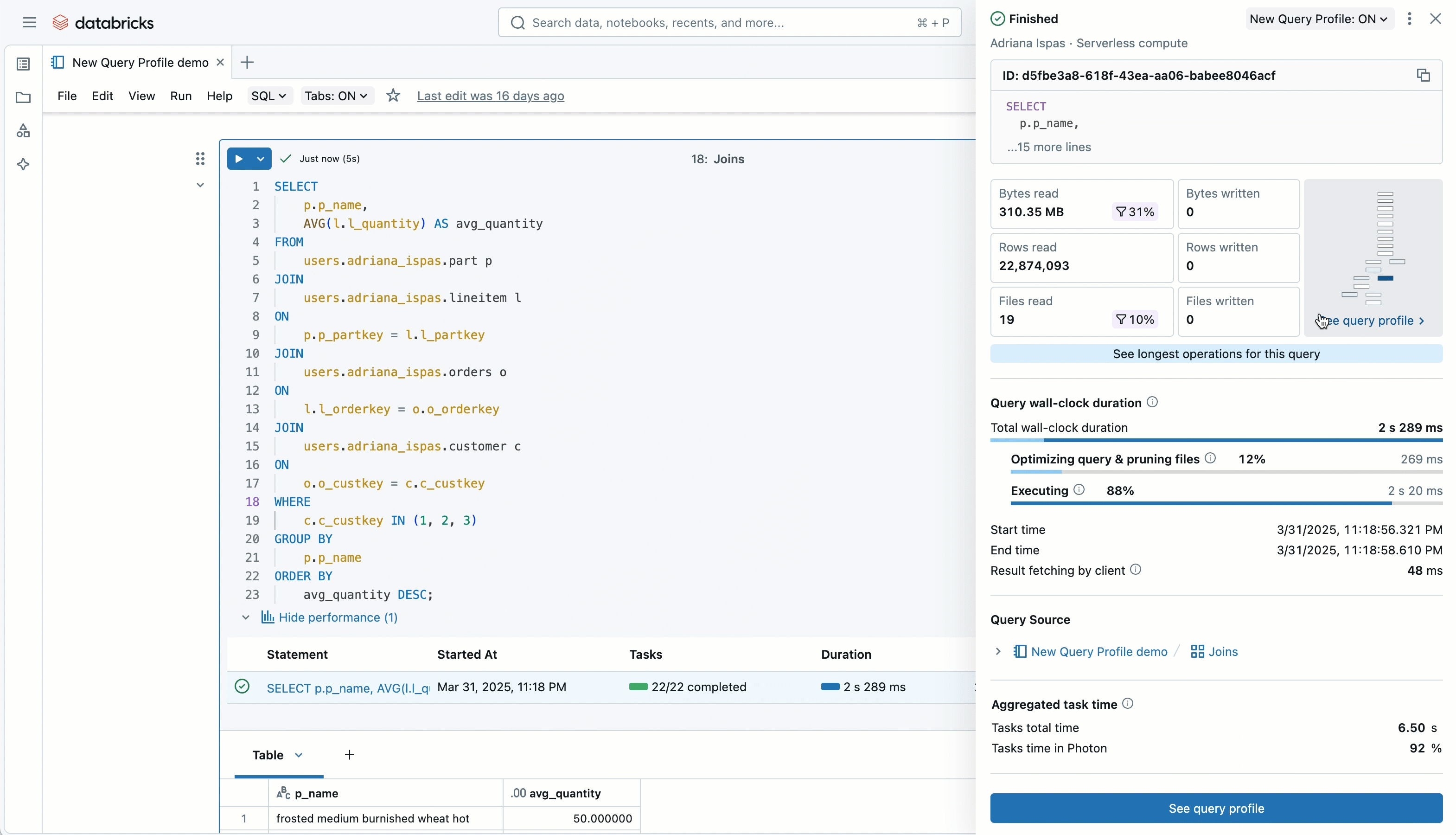
읽기/쓰기 메트릭과 필터의 효과성에 대한 시각적 요약을 볼 수 있으므로, 얼마나 많은 데이터가 제거되었는지 즉시 알 수 있습니다. 또한 쿼리 프로필의 전체적인 형태와 복잡성, 그리고 시간이 어디에서 소비되었는지(실행 vs 최적화와 같은 다른 단계)에 대한 고수준의 분해도를 미리 볼 수 있습니다.
빠른 링크를 통해 새로운 Top Operators 패널로 바로 이동할 수 있으며, 쿼리 소스 는 이제 클릭 한 번으로 접근할 수 있어, 쿼리를 생성한 코드의 정확한 부분으로 돌아가기 쉽습니다. 직접 편집이 불가능한 Query History나 Jobs 페이지와 같은 곳에서도 말이죠.
게다가, 모든 연산자에 걸쳐 집계된 주요 지표의 요약을 찾을 수 있으므로, 전체 실행 계획을 살펴��보기 전에도 빠르게 문제점을 파악할 수 있습니다.
새로운 Top operators 패널
새로운 Top operators 패널은 쿼리의 가장 비용이 많이 드는 부분을 바로 표시하여 최적화의 가장 큰 기회를 빠르게 찾을 수 있게 해줍니다. 연산자의 순위가 매겨진 목록을 받아, 가장 큰 영향을 미칠 곳에 튜닝 노력을 집중하기 쉽게 만들어줍니다.
우리는 상호 작용하는 컨트롤을 추가했습니다: 패널에서 연산자를 클릭하면 그래프의 해당 부분으로 확대되어 자세한 메트릭을 즉시 볼 수 있습니다. 이는 쿼리 계획에서 성능 핫스팟을 탐색하는 더 빠른 방법입니다.
실행 그래프를 탐색하는 더욱 세련되고 빠른 방법
우리는 실행 그래프를 재설계하여 탐색을 더욱 직관적이고 효율적으로 만들었습니다. 이제 노드를 직접 확대하여 볼 수 있으며, 키워드로 노드를 필터링하고, 더욱 풍부한 세부 정보를 볼 수 있습니다. 모두 깔끔하고 세련된 인터페이스 내에서 가능합니다.
대형 그래프 도 더 쉽게 관리할 수 있습니다. 우리는 최소화된 노드 뷰 를 도입하여 확대 축소 시 시각적 잡음을 줄이고, 계획에서 가장 비용이 많이 드는 노드를 강조합니다. 이 기능을 사용하면 성능 핫스팟을 빠르게 찾아내고 어디를 확대하여 더 자세히 조사할지 결정할 수 있습니다.
사용한 시간, 메모리 사용량, 처리된 행 수 중에서 집중할 항목을 선택할 수 있습니다. 특히 시간 소비 메트릭은 가장 집중적인 작업이 어디에서 이루어졌는지를 정확하게 지정하는 데 도움이 됩니다. 이는 귀하의 클러스터에서 여러 작업 노드에 걸쳐 병렬로 코드를 실행한 모든 작업의 실행 시간을 집계합니다.
연산자 메트릭에 대한 더 쉬운 접근
우리는 연산자 메트릭의 탐색과 분석을 단순화했습니다. 업데이트된 레이아웃은 주요 세부 사항을 더 명확하게 제��시하며, 새로운 필터 옵션을 통해 관심 있는 메트릭을 빠르게 좁혀볼 수 있습니다. 더 이상 끝없이 스크롤할 필요가 없습니다.
분석을 다른 곳으로 가져가야 할 필요가 있나요? 이제 연산자 메트릭을 내보내기 를 한 번의 클릭으로 CSV로 할 수 있습니다. 또한, 테이블 수준의 인사이트 를 스캔 연산자에 추가하여 읽는 테이블의 주요 세부 정보에 대한 개요를 제공합니다.
다음은 무엇인가요?
여기서 멈추지 않습니다. 현재 탐색 중인 내용의 미리보기를 제공합니다:
- 쿼리 프로필에 내장된 더욱 똑똑한 통찰력과 튜닝 제안.
- Databricks Assistant의 /optimize 기능과의 더욱 밀접한 통합.
- 시스템 테이블로서의 쿼리 인사이트를 통해 대규모로 성능을 모니터링할 수 있습니다.
무엇을 더 보고 싶은지 알려주세요 - 여러분의 피드백이 우리가 만드는 것을 결정합니다.
시작해 볼 준비가 되셨나요? 새로운 Query Profile을 Databricks SQL에서 탐색하거나, Databricks SQL을 무료로 사용해 보세요. Query Profiles는 또한 노트북, 워크플로우용 무서버 컴퓨팅 및 DLT를 지원합니다!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)

